上一篇:《Spring Cloud入门教程(六):API服务网关(Zuul) 下》
本人和同事撰写的《Spring Cloud微服务架构开发实战》一书也在京东、当当等书店上架,大家可以点击这里前往购买,多谢大家支持和捧场!

当我们进行微服务架构开发时,通常会根据业务来划分微服务,各业务之间通过REST进行调用。一个用户操作,可能需要很多微服务的协同才能完成,如果在业务调用链路上任何一个微服务出现问题或者网络超时,都会导致功能失败。随着业务越来越多,对于微服务之间的调用链的分析会越来越复杂。
Spring Cloud Sleuth为服务之间调用提供链路追踪。通过Sleuth可以很清楚的了解到一个服务请求经过了哪些服务,每个服务处理花费了多长。从而让我们可以很方便的理清各微服务间的调用关系。此外Sleuth可以帮助我们:
- 耗时分析: 通过Sleuth可以很方便的了解到每个采样请求的耗时,从而分析出哪些服务调用比较耗时;
- 可视化错误: 对于程序未捕捉的异常,可以通过集成Zipkin服务界面上看到;
- 链路优化: 对于调用比较频繁的服务,可以针对这些服务实施一些优化措施。
1. Sleuth+Log 示例代码
我们先用最简单的方式集成Sleuth,把Sleuth所跟踪到的信息输出到日志中。基础代码采用之前所构建的商城项目。
1.1 改造Mall-Web
增加bootstrap.properties文件
为了能够让日志文件可以获取到服务名称,我们需要将原来配置在application.properties中的部分内容移入到bootstrap.properties配置文件中,这是因为SpringBoot在启动时会优先扫描bootstrap配置源,从而能够让日志可以获取到服务名称。
server.port=8080
spring.application.name=MALL-WEB
修改application.properties文件
eureka.client.service-url.defaultZone=http://localhost:8260/eureka
logging.level.org.springframework=INFO
logging.level.org.springframework.web.servlet.DispatcherServlet=DEBUG
这里主要是把DispatcherServlet的日志级别修改为DEBUG。
修改Logback配文件
在resources目录中增加一个名称为: logback-spring.xml的文件,内容如下:
%d{yyyy-MM-dd HH:mm:ss SSS} [%thread] %-5level %logger{36} - %msg%n
DEBUG
${CONSOLE_LOG_PATTERN}
utf8
${LOG_FILE}
${LOG_FILE}.%d{yyyy-MM-dd}.gz
7
${CONSOLE_LOG_PATTERN}
utf8
SpringCloud的参考手册中提到:SLF4J MDC总是会自动进行设置,并且如果使用logback,那么trace/span的id则会立即显示在日志中。其他的日志系统需要配置各自的格式来达到这样的效果。默认的logging.pattern.level设置为%clr(%5p) %clr([${spring.application.name:},%X{X-B3-TraceId:-},%X{X-B3-SpanId:-},%X{X-Span-Export:-}]){yellow} (这也是一个Spring Boot整合logback时有的特性)。 这就意味着,如果使用SLF4J时不需要手工配置该格式,而其它日志系统则必须手工进行配置,否则不会输出。
修改POM文件
在pom.xml文件中增加如下依赖
org.springframework.cloud
spring-cloud-starter-sleuth
1.2 改造Product-Service
改造方式与上面相同。
1.3 启动测试
按照先后顺序分别启动Service-discovery、Product-Service和Mall-Web工程。然后在浏览器中输入: http://localhost:8080/products。然后我们分别观察Mall-Web和Product-Service控制台中日志输出,可以看到类似下面输出:
2017-07-10 21:36:24.802 DEBUG [MALL-WEB,e23abdb6268af95d,e23abdb6268af95d,false] [MALL-WEB,e23abdb6268af95d,e23abdb6268af95d,,false] 92827 --- [nio-8080-exec-4] o.s.web.servlet.DispatcherServlet : DispatcherServlet with name 'dispatcherServlet' processing GET request for [/products]
2017-07-10 21:36:24.838 DEBUG [PRODUCT-SERVICE,e23abdb6268af95d,c68a9b1c2ab8a025,false] [PRODUCT-SERVICE,e23abdb6268af95d,c68a9b1c2ab8a025,e23abdb6268af95d,false] 92782 --- [nio-2100-exec-3] o.s.web.servlet.DispatcherServlet : DispatcherServlet with name 'dispatcherServlet' processing GET request for [/products]
日志中类似 [MALL-WEB,e23abdb6268af95d,e23abdb6268af95d,false]、[PRODUCT-SERVICE,e23abdb6268af95d,c68a9b1c2ab8a025,false] 的日志内容它们的格式为: [appname,traceId,spanId,exportable],也就是Sleuth的跟踪数据。其中:
- appname: 为微服务的服务名称;
- traceId\spanId: 为Sleuth链路追踪的两个术语,后面我们再仔细介绍;
- exportable 是否是发送给Zipkin。
2. Sleuth术语
因为Sleuth是根据Google的Dapper’s论文而来的,所以在术语上也借鉴了Dapper。
- Span: 最基本的工作单元。例如: 发送一个RPC就是一个新的span,同样一次RPC的应答也是。Span通过一个唯一的,长度为64位的ID来作为标识,另外,再使用一个64位ID用于服务调用跟踪。Span也可以带有其他数据,例如:描述,时间戳,键值对标签,起始Span的ID,以及处理ID(通常使用IP地址)等等。 Span有起始和结束,它们用于跟踪时间信息。Span应该都是成对出现的,有始必有终,所以一旦创建了一个span,那就必须在未来某个时间点结束它。
提示: 起始的Span通常被称为:
root span。它的id通常也被作为一个跟踪记录的id。
- Trace: 一个树结构的Span集合。例如:在分布式大数据存储中,可能每一次请求都是一次跟踪记录。
- Annotation: 用于记录一个事件的时间信息。一些基础核心的Annotation用于记录请求的起始和结束时间,例如:
- cs: 客户端发送(Client Sent的缩写)。这个annotation表示一个span的起始;
- sr: 服务端接收(Server Received的缩写)。表示服务端接收到请求,并开始处理。如果减去
cs的时间戳,则可以计算出网络传输耗时。 - ss: 服务端完成请求处理,应答信息被发回客户端(Server Sent的缩写)。如果减去
sr的时间戳,则可以计算出服务端处理请求的耗时。 - cr: 客户端接收(Client Received的缩写)。标志着Span的结束。客户端成功的接收到服务端的应答信息。如果减去
cs的时间戳,则可以计算出请求的响应耗时。
下图,通过可视化的方式描述了Span和Trace的概念:

图中每一个颜色都表示着一个span(总共7个span,从A到G)。它们都有以下这些数据信息:
Trace Id = X
Span Id = D
Client Sent
表示该Span的Trace-Id为X,Span-Id为D。相应的事件为Client Sent。
这些Span的上下级关系可以通过下图来表示:

3. 整合Zipkin服务
Zipkin是一个致力于收集分布式服务的时间数据的分布式跟踪系统。其主要涉及以下四个组件:
- collector: 数据采集;
- storage: 数据存储;
- search: 数据查询;
- UI: 数据展示.
Zipkin提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch。接下来的测试为方便直接采用In-Memory方式进行存储,个人推荐Elasticsearch,特别是后续当我们需要整合ELK时。
ZipKin在Github源码地址为:https://github.com/openzipkin/zipkin。
ZipKin运行环境需要Jdk8支持。
在本篇中我们仅通过Http的方式向Zipkin提供跟踪数据,关于使用stream的方式后续讲到Spring Cloud Bus的时候再说明。我们所要搭建的系统架构如下(做了精简):

3.1 构建Zipkin-Server
编写pom.xml文件
还是继承自我们之前的parent:
4.0.0
twostepsfromjava.cloud
twostepsfromjava-cloud-parent
1.0.0-SNAPSHOT
../parent
zipkin-server
Spring Cloud Sample Projects: Zipkin Server
org.springframework.boot
spring-boot-starter-web
org.springframework.cloud
spring-cloud-starter-eureka
io.zipkin.java
zipkin-server
io.zipkin.java
zipkin-autoconfigure-ui
runtime
org.springframework.boot
spring-boot-maven-plugin
这里需要说明的时zipkin-autoconfigure-ui包提供了可视化界面。
编写启动类
/**
* TwoStepsFromJava Cloud -- Zipkin Server Project
*
* @author CD826([email protected])
* @since 1.0.0
*/
@SpringBootApplication
@EnableZipkinServer
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
这里在Application的注解中增加@EnableZipkinServer,开启Zipkin服务。
编写bootstrap.properties配置文件
server.port=8240
spring.application.name=ZIPKIN-SERVER
我们把Zipkin服务的端口设置为:8240。
3.2 修改Mall-Web工程
修改pom.xml文件
在pom文件中增加以下依赖:
org.springframework.cloud
spring-cloud-starter-zipkin
同时可以删除之前的:
org.springframework.cloud
spring-cloud-starter-sleuth
应为,在spring-cloud-starter-zipkin中已经包含了对spring-cloud-starter-sleuth的依赖。
修改application.properties配置文件
在application.properties增加以下内容:
spring.zipkin.base-url=http://localhost:8240
spring.sleuth.sampler.percentage=1.0
spring.zipkin.base-url指定了Zipkin服务器的地址,spring.sleuth.sampler.percentage将采样比例设置为1.0,也就是全部都需要。关于采样可以参考下面的说明。
3.3 修改Product-Service工程
改造方式与上面相同。
3.4 启动测试
按照先后顺序分别启动Service-discovery、Zipkin-Server、Product-Service和Mall-Web工程。
查看Zipkin服务器
启动后我们可以访问:http://localhost:8240,可以看到如下界面:

说明Zipkin服务器启动成功。
访问几次Mall-Web所提供的服务
我们在浏览器中访问几次Mall-Web所提供的服务,然后转到Zipkin服务器,可以看到如下界面:

可以看到,Zipkin已经获取到几次服务的调用跟踪信息了。我们可以点击其中的一个请求,可以看到如下界面:
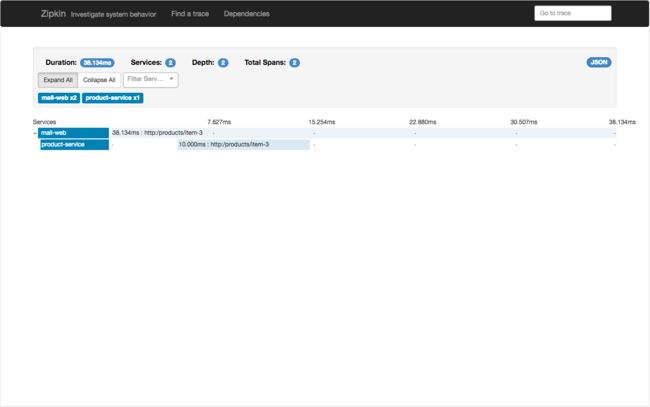
该界面对本次请求进行了更详细的展现。同样我们还可以再点击,以查看更为详细的数据,可以看到如下界面:
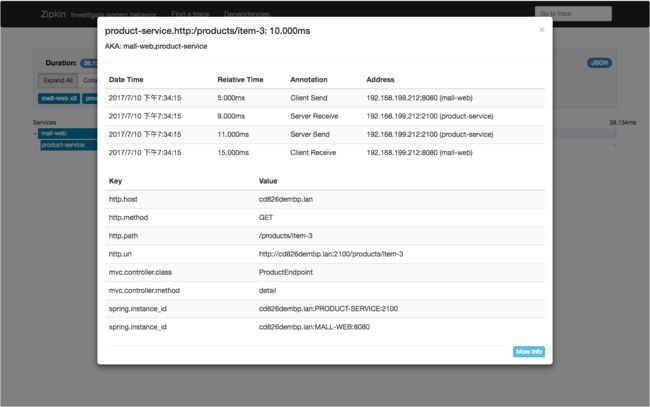
在该界面中我们可以看到之前所讲的各个时间跟踪信息。
在Zipkin界面中我们还可以点击[Dependencies]查看各服务之间的依赖关系,如下图:

错误信息
Zipkin可以在跟踪记录中显示错误信息。当异常抛出并且没有捕获,Zipkin就会自动的换个颜色显示。在跟踪记录的清单中,当看到红色的记录时,就表示有异常抛出了。如上面图中的第一个根据数据就显示了错误信息。我们还可以点击进去以获取更详细的错误信息。
3.5 采样率
在生成环境中,由于业务量比较大,所产生的跟踪数据可能会非常大,如果全部采集一是对业务有一定影响,二是对存储压力也会比较大,所以采样变的很重要。一般来说,我们也不需要把每一个发生的动作都进行记录。
Spring Cloud Sleuth有一个Sampler策略,可以通过这个实现类来控制采样算法。采样器不会阻碍span相关id的产生,但是会对导出以及附加事件标签的相关操作造成影响。 Sleuth默认采样算法的实现是Reservoir sampling,具体的实现类是PercentageBasedSampler,默认的采样比例为: 0.1(即10%)。不过我们可以通过spring.sleuth.sampler.percentage来设置,所设置的值介于0.0到1.0之间,1.0则表示全部采集。
也可以通过实现bean的方式来设置采样为全部采样(AlwaysSampler)或者不采样(NeverSampler):如
@Bean public Sampler defaultSampler() {
return new AlwaysSampler();
}
这也是为何之前我们需要修改
Mall-Web和Product-Service中的spring.sleuth.sampler.percentage配置,如果是默认值很可能我们在Zipkin服务器上根本看不到。
你可以到这里下载本篇的代码。