go GC 的基本特征是非分代、非紧缩、写屏障、并发标记清理。核心是抑制堆增长,充分利用CPU资源。
1. 三色标记
是指并发(垃圾回收和用户逻辑并发执行)的对系统中的对象进行颜色标记,然后根据颜色将对象进行清理。基本原理:
- 起初将堆上所有对象都标记为白色;
- 从底部开始遍历对象,将遍历到的白色对象标记为灰色,放入待处理队列;
- 遍历灰色对象,把灰色对像所引用的白色对象也标记为灰色,将原灰色对象本身标记为黑色;
- 循环执行上一步,直至原灰色对象全部标记为黑色;
步骤4结束后,标记为白色的对象就是不可达对象,就是垃圾对象,可以进行回收。
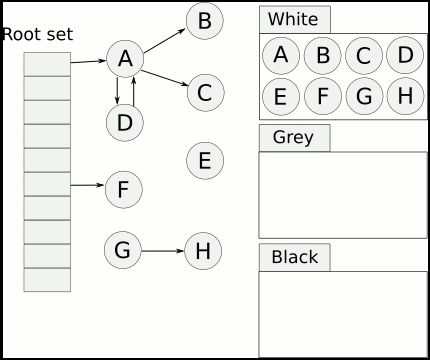
最后white的对象都会被清理掉
写屏障
在进行三色标记的时候并没有STW,也就是说,此时的对象还是可以进行修改;考虑这样一种情况,在进行三色标记扫描灰色对象时,扫描到了对象A,并标记了对象A的所有引用,当开始扫描对象D的引用时,另一个goroutine修改了D->E的引用,变成了A->E的引用,就会导致E对象扫描不到而一直是白对象,就会被误认为是垃圾。写屏障就是为了解决这样的问题,引入写屏障后,在A->E后,E会被认为是存活的,即使后面E被A对象抛弃,E只会被在下一轮的GC中进行回收,这一轮GC不会回收对象E。
写屏障监视对象内存修改,重新标色或放回队列。
Go1.9中开始启用了混合写屏障,伪代码如下:
1 writePointer(slot, ptr): 2 shade(*slot) 3 if any stack is grey: 4 shade(ptr) 5 *slot = ptr
混合写屏障会同时标记指针写入目标的"原指针"和“新指针"。
标记原指针的原因是, 其他运行中的线程有可能会同时把这个指针的值复制到寄存器或者栈上的本地变量,因为复制指针到寄存器或者栈上的本地变量不会经过写屏障, 所以有可能会导致指针不被标记,标记新指针的原因是, 其他运行中的线程有可能会转移指针的位置。
混合写屏障可以让GC在并行标记结束后不需要重新扫描各个G的堆栈, 可以减少Mark Termination中的STW时间。
除了写屏障外, 在GC的过程中所有新分配的对象都会立刻变为黑色。
控制器
控制器全程参与并发回收任务,记录相关状态数据,动态调整运行策略,影响并发标记单元的工作模式和数量,平衡CPU资源占用。回收结束时参与next_gc回收阈值设定,调整垃圾回收触发频率。
//mgc.go
1 // gcController implements the GC pacing controller that determines 2 // when to trigger concurrent garbage collection and how much marking 3 // work to do in mutator assists and background marking. 4 // 5 // It uses a feedback control algorithm to adjust the memstats.gc_trigger 6 // trigger based on the heap growth and GC CPU utilization each cycle. 7 // This algorithm optimizes for heap growth to match GOGC and for CPU 8 // utilization between assist and background marking to be 25% of 9 // GOMAXPROCS. The high-level design of this algorithm is documented 10 // at https://golang.org/s/go15gcpacing. 11 // 12 // All fields of gcController are used only during a single mark 13 // cycle. 14 15 //GC controller实现GC起搏控制器,该控制器确定何时触发并发垃圾收集,以及在mutator协助和后台标记中要做多少标记工作。 16 // 17 //它使用反馈控制算法根据堆增长和每个周期的gc CPU利用率调整memstats.gc_触发器。 18 //该算法优化堆增长以匹配GOGC,并优化辅助和后台标记之间的CPU利用率为GOMAXPROCS的25%。该算法的高级设计在https://golang.org/s/go15gcpacking上有文档记录。 19 // 20 //gcController的所有字段只在一个标记周期内使用。
辅助回收
当对象回收速递远快于后台标记,会引发堆恶性扩张等恶果,甚至是使垃圾回收永远也无法完成,此时让用户代码线程参与后台标记回收非常有必要,为对象分配堆内存时,通过相关策略去执行一定限度的回收操作,平衡分配和回收操作,让进程处于良性状态。
2. 初始化
初始化过程中,重点是设置 gcpercent 和 next_gc
//mgc.go
1 // Initialized from $GOGC. GOGC=off means no GC. 2 var gcpercent int32 3 4 func gcinit() { 5 if unsafe.Sizeof(workbuf{}) != _WorkbufSize { 6 throw("size of Workbuf is suboptimal") 7 } 8 9 // No sweep on the first cycle. 10 mheap_.sweepdone = 1 11 12 // Set a reasonable initial GC trigger. 13 memstats.triggerRatio = 7 / 8.0 14 15 // Fake a heap_marked value so it looks like a trigger at 16 // heapminimum is the appropriate growth from heap_marked. 17 // This will go into computing the initial GC goal. 18 memstats.heap_marked = uint64(float64(heapminimum) / (1 + memstats.triggerRatio)) 19 20 // Set gcpercent from the environment. This will also compute 21 // and set the GC trigger and goal. 22 //设置GOGC 23 _ = setGCPercent(readgogc()) 24 25 work.startSema = 1 26 work.markDoneSema = 1 27 } 28 29 func readgogc() int32 { 30 p := gogetenv("GOGC") 31 if p == "off" { 32 return -1 33 } 34 if n, ok := atoi32(p); ok { 35 return n 36 } 37 return 100 38 } 39 40 // gcenable is called after the bulk of the runtime initialization, 41 // just before we're about to start letting user code run. 42 // It kicks off the background sweeper goroutine and enables GC. 43 func gcenable() { 44 c := make(chan int, 1) 45 go bgsweep(c) 46 <-c 47 memstats.enablegc = true // now that runtime is initialized, GC is okay 48 } 49 50 //go:linkname setGCPercent runtime/debug.setGCPercent 51 func setGCPercent(in int32) (out int32) { 52 lock(&mheap_.lock) 53 out = gcpercent 54 if in < 0 { 55 in = -1 56 } 57 gcpercent = in 58 heapminimum = defaultHeapMinimum * uint64(gcpercent) / 100 59 // Update pacing in response to gcpercent change. 60 gcSetTriggerRatio(memstats.triggerRatio) 61 unlock(&mheap_.lock) 62 63 // If we just disabled GC, wait for any concurrent GC mark to 64 // finish so we always return with no GC running. 65 if in < 0 { 66 gcWaitOnMark(atomic.Load(&work.cycles)) 67 } 68 69 return out 70 }
启动
在为对象分配堆内存后,mallocgc函数会检查垃圾回收触发条件,并依照相关状态启动或参与辅助回收。
malloc.go
1 // Allocate an object of size bytes. 2 // Small objects are allocated from the per-P cache's free lists. 3 // Large objects (> 32 kB) are allocated straight from the heap. 4 func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer { 5 if gcphase == _GCmarktermination { 6 throw("mallocgc called with gcphase == _GCmarktermination") 7 } 8 9 // ... 10 11 // assistG is the G to charge for this allocation, or nil if 12 // GC is not currently active. 13 var assistG *g 14 if gcBlackenEnabled != 0 { 15 //让出资源 16 // Charge the current user G for this allocation. 17 assistG = getg() 18 if assistG.m.curg != nil { 19 assistG = assistG.m.curg 20 } 21 // Charge the allocation against the G. We'll account 22 // for internal fragmentation at the end of mallocgc. 23 assistG.gcAssistBytes -= int64(size) 24 25 if assistG.gcAssistBytes < 0 { 26 //辅助参与回收任务 27 // This G is in debt. Assist the GC to correct 28 // this before allocating. This must happen 29 // before disabling preemption. 30 gcAssistAlloc(assistG) 31 } 32 } 33 34 // Set mp.mallocing to keep from being preempted by GC. 35 mp := acquirem() 36 if mp.mallocing != 0 { 37 throw("malloc deadlock") 38 } 39 if mp.gsignal == getg() { 40 throw("malloc during signal") 41 } 42 mp.mallocing = 1 43 44 shouldhelpgc := false 45 dataSize := size 46 c := gomcache() 47 var x unsafe.Pointer 48 noscan := typ == nil || typ.kind&kindNoPointers != 0 49 50 //判断对象大小 51 //…… 52 53 // Allocate black during GC. 54 // All slots hold nil so no scanning is needed. 55 // This may be racing with GC so do it atomically if there can be 56 // a race marking the bit. 57 if gcphase != _GCoff { 58 //直接分配黑色对象 59 gcmarknewobject(uintptr(x), size, scanSize) 60 } 61 62 if assistG != nil { 63 // Account for internal fragmentation in the assist 64 // debt now that we know it. 65 assistG.gcAssistBytes -= int64(size - dataSize) 66 } 67 //检查垃圾回收触发条件 68 if shouldhelpgc { 69 //启动并发垃圾回收 70 if t := (gcTrigger{kind: gcTriggerHeap}); t.test() { 71 gcStart(t) 72 } 73 } 74 75 return x 76 }
垃圾回收默认以全并发模式运行,但可以用环境变量参数或参数禁用并发标记和并发清理。GC goroutine一直循环,直到符合触发条件时被唤醒。
gcStart
//mgc.go
1 func gcStart(mode gcMode, trigger gcTrigger) { 2 // Since this is called from malloc and malloc is called in 3 // the guts of a number of libraries that might be holding 4 // locks, don't attempt to start GC in non-preemptible or 5 // potentially unstable situations. 6 // 判断当前g是否可以抢占,不可抢占时不触发GC 7 mp := acquirem() 8 if gp := getg(); gp == mp.g0 || mp.locks > 1 || mp.preemptoff != "" { 9 releasem(mp) 10 return 11 } 12 releasem(mp) 13 mp = nil 14 15 // Pick up the remaining unswept/not being swept spans concurrently 16 // 17 // This shouldn't happen if we're being invoked in background 18 // mode since proportional sweep should have just finished 19 // sweeping everything, but rounding errors, etc, may leave a 20 // few spans unswept. In forced mode, this is necessary since 21 // GC can be forced at any point in the sweeping cycle. 22 // 23 // We check the transition condition continuously here in case 24 // this G gets delayed in to the next GC cycle. 25 // 清扫 残留的未清扫的垃圾 26 for trigger.test() && gosweepone() != ^uintptr(0) { 27 sweep.nbgsweep++ 28 } 29 30 // Perform GC initialization and the sweep termination 31 // transition. 32 semacquire(&work.startSema) 33 // Re-check transition condition under transition lock. 34 // 判断gcTrriger的条件是否成立 35 if !trigger.test() { 36 semrelease(&work.startSema) 37 return 38 } 39 40 // For stats, check if this GC was forced by the user 41 // 判断并记录GC是否被强制执行的,runtime.GC()可以被用户调用并强制执行 42 work.userForced = trigger.kind == gcTriggerAlways || trigger.kind == gcTriggerCycle 43 44 // In gcstoptheworld debug mode, upgrade the mode accordingly. 45 // We do this after re-checking the transition condition so 46 // that multiple goroutines that detect the heap trigger don't 47 // start multiple STW GCs. 48 // 设置gc的mode 49 if mode == gcBackgroundMode { 50 if debug.gcstoptheworld == 1 { 51 mode = gcForceMode 52 } else if debug.gcstoptheworld == 2 { 53 mode = gcForceBlockMode 54 } 55 } 56 57 // Ok, we're doing it! Stop everybody else 58 semacquire(&worldsema) 59 60 if trace.enabled { 61 traceGCStart() 62 } 63 64 // Check that all Ps have finished deferred mcache flushes.
