0x00 内容摘要
神经网络是一种模拟人脑的神经网络,以期望能够实现人工智能的机器学习技术
0x01 基础知识
1.线性代数和基本代数
这里的空白太小,只讲一些涉及这个项目的线性代数的知识。
矩阵乘法
C(hc,lc)=A(ha,la)*B(hb,lb)需要满足的条件是:
1. A的列数(la)==B的行数(hb)
2. C的行数(hc)==A的行数(ha)
C的列数(lc)==B的列数(lb)
阈值函数
为了模拟实际的神经网络,当给的输入过低时,输出的内容会为0,当达到阈值后,输出的内容才会是实际的输出。但是同样的阈值函数会是一条平滑的曲线,于是我们使用函数:
1/(e^-x+1)
并称之为S函数,当输入(x)过低时,输出接近与于0,当输出(x)过高时,输出接近于1。并且无论x为何值,输出的范围为(0,1)。
注:0与1是取不到的
误差分析
假设当我们的输入(Ai)为 [1.0 0.5]
通过中间过程(X)
变为输出(Ao) [0.7 0.6]
中间过程类似一个黑盒子。有两个接口,一个接口给输入,另一个接口给输出。
假设中间过程(X)为(随机取值的)
[0.9 0.3]
[0.2 0.8]
X*A^T=
[1.05 0.6]
输出误差Ae=
[-0.35 0]
于是对误差反相传播,将误差(-0.35)按权重的方式分配给 0.9与0.3。
所以我们认为0.9导致的误差为(-0.35)*[0.9/(0.3+0.9)]=-0.2625

于是我们的想法是减小(误差为负数) 0.9 和 0.3,并且,0.9减小的幅度比0.3大,
比如说:
0.9==>0.65(减少了k*反馈量)
0.3==>0.21
新的X=
[0.65 0.21]
[0.2 0.8]
计算新的输出为
X*A^T=
[0.755 0.6]
与期望输出任然有点偏差。
计算新的输出误差为
[0.055 0]
很明显误差变小了,
在进行一次反馈,误差会更加小。最后会得到一个能用的X(不一定是我完全推导出来的)
误差更新公式
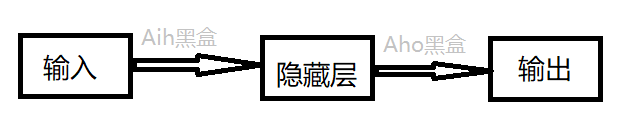
实际使用的神经网络结构。
误差更新公式:
Aho+=学习率(k)x输出误差(Ae)x输出结果(Ao')x(1-输出结果)*隐藏层输出
其中中间层误差为
隐藏层误差=Aho^T*输出误差
同理:
Aih+=学习率(k)x隐藏层误差x隐藏层结果x(1-隐藏层结果)*输出层输入
k为学习率,有每次更改步长的意思。
很明显,上面的Aih和Aho是重复的,只是对于不同的黑盒,矫正时的输入和输出的对象不同。
在上面的式子中x表示普通乘法,对于矩阵是对应元素相乘,*表示矩阵点乘。
2.python
python的内容有些广,当然不是要使用python的所有的内容,只是用一些python的库,进行实现。
几个比较有帮助的库:
numpy数学工具
常用的函数:
当然常用的函数都是与矩阵有关。
numpy.random.rand
生成一个随机矩阵内容为(0-1)的小数
举例:
wih=numpy.random.rand(hnodes,inode)-0.5
#产生一个行为hnodes列为inodes的内容为0-1小数的矩阵,为了参数负数于是-0.5
numpy.random.normal
生成随机内容的矩阵,但是矩阵里的内容满足正太分布。
举例:
numpy.random.normal(0.0,pow(hnodes,-0.5),(hnodes,inodes))
# 生成一个行数为hnodes,列数为inodes,满足内容为平均值为0.0,方差为hnodes^-0.5的随机矩阵。
numpy.array
列表转为矩阵
numpy.array(inputs_list,ndmin=2).T
# 将inputs_list转为2维(ndmin=2)的矩阵,并进行转置(.T)
numpy.dot
矩阵的点乘
numpy.dot(wih,inputs)
返回wih*inputs
numpy.zeros
生成一个元素全部为0的矩阵
numpy.zeros(output_nodes)
因为只有一个参数,所以产生的是列表(一维矩阵)
numpy.asfarray
将字符类型的元素转为浮点型,并做成矩阵
numpy.asfarray(all_values[1:]) / 255.0*0.99+0.01
all_value[1:]是指一个列表从第一项开始,到末尾的内容,这里内容为字符型的数字
将字符型的数字转为浮点型并/255.0*0.99+0.01
numpy.argmax(a, axis=None, out=None)
返回沿轴axis最大值的索引
numpy.argmax([[0 0 1 2]])
numpy.savetxt 矩阵保存
numpy.savetxt("wih.txt",wih,fmt="%f",delimiter=",")
将wih这个矩阵保存到wih.txt中,并且保存的每个元素是float类型,元素的间隔是','(逗号)隔开
numpy.loadtxt 矩阵保存
a=numpy.loadtxt("wih.txt",delimiter=",")
将wih.txt中的矩阵导入,矩阵元素的分割是‘,’(逗号),并把矩阵幅值给a。
scipy 内含S函数和图形操作
scripy.special.expit(x)
这个就是我们一个说的阈值函数,S函数
scipy.ndimage.interpolartion.rotate
图形矩阵旋转函数
scipy.ndimage.interpolartion.rotate(scaled_input.reshape(28.28),10,cval=0.01,reshape=False)
scaled_input是一个一维矩阵.reshape(28,28),将列表变为28*28的二维矩阵。
将图形旋转10度,产生的空白位置填充0.01,并且拒绝(reshape=False)出现,旋转后,不产生空白,而是压缩的形式。
scipy.misc.imread
读取png格式的图片,并转为像素点的矩阵
img_array = scipy.misc.imread(image_file_name,flatten=True)
img_data = 255.0-img_array.reshape(784)
将图片导入后,转为1维矩阵
