在计算机程序中的同步互斥就像生活中随处可见的排队等服务一样,像在医院、餐厅、机场等,都会有资源不足的情况,在同一时间能够提供的服务远低于需求量,而且同一时间只能为有限个客户提供服务,这就需要人们遵守规则等待,不能打起来。这就是最为人们熟知的就是生产者-消费者问题,也有“读者-写者”等若干个版本,但它们本质都是一样为了解决共享资源里的同步和互斥问题。
这里不会像大多数操作系统教程里面那样从锁、信号量、互斥量开始讲解解决同步互斥问题的基本原则和方法,我想从一般linux编程的角度,谈谈在项目中大多如何解决这类问题,以及影响效率、资源使用的因素是什么。
1.锁
解决对共享资源使用时发生冲突的方式,最直接但有效的方式就是加锁,这就像我们的一医一患的诊室一样,为用户提供服务时,锁上门,将其他等待的用户阻止在门外。在大型linux项目中使用的比较常见的锁有,自旋锁(spinlock)、读写锁(rwlock)和RCU(Read-Copy Update)。
spinlock
对于自旋锁的概念有一段来自百度百科的解释:
何谓自旋锁?它是为实现保护共享资源而提出一种锁机制。其实,自旋锁与互斥锁比较类似,它们都是为了解决对某项资源的互斥使用。无论是互斥锁,还是自旋锁,在任何时刻,最多只能有一个保持者,也就说,在任何时刻最多只能有一个执行单元获得锁。但是两者在调度机制上略有不同。对于互斥锁,如果资源已经被占用,资源申请者只能进入睡眠状态。但是自旋锁不会引起调用者睡眠,如果自旋锁已经被别的执行单元保持,调用者就一直循环在那里看是否该自旋锁的保持者已经释放了锁,"自旋"一词就是因此而得名。
通过这段介绍我们也可以很清楚地看到自旋锁的缺点:CPU资源利用率低,因为一直检查锁的状态,所以只适用于短时间等待的场景,否则造成CPU资源利用率降低。
它的另一个缺点是不正确的使用会引发死锁,事实上这不仅仅是自旋锁的问题,所有的同步互斥解决方法不正确使用都会引发这个问题。但在自旋锁中最常见的情况是递归使用一个自旋锁,即如果一个已经拥有某个自旋锁的CPU 想第二次获得这个自旋锁,则该CPU 将死锁。此外,如果进程获得自旋锁之后再阻塞,也有可能导致死锁的发生。copy_from_user()、copy_to_user()和kmalloc()等函数都有可能引起阻塞,因此在自旋锁的占用期间不能调用这些函数[1]。
在linux内核函数中,自旋锁的实现与体系结构硬相关,在对于体系结构的
spinlock_t lock = SPIN_LOCK_UNLOCKED;
spin_lock(&lock);
/*临界区业务逻辑代码*/
spin_unlock(&lock);
自旋锁的加解锁API远不止这两个,其解决的是多核情况下多个CPU之间的竞争问题,而单CPU模式下不需要自旋锁,这也意味着它的实现有很多涉及硬件指令级的操作,像中断还有CAS(compare and swap),CAS是有名的无锁实现,这会在最后章节里面讲。
其他的API可以查看对应的文档,直接使用linux自旋锁有两点要注意:
1)自旋锁是不可递归的(原因上面讲过)
