本文由云+社区发表
作者:腾讯技术工程
导语:最近几年来,深度学习在推荐系统领域中取得了不少成果,相比传统的推荐方法,深度学习有着自己独到的优势。我们团队在QQ看点的图文推荐中也尝试了一些深度学习方法,积累了一些经验。本文主要介绍了一种用于推荐系统召回模块的深度学习方法,其出处是Google在2016年发表于RecSys的一篇用于YouTube视频推荐的论文。我们在该论文的基础上做了一些修改,并做了线上AB测试,与传统的协同召回做对比,点击率等指标提升明显。
为了系统的完整性,在介绍主模型前,本文先对传统推荐算法和召回算法做一些简单的介绍和总结,并指出深度学习方法相对于传统方法的优势所在,然后再进入本文的主题——深度召回模型。
1. 推荐系统算法概述
按照使用的数据类型来分,推荐算法可以分为两大类:
第一类是基于用户行为数据的推荐算法,通常也叫做协同过滤;协同过滤又分为memory-based和model-based这两类。其中,memory-based协同过滤的代表算法有基于用户的UserCF,基于物品的ItemCF,它们的特点是用行为数据直接计算user-user或item-item的相似度[1]。Model-based协同过滤的代表算法主要是一些隐变量模型,例如SVD、矩阵分解MF[2, 3]、主题模型pLSA、LDA[4]等,它们的特点是用行为数据先计算出user和item的隐向量,然后通过这些隐向量计算user-user或item-item间的匹配度去做推荐。
在实践中,我们除了能拿到用户的行为数据以外,通常还可以拿到用户和物品的画像数据,比如性别、年龄、地域、标签、分类、标题、正文等,在一些文献中,这些行为以外的数据被称为side information。传统的协同过滤是不考虑side information的,如果把side information和行为数据结合使用,应该会提升推荐的准确率。这种同时使用行为数据和side information的算法都属于第二类算法。
在第二类算法中,最常见的模型就是CTR模型。CTR模型本质上是一个二分类的分类器,用得比较多的是LR、xgboost[10]、lightGBM[11]等分类器。其中,行为数据和side information被用于构造训练样本的特征和类标。分类器完成训练后,通过预测user点击item的概率,可以把topK概率最大的item作为推荐结果推送给用户。比起纯行为的协同过滤,使用了side information 的CTR模型通常会取得更好的推荐效果。而整个CTR模型取胜的关键,在于如何结合side information和行为数据构造出具有判别性的用户特征、物品特征以及交叉特征;
近五年来,基于深度学习的CTR模型逐渐发展起来,在不少应用场景下取得了比传统CTR模型更好的效果。相比于传统的CTR模型,深度CTR模型有着自己独到的优势,主要体现在如下几个方面:
(1)特征的整合能力:深度学习通过使用embedding技术,可以将任何分类变量转化为具有语义结构的低维稠密向量,很容易把分类变量和连续变量结合在一起作为模型的输入,比传统方法使用one-hot或multi-hot表示分类变量的方式更方便有效,特别适合于web推荐这种分类变量比较多的场景;
(2)自动交叉特征的能力:深度学习通过神经网络强大的非线性拟合能力,可以从原始输入数据中自动学习用户和物品的交叉特征,能更深层次地匹配用户与物品,从而提高推荐准确率。通过自动学习交叉特征,大大降低了特征工程的工作量;
(3)端到端的学习:传统CTR模型会把特征构造和模型训练分开,先做数据预处理、特征构造或特征学习,然后给模型训练。这些事先构造或学习好的特征,并不一定最适合用来拟合当前模型。而在深度学习中,输入数据不需要做过多的预处理或特征学习,特征学习和模型训练是同时进行的,学到的特征也是最适合拟合当前模型的,学出来的模型的泛化能力通常会更好一些。由于不需要专门学习特征,因此也提高了开发模型的效率。
(4)完善的计算平台和工具:模型建得再漂亮,最后也得能求解出来才能在实际中发挥真正的作用。对于深度学习来说,一些现有的计算平台(如TensorFlow)使得模型求解变得非常容易。研究者只需要把精力放在模型的设计和调优上,不需要推导复杂的求解公式。模型的求解由TensorFlow等工具的自动微分技术完成,大大降低了模型实现和落地的难度。
由于以上原因,基于深度学习的CTR模型受到了广泛关注,在最近几年内发展很快,并在不少业务中取得了显著的成果。
2.召回模型
推荐系统在架构上一般分为两层:召回层和排序层。
其中,召回层主要负责从全体物品中快速筛选出跟用户兴趣相关的物品池子,大大缩小物品的范围,为排序做准备。在资讯类产品的推荐场景下,召回物品通常还需要满足时新性。所以在资讯类推荐场景中,召回模型要满足如下几点:
(1)高效性:要在很短的响应时间内完成物品的召回;
(2)相关性:要尽可能召回那些匹配用户兴趣的物品;
(3)时新性:新上线的物品,也要能被召回,以确保最新的内容也有曝光的机会;
2.1传统召回模型
以图文推荐为例,常用的召回方式是通过用户历史点击的文章去关联相似文章作为召回,其中,按照所用数据的不同,又分为按内容召回和协同召回。
内容召回:
(1)根据用户画像中的标签、分类,召回具有相同或相似标签、分类的文章;
(2)使用文章的标题或正文,通过word2vec、glove等方法求出文章的标题向量或正文向量,通过计算向量的余弦相似度召回内容上相似的文章。
协同召回:
(1)可以使用jaccard公式直接计算两篇文章的用户重合度作为这两篇文章的行为相似度;