// 启动后台标记任务
67 // 重置gc 标记相关的状态 68 gcResetMarkState() 69 70 work.stwprocs, work.maxprocs = gomaxprocs, gomaxprocs 71 if work.stwprocs > ncpu { 72 // This is used to compute CPU time of the STW phases, 73 // so it can't be more than ncpu, even if GOMAXPROCS is. 74 work.stwprocs = ncpu 75 } 76 work.heap0 = atomic.Load64(&memstats.heap_live) 77 work.pauseNS = 0 78 work.mode = mode 79 80 now := nanotime() 81 work.tSweepTerm = now 82 work.pauseStart = now 83 if trace.enabled { 84 traceGCSTWStart(1) 85 } 86 // STW,停止世界 87 systemstack(stopTheWorldWithSema) 88 // Finish sweep before we start concurrent scan. 89 // 先清扫上一轮的垃圾,确保上轮GC完成 90 systemstack(func() { 91 finishsweep_m() 92 }) 93 // clearpools before we start the GC. If we wait they memory will not be 94 // reclaimed until the next GC cycle. 95 // 清理 sync.pool sched.sudogcache、sched.deferpool,这里不展开,sync.pool已经说了,剩余的后面的文章会涉及 96 clearpools() 97 98 // 增加GC技术 99 work.cycles++ 100 if mode == gcBackgroundMode { // Do as much work concurrently as possible 101 gcController.startCycle() 102 work.heapGoal = memstats.next_gc 103 104 // Enter concurrent mark phase and enable 105 // write barriers. 106 // 107 // Because the world is stopped, all Ps will 108 // observe that write barriers are enabled by 109 // the time we start the world and begin 110 // scanning. 111 // 112 // Write barriers must be enabled before assists are 113 // enabled because they must be enabled before 114 // any non-leaf heap objects are marked. Since 115 // allocations are blocked until assists can 116 // happen, we want enable assists as early as 117 // possible. 118 // 设置GC的状态为 gcMark 119 setGCPhase(_GCmark) 120 121 // 更新 bgmark 的状态 122 gcBgMarkPrepare() // Must happen before assist enable. 123 // 计算并排队root 扫描任务,并初始化相关扫描任务状态 124 gcMarkRootPrepare() 125 126 // Mark all active tinyalloc blocks. Since we're 127 // allocating from these, they need to be black like 128 // other allocations. The alternative is to blacken 129 // the tiny block on every allocation from it, which 130 // would slow down the tiny allocator. 131 // 标记 tiny 对象 132 gcMarkTinyAllocs() 133 134 // At this point all Ps have enabled the write 135 // barrier, thus maintaining the no white to 136 // black invariant. Enable mutator assists to 137 // put back-pressure on fast allocating 138 // mutators. 139 // 设置 gcBlackenEnabled 为 1,启用写屏障 140 atomic.Store(&gcBlackenEnabled, 1) 141 142 // Assists and workers can start the moment we start 143 // the world. 144 gcController.markStartTime = now 145 146 // Concurrent mark. 147 systemstack(func() { 148 now = startTheWorldWithSema(trace.enabled) 149 }) 150 work.pauseNS += now - work.pauseStart 151 work.tMark = now 152 } else { 153 // 非并行模式 154 // 记录完成标记阶段的开始时间 155 if trace.enabled { 156 // Switch to mark termination STW. 157 traceGCSTWDone() 158 traceGCSTWStart(0) 159 } 160 t := nanotime() 161 work.tMark, work.tMarkTerm = t, t 162 work.heapGoal = work.heap0 163 164 // Perform mark termination. This will restart the world. 165 // stw,进行标记,清扫并start the world 166 gcMarkTermination(memstats.triggerRatio) 167 } 168 169 semrelease(&work.startSema) 170 }
4. 并发标记
- 扫描:遍历相关内存区域,依照指针标记找出灰色可达对象,加入队列;
- 标记:将灰色对象从队列取出,将其引用对象标记为灰色,自身标记为黑色。
gcBgMarkStartWorkers
这个函数准备一些 执行bg mark工作的mark worker goroutine,但是这些goroutine并不是立即工作的,它们在回收任务开始前被绑定到P,然后进入休眠状态,等到GC的状态被标记为gcMark 才被调度器唤醒,开始工作。
1 func gcBgMarkStartWorkers() { 2 // Background marking is performed by per-P G's. Ensure that 3 // each P has a background GC G. 4 for _, p := range allp { 5 if p.gcBgMarkWorker == 0 { 6 go gcBgMarkWorker(p) 7 // 等待gcBgMarkWorker goroutine 的 bgMarkReady信号再继续 8 notetsleepg(&work.bgMarkReady, -1) 9 noteclear(&work.bgMarkReady) 10 } 11 } 12 }
MarkWorker有三种工作模式:
- gcMark Worker DedicateMode:全力运行,直到并发标记任务结束;
- gcMark WorkerFractionMode:参与标记任务但可被抢占和调度;
- gcMark WorkerIdleMode:仅在空闲时参与标记任务。
gcBgMarkWorker
后台标记任务的函数,不同模式的Mark Worker 对待工作的态度完全不同。
1 func gcBgMarkWorker(_p_ *p) { 2 gp := getg() 3 // 用于休眠结束后重新获取p和m 4 type parkInfo struct { 5 m muintptr // Release this m on park. 6 attach puintptr // If non-nil, attach to this p on park. 7 } 8 // We pass park to a gopark unlock function, so it can't be on 9 // the stack (see gopark). Prevent deadlock from recursively 10 // starting GC by disabling preemption. 11 gp.m.preemptoff = "GC worker init" 12 park := new(parkInfo) 13 gp.m.preemptoff = "" 14 // 设置park的m和p的信息,留着后面传给gopark,在被gcController.findRunnable唤醒的时候,便于找回 15 park.m.set(acquirem()) 16 park.attach.set(_p_) 17 // Inform gcBgMarkStartWorkers that this worker is ready. 18 // After this point, the background mark worker is scheduled 19 // cooperatively by gcController.findRunnable. Hence, it must 20 // never be preempted, as this would put it into _Grunnable 21 // and put it on a run queue. Instead, when the preempt flag 22 // is set, this puts itself into _Gwaiting to be woken up by 23 // gcController.findRunnable at the appropriate time. 24 // 让gcBgMarkStartWorkers notetsleepg停止等待并继续及退出 25 notewakeup(&work.bgMarkReady) 26 27 for { 28 // Go to sleep until woken by gcController.findRunnable. 29 // We can't releasem yet since even the call to gopark 30 // may be preempted. 31 // 让g进入休眠 32 gopark(func(g *g, parkp unsafe.Pointer) bool { 33 park := (*parkInfo)(parkp) 34 35 // The worker G is no longer running, so it's 36 // now safe to allow preemption. 37 // 释放当前抢占的m 38 releasem(park.m.ptr()) 39 40 // If the worker isn't attached to its P, 41 // attach now. During initialization and after 42 // a phase change, the worker may have been 43 // running on a different P. As soon as we 44 // attach, the owner P may schedule the 45 // worker, so this must be done after the G is 46 // stopped. 47 // 设置关联p,上面已经设置过了 48 if park.attach != 0 { 49 p := park.attach.ptr() 50 park.attach.set(nil) 51 // cas the worker because we may be 52 // racing with a new worker starting 53 // on this P. 54 if !p.gcBgMarkWorker.cas(0, guintptr(unsafe.Pointer(g))) { 55 // The P got a new worker. 56 // Exit this worker. 57 return false 58 } 59 } 60 return true 61 }, unsafe.Pointer(park), waitReasonGCWorkerIdle, traceEvGoBlock, 0) 62 63 // Loop until the P dies and disassociates this 64 // worker (the P may later be reused, in which case 65 // it will get a new worker) or we failed to associate. 66 // 检查P的gcBgMarkWorker是否和当前的G一致, 不一致时结束当前的任务 67 if _p_.gcBgMarkWorker.ptr() != gp { 68 break 69 } 70 71 // Disable preemption so we can use the gcw. If the 72 // scheduler wants to preempt us, we'll stop draining, 73 // dispose the gcw, and then preempt. 74 // gopark第一个函数中释放了m,这里再抢占回来 75 park.m.set(acquirem()) 76 77 if gcBlackenEnabled == 0 { 78 throw("gcBgMarkWorker: blackening not enabled") 79 } 80 81 startTime := nanotime() 82 // 设置gcmark的开始时间 83 _p_.gcMarkWorkerStartTime = startTime 84 85 decnwait := atomic.Xadd(&work.nwait, -1) 86 if decnwait == work.nproc { 87 println("runtime: work.nwait=", decnwait, "work.nproc=", work.nproc) 88 throw("work.nwait was > work.nproc") 89 } 90 // 切换到g0工作 91 systemstack(func() { 92 // Mark our goroutine preemptible so its stack 93 // can be scanned. This lets two mark workers 94 // scan each other (otherwise, they would 95 // deadlock). We must not modify anything on 96 // the G stack. However, stack shrinking is 97 // disabled for mark workers, so it is safe to 98 // read from the G stack. 