软件版本
- spark 2.0.2
- 2.6.0-cdh5.9.0
一.编译
参考官网配置即可:
http://spark.apache.org/docs/latest/running-on-yarn.html
下载spark2.0.2的源码后在根目录进行编译
dev/make-distribution.sh \
-Phive -Phive-thriftserver \
-Dhadoop.version=2.6.0-cdh5.9.0 \
-Dyarn.version=2.6.0-cdh5.9.0 \
--tgz -Pyarn
可能需要配置仓库
cloudera
https://repository.cloudera.com/artifactory/cloudera-repos/
二.配置
在yarn上运行spark需要在spark-env.sh或环境变量中配置HADOOP_CONF_DIR或YARN_CONF_DIR目录指向hadoop的配置文件。
spark-default.conf中配置spark.yarn.jars指向hdfs上的spark需要的jar包。如果不配置该参数,每次启动spark程序将会将driver端的SPARK_HOME打包上传分发到各个节点。
spark.yarn.jars hdfs://clusterName/spark/spark2/jars/*
启动spark程序时,其他节点会自动去下载这些包并进行缓存,下次启动如果包没有变化则会直接读取本地缓存的包。
缓存清理间隔在yarn-site.xml通过yarn.nodemanager.localizer.cache.cleanip.interval-ms配置
启动spark-shell,指定master为yarn,默认为client模式 :
/usr/install/spark2/bin/spark-shell
--master yarn
--deploy-mode client
--executor-memory 1g
--executor-cores 1
--driver-memory 1g
--queue test (默认队列是default)
Dynamic allocation
动态申请/释放executor可以提高集群资源利用率。适用于spark-shell这种交互或长时任务等场景。
在spark-default.conf中配置
spark.dynamicAllocation.enabled true
spark.shuffle.service.enabled true
spark.dynamicAllocation.minExecutors 0
spark.dynamicAllocation.maxExecutors 20
External Shuffle Service
在yarn-site.xml中修改参数(如果是使用cdh,在 yarn-site.xml的 YARN 服务高级配置代码段中添加xml片段,重启nodeManager即可。)
yarn.nodemanager.aux-services
mapreduce_shuffle,spark_shuffle
yarn.nodemanager.aux-services.spark_shuffle.class
org.apache.spark.network.yarn.YarnShuffleService
spark.shuffle.service.port
7338
tip: 为了减少shuffle service的gc带来的性能影响,可以提高NodeManager的内存,默认只有1G。
如果没有成功开启External shuffle service,提交任务将会报错。
Caused by: java.io.IOException: Failed to send RPC 7920194824462016141 to /172.27.1.63:41034: java.nio.channels.ClosedChannelException
shuffle文件目录
Spark shuffle等临时文件写入目录的设置
cluster mode
spark.local.dirs路径被yarn.nodemanager.local-dirs取代,shuffle文件将会写入到yarn配置的目录下。
client mode
driver 没有在container中启动,因此依旧使用spark.local.dirs配置,executor在container中启动,使用的是yarn.nodemanager.local-dirs的配置。
在nodeManager的日志中可以看到,blockmgr已经写入yarn.nodemanager.local-dirs所配置的目录
ExternalShuffleBlockResolver
Registered executor AppExecId{appId=application_1486360553595_0003, execId=5} with ExecutorShuffleInfo{localDirs=[/data/yarn/nm/usercache/admin/appcache/application_1486360553595_0003/blockmgr-0ae6c816-fb68-4614-9a3c-1e8620e45d4d, /data1/yarn/nm/usercache/admin/appcache/application_1486360553595_0003/blockmgr-af95ae92-4f69-46ba-9bd7-216595b852a8, subDirsPerLocalDir=64, shuffleManager=org.apache.spark.shuffle.sort.SortShuffleManager}
三.调度
Fair Scheduler
CDH默认使用Fair Scheduler,Fair Scheduler将会尽量尝试每个任务均匀分配资源,同时也支持队列。
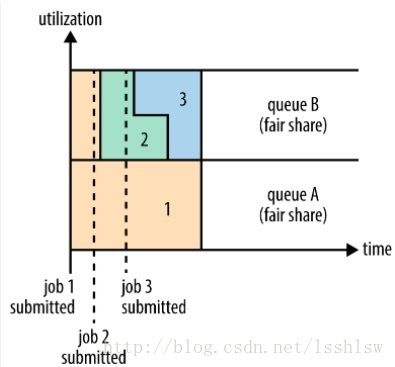
- 在A队列中提交job1,独占集群资源运行。
- 在B队列中提交job2,job1在队列B中的资源被回收,提供给job2。
- 在B队列中提交job3,job2和job3共享队列B的资源
tip: 上诉所说的仅仅是一种理想情况,实际上在spark on yarn模式中,如果container没有释放,后续的其他任务依旧是申请不到资源的。这也是为什么要使用dynamic allocation的一个原因。
队列设置
队列可以设置资源分配的比例,每个队列资源的最大最小值等。
具体可以参考cloudera:
https://www.cloudera.com/documentation/enterprise/5-5-x/topics/cm_mc_resource_pools.html
资源抢占(Preempt)
如同上面说的,如果A队列的job1同时占用了B队列的资源,那么此时在B队列提交的job2可能得不到资源而处于等待状态(job1的container没释放)。
可以通过资源抢占的方式,通过杀死job1的 container释放资源,使job2可以获得队列B的资源正常执行。
这种方式将会牺牲集群资源,因为被杀死的container需要被重新计算。
yarn-site.xml中设置
yarn.scheduler.fair.preemption- 通过参数控制是否开启抢占,默认为falseyarn.scheduler.fair.preemption.cluster-utilization-threshold- 默认为0.8f,意味着最多可以抢占到集群所有资源的80%
fair-scheduler.xml中设置
-
defaultMinSharePreemptionTimeout设置一个队列等待多长时间开始抢占
delay scheduling
延时调度是为了提高数据本地性而设置。
每一个 node manager 会定期发送心跳给 resource manager,这其中就包含了该 node manager 正在运行的 container 数量以及可以分配给新 container 的资源。当采用延迟调度策略时,调度器并不会立即使用收集到的信息,而会等待一段时间,以达到遵从 locality 的目的。
yarn.scheduler.fair.locality.threshold.node和yarn.scheduler.fair.locality.threshold.rack参数配置0-1之间的浮点数,如果设置为0.1则表示等待超过10%的节点发送心跳信息后再分配container。默认为-1表示不进行延时调度。
hadoop2.6 FairScheduler文档
http://hadoop.apache.org/docs/r2.6.0/hadoop-yarn/hadoop-yarn-site/FairScheduler.html