优缺点:
以上这两类召回方法,都有各自的优点和缺点。
第一种方法的优点是可以召回最新的文章。缺点是可能会出现召回内容过于集中或兴趣漂移等问题。对于向量化方法,容易出现“点过什么就召回什么”的现象,降低了推荐的多样性。对于直接用标签或分类来召回,可能会召回相关性不高的文章,降低召回的准确性。
第二种方法在一定程度上解决召回内容过于集中和兴趣漂移的问题,但是因为依赖于行为数据,所以只能召回训练数据中包含的文章,没办法召回最新的文章。为了召回新文章,就必须每隔一段时间重新计算一遍。所以它召回的文章做不到真正意义的时新。
为了解决以上两种方法存在的缺点,我们使用了深度学习的方法去做召回,充分利用用户的画像信息去深度匹配用户兴趣和文章,同时保证可以召回最新的文章。业界中用深度学习做召回比较成功的是Google在YouTube视频推荐中使用的召回方法[9],但它并不考虑召回内容是否时新这一点,所以为了让这个方法也能召回最新的item,我们对YouTube深度召回模型做了一些修改,让它既能召回深度匹配用户兴趣的文章,也能保持召回文章的时新性。“此外,由于YouTube召回模型使用的是用户向量直接匹配文章向量的召回方式,因此通过使用向量索引系统,很容易满足从大量文章中快速召回候选集的性能要求。”
2.2深度召回模型
为了表述上的简洁,我把Google提出的这个用于YouTube视频推荐的深度召回模型简称为YouTube召回模型。在讲述模型之前,先讲一下深度CTR模型中一般都要使用的两个基本网络结构:embedding层和全连接层。
Embedding层
深度CTR模型的输入通常会包含各种不同的分类变量,例如用户画像里的标签、一级分类、二级分类等。这些分类变量的取值往往比较多,比如标签,它的取值可能就有几十万个,如果用one-hot或multi-hot方式来表示标签,则会产生几十万维的高维稀疏向量。在深度CTR模型中,对这些取值特别多的分类变量通常都会使用embedding方法,将其表示为一个低维稠密的向量,然后输入到网络中。这个低维稠密向量被称为这个分类变量的embedding,把分类变量转化为embedding的那一层网络称为embedding层。下图给出了一个例子,讲述了如何使用embedding方法将用户画像中的标签表示为一个低维稠密向量。
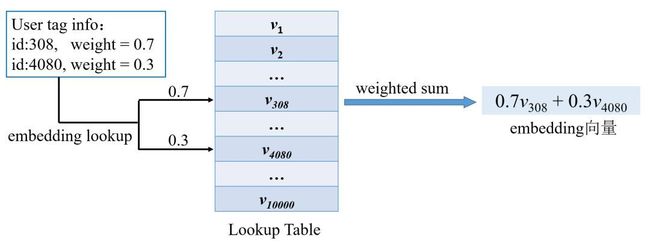
图1 用embedding方法表示分类变量的例子
首先,我们初始化一个lookup table,这个lookup table是一个矩阵(可以是事先选了好固定不变的,也可以是从数据中学习,不断迭代更新的),矩阵的行数为分类变量的取值数,在这个例子中就是标签总个数,矩阵的列数是低维稠密向量的维数(事先指定)。假设标签总个数为1万,那么lookup table就有1万行,其中第i行是编号为i的标签对应的embedding。在上图例子中,用户有两个标签,编号分别为308和4080,对应权重为0.7和0.3,求embedding时首先将第308行和第4080行的向量拿出来,分别记为
![]()
,然后以0.7和0.3为权重加权求和这两个向量,就得到了用户标签的embedding,即
![]()
事实上,用以上方法求embedding,跟用输入分类变量one-hot或multi-hot后得到的高维稀疏向量乘以lookup table,得到的结果是一样的,不同的只是用查表求和的方式来做这个矩阵乘法会高效得多。所以从本质上说,求embedding做的是线性降维。
全连接层
全连接层是多层感知器(multiple layer perceptron, MLP)中的基本结构,定义了第l层到第l+1层的非线性映射关系,它的主要作用是使模型具备非线性拟合能力,或者说学习特征交叉的能力。图2给出了一个从第l层到第l+1层的全连接示意图。
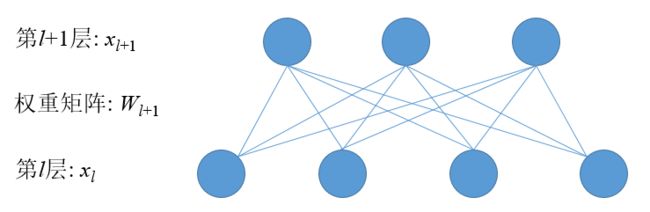
图2 第l层到第l+1层的全连接示意图