99 // 设置G的状态为waiting,以便于另一个g扫描它的栈(两个g可以互相扫描对方的栈) 100 casgstatus(gp, _Grunning, _Gwaiting) 101 switch _p_.gcMarkWorkerMode { 102 default: 103 throw("gcBgMarkWorker: unexpected gcMarkWorkerMode") 104 case gcMarkWorkerDedicatedMode: 105 // 专心执行标记工作的模式 106 gcDrain(&_p_.gcw, gcDrainUntilPreempt|gcDrainFlushBgCredit) 107 if gp.preempt { 108 // 被抢占了,把所有本地运行队列中的G放到全局运行队列中 109 // We were preempted. This is 110 // a useful signal to kick 111 // everything out of the run 112 // queue so it can run 113 // somewhere else. 114 lock(&sched.lock) 115 for { 116 gp, _ := runqget(_p_) 117 if gp == nil { 118 break 119 } 120 globrunqput(gp) 121 } 122 unlock(&sched.lock) 123 } 124 // Go back to draining, this time 125 // without preemption. 126 // 继续执行标记工作 127 gcDrain(&_p_.gcw, gcDrainNoBlock|gcDrainFlushBgCredit) 128 case gcMarkWorkerFractionalMode: 129 // 执行标记工作,知道被抢占 130 gcDrain(&_p_.gcw, gcDrainFractional|gcDrainUntilPreempt|gcDrainFlushBgCredit) 131 case gcMarkWorkerIdleMode: 132 // 空闲的时候执行标记工作 133 gcDrain(&_p_.gcw, gcDrainIdle|gcDrainUntilPreempt|gcDrainFlushBgCredit) 134 } 135 // 把G的waiting状态转换到runing状态 136 casgstatus(gp, _Gwaiting, _Grunning) 137 }) 138 139 // If we are nearing the end of mark, dispose 140 // of the cache promptly. We must do this 141 // before signaling that we're no longer 142 // working so that other workers can't observe 143 // no workers and no work while we have this 144 // cached, and before we compute done. 145 // 及时处理本地缓存,上交到全局的队列中 146 if gcBlackenPromptly { 147 _p_.gcw.dispose() 148 } 149 150 // Account for time. 151 // 累加耗时 152 duration := nanotime() - startTime 153 switch _p_.gcMarkWorkerMode { 154 case gcMarkWorkerDedicatedMode: 155 atomic.Xaddint64(&gcController.dedicatedMarkTime, duration) 156 atomic.Xaddint64(&gcController.dedicatedMarkWorkersNeeded, 1) 157 case gcMarkWorkerFractionalMode: 158 atomic.Xaddint64(&gcController.fractionalMarkTime, duration) 159 atomic.Xaddint64(&_p_.gcFractionalMarkTime, duration) 160 case gcMarkWorkerIdleMode: 161 atomic.Xaddint64(&gcController.idleMarkTime, duration) 162 } 163 164 // Was this the last worker and did we run out 165 // of work? 166 incnwait := atomic.Xadd(&work.nwait, +1) 167 if incnwait > work.nproc { 168 println("runtime: p.gcMarkWorkerMode=", _p_.gcMarkWorkerMode, 169 "work.nwait=", incnwait, "work.nproc=", work.nproc) 170 throw("work.nwait > work.nproc") 171 } 172 173 // If this worker reached a background mark completion 174 // point, signal the main GC goroutine. 175 if incnwait == work.nproc && !gcMarkWorkAvailable(nil) { 176 // Make this G preemptible and disassociate it 177 // as the worker for this P so 178 // findRunnableGCWorker doesn't try to 179 // schedule it. 180 // 取消p m的关联 181 _p_.gcBgMarkWorker.set(nil) 182 releasem(park.m.ptr()) 183 184 gcMarkDone() 185 186 // Disable preemption and prepare to reattach 187 // to the P. 188 // 189 // We may be running on a different P at this 190 // point, so we can't reattach until this G is 191 // parked. 192 park.m.set(acquirem()) 193 park.attach.set(_p_) 194 } 195 } 196 }
gcDrain
三色标记的主要实现
gcDrain扫描所有的roots和对象,并表黑灰色对象,知道所有的roots和对象都被标记
1 func gcDrain(gcw *gcWork, flags gcDrainFlags) { 2 if !writeBarrier.needed { 3 throw("gcDrain phase incorrect") 4 } 5 6 gp := getg().m.curg 7 // 看到抢占标识是否要返回 8 preemptible := flags&gcDrainUntilPreempt != 0 9 // 没有任务时是否要等待任务 10 blocking := flags&(gcDrainUntilPreempt|gcDrainIdle|gcDrainFractional|gcDrainNoBlock) == 0 11 // 是否计算后台的扫描量来减少辅助GC和唤醒等待中的G 12 flushBgCredit := flags&gcDrainFlushBgCredit != 0 13 // 是否在空闲的时候执行标记任务 14 idle := flags&gcDrainIdle != 0 15 // 记录初始的已经执行过的扫描任务 16 initScanWork := gcw.scanWork 17 18 // checkWork is the scan work before performing the next 19 // self-preempt check. 20 // 设置对应模式的工作检查函数 21 checkWork := int64(1<<63 - 1) 22 var check func() bool 23 if flags&(gcDrainIdle|gcDrainFractional) != 0 { 24 checkWork = initScanWork + drainCheckThreshold 25 if idle { 26 check = pollWork 27 } else if flags&gcDrainFractional != 0 { 28 check = pollFractionalWorkerExit 29 } 30 } 31 32 // Drain root marking jobs. 33 // 如果root对象没有扫描完,则扫描 34 if work.markrootNext < work.markrootJobs { 35 for !(preemptible && gp.preempt) { 36 job := atomic.Xadd(&work.markrootNext, +1) - 1 37 if job >= work.markrootJobs { 38 break 39 } 40 // 执行root扫描任务 41 markroot(gcw, job) 42 if check != nil && check() { 43 goto done 44 } 45 } 46 } 47 48 // Drain heap marking jobs. 49 // 循环直到被抢占 50 for !(preemptible && gp.preempt) { 51 // Try to keep work available on the global queue. We used to 52 // check if there were waiting workers, but it's better to 53 // just keep work available than to make workers wait. In the 54 // worst case, we'll do O(log(_WorkbufSize)) unnecessary 55 // balances. 56 if work.full == 0 { 57 // 平衡工作,如果全局的标记队列为空,则分一部分工作到全局队列中 58 gcw.balance() 59 } 60 61 var b uintptr 62 if blocking { 63 b = gcw.get() 64 } else { 65 b = gcw.tryGetFast() 66 if b == 0 { 67 b = gcw.tryGet() 68 } 69 } 70 // 获取任务失败,跳出循环 71 if b == 0 { 72 // work barrier reached or tryGet failed. 73 break 74 } 75 // 扫描获取的到对象 76 scanobject(b, gcw) 77 78 // Flush background scan work credit to the global 79 // account if we've accumulated enough locally so 80 // mutator assists can draw on it. 81 // 如果当前扫描的数量超过了 gcCreditSlack,就把扫描的对象数量加到全局的数量,批量更新 82 if gcw.scanWork >= gcCreditSlack { 83 atomic.Xaddint64(&gcController.scanWork, gcw.scanWork) 84 if flushBgCredit { 85 gcFlushBgCredit(gcw.scanWork - initScanWork) 86 initScanWork = 0 87 } 88 checkWork -= gcw.scanWork 89 gcw.scanWork = 0 90 // 如果扫描的对象数量已经达到了 执行下次抢占的目标数量 checkWork, 则调用对应模式的函数 91 // idle模式为 pollWork, Fractional模式为 pollFractionalWorkerExit ,在第20行 92 if checkWork <= 0 { 93 checkWork += drainCheckThreshold 94 if check != nil && check() { 95 break 96 } 97 } 98 } 99 } 100 101 // In blocking mode, write barriers are not allowed after this 102 // point because we must preserve the condition that the work 103 // buffers are empty. 104 105 done: 106 // Flush remaining scan work credit. 107 if gcw.scanWork > 0 { 108 // 把扫描的对象数量添加到全局 109 atomic.Xaddint64(&gcController.scanWork, gcw.scanWork) 110 if flushBgCredit { 111 gcFlushBgCredit(gcw.scanWork - initScanWork) 112 } 113 gcw.scanWork = 0 114 } 115 }
处理灰色对象时,无需知道其真实大小,只当做内存分配器提供的object块即可。按指针类型长度对齐配合bitmap标记进行遍历,就可找出所有引用成员,将其作为灰色对象压入队列,当然,当前对象自然成为黑色对象,从队列移除。
markroot
这个被用于根对象扫描。
