Deploying JupyterHub for Education
By Jessica Hamrick - Posted on Mar 24 2015
docker,education,ipython,jupyter,python
As a PhD student at UC Berkeley, my duties involve some amount of teaching; so, this semester (Spring 2015), as well as last spring, I have been a teaching assistant for a class taught by my advisor,Tom Griffiths. The class, called Computational Models of Cognition (COGSCI 131), aims to introduce students to computational models of human behavior. The problem sets are a mixture of simple programming assignments—usually requiring students to implement pieces of different models—and written answers, in which students report and interpret the results of their code.
In the past, the problem sets were written in MATLAB. This year, however, we decided to make the switch to Python. In particular, we decided that theIPython/Jupyter notebookwould be an ideal format for the assignments. The notebook is a cross-platform, browser-based application that seamlessly interleaves code, text, and images. With the notebook, it is possible for us to write instructions in the notebook, include a coding exercise after the instructions, and then ask for their interpretation of the results immediately after that. For an example of what the notebook looks like, you can check outtry.jupyter.orgfor a demo.
There were two options for using the notebook in the class. The first (and more traditional) method would be to require students to install the notebook themselves on their own computers. To run it, they would have to first start the IPython notebook server from the command line, which would then give them access to the notebook files through the browser. The second (and more experimental) method would be to launch a server runningJupyterHub, which is a platform for hosting notebooks on a server with multiple users. Importantly, JupyterHub requires no installation on the part of the user—they simply go to a website, login, and immediately have access to the IPython notebook:
For a class of 220 students, ensuring that everybody would be able to install the correct version of the notebook—with the correct versions of the necessary packages likeNumPy,SciPy, andMatplotlib—would have been nearly impossible. On top of that, many students in this class have not used the command line before, and requiring that they use it to launch the notebook seemed both unfair to them, as well as a headache for us. In light of this, the second option of using JupyterHub seemed like the more attractive and feasible option.
Of course, when I say "attractive and feasible", I really mean "exciting and challenging." As of November 2014, when I made final the decision to go with JupyterHub, there were many pieces that still needed to be assembled for this to work—JupyterHub itself had only just been created! Over the course of a few months and with the help of a couple core IPython developers (Min RKandKyle Kelley), I managed to pull together a setup that has actually worked remarkably well.
Getting started
Min and Kyle had already started using Docker with IPython notebooks for thetmpnb demo(now running astry.jupyter.org), and suggested that I start from there with the setup for my class. However, I barely knew what Docker was at that point, so my first task was to figure out what it was all about and learn how to use it. I started by playing around with the existing Docker images forJupyterHubandIPython, and going forward continued to figure stuff out as I went along. Nothing like learning to swim by diving in head-first!
While I began learning what Docker was, Kyle got me set up with some servers on Rackspace that I could use to start trying things out. Kyle also pointed me in the direction of Ansible, and got me started with that by forking and modifying thetmpnb Ansible scriptsas a basis for my class' setup. These scripts initially just set up a proxy server to forward a SSL connection to JupyterHub using nginx, and got a plain install of JupyterHub itself up and running. Over time, I figured out how Ansible worked and modified the scripts to handlethe entire deploymentfor my class (including releasing, collecting, and returning assignments).
Launching Docker from Docker
JupyterHub has two main configurable components: theauthenticator, which handle authenticating users, and thespawner, which launches the notebook server for each user. There was already aGitHub authenticatorthat I could use (as long as the students signed up for GitHub accounts), as well as aDocker spawnerwhich spawned the user servers inside Docker containers. As I already mentioned, there was also an existing Docker image for running JupyterHub, but at this point no one had tried to run JupyterHub in a Docker containeranduse the Docker spawner to launch user servers.
Thus, my next task: figuring out how to get Docker containers to launch other Docker containers. This actually ended up not being too difficult in practice because Docker runs on a UNIX socket (/var/run/docker.sock). This socket can be mounted inside the hub container, giving it access to the Docker server running on the host machine. With this configuration, Docker containers for the users would be launched on the same machine, side-by-side with the hub.
Users in Docker containers
While convenient in some ways, using Docker containers for the user servers created other challenges: most notably, getting users in the containers themselves. The existing Docker spawner just created ajupyteruser with a pre-set home directory, but in my case, I needed users' home directories to existoutsidethe Docker containers, and to be mounted on demand, so that they could persist throughout the entire semester. However, the home directories on the host machine had to be owned by the same user (with the same UID) as the one running inside the Docker container, or else the user in the Docker container wouldn't be able to read and write to their homedir. Thus, I had to figure out a way to run the Docker containers with the same users as the ones that existed on the host system. I considered two options for this:
Build a different image for each user and create that user inside the container at build time. Then, run the container as that user.
Build a single image that runs as root, creates the user at runtime, and then runs the notebook server itself as the user withsudo.
Neither option was particularly attractive: the first requires many expensive build operations, while the second is less secure. I ended up going with the second option, but in practice the bulk of the implementation would have been the same in that they both required that the UID of the user in the container match that of the user on the host. This meant I ended up jumping through alotof hoops. JupyterHub didn't know the UIDs of users by default (because JupyterHub doesn't have to necessarily use system users), and couldn't easily get them because it was running inside a Docker container. To solve this, Min wrote asimple REST servicethat allowed JupyterHub to create and query users on the host system, and I wrote asystem user spawnerthat extended the Docker spawner to mount home directories and pass along the username and UID to the container in environment variables. The spawner could then launch asystem user Docker imagewhich created the user with the appropriate UID on startup.