Youtube召回模型的网络结构
YouTube召回模型根据user的点击历史和画像,计算user对item库里每个item的喜欢的概率,返回topK概率最大的item作为召回列表。从本质上说,YouTube召回模型是一个超大规模的多分类模型,每个item是一个类别,通过用户画像计算出用户特征作为模型输入,预测用户最喜欢的topK个类别(topK个item)。
在图文主feeds召回这一场景中,用户的输入主要为以下几种类型的数据:
(1)用户的点击历史,包括阅读、点赞、评论、收藏、biu过的文章;
(2)用户的兴趣画像,包括用户的标签、一级分类、二级分类等;
(3)用户的人口统计学特征,包括用户的性别、年龄等;
(4)用户的上下文信息,包括用户的地域信息、访问推荐系统时的时间段等;

这里有一点需要注意的,就是我们模型里文章的lookup table是由文章正文分词的word2vec向量构成的,在训练过程中不更新。在YouTube召回模型的原始论文里,item是视频,item的lookup table是学习出来的。但是在图文推荐场景下,如果文章的lookup table是学习得到的话,那就没办法召回最新的文章了,只能召回那些训练样本中出现过的文章,满足不了时新文章推荐的需求。为了能召回新文章,我们修改了原模型,直接用文章的word2vec向量构造文章的lookup table,其中文章的word2vec向量由文章的词向量加权求和得到,而词向量则是事先用word2vec学好固定下来的。每入库一篇新文章,我们都可以通过该文章的词向量加权求和得到它的word2vec向量,然后存起来,YouTube模型在线召回时,无论是计算用户兴趣向量还是计算内积,都可以实时获取到每篇文章的向量,包括最新文章,从而可以满足时新文章召回的需求。

