爬虫的基本概念
关于爬虫的基本概念, 推荐博客https://xlzd.me/ 里面关于爬虫的介绍非常通俗易懂.
简单地说,在我们输入网址后到可以浏览网页,中间浏览器做了很多工作, 这里面涉及到两个概念:
- IP地址: IP地址是你在网络上的地址,大部分情况下它的表示是一串类似于192.168.1.1的数字串。访问网址的时候,事实上就是向这个IP地址请求了一堆数据。
- DNS服务器: 而DNS服务器则是记录IP到域名映射关系的服务器,爬虫在很大层次上不关系这一步的过程。一般浏览器并不会直接向DNS服务器查询的IP,这个过程要复杂的多,包括向浏览器自己、hosts文件等很多地方先查找一次,上面的说法只是一个统称。
浏览器得到IP地址之后,浏览器就会向这个地址发送一个HTTP请求。然后从网站的服务器端请求到了首页的HTML源码,然后通过浏览器引擎解析源码,再次向服务器发请求得到里面引用过的Javascript、CSS、图片等资源,得到了网页浏览时的样子。
搭建实验环境
import requests # 网页下载工具
from bs4 import BeautifulSoup # 分析网页数据的工具
import re # 正则表达式,用于数据清洗\整理等工作
import os # 系统模块,用于创建结果文件保存等
import codecs # 用于创建结果文件并写入
2 爬虫的实现
编写爬虫之前,我们需要先思考爬虫需要干什么、目标网站有什么特点,以及根据目标网站的数据量和数据特点选择合适的架构。
推荐使用Chrome的开发者工具来观察网页结构。对应的快捷键是"F12"。
右键选择检查(inspect)即可查看选中条目的HTML结构。
一般,浏览器在向服务器发送请求的时候,会有一个请求头——User-Agent,它用来标识浏览器的类型.
如果是python代码直接爬,发送默认的User-Agent是python-requests/[版本号数字]
这时可能会请求失败,因为服务器会设置通过校验请求的U-A来识别爬虫,通过模拟浏览器的U-A,能够很轻松地绕过这个问题。
设置Use-Agent请求头, 在代码'User-Agent':后就是虚拟的浏览器请求头.
def fetch_html(url_link):
html = requests.get(url_link,
headers={'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'}).content
return html
DOWNLOAD_URL = 'http://usefulenglish.ru/phrases/'
html = fetch_html(DOWNLOAD_URL)
上面这段代码可以将url_link中网址的页面信息全部下载到变量html中.
之后调用Beautifulsoup解析html中的数据.
#!/usr/bin/python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html_doc)
print soup.title # 输出:The Dormouse's story
print soup.title.name # 输出:title
print soup.title.string # 输出: The Dormouse's story
print soup.p # 输出: The Dormouse's story
print soup.a # 输出:Elsie
print soup.find_all('a')
print soup.find(id='link3')
print soup.get_text()
soup 就是BeautifulSoup处理格式化后的字符串
soup.title得到的是title标签
soup.p 得到的是文档中的第一个p标签
soup.find_all(‘p’) 遍历树, 得到所有的标签’p’匹配结果
get_text() 是返回文本, 其实是可以获得标签的其他属性的,比如要获得a标签的href属性的值,可以使用 print soup.a['href'],类似的其他属性,比如class也可以这么得到: soup.a['class'])
用Beautifulsoup解析html文件, 就可以获得需要的网址\数据等文件. 下面这段代码是用来获取字段中的url链接的:
def findLinks(htmlString):
"""
搜索htmlString中所有的有效链接地址,方便下次继续使用
htmlString = ‘Lacie'类似的字符串
"""
linkPattern = re.compile("(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')")
return linkPattern.findall(htmlString)
正则表达式
实际使用中,用Beautifulsoup应该可以处理绝大多数需求,但是如果需要对爬去下来的数据再进一步分析的话,就要用到正则表达式了.
大多数符号在正则表达式中都有特别的含义,所以要作为匹配模式的话,就必须要用\符号转义.例如搜索'/a', 对应的正则表达式是'/a'
[]代表匹配里面的字符中的任意一个
[^]代表除了内部包含的字符以外都能匹配,例如pattern1 = re.compile("[^p]at")#这代表除了p以外都匹配
正则表达式中()内的部分是通过匹配提取的字段.
基本用法,例如得到的url字符串后,需要截取最后一个/符号后的字段作为保存的文件名:
topic_url='http://usefulenglish.ru/phrases/bus-taxi-train-plane'
filename_pattern=re.compile('.*\/(.*)$')
filename = filename_pattern.findall(topic_url)[0]+'.txt'
得到:
filename = 'bus-taxi-train-plane.txt'
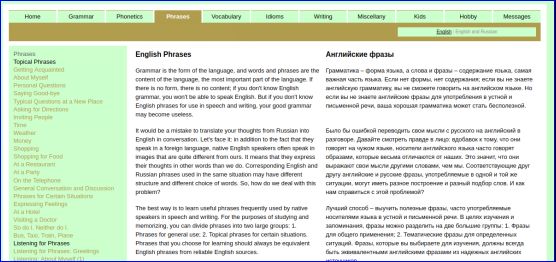
最后给出完整代码. 这段代码实现了对英文学习网站()中phrase栏目下日常口语短语的提取.代码的功能主要分为两部分:
1)解析侧边栏条目的url地址, 保存在url_list中
2)下载url_list中网页正文列表中的英文句子.