1 func markroot(gcw *gcWork, i uint32) { 2 // TODO(austin): This is a bit ridiculous. Compute and store 3 // the bases in gcMarkRootPrepare instead of the counts. 4 baseFlushCache := uint32(fixedRootCount) 5 baseData := baseFlushCache + uint32(work.nFlushCacheRoots) 6 baseBSS := baseData + uint32(work.nDataRoots) 7 baseSpans := baseBSS + uint32(work.nBSSRoots) 8 baseStacks := baseSpans + uint32(work.nSpanRoots) 9 end := baseStacks + uint32(work.nStackRoots) 10 11 // Note: if you add a case here, please also update heapdump.go:dumproots. 12 switch { 13 // 释放mcache中的span 14 case baseFlushCache <= i && i < baseData: 15 flushmcache(int(i - baseFlushCache)) 16 // 扫描可读写的全局变量 17 case baseData <= i && i < baseBSS: 18 for _, datap := range activeModules() { 19 markrootBlock(datap.data, datap.edata-datap.data, datap.gcdatamask.bytedata, gcw, int(i-baseData)) 20 } 21 // 扫描只读的全局队列 22 case baseBSS <= i && i < baseSpans: 23 for _, datap := range activeModules() { 24 markrootBlock(datap.bss, datap.ebss-datap.bss, datap.gcbssmask.bytedata, gcw, int(i-baseBSS)) 25 } 26 // 扫描Finalizer队列 27 case i == fixedRootFinalizers: 28 // Only do this once per GC cycle since we don't call 29 // queuefinalizer during marking. 30 if work.markrootDone { 31 break 32 } 33 for fb := allfin; fb != nil; fb = fb.alllink { 34 cnt := uintptr(atomic.Load(&fb.cnt)) 35 scanblock(uintptr(unsafe.Pointer(&fb.fin[0])), cnt*unsafe.Sizeof(fb.fin[0]), &finptrmask[0], gcw) 36 } 37 // 释放已经终止的stack 38 case i == fixedRootFreeGStacks: 39 // Only do this once per GC cycle; preferably 40 // concurrently. 41 if !work.markrootDone { 42 // Switch to the system stack so we can call 43 // stackfree. 44 systemstack(markrootFreeGStacks) 45 } 46 // 扫描MSpan.specials 47 case baseSpans <= i && i < baseStacks: 48 // mark MSpan.specials 49 markrootSpans(gcw, int(i-baseSpans)) 50 51 default: 52 // the rest is scanning goroutine stacks 53 // 获取需要扫描的g 54 var gp *g 55 if baseStacks <= i && i < end { 56 gp = allgs[i-baseStacks] 57 } else { 58 throw("markroot: bad index") 59 } 60 61 // remember when we've first observed the G blocked 62 // needed only to output in traceback 63 status := readgstatus(gp) // We are not in a scan state 64 if (status == _Gwaiting || status == _Gsyscall) && gp.waitsince == 0 { 65 gp.waitsince = work.tstart 66 } 67 68 // scang must be done on the system stack in case 69 // we're trying to scan our own stack. 70 // 转交给g0进行扫描 71 systemstack(func() { 72 // If this is a self-scan, put the user G in 73 // _Gwaiting to prevent self-deadlock. It may 74 // already be in _Gwaiting if this is a mark 75 // worker or we're in mark termination. 76 userG := getg().m.curg 77 selfScan := gp == userG && readgstatus(userG) == _Grunning 78 // 如果是扫描自己的,则转换自己的g的状态 79 if selfScan { 80 casgstatus(userG, _Grunning, _Gwaiting) 81 userG.waitreason = waitReasonGarbageCollectionScan 82 } 83 84 // TODO: scang blocks until gp's stack has 85 // been scanned, which may take a while for 86 // running goroutines. Consider doing this in 87 // two phases where the first is non-blocking: 88 // we scan the stacks we can and ask running 89 // goroutines to scan themselves; and the 90 // second blocks. 91 // 扫描g的栈 92 scang(gp, gcw) 93 94 if selfScan { 95 casgstatus(userG, _Gwaiting, _Grunning) 96 } 97 }) 98 } 99 }
所有这些扫描过程,最终通过scanblock 比对bitmap区域信息找出合法指针,将其目标当做灰色可达对象添加到待处理队列。
markRootBlock
根据 ptrmask0,来扫描[b0, b0+n0)区域
1 func markrootBlock(b0, n0 uintptr, ptrmask0 *uint8, gcw *gcWork, shard int) { 2 if rootBlockBytes%(8*sys.PtrSize) != 0 { 3 // This is necessary to pick byte offsets in ptrmask0. 4 throw("rootBlockBytes must be a multiple of 8*ptrSize") 5 } 6 7 b := b0 + uintptr(shard)*rootBlockBytes 8 // 如果需扫描的block区域,超出b0+n0的区域,直接返回 9 if b >= b0+n0 { 10 return 11 } 12 ptrmask := (*uint8)(add(unsafe.Pointer(ptrmask0), uintptr(shard)*(rootBlockBytes/(8*sys.PtrSize)))) 13 n := uintptr(rootBlockBytes) 14 if b+n > b0+n0 { 15 n = b0 + n0 - b 16 } 17 18 // Scan this shard. 19 // 扫描给定block的shard 20 scanblock(b, n, ptrmask, gcw) 21 }
1 func scanblock(b0, n0 uintptr, ptrmask *uint8, gcw *gcWork) { 2 // Use local copies of original parameters, so that a stack trace 3 // due to one of the throws below shows the original block 4 // base and extent. 5 b := b0 6 n := n0 7 8 for i := uintptr(0); i < n; { 9 // Find bits for the next word. 10 // 找到bitmap中对应的bits 11 bits := uint32(*addb(ptrmask, i/(sys.PtrSize*8))) 12 if bits == 0 { 13 i += sys.PtrSize * 8 14 continue 15 } 16 for j := 0; j < 8 && i < n; j++ { 17 if bits&1 != 0 { 18 // 如果该地址包含指针 19 // Same work as in scanobject; see comments there. 20 obj := *(*uintptr)(unsafe.Pointer(b + i)) 21 if obj != 0 { 22 // 如果该地址下找到了对应的对象,标灰 23 if obj, span, objIndex := findObject(obj, b, i); obj != 0 { 24 greyobject(obj, b, i, span, gcw, objIndex) 25 } 26 } 27 } 28 bits >>= 1 29 i += sys.PtrSize 30 } 31 } 32 }
此处的gcWork是专门设计的高性能队列,它允许局部队列和全局队列work.full/partial协同工作,平衡任务分配。
greyobject
标灰对象其实就是找到对应bitmap,标记存活并扔进队列
1 func greyobject(obj, base, off uintptr, span *mspan, gcw *gcWork, objIndex uintptr) { 2 // obj should be start of allocation, and so must be at least pointer-aligned. 3 if obj&(sys.PtrSize-1) != 0 { 4 throw("greyobject: obj not pointer-aligned") 5 } 6 mbits := span.markBitsForIndex(objIndex) 7 8 if useCheckmark { 9 // 这里是用来debug,确保所有的对象都被正确标识 10 if !mbits.isMarked() { 11 // 这个对象没有被标记 12 printlock() 13 print("runtime:greyobject: checkmarks finds unexpected unmarked object obj=", hex(obj), "\n") 14 print("runtime: found obj at *(", hex(base), "+", hex(off), ")\n") 15 16 // Dump the source (base) object 17 gcDumpObject("base", base, off) 18 19 // Dump the object 20 gcDumpObject("obj", obj, ^uintptr(0)) 21 22 getg().m.traceback = 2 23 throw("checkmark found unmarked object") 24 } 25 hbits := heapBitsForAddr(obj) 26 if hbits.isCheckmarked(span.elemsize) { 27 return 28 } 29 hbits.setCheckmarked(span.elemsize) 30 if !hbits.isCheckmarked(span.elemsize) { 31 throw("setCheckmarked and isCheckmarked disagree") 32 } 33 } else { 34 if debug.gccheckmark > 0 && span.isFree(objIndex) { 35 print("runtime: marking free object ", hex(obj), " found at *(", hex(base), "+", hex(off), ")\n") 36 gcDumpObject("base", base, off) 37 gcDumpObject("obj", obj, ^uintptr(0)) 38 getg().m.traceback = 2 39 throw("marking free object") 40 } 41 42 // If marked we have nothing to do. 43 // 对象被正确标记了,无需做其他的操作 44 if mbits.isMarked() { 45 return 46 } 47 // mbits.setMarked() // Avoid extra call overhead with manual inlining. 48 // 标记对象 49 atomic.Or8(mbits.bytep, mbits.mask) 50 // If this is a noscan object, fast-track it to black 51 // instead of greying it. 52 // 如果对象不是指针,则只需要标记,不需要放进队列,相当于直接标黑 53 if span.spanclass.noscan() { 54 gcw.bytesMarked += uint64(span.elemsize) 55 return 56 } 57 } 58 59 // Queue the obj for scanning. The PREFETCH(obj) logic has been removed but 60 // seems like a nice optimization that can be added back in. 61 // There needs to be time between the PREFETCH and the use. 62 // Previously we put the obj in an 8 element buffer that is drained at a rate 63 // to give the PREFETCH time to do its work. 64 // Use of PREFETCHNTA might be more appropriate than PREFETCH 65 // 判断对象是否被放进队列,没有则放入,标灰步骤完成 66 if !gcw.putFast(obj) { 67 gcw.put(obj) 68 } 69 }
gcWork.putFast
work有wbuf1 wbuf2两个队列用于保存灰色对象,首先会往wbuf1队列里加入灰色对象,wbuf1满了后,交换wbuf1和wbuf2,这事wbuf2便晋升为wbuf1,继续存放灰色对象,两个队列都满了,则想全局进行申请
putFast这里进尝试将对象放进wbuf1队列中
1 func (w *gcWork) putFast(obj uintptr) bool { 2 wbuf := w.wbuf1 3 if wbuf == nil { 4 // 没有申请缓存队列,返回false 5 return false 6 } else if wbuf.nobj == len(wbuf.obj) { 7 // wbuf1队列满了,返回false 8 return false 9 } 10 11 // 向未满wbuf1队列中加入对象 12 wbuf.obj[wbuf.nobj] = obj 13 wbuf.nobj++ 14 return true 15 }
gcWork.put
put不仅尝试将对象放入wbuf1,还会再wbuf1满的时候,尝试更换wbuf1 wbuf2的角色,都满的话,则想全局进行申请,并将满的队列上交到全局队列