In the future, I will use a third and much cleaner option: change the ownership of the files on the host to thejupyteruser. This wouldn't work if I actually needed the users to have accounts on the host system, but at least in my case, that's not a requirement (though at the time, I was under the impression that it was, hence why this option wasn't even under consideration at the beginning). The only real constraint of this third option is that the spawner knows which home directory to mount—otherwise students would have access to all the files of all other students—but this is a constraint that already exists and requires no special machinery.
Load balancing with Docker Swarm
At this point, the setup worked by running JupyterHub in a Docker container, and launching notebook servers in Docker containers on the same machine. Unfortunately, with 220 users, one machine wasn't going to cut it—so, what I really wanted to do was to launch the user Docker containers ondifferentmachines. I wanted a solution for this which wouldn't require too much orchestration on my part of figuring out what machines were available or monitoring available resources on each of the machines. Serendipitously, when I searched for ways to do load-balancing with Docker, I found that they had just announced a new project calledSwarm, which turned out to be exactly what I wanted (of course, at the time Swarm was still in pre-beta, but I figured: what the heck, every other piece of software that I'm using is pre-beta, too!).
Swarm is a service that acts just like the Docker server, except that it knows about other machines and will start up Docker containers on those nodes rather than the host. To use Swarm on the hub server, I needed to run Docker on the nodes using public-facing ports so that Swarm could connect to them. Having public-facing ports without SSL/TLS authentication is a terrible idea, so I needed to run Docker on the nodes with--tlsverifyand then have Swarm present valid certificates. As an additional layer of complexity, Swarm at the time could only connect to nodes via their IP address (rather than their domain), which required generating certificates with a SAN (Subject Alternative Name) corresponding to the IP address.
Persistent files across machines
Once I got Swarm up and running, I had to ensure that regardless of the node their container was started on, users would have access to the same files. Kyle suggested two options:
Run a NFS server on the hub machine along with NFS clients on each of the nodes, thereby mirroring all of the files to each machine.
Have cloud block storage for each user, and mount that on demand.
Unfortunately, cloud block storage currently only works with Rackspace VMs, and we had been planning to use OnMetal servers because they are more resource-efficient. So, we ended up going with the first option (in the future, though, cloud block storage would probably be the better option). Kyle put together a prototype NFS setup, which served the entirety of/homein NFS, and then mounted it (also at/home) on each of the node servers. Thus, when the Docker containers went to mount the home directory of their user, they were guaranteed to always have access to the correct files, regardless of the machine they were running on.
Using NFS meant that I also needed to come up with my own backup solution for students' files. The easiest option was to back up to a Rackspace Cloud Files container usingDuplicitywith GPG encryption. This works mostly out-of-the-box, because Cloud Files are build on OpenStack, which is already supported by Duplicity. The trickiest part about this was actually just figuring out what the appropriate URLs and environment variables were that needed to get passed to Duplicity (for reference, the URL needs to becf+http://$CONTAINER_NAMEand the environment variables that must be present areCLOUDFILES_USERNAMEandCLOUDFILES_APIKEY).
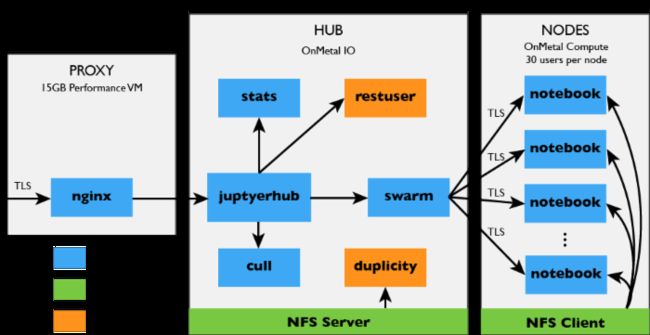
The big picture
After getting all the previous parts working, we had:
nginx running in a Docker container on the proxy server,
JupyterHub running in a Docker container on the hub server,
Swarm running in a different Docker container on the hub and starting up other containers on the node servers,
NFS host on the hub and NFS clients on the nodes, and
Duplicity backup running as a cron job on the hub.
Min added a few additional helper services, including anactivity logger(so we could keep track of how many people were using the server over time) and aculling service(to shut down notebook servers that hadn't been accessed in a while), both of which were also run in Docker containers.
Here is the full, glorious setup:
Going live!
The server for the class officially went live when the semester started at the end of January. Since then, things have been mostly smooth sailing, with only one major period of unplanned downtime due to a bug—and even this outage was only an hour or two. Having the students use the server, rather than installing IPython on their own computers, has been incredibly convenient despite the effort that it took to get it set up. We can guarantee that all students are working in the same environment, with the same library versions, and we can (almost) guarantee that when we collect their assignments for grading, they will have the filenames and directory structure that we expect (this might not sound like much, but when students have to manually upload submissions, there will inevitably be some that change filenames, submit the wrong version, or forget to include files). Finally, when we are ready to give students feedback, we can just upload their graded assignments to the server.
I'm really happy with how well this has worked out this semester, and how much I learned in the process. My class has certainly benefited a great deal from using the notebook: this setup along withnbgrader—which is a tool I've written withBrian Grangerfor grading IPython notebooks—has removed a lot of the pain of running a large class with programming assignments.
Many thanks go to Min and Kyle, who were a tremendous help in getting everything setup, to Rackspace for the servers, to Docker and the Swarm team, and—of course—to the IPython/Jupyter team in general for creating the notebook in the first place.