matplotlib.pyplot 像素矩阵与图形的转化工具
%matplotlib inline
坚持在编译器中显示图片而不是在窗口里显示
matplotlib.pyplot.imshow
将像素矩阵进行图片显示
imshow(image_array,cmp='Greys',interpolation='None')
将图片的矩阵(image_array),选择灰度调色板(cmp='Greys'),并且不要为了让图形更加顺滑而混合颜色。
json 数据导入导出工具
dumps和dump
将变量的内容写入文件
f.write(json.dumps(a, indent=4))
json.dump(a,f,indent=4)
作用都是将a的内容写入文件f,并格式化写入文件(indent = 4),作用相同,参数不同
loads和load
将文件的内容导出到变量
json.load(f)
json.loads(f.read())
将文件f的内容导出,作用相同,参数不同
3.准备训练文件
训练集
测试集
[训练集](http://www.pjreddie.com/media/files/mnist_train.csv)
[测试集](http://www.pjreddie.com/media/files/mnist_test.csv)
4.准备python的环境
0x02 程序代码
import numpy
import matplotlib.pyplot
import scipy.special
import json
class neuralNetwork:
def __init__(self,inputnodes,hiddennodes,outputnodes,learningrate):
#输入层的大小
self.inodes = inputnodes
#隐藏层的大小
self.hnodes = hiddennodes
#输出层的大小
self.onodes = outputnodes
#输入层与隐藏层之间的矩阵:输入(矩阵)*wih(矩阵) = hidden(隐藏层)
#numpy.random.normal生成一个指定大小(self.hnodes,self.inodes)的随机矩阵(满足正太分布,平均值为0,方均根为(hnode)^-0.5)
self.wih = numpy.random.normal(0.0,pow(self.hnodes,-0.5),(self.hnodes,self.inodes))
#输出层与隐藏层之间的矩阵:hidden(矩阵)*wih(矩阵) = 输出(矩阵)
self.who = numpy.random.normal(0.0,pow(self.onodes,-0.5),(self.onodes,self.hnodes))
#也可以直接简单粗暴的使用,因为产生的都是一个正数(0-1)所以-0.5调节了一下
#self.wih=numpy.random.rand(self.hnodes,self.inode)-0.5
#学习率
self.lr=learningrate
#模拟神经元的阈值
#expit为阈值函数:1/[1+e^(-x)]
self.activation_function = lambda x: scipy.special.expit(x)
pass
#查询函数(测试结果)
def query(self,inputs_list):
#进行转置:.T ndmin表示为2维矩阵
inputs = numpy.array(inputs_list,ndmin=2).T
#隐藏层: wih与inputs进行矩阵乘法
hidden_inputs = numpy.dot(self.wih,inputs)
#对隐藏层进行阈值函数归一化
hidden_outputs = self.activation_function(hidden_inputs)
#输出层: who与hidden_outputs进行矩阵乘法
final_inputs = numpy.dot(self.who , hidden_outputs)
#对输出进行阈值函数归一化
final_outputs = self.activation_function(final_inputs)
#返回结果
return final_inputs
#数据训练
def train(self,inputs_list,targets_list):
#inputs为748个元素的数列,不能直接转置
#进行二位矩阵转置
inputs = numpy.array(inputs_list,ndmin = 2).T
targets = numpy.array(targets_list,ndmin = 2).T
# hidden_inputs[h行,1] = wih[h行,i列] *inputs[i行,1列]
hidden_inputs = numpy.dot(self.wih,inputs)
# 进行归一化
hidden_outputs = self.activation_function(hidden_inputs)
# final_inputs[o行,1列] = who[o行,h列] * hidden_outputs[h行,1列]
final_inputs = numpy.dot(self.who , hidden_outputs)
# 对final进行阈值函数调整
final_outputs = self.activation_function(final_inputs)
# 计算输出层误差
output_errors = targets - final_outputs
# 计算隐藏层误差
hidden_errors = numpy.dot(self.who.T,output_errors)
# 调整隐藏层与输出层的黑盒矩阵
self.who += self.lr*numpy.dot((output_errors*final_outputs*(1.0-final_outputs)),numpy.transpose(hidden_outputs))
# 调整输入层与隐藏层的黑盒矩阵
self.wih += self.lr*numpy.dot((hidden_errors*hidden_outputs*(1.0-hidden_outputs)),numpy.transpose(inputs))