1 func (w *gcWork) put(obj uintptr) { 2 flushed := false 3 wbuf := w.wbuf1 4 if wbuf == nil { 5 // 如果wbuf1不存在,则初始化wbuf1 wbuf2两个队列 6 w.init() 7 wbuf = w.wbuf1 8 // wbuf is empty at this point. 9 } else if wbuf.nobj == len(wbuf.obj) { 10 // wbuf1满了,更换wbuf1 wbuf2的角色 11 w.wbuf1, w.wbuf2 = w.wbuf2, w.wbuf1 12 wbuf = w.wbuf1 13 if wbuf.nobj == len(wbuf.obj) { 14 // 更换角色后,wbuf1也满了,说明两个队列都满了 15 // 把 wbuf1上交全局并获取一个空的队列 16 putfull(wbuf) 17 wbuf = getempty() 18 w.wbuf1 = wbuf 19 // 设置队列上交的标志位 20 flushed = true 21 } 22 } 23 24 wbuf.obj[wbuf.nobj] = obj 25 wbuf.nobj++ 26 27 // If we put a buffer on full, let the GC controller know so 28 // it can encourage more workers to run. We delay this until 29 // the end of put so that w is in a consistent state, since 30 // enlistWorker may itself manipulate w. 31 // 此时全局已经有标记满的队列,GC controller选择调度更多work进行工作 32 if flushed && gcphase == _GCmark { 33 gcController.enlistWorker() 34 } 35 }
gcw.balance()
继续分析 gcDrain的58行,balance work是什么
1 func (w *gcWork) balance() { 2 if w.wbuf1 == nil { 3 // 这里wbuf1 wbuf2队列还没有初始化 4 return 5 } 6 // 如果wbuf2不为空,则上交到全局,并获取一个空岛队列给wbuf2 7 if wbuf := w.wbuf2; wbuf.nobj != 0 { 8 putfull(wbuf) 9 w.wbuf2 = getempty() 10 } else if wbuf := w.wbuf1; wbuf.nobj > 4 { 11 // 把未满的wbuf1分成两半,并把其中一半上交的全局队列 12 w.wbuf1 = handoff(wbuf) 13 } else { 14 return 15 } 16 // We flushed a buffer to the full list, so wake a worker. 17 // 这里,全局队列有满的队列了,其他work可以工作了 18 if gcphase == _GCmark { 19 gcController.enlistWorker() 20 } 21 }
gcw.get()
继续分析 gcDrain的63行,这里就是首先从本地的队列获取一个对象,如果本地队列的wbuf1没有,尝试从wbuf2获取,如果两个都没有,则尝试从全局队列获取一个满的队列,并获取一个对象
1 func (w *gcWork) get() uintptr { 2 wbuf := w.wbuf1 3 if wbuf == nil { 4 w.init() 5 wbuf = w.wbuf1 6 // wbuf is empty at this point. 7 } 8 if wbuf.nobj == 0 { 9 // wbuf1空了,更换wbuf1 wbuf2的角色 10 w.wbuf1, w.wbuf2 = w.wbuf2, w.wbuf1 11 wbuf = w.wbuf1 12 // 原wbuf2也是空的,尝试从全局队列获取一个满的队列 13 if wbuf.nobj == 0 { 14 owbuf := wbuf 15 wbuf = getfull() 16 // 获取不到,则返回 17 if wbuf == nil { 18 return 0 19 } 20 // 把空的队列上传到全局空队列,并把获取的满的队列,作为自身的wbuf1 21 putempty(owbuf) 22 w.wbuf1 = wbuf 23 } 24 } 25 26 // TODO: This might be a good place to add prefetch code 27 28 wbuf.nobj-- 29 return wbuf.obj[wbuf.nobj] 30 }
gcw.tryGet() gcw.tryGetFast() 逻辑差不多,相对比较简单,就不继续分析了
scanobject
我们继续分析到 gcDrain 的L76,这里已经获取到了b,开始消费队列
1 func scanobject(b uintptr, gcw *gcWork) { 2 // Find the bits for b and the size of the object at b. 3 // 4 // b is either the beginning of an object, in which case this 5 // is the size of the object to scan, or it points to an 6 // oblet, in which case we compute the size to scan below. 7 // 获取b对应的bits 8 hbits := heapBitsForAddr(b) 9 // 获取b所在的span 10 s := spanOfUnchecked(b) 11 n := s.elemsize 12 if n == 0 { 13 throw("scanobject n == 0") 14 } 15 // 对象过大,则切割后再扫描,maxObletBytes为128k 16 if n > maxObletBytes { 17 // Large object. Break into oblets for better 18 // parallelism and lower latency. 19 if b == s.base() { 20 // It's possible this is a noscan object (not 21 // from greyobject, but from other code 22 // paths), in which case we must *not* enqueue 23 // oblets since their bitmaps will be 24 // uninitialized. 25 // 如果不是指针,直接标记返回,相当于标黑了 26 if s.spanclass.noscan() { 27 // Bypass the whole scan. 28 gcw.bytesMarked += uint64(n) 29 return 30 } 31 32 // Enqueue the other oblets to scan later. 33 // Some oblets may be in b's scalar tail, but 34 // these will be marked as "no more pointers", 35 // so we'll drop out immediately when we go to 36 // scan those. 37 // 按maxObletBytes切割后放入到 队列 38 for oblet := b + maxObletBytes; oblet < s.base()+s.elemsize; oblet += maxObletBytes { 39 if !gcw.putFast(oblet) { 40 gcw.put(oblet) 41 } 42 } 43 } 44 45 // Compute the size of the oblet. Since this object 46 // must be a large object, s.base() is the beginning 47 // of the object. 48 n = s.base() + s.elemsize - b 49 if n > maxObletBytes { 50 n = maxObletBytes 51 } 52 } 53 54 var i uintptr 55 for i = 0; i < n; i += sys.PtrSize { 56 // Find bits for this word. 57 // 获取到对应的bits 58 if i != 0 { 59 // Avoid needless hbits.next() on last iteration. 60 hbits = hbits.next() 61 } 62 // Load bits once. See CL 22712 and issue 16973 for discussion. 63 bits := hbits.bits() 64 // During checkmarking, 1-word objects store the checkmark 65 // in the type bit for the one word. The only one-word objects 66 // are pointers, or else they'd be merged with other non-pointer 67 // data into larger allocations. 68 if i != 1*sys.PtrSize && bits&bitScan == 0 { 69 break // no more pointers in this object 70 } 71 // 不是指针,继续 72 if bits&bitPointer == 0 { 73 continue // not a pointer 74 } 75 76 // Work here is duplicated in scanblock and above. 77 // If you make changes here, make changes there too. 78 obj := *(*uintptr)(unsafe.Pointer(b + i)) 79 80 // At this point we have extracted the next potential pointer. 81 // Quickly filter out nil and pointers back to the current object. 82 if obj != 0 && obj-b >= n { 83 // Test if obj points into the Go heap and, if so, 84 // mark the object. 85 // 86 // Note that it's possible for findObject to 87 // fail if obj points to a just-allocated heap 88 // object because of a race with growing the 89 // heap. In this case, we know the object was 90 // just allocated and hence will be marked by 91 // allocation itself. 92 // 找到指针对应的对象,并标灰 93 if obj, span, objIndex := findObject(obj, b, i); obj != 0 { 94 greyobject(obj, b, i, span, gcw, objIndex) 95 } 96 } 97 } 98 gcw.bytesMarked += uint64(n) 99 gcw.scanWork += int64(i) 100 }
标灰就是标记并放进队列,标黑就是标记,所以当灰色对象从队列中取出后,我们就可以认为这个对象是黑色对象了。
至此,gcDrain的标记工作分析完成,我们继续回到gcBgMarkWorker分析
1 func gcMarkDone() { 2 top: 3 semacquire(&work.markDoneSema) 4 5 // Re-check transition condition under transition lock. 6 if !(gcphase == _GCmark && work.nwait == work.nproc && !gcMarkWorkAvailable(nil)) { 7 semrelease(&work.markDoneSema) 8 return 9 } 10 11 // Disallow starting new workers so that any remaining workers 12 // in the current mark phase will drain out. 13 // 14 // TODO(austin): Should dedicated workers keep an eye on this 15 // and exit gcDrain promptly? 16 // 禁止新的标记任务 17 atomic.Xaddint64(&gcController.dedicatedMarkWorkersNeeded, -0xffffffff) 18 prevFractionalGoal := gcController.fractionalUtilizationGoal 19 gcController.fractionalUtilizationGoal = 0 20 21 // 如果gcBlackenPromptly表名需要所有本地缓存队列立即上交到全局队列,并禁用本地缓存队列 22 if !gcBlackenPromptly { 23 // Transition from mark 1 to mark 2. 24 // 25 // The global work list is empty, but there can still be work 26 // sitting in the per-P work caches. 27 // Flush and disable work caches. 28 29 // Disallow caching workbufs and indicate that we're in mark 2. 30 // 禁用本地缓存队列,进入mark2阶段 31 gcBlackenPromptly = true 32 33 // Prevent completion of mark 2 until we've flushed 34 // cached workbufs. 35 atomic.Xadd(&work.nwait, -1) 36 37 // GC is set up for mark 2. Let Gs blocked on the 38 // transition lock go while we flush caches. 39 semrelease(&work.markDoneSema) 40 // 切换到g0执行,本地缓存上传到全局的操作 41 systemstack(func() { 42 // Flush all currently cached workbufs and 43 // ensure all Ps see gcBlackenPromptly. This 44 // also blocks until any remaining mark 1 45 // workers have exited their loop so we can 46 // start new mark 2 workers. 47 forEachP(func(_p_ *p) { 48 wbBufFlush1(_p_) 49 _p_.gcw.dispose() 50 }) 51 }) 52 53 // Check that roots are marked. We should be able to 54 // do this before the forEachP, but based on issue 55 // #16083 there may be a (harmless) race where we can 56 // enter mark 2 while some workers are still scanning 57 // stacks. The forEachP ensures these scans are done. 58 // 59 // TODO(austin): Figure out the race and fix this 60 // properly. 