原文链接:Architecting Android…The clean way?
在过去的几个月里,在Tuenti和同事@pedro_g_s和@flipper83(顺带一提,这两个都是Android开发高手)探讨之后,我觉得是时候写一篇关于构建Android应用架构方面的文章了。
本文的目的在于告诉你我过去几个月脑中的一些想法,还有我研究和实现后总结的一些资料。
Getting Started
我们知道编写高质量的软件很困难也很复杂:它不仅仅是符合需求,还要有鲁棒性、可维护、可测试和足够灵活,以适应代码增长和改变的需要。因此,我们提出了“the clean architecture“(清爽架构)的概念,它对于开发任何软件应用都是一个绝佳的方案。
这个概念很简单:clean architecture主张通过一系列的实践,来构建一个具备下面特性的系统:
- Independent of Frameworks(框架独立)
- Testable(可测试)
- Independent of UI(用户界面独立)
- Independent of Database(数据库独立)
- Independent of any external agency(所有外部代理独立)
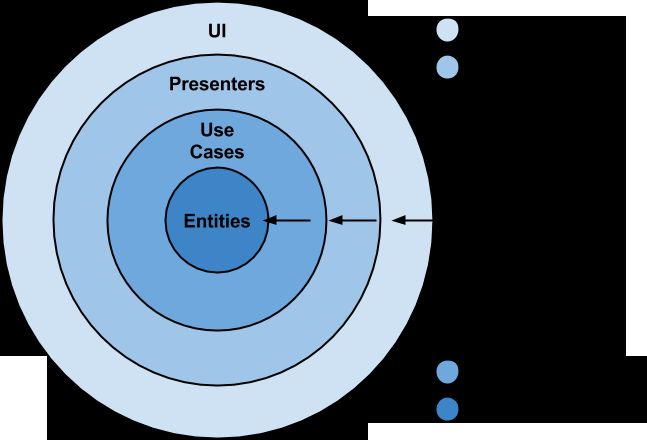
这并不是说一定只用这4层(如图所示),因为这张原理图只是要让你考虑Dependency Rule(依赖规则):源代码中的依赖只能指向里面,内圈代码必须对外圈的一无所知。
下面有一些相关的词汇能让你更好地熟悉和理解该方法:
- Entities:应用的业务对象所在
- Use Cases:协调数据从entities中流进流出。也可以叫Interactors。(备注:用例,就是一系列的步骤,典型地说就是用户为达到一种目的,与系统进行的交互)
- Interface Adapters:转换数据以方便use cases和entities使用。Presenters和Controllers都属于此处
- Frameworks and Drivers:细节处理,比如UI、tools、frameworks等等
更多更棒的解析,参见这篇文章和这个视频。
Our Scenario
我会从一个简单的方案开始讲起:一个简单的app,显示一个朋友或用户列表,数据从云端获取;当点击任意一项,会打开一个新界面,显示用户详情。
我录制了一个视频,这样你就可以对我谈论的东西有个大概了。
Android Architecture
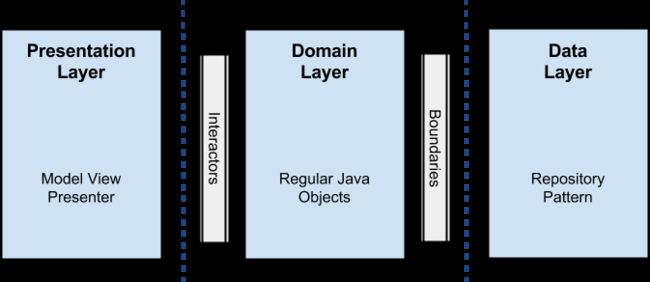
我们的目标是:通过让业务逻辑对外部世界一无所获来进行解耦,这样,业务逻辑就可以毫无依赖地使用外部元素进行测试了。为了达到该目的,我的解决方案是划分项目成3个不同的层次,每个层都有各自的功能,并且各自独立工作。
值得一提的是,每个层使用各自的数据模型(data model),因为这种独立是可达的(你可以在代码中有一个data mapper,它用来完成数据的转换,如果你不想在整个应用中交叉使用models的话是要支付一定的代价的)
看看下面的图就知道了:
注意:我没有使用任何外部类库(除了使用gson来解析json数据,使用junit、mockito、robolectric和espresso来测试)。这是为了让示例代码更清晰点。不管如何,你可以毫不犹豫地添加ORM进行数据存储或者任何依赖注入框架或者任何你熟悉的工具和类库,那样你的生活很更美好。(记住,不要重新造轮子)
Presentation Layer
这里放置的是关联视图和动画相关的逻辑代码。它不仅仅可以使用MVP模式(Model View Presenter),也可以使用MVC或MVVM。关于这点我不会展开来说。在这里,fragments和activities都只是views,里面没有任何逻辑,当然除了UI逻辑。所有需要渲染或展示的东西都在这里进行。
本层的Presenters由interactors(use cases)构成,在UI线程之外的新线程进行工作,然后通过回调将数据提供给view进行渲染或展示。

如果你在找一个使用MVP和MVVM的酷酷的案例,推荐看看我朋友 Pedro Gómez 写的
Effective Android UI。
Domain Layer
这里是业务逻辑层:所有的逻辑都在这里进行。环视整个android项目,你会发现所有的interactors(use cases)都是在这里实现的。
