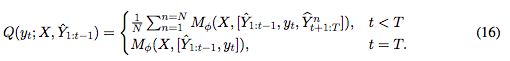论文链接:paper
(......paraphrase翻译成中文不知道是不是这个:释义,这篇博客都用的这个来表示,如果是错的,欢迎纠错哦(*^__^*))
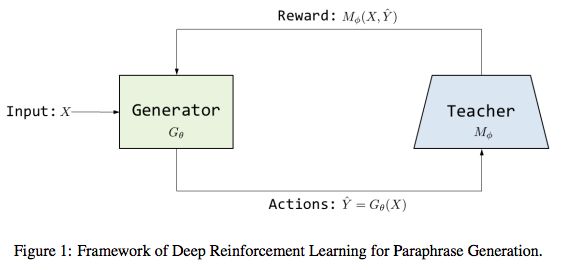
给定一个句子,自动生成释义是NLP中一个重要任务,在很多应用中扮演重要角色,例如question answering问答, information retrieval信息检索,dialogue对话。本文用一个深度强化学习方法来做释义生成,包含一个generator和一个teacher。generator是一个sequence-to-sequence框架,可以对给定句子生成释义。teacher是一个深度神经网络模型,可以决定句子之间是否相互是释义。
在构建来generator和teacher之后,the generator is further fine-tuned by reinforcement learning in which the reward is given by a teacher. 研究表明teacher可以给generator提供精确的知道,并且引导generator生成更准确的释义。
Introduction:
paraphrase是具有相同意义但是不同表达的文本。释义在很多场景中都是非常重要的部分,例如基于检索的qa问答,web搜索的查询重写,为面向任务的对话做数据增强。然而由于自然语言的灵活性和多样性,自动生成准确和多种释义具有挑战性。
传统的方法:基于规则,基于同义词词典,statistical machine translation(SMT)
近期,基于神经网络的seq2seq学习在很多NLP任务上都取得了不错的效果,包括机器翻译,短文交谈(short-text conversation),text summarization,question answering。
与最近出现的技术结合,例如attention机制,copying机制和coverage模型。seq2seq模型更加有效。
释义生成可以看作是sequence-to-sequence学习的问题,给定a collection of pairs of paraphrases as training data.
sequence-to-sequence模型通常用最大化给定一个输入序列,预测输出序列的对数似然,训练集和测试集可能会包含矛盾。2015年Ranzato提出了强化学习(reinforcement learning),来自REINFORCE算法,直接优化序列级别的metric,例如BLEU或ROUGE。然而,使用这些metrics作为reward function会有问题,因为所有的metrics是基于和human references的词汇相似度,不能很好的代表paraphrase相似度。所以这种方法是次优的
本文,使用强化学习,用policy gradient来训练generator。不使用evaluation metric,本文使用深度匹配网络(deep matching network)建模reward function,可以区分positive和negative的例子。
generator:attentive Seq2Seq 架构,结合copy and coverage mechanisms。
teacher:deep matching network based on the decomposable attention model。
Background:
释义生成可以看作是seq2seq的转型问题。给定一句话X=[x1, x2, ..., xL]长度为L,生成另一个输出序列Y=[y1, y2,... yT] 长度为T,输入和输出有相同含义。有不同粒度的,从phrase短语到passage文章,本文针对句子级别的释义问题。
Neural Sequence-to-Sequence Models with Attention
Seq2Seq模型是基于encoder-decoder框架的,都是Recurrent Neural Network(RNN)。encoder将输入序列X转换成一系列隐状态H=[h1, ... hL], hi=fh(xi, hi-1). decoder基于states和之前的单词yt-1,预测下一个词by sampleing
st是decoder的状态,ct是context vector
attention机制:
根据有权重的encoder states来计算context vector:
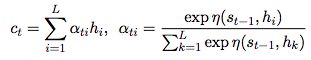
ati是attention权重, attention function
attention function:which can be a feed-forward neural network and jointly trained within the whole network.
Seq2Seq模型通过最大化对数似然来训练:
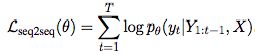
在计算条件概率时,常规方法是使用yt-1的真实值,而不是模型生成的,为了避免符合错误。这个方法称为teacher forcing.