61 // 检查所有的root是否都被标记了 62 gcMarkRootCheck() 63 64 // Now we can start up mark 2 workers. 65 atomic.Xaddint64(&gcController.dedicatedMarkWorkersNeeded, 0xffffffff) 66 gcController.fractionalUtilizationGoal = prevFractionalGoal 67 68 incnwait := atomic.Xadd(&work.nwait, +1) 69 // 如果没有更多的任务,则执行第二次调用,从mark2阶段转换到mark termination阶段 70 if incnwait == work.nproc && !gcMarkWorkAvailable(nil) { 71 // This loop will make progress because 72 // gcBlackenPromptly is now true, so it won't 73 // take this same "if" branch. 74 goto top 75 } 76 } else { 77 // Transition to mark termination. 78 now := nanotime() 79 work.tMarkTerm = now 80 work.pauseStart = now 81 getg().m.preemptoff = "gcing" 82 if trace.enabled { 83 traceGCSTWStart(0) 84 } 85 systemstack(stopTheWorldWithSema) 86 // The gcphase is _GCmark, it will transition to _GCmarktermination 87 // below. The important thing is that the wb remains active until 88 // all marking is complete. This includes writes made by the GC. 89 90 // Record that one root marking pass has completed. 91 work.markrootDone = true 92 93 // Disable assists and background workers. We must do 94 // this before waking blocked assists. 95 atomic.Store(&gcBlackenEnabled, 0) 96 97 // Wake all blocked assists. These will run when we 98 // start the world again. 99 // 唤醒所有的辅助GC 100 gcWakeAllAssists() 101 102 // Likewise, release the transition lock. Blocked 103 // workers and assists will run when we start the 104 // world again. 105 semrelease(&work.markDoneSema) 106 107 // endCycle depends on all gcWork cache stats being 108 // flushed. This is ensured by mark 2. 109 // 计算下一次gc出发的阈值 110 nextTriggerRatio := gcController.endCycle() 111 112 // Perform mark termination. This will restart the world. 113 // start the world,并进入完成阶段 114 gcMarkTermination(nextTriggerRatio) 115 } 116 }
gcMarkTermination
结束标记,并进行清扫等工作
1 func gcMarkTermination(nextTriggerRatio float64) { 2 // World is stopped. 3 // Start marktermination which includes enabling the write barrier. 4 atomic.Store(&gcBlackenEnabled, 0) 5 gcBlackenPromptly = false 6 // 设置GC的阶段标识 7 setGCPhase(_GCmarktermination) 8 9 work.heap1 = memstats.heap_live 10 startTime := nanotime() 11 12 mp := acquirem() 13 mp.preemptoff = "gcing" 14 _g_ := getg() 15 _g_.m.traceback = 2 16 gp := _g_.m.curg 17 // 设置当前g的状态为waiting状态 18 casgstatus(gp, _Grunning, _Gwaiting) 19 gp.waitreason = waitReasonGarbageCollection 20 21 // Run gc on the g0 stack. We do this so that the g stack 22 // we're currently running on will no longer change. Cuts 23 // the root set down a bit (g0 stacks are not scanned, and 24 // we don't need to scan gc's internal state). We also 25 // need to switch to g0 so we can shrink the stack. 26 systemstack(func() { 27 // 通过g0扫描当前g的栈 28 gcMark(startTime) 29 // Must return immediately. 30 // The outer function's stack may have moved 31 // during gcMark (it shrinks stacks, including the 32 // outer function's stack), so we must not refer 33 // to any of its variables. Return back to the 34 // non-system stack to pick up the new addresses 35 // before continuing. 36 }) 37 38 systemstack(func() { 39 work.heap2 = work.bytesMarked 40 if debug.gccheckmark > 0 { 41 // Run a full stop-the-world mark using checkmark bits, 42 // to check that we didn't forget to mark anything during 43 // the concurrent mark process. 44 // 如果启用了gccheckmark,则检查所有可达对象是否都有标记 45 gcResetMarkState() 46 initCheckmarks() 47 gcMark(startTime) 48 clearCheckmarks() 49 } 50 51 // marking is complete so we can turn the write barrier off 52 // 设置gc的阶段标识,GCoff时会关闭写屏障 53 setGCPhase(_GCoff) 54 // 开始清扫 55 gcSweep(work.mode) 56 57 if debug.gctrace > 1 { 58 startTime = nanotime() 59 // The g stacks have been scanned so 60 // they have gcscanvalid==true and gcworkdone==true. 61 // Reset these so that all stacks will be rescanned. 62 gcResetMarkState() 63 finishsweep_m() 64 65 // Still in STW but gcphase is _GCoff, reset to _GCmarktermination 66 // At this point all objects will be found during the gcMark which 67 // does a complete STW mark and object scan. 68 setGCPhase(_GCmarktermination) 69 gcMark(startTime) 70 setGCPhase(_GCoff) // marking is done, turn off wb. 71 gcSweep(work.mode) 72 } 73 }) 74 75 _g_.m.traceback = 0 76 casgstatus(gp, _Gwaiting, _Grunning) 77 78 if trace.enabled { 79 traceGCDone() 80 } 81 82 // all done 83 mp.preemptoff = "" 84 85 if gcphase != _GCoff { 86 throw("gc done but gcphase != _GCoff") 87 } 88 89 // Update GC trigger and pacing for the next cycle. 90 // 更新下次出发gc的增长比 91 gcSetTriggerRatio(nextTriggerRatio) 92 93 // Update timing memstats 94 // 更新用时 95 now := nanotime() 96 sec, nsec, _ := time_now() 97 unixNow := sec*1e9 + int64(nsec) 98 work.pauseNS += now - work.pauseStart 99 work.tEnd = now 100 atomic.Store64(&memstats.last_gc_unix, uint64(unixNow)) // must be Unix time to make sense to user 101 atomic.Store64(&memstats.last_gc_nanotime, uint64(now)) // monotonic time for us 102 memstats.pause_ns[memstats.numgc%uint32(len(memstats.pause_ns))] = uint64(work.pauseNS) 103 memstats.pause_end[memstats.numgc%uint32(len(memstats.pause_end))] = uint64(unixNow) 104 memstats.pause_total_ns += uint64(work.pauseNS) 105 106 // Update work.totaltime. 107 sweepTermCpu := int64(work.stwprocs) * (work.tMark - work.tSweepTerm) 108 // We report idle marking time below, but omit it from the 109 // overall utilization here since it's "free". 110 markCpu := gcController.assistTime + gcController.dedicatedMarkTime + gcController.fractionalMarkTime 111 markTermCpu := int64(work.stwprocs) * (work.tEnd - work.tMarkTerm) 112 cycleCpu := sweepTermCpu + markCpu + markTermCpu 113 work.totaltime += cycleCpu 114 115 // Compute overall GC CPU utilization. 116 totalCpu := sched.totaltime + (now-sched.procresizetime)*int64(gomaxprocs) 117 memstats.gc_cpu_fraction = float64(work.totaltime) / float64(totalCpu) 118 119 // Reset sweep state. 120 // 重置清扫的状态 121 sweep.nbgsweep = 0 122 sweep.npausesweep = 0 123 124 // 如果是强制开启的gc,标识增加 125 if work.userForced { 126 memstats.numforcedgc++ 127 } 128 129 // Bump GC cycle count and wake goroutines waiting on sweep. 130 // 统计执行GC的次数然后唤醒等待清扫的G 131 lock(&work.sweepWaiters.lock) 132 memstats.numgc++ 133 injectglist(work.sweepWaiters.head.ptr()) 134 work.sweepWaiters.head = 0 135 unlock(&work.sweepWaiters.lock) 136 137 // Finish the current heap profiling cycle and start a new 138 // heap profiling cycle. We do this before starting the world 139 // so events don't leak into the wrong cycle. 140 mProf_NextCycle() 141 // start the world 142 systemstack(func() { startTheWorldWithSema(true) }) 143 144 // Flush the heap profile so we can start a new cycle next GC. 145 // This is relatively expensive, so we don't do it with the 146 // world stopped. 147 mProf_Flush() 148 149 // Prepare workbufs for freeing by the sweeper. We do this 150 // asynchronously because it can take non-trivial time. 151 prepareFreeWorkbufs() 152 153 // Free stack spans. This must be done between GC cycles. 