Flink 写入数据到Kafka
前言
通过Flink官网可以看到Flink里面就默认支持了不少sink,比如也支持Kafka sink connector(FlinkKafkaProducer),那么这篇文章我们就来看看如何将数据写入到Kafka。
准备
Flink里面支持Kafka 0.8、0.9、0.10、0.11.

这里我们需要安装下Kafka,请对应添加对应的Flink Kafka connector依赖的版本,这里我们使用的是0.11 版本:
org.apache.flink
flink-connector-kafka-0.11_2.11
${flink.version}
目前我们先看下本地Kafka是否有这个student-write topic呢?需要执行下这个命令:
➜ kafka_2.11-0.10.2.0 ./bin/kafka-topics.sh --list --zookeeper localhost:2181
__consumer_offsets
lambda-pipeline-topic
metrics
my-topic
my-topic-thread1
my-topic-thread2
qb_ad
qbad
qbad_test
student
topic1
wikipedia
wikipedia_stream
如果等下我们的程序运行起来后,再次执行这个命令出现student-write topic,那么证明我的程序确实起作用了,已经将其他集群的Kafka数据写入到本地Kafka了。
程序代码
public class FlinkSinkToKafka {
private static final String READ_TOPIC = "student";
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("zookeeper.connect", "localhost:2181");
props.put("group.id", "student-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "latest");
DataStreamSource student = env.addSource(new FlinkKafkaConsumer011<>(
READ_TOPIC, //这个 kafka topic 需要和上面的工具类的 topic 一致
new SimpleStringSchema(),
props)).setParallelism(1);
student.print();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("zookeeper.connect", "localhost:2181");
properties.setProperty("group.id", "student-write");
student.addSink(new FlinkKafkaProducer011<>(
"localhost:9092",
"student-write",
new SimpleStringSchema()
)).name("flink-connectors-kafka")
.setParallelism(5);
env.execute("flink learning connectors kafka");
}
}
运行结果
运行flink程序之后再次查看topic,发现多了student-write这个topic
➜ kafka_2.11-0.10.2.0 ./bin/kafka-topics.sh --list --zookeeper localhost:2181
__consumer_offsets
lambda-pipeline-topic
metrics
my-topic
my-topic-thread1
my-topic-thread2
qb_ad
qbad
qbad_test
student
student-write
topic1
wikipedia
wikipedia_stream
查看topic student-write
➜ kafka_2.11-0.10.2.0 ./bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic student-write
Topic:student-write PartitionCount:1 ReplicationFactor:1 Configs:
Topic: student-write Partition: 0 Leader: 0 Replicas: 0 Isr: 0
IDEA打印如下:
2> {"age":20,"id":2,"name":"itzzy2","password":"password2"}
6> {"age":24,"id":6,"name":"itzzy6","password":"password6"}
2> {"age":28,"id":10,"name":"itzzy10","password":"password10"}
6> {"age":32,"id":14,"name":"itzzy14","password":"password14"}
2> {"age":36,"id":18,"name":"itzzy18","password":"password18"}
6> {"age":40,"id":22,"name":"itzzy22","password":"password22"}
2> {"age":44,"id":26,"name":"itzzy26","password":"password26"}
6> {"age":48,"id":30,"name":"itzzy30","password":"password30"}
2> {"age":52,"id":34,"name":"itzzy34","password":"password34"}
6> {"age":56,"id":38,"name":"itzzy38","password":"password38"}
查看topic信息
➜ kafka_2.11-0.10.2.0 ./bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic student
student:0:0
➜ kafka_2.11-0.10.2.0 ./bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic student_write
student_write:0:0
查看日志logs
➜ kafka_2.11-0.10.2.0 ll /tmp/kafka-logs/student-write-0
total 0
-rw-r--r-- 1 zzy wheel 10485760 Jan 29 12:03 00000000000000000000.index
-rw-r--r-- 1 zzy wheel 0 Jan 29 12:03 00000000000000000000.log
-rw-r--r-- 1 zzy wheel 10485756 Jan 29 12:03 00000000000000000000.timeindex
➜ kafka_2.11-0.10.2.0 ll /tmp/kafka-logs/student-0
total 0
-rw-r--r-- 1 zzy wheel 10485760 Jan 29 12:03 00000000000000000000.index
-rw-r--r-- 1 zzy wheel 0 Jan 29 12:03 00000000000000000000.log
-rw-r--r-- 1 zzy wheel 10485756 Jan 29 12:03 00000000000000000000.timeindex
分析
上面代码我们使用 Flink Kafka Producer 只传了三个参数:brokerList、topicId、serializationSchema(序列化)
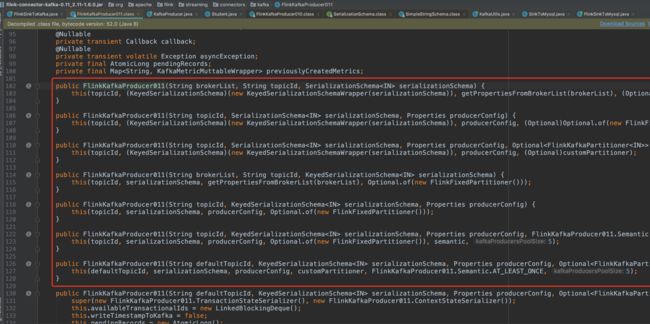
其实也可以传入多个参数进去,现在有的参数用的是默认参数,因为这个内容比较多,后面可以抽出一篇文章单独来讲。
总结
本篇文章写了Flink读取Kafka集群的数据,然后写入到本地的Kafka上。
附上kafka生产者代码
public class KafkaUtils {
private static final String broker_list = "localhost:9092";
private static final String topic = "student-1"; //kafka topic 需要和 flink 程序用同一个 topic
public static void writeToKafka() throws InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", broker_list);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// KafkaProducer producer = new KafkaProducer(props);//老版本producer已废弃
Producer producer = new org.apache.kafka.clients.producer.KafkaProducer<>(props);
try {
for (int i = 1; i <= 100; i++) {
Student student = new Student(i, "itzzy" + i, "password" + i, 18 + i);
ProducerRecord record = new ProducerRecord(topic, null, null, JSON.toJSONString(student));
producer.send(record);
System.out.println("发送数据: " + JSON.toJSONString(student));
}
Thread.sleep(3000);
}catch (Exception e){
}
producer.flush();
}
public static void main(String[] args) throws InterruptedException {
writeToKafka();
}
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Student {
private int id;
private String name;
private String password;
private int age;
}
参考:
https://ci.apache.org/projects/flink/flink-docs-release-1.6/dev/connectors/kafka.html#top
http://www.54tianzhisheng.cn/2019/01/06/Flink-Kafka-sink/