Incorporating copying and coverage mechanism
有时会需要从输入序列复制一些词,具体来说,decoder除了会从fixed-size vocabulary,也会需要从输入序列选择词。最后decoder中下一个词的概率是混合模型:
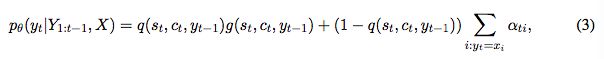
q(st, ct, yt-1)是一个二元分类器,管理generation mode和copy mode之间的切换概率。
受到单词重复的问题影响,因此在目标函数中加入coverage loss:
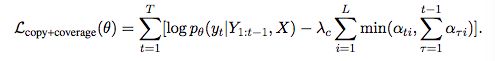
Neural Networks for Matching sentences:
另一个问题是paraphrase identification,可以决定一对句子是否是paraphrases。 本文方法是通过训练一个matching模型,这个模型可以identify paraphrases。然后tune the paraphrase generator based on the feedback from the matching model, 根据matching模型的反馈来调整generator。
选择一个decomposable attention model模型,来计算两个句子之间的相似度,给定两个句子X和Y,这个模型通过以下三步来计算:
1. attend,两个句子互相inter-attended....(X﹏X 不懂啊...直接上公式)
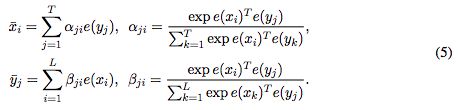
e(.)是维度为d的word embedding。公式计算的别分是xi和yi的inter-attentive vector
2. Compare,对每个单词,embedding vector与attentive vector合并,通过一个前向神经网络fc
3. Aggregate,两个序列分别求和,然后用线性分类fa
z是X和Y之间的匹配度
除此之外,positional encoding:

代表位置i的position encoding vector
模型:
传统seq2seq模型的问题:1)需要大量数据来训练模型 2)使用teacher,训练和预测的矛盾(也称为exposure bias)随着生成的序列加速导致错误。 3)使用对数似然作为目标函数对这个问题不是首选项。paraphrasing的最终目标是根据输入句子生成多个相同意思的句子,而不是选取最貌似有理的seq2seq的翻译。为了解决这个问题,本文提出在强化学习的框架下去优化seq2seq模型。而不是使用一个基于词典的evaluation metric作为目标,同时,本文学习了一个matching网络,作为teacher,可以给generator提供可靠的信号来fine-tune。
generator G:最大化训练future expected reward,which can be obtained in various manner。
reward function的选择可以是evaluation metric 例如BLEU或ROUGE,对比生成的序列和reference。
在RL setting中,生成下一个词被定义为一个action,decoding概率产生了一个stochastic policy(随机策略):
rt是t时刻的reward
RL的目标是找到一个policy,可以最大化expected return:
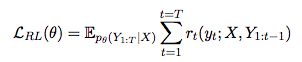
在序列生成的任务中,reward通常在序列的结尾获得,这会带来系数的reward signal。受到reward shaping的启发,使用value function作为一个surrogate(代理),定义为每个时间点的expected cumulative reward。
value function约等于每一时间点的蒙特卡洛模拟的总计:
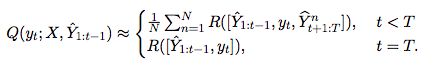
使用ROUGE-2 score 作为reward,即
根据policy gradient theorem(policy梯度定理),expected return的梯度为:
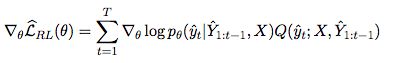
baseline function b:
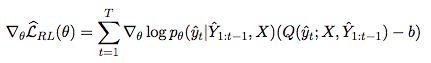
本文使用的baseline function是moving average,而不是一个分离的神经网络。
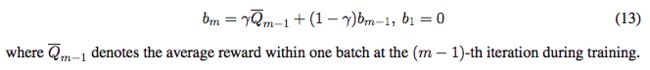
Learning Reward with Deep Matching Network:
基于decomposable-attention architecture:
用二元交叉熵损失训练M:
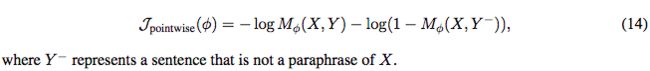
也可以使用margin-based ranking loss:
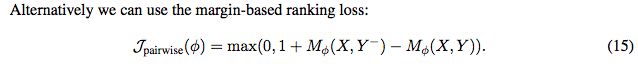
目标函数,使用不同的reward或者the value function