154 systemstack(freeStackSpans) 155 156 // Print gctrace before dropping worldsema. As soon as we drop 157 // worldsema another cycle could start and smash the stats 158 // we're trying to print. 159 if debug.gctrace > 0 { 160 util := int(memstats.gc_cpu_fraction * 100) 161 162 var sbuf [24]byte 163 printlock() 164 print("gc ", memstats.numgc, 165 " @", string(itoaDiv(sbuf[:], uint64(work.tSweepTerm-runtimeInitTime)/1e6, 3)), "s ", 166 util, "%: ") 167 prev := work.tSweepTerm 168 for i, ns := range []int64{work.tMark, work.tMarkTerm, work.tEnd} { 169 if i != 0 { 170 print("+") 171 } 172 print(string(fmtNSAsMS(sbuf[:], uint64(ns-prev)))) 173 prev = ns 174 } 175 print(" ms clock, ") 176 for i, ns := range []int64{sweepTermCpu, gcController.assistTime, gcController.dedicatedMarkTime + gcController.fractionalMarkTime, gcController.idleMarkTime, markTermCpu} { 177 if i == 2 || i == 3 { 178 // Separate mark time components with /. 179 print("/") 180 } else if i != 0 { 181 print("+") 182 } 183 print(string(fmtNSAsMS(sbuf[:], uint64(ns)))) 184 } 185 print(" ms cpu, ", 186 work.heap0>>20, "->", work.heap1>>20, "->", work.heap2>>20, " MB, ", 187 work.heapGoal>>20, " MB goal, ", 188 work.maxprocs, " P") 189 if work.userForced { 190 print(" (forced)") 191 } 192 print("\n") 193 printunlock() 194 } 195 196 semrelease(&worldsema) 197 // Careful: another GC cycle may start now. 198 199 releasem(mp) 200 mp = nil 201 202 // now that gc is done, kick off finalizer thread if needed 203 // 如果不是并行GC,则让当前M开始调度 204 if !concurrentSweep { 205 // give the queued finalizers, if any, a chance to run 206 Gosched() 207 } 208 }
5. 清理
goSweep
清扫任务:
1 func gcSweep(mode gcMode) { 2 if gcphase != _GCoff { 3 throw("gcSweep being done but phase is not GCoff") 4 } 5 6 lock(&mheap_.lock) 7 // sweepgen在每次GC之后都会增长2,每次GC之后sweepSpans的角色都会互换 8 mheap_.sweepgen += 2 9 mheap_.sweepdone = 0 10 if mheap_.sweepSpans[mheap_.sweepgen/2%2].index != 0 { 11 // We should have drained this list during the last 12 // sweep phase. We certainly need to start this phase 13 // with an empty swept list. 14 throw("non-empty swept list") 15 } 16 mheap_.pagesSwept = 0 17 unlock(&mheap_.lock) 18 // 如果不是并行GC,或者强制GC 19 if !_ConcurrentSweep || mode == gcForceBlockMode { 20 // Special case synchronous sweep. 21 // Record that no proportional sweeping has to happen. 22 lock(&mheap_.lock) 23 mheap_.sweepPagesPerByte = 0 24 unlock(&mheap_.lock) 25 // Sweep all spans eagerly. 26 // 清扫所有的span 27 for sweepone() != ^uintptr(0) { 28 sweep.npausesweep++ 29 } 30 // Free workbufs eagerly. 31 // 释放所有的 workbufs 32 prepareFreeWorkbufs() 33 for freeSomeWbufs(false) { 34 } 35 // All "free" events for this mark/sweep cycle have 36 // now happened, so we can make this profile cycle 37 // available immediately. 38 mProf_NextCycle() 39 mProf_Flush() 40 return 41 } 42 43 // Background sweep. 44 lock(&sweep.lock) 45 // 唤醒后台清扫任务,也就是 bgsweep 函数,清扫流程跟上面非并行清扫差不多 46 if sweep.parked { 47 sweep.parked = false 48 ready(sweep.g, 0, true) 49 } 50 unlock(&sweep.lock) 51 }
并发清理同样由一个专门的goroutine完成,它在 runtime.main 调用时被创建。
sweepone
接下来我们就分析一下sweepone 清扫的流程
1 func sweepone() uintptr { 2 _g_ := getg() 3 sweepRatio := mheap_.sweepPagesPerByte // For debugging 4 5 // increment locks to ensure that the goroutine is not preempted 6 // in the middle of sweep thus leaving the span in an inconsistent state for next GC 7 _g_.m.locks++ 8 // 检查是否已经完成了清扫 9 if atomic.Load(&mheap_.sweepdone) != 0 { 10 _g_.m.locks-- 11 return ^uintptr(0) 12 } 13 // 增加清扫的worker数量 14 atomic.Xadd(&mheap_.sweepers, +1) 15 16 npages := ^uintptr(0) 17 sg := mheap_.sweepgen 18 for { 19 // 循环获取需要清扫的span 20 s := mheap_.sweepSpans[1-sg/2%2].pop() 21 if s == nil { 22 atomic.Store(&mheap_.sweepdone, 1) 23 break 24 } 25 if s.state != mSpanInUse { 26 // This can happen if direct sweeping already 27 // swept this span, but in that case the sweep 28 // generation should always be up-to-date. 29 if s.sweepgen != sg { 30 print("runtime: bad span s.state=", s.state, " s.sweepgen=", s.sweepgen, " sweepgen=", sg, "\n") 31 throw("non in-use span in unswept list") 32 } 33 continue 34 } 35 // sweepgen == h->sweepgen - 2, 表示这个span需要清扫 36 // sweepgen == h->sweepgen - 1, 表示这个span正在被清扫 37 // 这是里确定span的状态及尝试转换span的状态 38 if s.sweepgen != sg-2 || !atomic.Cas(&s.sweepgen, sg-2, sg-1) { 39 continue 40 } 41 npages = s.npages 42 // 单个span的清扫 43 if !s.sweep(false) { 44 // Span is still in-use, so this returned no 45 // pages to the heap and the span needs to 46 // move to the swept in-use list. 47 npages = 0 48 } 49 break 50 } 51 52 // Decrement the number of active sweepers and if this is the 53 // last one print trace information. 54 // 当前worker清扫任务完成,更新sweepers的数量 55 if atomic.Xadd(&mheap_.sweepers, -1) == 0 && atomic.Load(&mheap_.sweepdone) != 0 { 56 if debug.gcpacertrace > 0 { 57 print("pacer: sweep done at heap size ", memstats.heap_live>>20, "MB; allocated ", (memstats.heap_live-mheap_.sweepHeapLiveBasis)>>20, "MB during sweep; swept ", mheap_.pagesSwept, " pages at ", sweepRatio, " pages/byte\n") 58 } 59 } 60 _g_.m.locks-- 61 return npages 62 }
mspan.sweep
1 func (s *mspan) sweep(preserve bool) bool { 2 // It's critical that we enter this function with preemption disabled, 3 // GC must not start while we are in the middle of this function. 4 _g_ := getg() 5 if _g_.m.locks == 0 && _g_.m.mallocing == 0 && _g_ != _g_.m.g0 { 6 throw("MSpan_Sweep: m is not locked") 7 } 8 sweepgen := mheap_.sweepgen 9 // 只有正在清扫中状态的span才可以正常执行 10 if s.state != mSpanInUse || s.sweepgen != sweepgen-1 { 11 print("MSpan_Sweep: state=", s.state, " sweepgen=", s.sweepgen, " mheap.sweepgen=", sweepgen, "\n") 12 throw("MSpan_Sweep: bad span state") 13 } 14 15 if trace.enabled { 16 traceGCSweepSpan(s.npages * _PageSize) 17 } 18 // 先更新清扫的page数 19 atomic.Xadd64(&mheap_.pagesSwept, int64(s.npages)) 20 21 spc := s.spanclass 22 size := s.elemsize 23 res := false 24 25 c := _g_.m.mcache 26 freeToHeap := false 27 28 // The allocBits indicate which unmarked objects don't need to be 29 // processed since they were free at the end of the last GC cycle 30 // and were not allocated since then. 31 // If the allocBits index is >= s.freeindex and the bit 32 // is not marked then the object remains unallocated 33 // since the last GC. 34 // This situation is analogous to being on a freelist. 35 36 // Unlink & free special records for any objects we're about to free. 37 // Two complications here: 38 // 1. An object can have both finalizer and profile special records. 39 // In such case we need to queue finalizer for execution, 40 // mark the object as live and preserve the profile special. 41 // 2. A tiny object can have several finalizers setup for different offsets. 42 // If such object is not marked, we need to queue all finalizers at once. 43 // Both 1 and 2 are possible at the same time. 44 specialp := &s.specials 45 special := *specialp 46 // 判断在special中的对象是否存活,是否至少有一个finalizer,释放没有finalizer的对象,把有finalizer的对象组成队列 47 for special != nil { 48 // A finalizer can be set for an inner byte of an object, find object beginning. 49 objIndex := uintptr(special.offset) / size 50 p := s.base() + objIndex*size 51 mbits := s.markBitsForIndex(objIndex) 52 if !mbits.isMarked() { 53 // This object is not marked and has at least one special record. 