pass
# 输入的节点(28*28)
input_nodes = 784
# 隐藏节点(要小于784,表示机器要自己总结)
hidden_nodes = 200
# 输出节点数(数字只有0-9)10个
output_nodes = 10
# 学习率(每次修正的步长一般在0.1-0.3时比较理想)
learning_rate = 0.1
# 创建神经网络
n = neuralNetwork(input_nodes,hidden_nodes,output_nodes,learning_rate)
# 导入训练集
training_data_file = open("D:\\qjm\\numcheck\\mnist_train.csv",'r')
#training_data_file = open("/root/Desktop/numcheck/mnist_train.csv",'r')
#training_data_file = open("D:\\qjm\\numcheck\\mnist_train1.csv",'r')
training_data_list = training_data_file.readlines()
training_data_file.close
# 设置世代(重复训练的次数) 5次比较理想
epochs = 1
#epochs = 5
for e in range(epochs):
i=0
for record in training_data_list:
#print(training_data_list)
#print(record)
# 将数据进行分解 all_values 为 标签[0] +1维矩阵(1*748)[1:],但是都是字符类型
all_values = record.split(',')
# asfarray能把字符类型的转为数字类型
# all_values[1:])/255.0*0.99,将像素矩阵中的每个值进行(阈值函数)归一化
inputs = (numpy.asfarray(all_values[1:])/255.0*0.99)+0.01
# target 为标签 即为实际输出
# numpy.zeros(output_nodes)+0.01 生成一个 [0.01 0.01 *10]含有10个0.01的矩阵
targets = numpy.zeros(output_nodes)+0.01
# 将与标签位形同的那个设置为 0.99
targets[int(all_values[0])]=0.99
# 举例:
# 标签为 0 的实际输出为 [0.99 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01]
# 将这个像素与标签进行训练
n.train(inputs,targets)
print('e:',e,',i:',i)
i+=1
pass
pass
print(n.wih)
# 打开测试数据集
test_data_file = open("D:\\qjm\\numcheck\\mnist_test.csv",'r')
#training_data_file = open("/root/Desktop/numcheck/mnist_test.csv",'r')
test_data_list = test_data_file.readlines()
test_data_file.close()
# 成绩单
scorecard=[]
for record in test_data_list:
all_values = record.split(',')
correct_label = int(all_values[0])
inputs = (numpy.asfarray(all_values[1:])/255.0*0.99)+0.01
outputs = n.query(inputs)
# 取出最高的可能性
label = numpy.argmax(outputs)
# 如果网络算对了
if( label == correct_label):
# 那条记录就为正确
scorecard.append(1)
else:
# 否则就为错误
scorecard.append(0)
scorecard_array = numpy.asarray(scorecard)
print("performance = ", scorecard_array.sum()/scorecard_array.size)
0x03 一些小建议
- 本来是在windows下的pyCharm下运行的,但是没过多久,就爆出内存不足,pyCharm自动闪退,现在pycharm还打不开。所以建议在60000个训练集中选出100个作为副本,在写代码时进行测试。或者像我干脆直接用notepad++,配合cmd命令行,进行测试。
- 一开始追求完美,设置了5个世代,60000个测试集,发现程序能跑了,在我的电脑中,大约跑了15分钟,树莓派大约跑了40分钟。但是不幸的是,代码逻辑出了点问题,训练结果,正确率只有0.02%。猜测我的反馈没有写对,果然,出现了错误,但是为了防止还有其他的错误,建议测试的时候只设置1个世代,1万个数据。正确率至少高于90%。才是正确的代码。
- 如果正确率偏低,可能原因:
1. 反馈的信息没有写好。
2. 反馈的信息没有写好。
3. 输入(inputs)的信息没有写好(训练阶段)
4. 输入(inputs)的信息没有写好(测试阶段)
inputs = (numpy.asfarray(all_values[1:])/255.0*0.99)+0.01
-
我设置了1个世代,60000个数据进行训练,正确率达到95.92%。训练时间大约3分钟
 笔记本电脑的显示.png
笔记本电脑的显示.png -
同样的测试集,在树莓派中训练。(1个世代大约12分钟,正确率也有95.85%。)
可见不同的电脑,运行出来的矩阵不同。但是正确率是相仿的
命令:python3 shibie.py
 树莓派的显示.png
树莓派的显示.png 根据我的测量,
1.世代在 1-5 时,正确率呈现上升趋势。
2.学习率在 0.1-0.3 为高峰。
3.训练数据越多,结果会更好。
4.隐藏层节点越多,正确率越高。