2)线程获取自旋锁之前,要禁止当前处理器上的中断。
上述第二点有这样一种情况,当一个线程获取了自旋锁以后,在临界区中被中断处理程序打断,中断处理程序正好也要获取这个锁,而造成中断处理程序和当前线程互相等待的死锁。
rwlock
在一些很常见的操作中,会出现频繁地读取一个变量,但是写操作很少的情况。例如,OVS中对流表的读取,每个数据包都会读取流表进行五元组匹配查找,但是只有有限情况下,像手动增删流表项,才会触发对流表结构的写操作。这种情况下,对于多读操作是可以并行的,互不干扰,但是写与读互斥。这种场景下一般使用一种特殊的自旋锁,读写锁来实现。
上面的描述基本概况了读写锁的几个特性:
1)读操作资源共享
2)写操作之间互斥
3)写操作与读操作互斥
这在大多操作系统教程中用的是读者-写者问题来描述这一事实,并且针对读者优先级更高还是写者优先级更高指定不同的策略。
在Linux实现中,与自旋锁类似,读写锁rwlock的相关API在
RCU
RCU(Read-Copy Update)也是在大型项目中常用的一种读写锁,它的出现主要是为了解决上述普通读写锁中,写进程对临界区写操作时,阻塞了所有的读操作这一问题。试想一下,在OVS流表匹配中,如果一个写操作引发了所有的读阻塞,那是不是那一时刻流量中断了?这将引发严重的问题。所以RCU的设计就是为了让写操作不要阻塞读操作。
有篇博客对RCU的分析总结非常透彻[2],其中总结了RCU有三个要素:
1)读标志。如果一个Reader企图占据一把RCU锁,它是不需要付出任何代价的,只需要设置一个标志,让外界知道有Reader在占据这把RCU锁,多个Reader可以共同持有一把RCU锁。
2)写时拷贝。如果有一个Write企图更新RCU锁所保护的数据,那么它会首先查看该RCU锁的读标志,如果有该标志,说明有最少一个Reader持有了该RCU锁,它需要对原始数据make a copy,写这个副本并将更新过的副本保存在某处,等待时机用该副本更新原始数据。
3)更新时机。这个时机就是用副本更新原始数据的时间点,这个时间点如何确定是RCU锁实现的算法核心,它直接可以确定所有的数据结构。确切来讲,Writer必须 waitting for all readers leaving,方可Update原始数据。
这在linux具体实现中也有很多版本迭代,有利于抢占禁止的、阶段计数器的。但是最基本的机理就如同上面三要素所说。可以说所有关于多读少写的场景都可以利用RCU获取连续不中断地运行。
2.原子操作
原子本意是不可再分的粒子,因此在操作系统中用此名字来命名最基本的操作单一,即如果一个线程执行原子操作,要么完全执行完,要么完全没有开始执行,期间不会被任何别的线程打断。
原子操作
原子操作依赖于硬件处理器实现,早在单处理器时代,原子操作被认为是单条指令;而在我们今天越来越复杂的多核CPU时代,即使是运行单条指令也不能保证它不会被干扰,因为多核CPU不可避免的共享总线,而一条指令或许就伴随着访存操作等。