该层属于纯java模块,没有一丁点的android依赖。所有的外部组件(components)都是以接口形式跟business objects联系。
Data Layer
应用所需的所有数据都来自该层,通过一个UserRepository的实现(其接口在domain layer),使用一个存储库模式(Repository Pattern),使用这样的策略:通过一个工厂依赖于具体的条件,获取不同的数据。
例如,当需要通过id获取user,如果user已经存在于缓存中,那么将会从磁盘中缓存的数据源中获取;否则,从云端获取,然后再缓存到本地磁盘。
这一切背后的理念是数据源对于客户端透明,就是说客户端不用关心数据是从内存、磁盘还是云端获取的,只要知道数据终会被获取就行了。
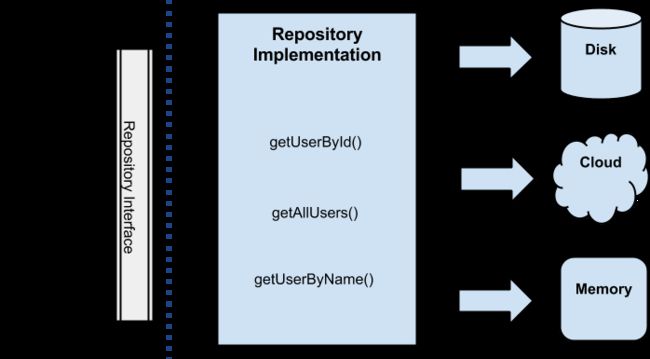
注意:在代码方面,我已经实现了一个非常简单和原始的磁盘缓存,使用的是文件系统和android preferences,仅仅是出于学习目的。再次提醒,如果已有类库可以搞定需求就不要重复造轮子。
Error Handling
这个话题仍在探讨中,如果你可以在这里分享下你的解决方案的话就更棒了。
我的策略是使用回调,因此,假如在data repository有事件发生,回调接口有两个方法onResponse()和onError()来进行处理。最后一个使用了一个叫“ErrorBundle”的包装类来封装异常:这种方法带来了一些困境,因为存在着一条直达显示层的回调链。代码可读性难以保证。
另一方面,我已经实现了一个事件总线系统,如果有错误发生会抛出一个事件。这个解决方案类似于GOTO。我的观点是,如果你订阅了多个事件而没有紧接着处理好的话,你会丢失一些事件。
Testing
关注于测试,我根据各个层的特点选择了几个解决方案:
- Presentation Layer:使用android instrumentation和espresso进行综合测试和功能测试
- Domain Layer:使用JUnit+mockito进行单元测试
- Data Layer:Robolectric(因为该层有android依赖)+ JUnit + mockito进行综合和单元测试
Show me the code
我知道你一定想知道代码放哪里了,对吧?诺,这里有个github链接,我代码都放上面了。关于其中的文件结构,我要说几句,不同的层表示的使用的模块如下:
- presentation:属于android 模块,代表presenttation层
- domain:属于java模块,没有android依赖
- data:属于android模块,数据源
- data-test:data层的测试代码。由于使用Robolectric的一些限制,我不得不独立出一个java模块
Conclusion
正如Uncle Bob说的 "Architecture is About Intent, not Frameworks" ,我完全同意这种说法。当然,达到目的的途径有很多且各异(不同的实现),我们每天都面临着许许多多的挑战。但是,通过使用该技术,你可以确保你的应用:
- 易于维护
- 易于测试
- 高内聚
- 低耦合
总而言之,我强烈推荐你试一下,然后把你的结果和经历分享出来,包括你发现的其他更好的方法:我们知道持续改进是一件非常棒喝积极的事。
我希望本文对于有所裨益,并且我一如既往地欢迎任何反馈。
Source code
- Clean architecture github repository – master branch
- Clean architecture github repository – releases
Further reading:
- Architecting Android..the evolution
- Tasting Dagger 2 on Android
- The Mayans Lost Guide to RxJava on Android
- It is about philosophy: Culture of a good programmer
Links and Resources
- The clean architecture by Uncle Bob
- Architecture is about Intent, not Frameworks
- Model View Presenter
- Repository Pattern by Martin Fowler
- Android Design Patterns Presentation