图3 YouTube深度召回模型的网络结构
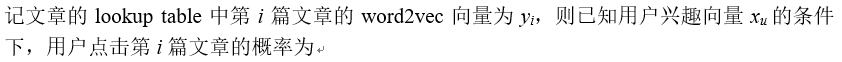


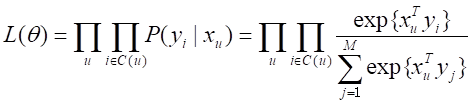

训练阶段:
以用户所有的side information和点击行为数据作为训练样本,最大化以上这个总似然函数,便可以学习出所有lookup table、DNN网络权重和偏置。
预测阶段:

优化算法:
由于这个模型里的softmax需要对库中所有文章进行,文章数量一般都在几十万这个量级,直接优化是不可行的,会非常耗时,所以实际计算中会采用专门针对这种超大规模多分类问题而设计的优化算法,这类算法的名字叫做candidate sampling,其中用得最广泛的是噪声对比估计(NCE,Noise-Contrastive Estimation),它将点击样本的softmax变为多个二分类logistic问题。由于softmax具有sum-to-one的性质,最大化点击样本的概率必然能导致最小化非点击样本的概率,而二分类logistic则没有这个性质,所以需要人为指定负样本,NCE就是一种根据热度随机选取负样本的技术,通过优化NCE损失,可以快速地训练得到模型的所有参数。在实践中,我们采用了TensorFlow提供的函数tf.nn.nce_loss去做候选采样并计算NCE损失。
3.实验和分析
实验设置
为了验证YouTube深度召回模型是否比传统的召回方法更有效,我们做了线上的AB测试实验。其中,深度召回模型离线训练完成以后,将其用于服务端做在线召回,对比的召回方法是基于文章的协同过滤。
训练样本
(1)用户向量计算:
用户最近一段时间的点击历史,包括阅读、点赞、评论、收藏、分享过的文章;
用户最近一段时间的兴趣画像,包括用户的标签、一级分类、二级分类以及对应权重;
用户的人口统计学特征,主要为用户的性别、年龄;
用户的上下文信息,主要为用户的地域信息、当前时间;
(2)正样本选取:
用户在画像统计时间点后一天点击过的文章;
(3)文章向量:
计算用户向量和正样本涉及到的所有文章的word2vec向量;
(4)样本量:
对用户抽样,用于训练的用户数抽样到千万级别,样本总数达到亿级别;
实验结果抽样分析
在上线实验前,我们做了抽样分析。也就是随机抽取若干用户,获取他们的历史点击文章,然后看看 YouTube召回模型和协同过滤模型分别召回了什么文章,主观上去看一下哪个召回更符合用户的历史点击。以下是某个用户的case分析:

从这个用户的历史点击文章可以看出,他的兴趣点有娱乐类、社会类和科技类。协同召回和YouTube召回基本都能召回这些类别相关的文章。相比而言,协同召回的文章在内容上会比较相似,YouTube召回的文章不仅有内容相似的,而且还有主题相关的,在多样性和推广性上会更好一些。比如说,对于协同召回,历史点击了漫威的复联4,召回就有漫威的文章,历史点击了马云,召回也有马云。而对于YouTube召回,“点什么就召回什么”这种现象会少很多,召回的文章既保持了相关性,同时又有一定推广性。比如说,“复联4”召回“疯狂的外星人”,虽然它们不是同一个系列的电影,但是都是新电影。也许该用户并不是特别关心漫威的电影,而只是关心一些新电影,YouTube模型可能识别到了用户的这一兴趣趋向,召回了“疯狂的外星人”。所以主观上会有一种在相关性上做推广的感觉。
然而,以上case分析只是主观上的感受,而且抽样分析不能代表总体。最可靠的还是通过线上的AB测试来评估召回算法,看能否提高线上的核心指标。
在线评估指标
在线AB测试实验的评估指标是算法的点击数、曝光数、点击率以及文章覆盖度。AB测试实验的对照组用的是基于Item的协同过滤算法,即ItemCF,通过jaccard计算item-item相似度,根据用户历史点击过的文章召回相似文章。实验组是YouTube深度召回模型。在ranker档位相同的情况下,实验组和对照组在点击数、曝光数和点击率上的对比如下:

点击率对比

曝光数对比

点击数对比
从在线指标上可以看到,YouTube深度召回的曝光数稍低于协同召回的曝光数,但是点击率会明显高于协同召回的点击率。YouTube召回模型的曝光数大约是协同召回曝光数的80%,但平均点击率比协同召回的平均点击率有大约20%的相对提升。说明YouTube深度召回模型召回的文章比协同召回更能匹配用户的兴趣。
此外,YouTube召回模型在推荐内容的多样性和文章覆盖度上也比协同召回更好一些,在线实验统计结果显示,在推荐出去的去重文章总数上,实验组比对照组的多2%左右,这个数据间接反映了YouTube召回比协同召回找到了更多匹配用户兴趣的文章。
小结
(1)本文介绍了一种基于深度学习的召回模型,并将其与传统召回方法进行了实验对比;
(2)在线实验表明, YouTube召回模型召回文章的点击率显著高于协同过滤召回文章的点击率,说明YouTube召回模型通过画像数据学到了更准确的用户兴趣向量,匹配到更多符合用户兴趣的文章,体现出深度学习模型在特征整合利用和自动学习交叉特征上的优势;
(3)因为YouTube召回模型在计算用户向量时采用的是word2vec预训练的文章向量,而每篇文章入库时都可以计算出其word2vec向量,因此YouTube召回模型能够召回最新入库的文章,做到真正的时新召回。
参考文献
[1]项亮. 推荐系统实践. 北京: 人民邮电出版社, 2012.
[2]KorenY, Bell R, Volinsky C. Matrix factorization techniques for recommender systems.Computer, 2009 (8): 30-37.
[3]HuY, Koren Y, Volinsky C. Collaborative filtering for implicit feedback datasets.ICDM, 2008: 263-272.
[4]BleiD M, Ng A Y, Jordan M I. Latent dirichlet allocation. Journal of machineLearning research, 2003, 3(Jan): 993-1022.
[5]ZhangS, Yao L, Sun A. Deep learning based recommender system: A survey and newperspectives. arXiv preprint arXiv:1707.07435, 2017.
[6]Mikolov,Tomas & Chen, Kai & Corrado, G.s & Dean, Jeffrey. EfficientEstimation of Word Representations in Vector Space. Proceedings of Workshop atICLR. 2013.
[7]MikolovT, Sutskever I, Chen K, et al. Distributed representations of words and phrasesand their compositionality. NIPS.2013: 3111-3119.
[8]PenningtonJ, Socher R, Manning C. Glove: Global vectors for word representation. EMNLP.2014: 1532-1543.
[9]CovingtonP, Adams J, Sargin E. Deep neural networks for youtube recommendations. RecSys.2016: 191-198.
[10]Chen T, Guestrin C. Xgboost: A scalable tree boosting system. SIGKDD. 2016:785-794.
[11]Ke G, Meng Q, Finley T, et al. Lightgbm: A highly efficient gradient boostingdecision tree. NIPS. 2017: 3146-3154.
此文已由腾讯云+社区在各渠道发布
获取更多新鲜技术干货,可以关注我们腾讯云技术社区-云加社区官方号及知乎机构号