在x86平台上,CPU提供三种独立的原子锁机制:原子保证操作、加LOCK指令前缀和缓存一致性协议。其中原子保证操作一般用于基础内存事务,比方说一个字节的读写或者对于边界对齐是字节、字、双字、四字等读写都可以保证是原子操作。加LOCK指令前缀主要是一种总线锁,其原始实现是当前CPU拉低总线电平锁住总线,而后不断完善性能已有了新的方式代替,但实现的功能还是一样。而缓存一致性协议,又被称为是MESI协议,由于我们CPU有自己的cache缓存,而存在内存中的数据可能会被多个CPU利用,所以需要一种防止多个处理器同时修改相同内存地址的方式。
关于cache的MESI协议可以参考任何计算机体系结构教材。这里需要特别提到一个指令CMPXCHG,它的语义是实现比较并交换操作数(CAS,Compare And Set)。CAS操作需要输入两个数值,一个旧值(期望操作前的值)和一个新值,在操作期间先比较下旧值有没有发生变化,如果没有发生变化,才交换新值,发生了变化则不交换。这是很多无锁设计的基础,下一章节会详细讲述DPDK中无锁队列的设计。
在Linux内核中,提供了两组原子操作的接口:一组是针对整数的操作;一组是针对位运算的操作。
针对整数的原子操作通常只处理atomic_t类型的数据,没有C语言中的int型,该类型可以被认为是一个24位的数据,通常用于实现计数器。而且原子整数操作往往是内联函数,通过内嵌汇编实现。另一方面如果某个函数是原子的,它也通常被定义为一个宏。
原子位操作通常是实现原子地翻转、清空、设置某一地址处n位的值。
内存屏障
在处理器和编译优化经过了几十年的发展,已经为了获取更高的性能变得非常复杂,一些时候甚至编写C语言程序的程序员自己也不知道哪条语句会被先执行。那是因为在O2甚至O3的优化下,循环展开、写入折叠、乱序执行将CPU性能发挥到极致,但是也带来了一些问题,只有弱序类型的程序才可以获取这样更高的性能。而需要保序的程序,不能保证一些指令会在特定指令之前执行完。
为了解决这一问题而引入了内存屏障的概念,虽然分为三种:读写屏障、读屏障和写屏障。但其实现上都是调用__sync_synchronize(),而内核中该函数对应着的正是MFENCE这个序列化加载和存储操作汇编指令。此序列化确保:在全局范围内,MFENCE前后的任何加载和存储操作以MFENCE为界限,严格保序。
*(volatile uint16_t *)&vq->used->idx += count;
vq->last_used_idx = res_end_idx;
rte_mb(); //DPDK封装的内存屏障,就是使用__sync_synchronize实现
if (!(vq->avail->flags & VRING_AVAIL_F_NO_INTERRUPT))
eventfd_write(vq->callfd, (eventfd_t)1);
上面代码所示是vhost-user数据包收发中一个典型应用场景,每次后端发送完了数据包,更改了avail指针,然后才可以发出eventfd通知前端接收数据包。这个顺序如果乱了,将会引发错误。
3.无锁队列