网站页面如下:
import requests
from bs4 import BeautifulSoup
import re
import os
import codecs
def findLinks(htmlString):
"""
搜索htmlString中所有的有效链接地址,方便下次继续使用
"""
linkPattern = re.compile("(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')")
return linkPattern.findall(htmlString)
def fetch_html(url_link):
html = requests.get(url_link,
headers={'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'}).content
return html
DOWNLOAD_URL = 'http://usefulenglish.ru/phrases/'
html = fetch_html(DOWNLOAD_URL)
soup = BeautifulSoup(html, "lxml")
side_soup = soup.find('div', attrs={'id': 'sidebar'})
url_pattern = re.compile('^[\附录: 正则表达式
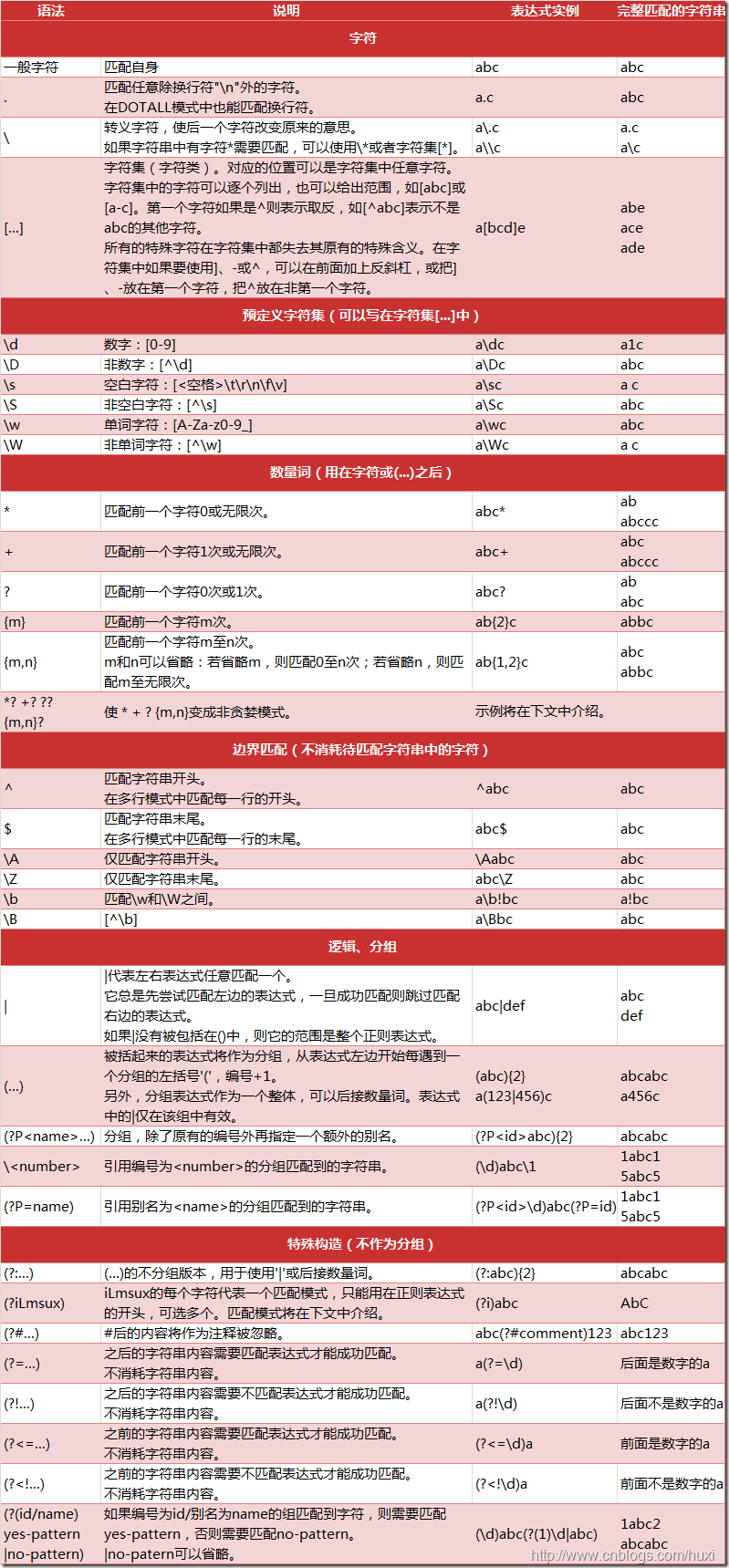
参考:
使用request爬:https://zhuanlan.zhihu.com/p/20410446
爬豆瓣电影top250(网页列表中的数据):
https://xlzd.me/2015/12/16/python-crawler-03
Beautifulsoup使用方法详解: http://www.jb51.net/article/43572.htm
Beautifulsoup官网文档: https://www.crummy.com/software/BeautifulSoup/bs4/doc/
http://www.169it.com/article/9913111281939258943.html
Python正则表达式:
http://www.runoob.com/python/python-reg-expressions.html
http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html