54 // Pass 1: see if it has at least one finalizer. 55 hasFin := false 56 endOffset := p - s.base() + size 57 for tmp := special; tmp != nil && uintptr(tmp.offset) < endOffset; tmp = tmp.next { 58 if tmp.kind == _KindSpecialFinalizer { 59 // Stop freeing of object if it has a finalizer. 60 mbits.setMarkedNonAtomic() 61 hasFin = true 62 break 63 } 64 } 65 // Pass 2: queue all finalizers _or_ handle profile record. 66 for special != nil && uintptr(special.offset) < endOffset { 67 // Find the exact byte for which the special was setup 68 // (as opposed to object beginning). 69 p := s.base() + uintptr(special.offset) 70 if special.kind == _KindSpecialFinalizer || !hasFin { 71 // Splice out special record. 72 y := special 73 special = special.next 74 *specialp = special 75 freespecial(y, unsafe.Pointer(p), size) 76 } else { 77 // This is profile record, but the object has finalizers (so kept alive). 78 // Keep special record. 79 specialp = &special.next 80 special = *specialp 81 } 82 } 83 } else { 84 // object is still live: keep special record 85 specialp = &special.next 86 special = *specialp 87 } 88 } 89 90 if debug.allocfreetrace != 0 || raceenabled || msanenabled { 91 // Find all newly freed objects. This doesn't have to 92 // efficient; allocfreetrace has massive overhead. 93 mbits := s.markBitsForBase() 94 abits := s.allocBitsForIndex(0) 95 for i := uintptr(0); i < s.nelems; i++ { 96 if !mbits.isMarked() && (abits.index < s.freeindex || abits.isMarked()) { 97 x := s.base() + i*s.elemsize 98 if debug.allocfreetrace != 0 { 99 tracefree(unsafe.Pointer(x), size) 100 } 101 if raceenabled { 102 racefree(unsafe.Pointer(x), size) 103 } 104 if msanenabled { 105 msanfree(unsafe.Pointer(x), size) 106 } 107 } 108 mbits.advance() 109 abits.advance() 110 } 111 } 112 113 // Count the number of free objects in this span. 114 // 获取需要释放的alloc对象的总数 115 nalloc := uint16(s.countAlloc()) 116 // 如果sizeclass为0,却分配的总数量为0,则释放到mheap 117 if spc.sizeclass() == 0 && nalloc == 0 { 118 s.needzero = 1 119 freeToHeap = true 120 } 121 nfreed := s.allocCount - nalloc 122 if nalloc > s.allocCount { 123 print("runtime: nelems=", s.nelems, " nalloc=", nalloc, " previous allocCount=", s.allocCount, " nfreed=", nfreed, "\n") 124 throw("sweep increased allocation count") 125 } 126 127 s.allocCount = nalloc 128 // 判断span是否empty 129 wasempty := s.nextFreeIndex() == s.nelems 130 // 重置freeindex 131 s.freeindex = 0 // reset allocation index to start of span. 132 if trace.enabled { 133 getg().m.p.ptr().traceReclaimed += uintptr(nfreed) * s.elemsize 134 } 135 136 // gcmarkBits becomes the allocBits. 137 // get a fresh cleared gcmarkBits in preparation for next GC 138 // 重置 allocBits为 gcMarkBits 139 s.allocBits = s.gcmarkBits 140 // 重置 gcMarkBits 141 s.gcmarkBits = newMarkBits(s.nelems) 142 143 // Initialize alloc bits cache. 144 // 更新allocCache 145 s.refillAllocCache(0) 146 147 // We need to set s.sweepgen = h.sweepgen only when all blocks are swept, 148 // because of the potential for a concurrent free/SetFinalizer. 149 // But we need to set it before we make the span available for allocation 150 // (return it to heap or mcentral), because allocation code assumes that a 151 // span is already swept if available for allocation. 152 if freeToHeap || nfreed == 0 { 153 // The span must be in our exclusive ownership until we update sweepgen, 154 // check for potential races. 155 if s.state != mSpanInUse || s.sweepgen != sweepgen-1 { 156 print("MSpan_Sweep: state=", s.state, " sweepgen=", s.sweepgen, " mheap.sweepgen=", sweepgen, "\n") 157 throw("MSpan_Sweep: bad span state after sweep") 158 } 159 // Serialization point. 160 // At this point the mark bits are cleared and allocation ready 161 // to go so release the span. 162 atomic.Store(&s.sweepgen, sweepgen) 163 } 164 165 if nfreed > 0 && spc.sizeclass() != 0 { 166 c.local_nsmallfree[spc.sizeclass()] += uintptr(nfreed) 167 // 把span释放到mcentral上 168 res = mheap_.central[spc].mcentral.freeSpan(s, preserve, wasempty) 169 // MCentral_FreeSpan updates sweepgen 170 } else if freeToHeap { 171 // 这里是大对象的span释放,与117行呼应 172 // Free large span to heap 173 174 // NOTE(rsc,dvyukov): The original implementation of efence 175 // in CL 22060046 used SysFree instead of SysFault, so that 176 // the operating system would eventually give the memory 177 // back to us again, so that an efence program could run 178 // longer without running out of memory. Unfortunately, 179 // calling SysFree here without any kind of adjustment of the 180 // heap data structures means that when the memory does 181 // come back to us, we have the wrong metadata for it, either in 182 // the MSpan structures or in the garbage collection bitmap. 183 // Using SysFault here means that the program will run out of 184 // memory fairly quickly in efence mode, but at least it won't 185 // have mysterious crashes due to confused memory reuse. 186 // It should be possible to switch back to SysFree if we also 187 // implement and then call some kind of MHeap_DeleteSpan. 188 if debug.efence > 0 { 189 s.limit = 0 // prevent mlookup from finding this span 190 sysFault(unsafe.Pointer(s.base()), size) 191 } else { 192 // 把sapn释放到mheap上 193 mheap_.freeSpan(s, 1) 194 } 195 c.local_nlargefree++ 196 c.local_largefree += size 197 res = true 198 } 199 if !res { 200 // The span has been swept and is still in-use, so put 201 // it on the swept in-use list. 202 // 如果span未释放到mcentral或mheap,表示span仍然处于in-use状态 203 mheap_.sweepSpans[sweepgen/2%2].push(s) 204 } 205 return res 206 }
并发清理本质上就是一个死循环,被唤醒后开始执行清理任务。通过遍历所有span对象,触发内存分配的回收操作。任务完成后再次休眠,等待下次任务。
6. 回收流程
GO的GC是并行GC, 也就是GC的大部分处理和普通的go代码是同时运行的, 这让GO的GC流程比较复杂.
首先GC有四个阶段, 它们分别是:
- Sweep Termination: 对未清扫的span进行清扫, 只有上一轮的GC的清扫工作完成才可以开始新一轮的GC
- Mark: 扫描所有根对象, 和根对象可以到达的所有对象, 标记它们不被回收
- Mark Termination: 完成标记工作, 重新扫描部分根对象(要求STW)
- Sweep: 按标记结果清扫span
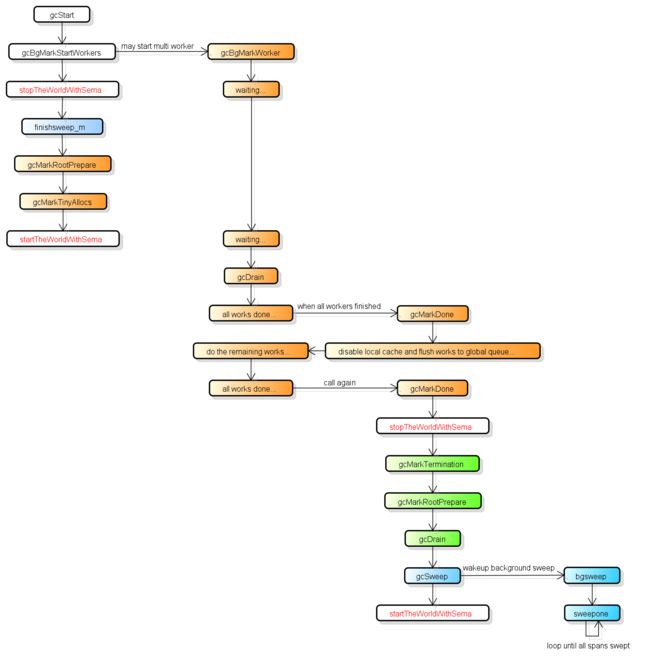
在GC过程中会有两种后台任务(G), 一种是标记用的后台任务, 一种是清扫用的后台任务.标记用的后台任务会在需要时启动, 可以同时工作的后台任务数量大约是P的数量的25%, 也就是go所讲的让25%的cpu用在GC上的根据.清扫用的后台任务在程序启动时会启动一个, 进入清扫阶段时唤醒.
目前整个GC流程会进行两次STW(Stop The World), 第一次是Mark阶段的开始, 第二次是Mark Termination阶段.第一次STW会准备根对象的扫描, 启动写屏障(Write Barrier)和辅助GC(mutator assist).第二次STW会重新扫描部分根对象, 禁用写屏障(Write Barrier)和辅助GC(mutator assist).需要注意的是, 不是所有根对象的扫描都需要STW, 例如扫描栈上的对象只需要停止拥有该栈的G.写屏障的实现使用了Hybrid Write Barrier, 大幅减少了第二次STW的时间.
7. 监控
场景:服务重启,海量客户端重新接入,瞬间分配大量对象,这会将垃圾回收的触发条件next_gc推到一个很大值。服务正常后,因活跃的远小于该阈值,造成垃圾回收久久无法触发,服务进程内会有大量白色对象无法被回收,造成隐性内存泄漏,也可能是某个对象在短期内大量使用临时对象造成。
场景示例:
1 //testms.go 2 packmage main 3 4 import ( 5 "fmt" 6 "runtime" 7 "time" 8 ) 9 10 func test(){ 11 type M [1 << 10]byte 12 data := make([]*M, 1024*20) 13 14 //申请20MB内存分配,超出初始阈值,将next_GC提高 15 for i := range data { 16 data[i] = new(M) 17 } 18 19 //解除引用,预防内联导致data生命周期变长 20 for i := range data { 21 data[i] = nil 22 } 23 } 24 25 func main(){ 26 test() 27 now := time.New() 28 for{ 29 var ms runtime.MemStats 30 runtime.ReadMemStats(&ms) 31 fmt.Printf("%s %d MB\n", now.Format("15:04:05"), ms.NextGC>>20) 32 33 time.Sleep(time.Second * 30) 34 } 35 }
编译执行:
test()函数模拟了短期内大量分配对象的行为。
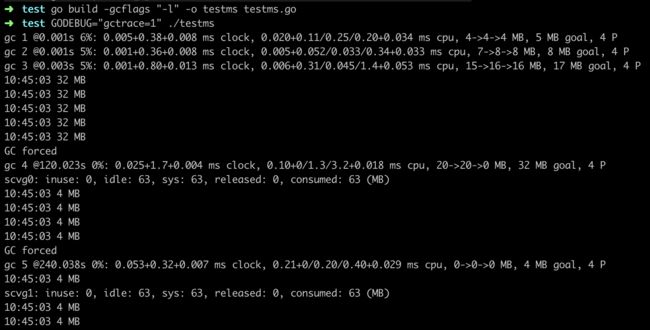
输出结果显示在其结束后的的一段时间内都没有触发垃圾回收。直到forcegc介入,才将next_gc恢复正常。这是垃圾回收的最后一道保障措施。监控服务sysmon每隔2分钟就会检查一次垃圾回收状态,如超出2分钟未触发,则强制执行。