在介绍无锁队列之前,我想先为锁正名,上面介绍到锁的提出的解决临界区的争端,会有些线程需要等待锁被释放,因此有人觉得锁是性能杀手,是锁导致了性能的下降。实际上这是不完全正确的,大多数时候慢的不是锁本身,而是等锁的时间,这种情况下换成其他的方式也不能解决你的问题。这种情况下最佳的方式还是避免竞争,相当于说你自己的业务处理逻辑的问题,造成大量互相竞争等待甚至锁死的情况,不管是使用锁还是其他的方式,都不会提升性能。
对于无锁队列的实现,由于体系结构以及编译等问题,实际上在实现上做到没有bug是很难的。很多时候一个程序运行几十次、上百次没有任何异常,但是运行上万次可能会出现一次异常,甚至在有些场景下会产生和体系结构硬相关的异常。比方说一个我们在实际运行中遇到的bug,在核隔离情况下,一个隔离核使用CAS指令与非隔离核在缓存MESI协议中有一些同步问题。
上面讲过的CAS操作,就是一种实现无锁队列的基础技术,这里以DPDK为例讲述其无锁队列的实现方法。以下摘自DPDK官方文档[3]:
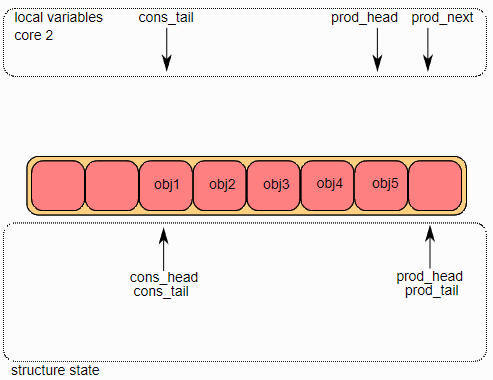
DPDK rte_ring这一环形结构由两个头尾组成,一组由生产者使用,一组由消费者使用。下图中分别用prod_head、prod_tail、cons_head和cons_tail来指代他们。关于该无锁队列的操作主要分为四点:单生产者入队、单消费者出队、多生产者入队和多消费者出队。下面只介绍前三个,多消费者出队与前面类似。
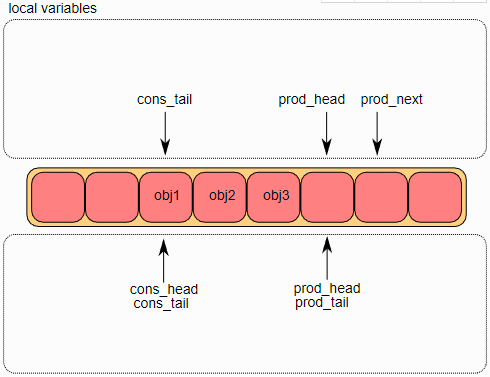
单生产者入队
首先将ring->prod_head和ring->cons_tail复制到局部变量中。prod_next局部变量指向下一个对象,或者在批量入队的情况下指向下几个对象。如果ring中没有足够的空间(通过检查cons_tail检测到),则返回错误。
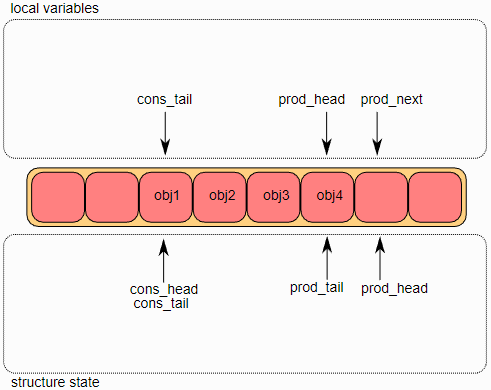
第二步是修改
ring结构中的
ring->prod_head,使其指向与
prod_next相同的位置。指向添加的对象的指针被拷贝到
ring(obj4)中。
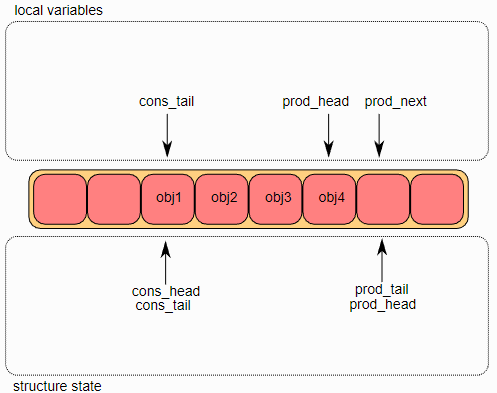
将对象添加到
ring中后,
ring->prod_tail将被修改为指向与
ring->prod_head相同的位置,入队操作完成。
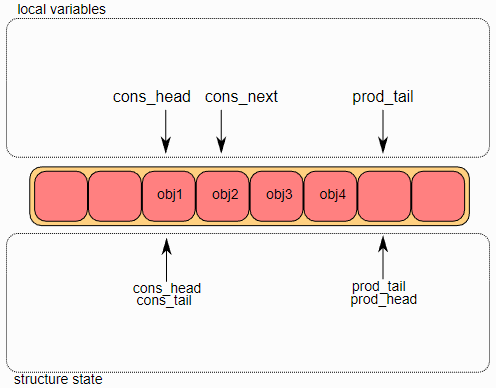
单消费者出队
首先,将ring->cons_head和ring->prod_tail复制到局部变量中。cons_next局部变量指向ring的下一个对象,或者在批量出队的情况下指向下几个对象。如果ring中没有足够的对象(通过检查prod_tail检测到这种情况),则会返回错误。
第二步是修改
ring->cons_head指向与
cons_next相同的位置。指向出队对象
(obj1)的指针被拷贝到一个临时用户定义的指针中。
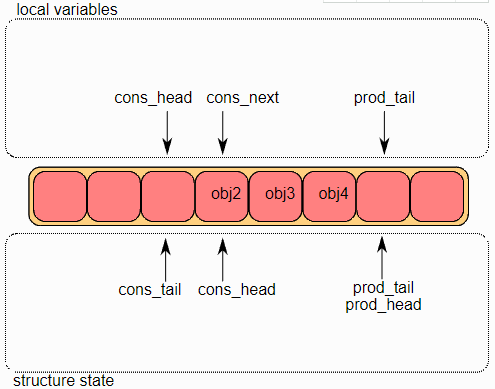
最后,修改
ring->cons_tail以指向与
ring->cons_head相同的位置,出列操作完成。
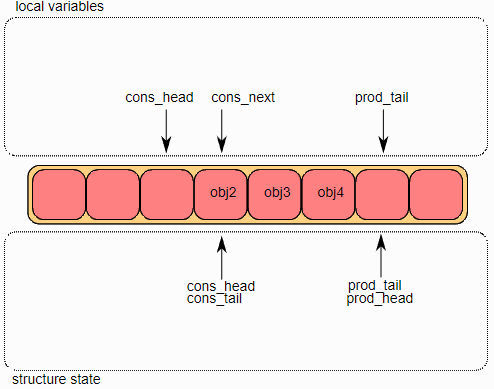
多生产者入队
这里模拟两个生产者同时进行入队操作。
在两个core上,ring->prod_head和ring->cons_tail被复制到局部变量中。prod_next局部变量指向ring的下一个对象,或者在批量入队的情况下指向下几个对象。如果ring中没有足够的空间(通过检查cons_tail检测到),则返回错误。
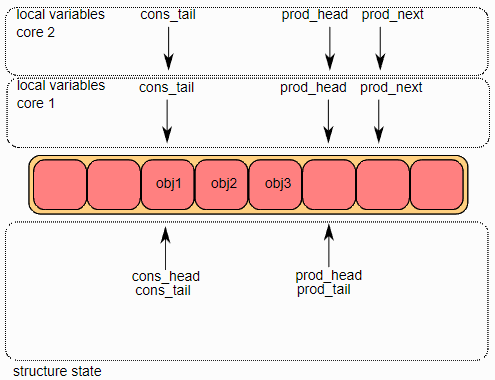
第二步是修改ring->prod_head,使其指向与prod_next相同的位置。此操作使用CAS指令完成,该指令以原子方式执行以下操作:
如果
ring->prod_head与局部变量prod_head不同,则CAS操作失败,并且代码在第一步重新启动;否则,ring->prod_head设置为局部变量prod_next,CAS操作成功,处理继续。在图中,操作在core 1上成功,在core 2上重新启动第一步。

第三步,CAS操作在core 2取得成功,core 1更新ring的一个元素(obj4),core 2更新另一个元素(obj5)。
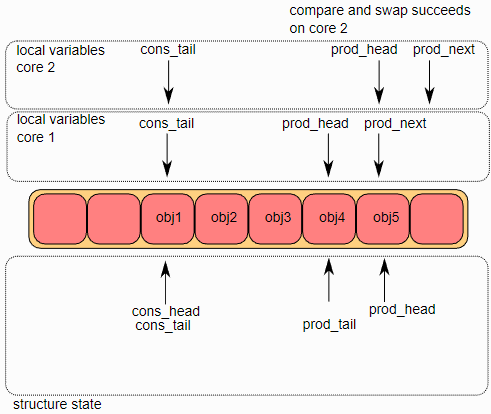
第四步,每个core都想更新ring->prod_tail。只有当ring->prod_tail等于prod_head局部变量,core才能更新它。这个操作只在core 1上完成。
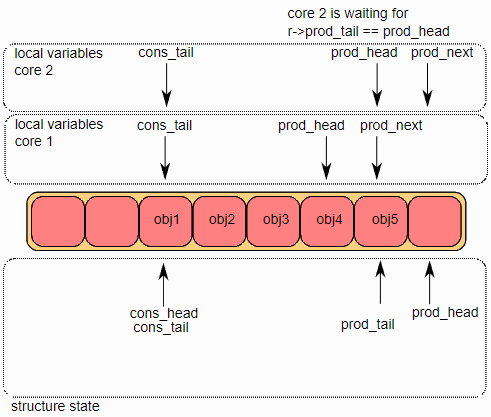
一旦ring->prod_tail在core 1上更新完成,core 2也将被允许更新它。这个操作也在core 2上完成了。
同步互斥机制的基本方法介绍完了,我们现在已有这么多种策略保证代码正确高效地运行。在选择哪种策略的时候,应当根据使用场景的具体情况而定,另外每种策略虽然内核有自己的实现,但都可以实现在用户空间高效地执行。人们对临界区同步互斥问题的研究还在继续。
引用:
[1] "Algorithms for Scalable Synchronization on Shared-Memory Multiprocessors" by John M. Mellor-Crummey and Michael L. Scott. This paper received the 2006 Dijkstra Prize in Distributed Computing.
[2] Linux内核RCU(Read Copy Update)锁简析, https://blog.51cto.com/dog250/1673351
[3] DPDK rte_ring文档,http://doc.dpdk.org/guides/prog_guide/ring_lib.html
[4]《深入浅出DPDK》