笔者近期在做一个人岗匹配的项目研究,无意间,在网上搜到了一篇SIGIR 2018上的论文,发现正好跟我们团队所做的事情很相似,遂十分欣喜,拿来拜读,然后跟老师同学们交流。最后得出了很多有意义的思考。
该论文提出的模型结构有些复杂,为了深刻理解,我将每个步骤拆分,自己重新画图,逐步剖析模型的细节。这里分享给大家:

人岗匹配问题的背景
抛开这篇论文,我们先谈一谈人岗匹配这件事到底在做什么,做哪些难点。
一家大公司,一旦发布了某招聘需求,往往每天会有成千上万封简历飞来应聘。HR需要从这成千上万封简历中筛选符合要求的、跟岗位匹配的一批简历,进入面试环节。而这个筛选过程是十分痛苦的,一天看上百封简历可能还看得过来,一天看一千封、一万封,你就根本没法应付了。这个时候,我们就希望借助于机器帮我们筛选。所以最初,我们会设定一些规则,让电脑去判断一封简历是否满足了某些要求,比如毕业学校、学历、年龄等等这些硬性要求。但是,对简历的要求远远不止这些,还有对技能(软技能、硬技能)的要求,对工作经历项目经历的要求,这些很难通过人工设定规则来判断。另外,语言的表达形式多种多样,你定义了一个要求,简历实际上也满足这个要求,但是表达方式、用词用语不一样怎么办?而且,不光是筛选掉不合格的简历,合格的简历也不是全部都要,这个数量依然太大了,我们还需要优中选优,对所有合格的简历进行一个匹配度的排序,最终可以选出前N个最符合要求的简历来。
人岗匹配的问题,一般有两种路线去思考:
(注:为了方便行文,下文中“招聘启事”用J表示,“简历”用R表示。)
- 从J和R中提取尽可能优质的关键词/短语,用关键词/短语来表示J和R,然后对两个表示进行匹配度计算。
- 采用深度学习端到端的方法,通过大量的J-R匹配样本进行训练,得到一个模型直接计算二者匹配度。
两种路线的关键,其实都是探讨:“如何表示一个长文本(如招聘启事、简历)”。前者希望用人工划定的结构,形成以关键词为基础的表示,而后者希望借助深度学习去发掘文本的内在分布式表示。两种路线不分伯仲,各有优劣,我们后面再思考二者在实际场景中的使用问题。
这篇论文,就是走的第二条路线——深度学习,端到端。为了应对J和R各自复杂的结构,以及深度学习解释性差的问题,作者精心设计了一套复杂的基于Attention+BiLSTM的模型,试图学习出J和R的较为精确的表示,从而进行匹配。
下面进入正文。
(注,我讲论文很有意思的,不会上来就贴论文各种截图,然后翻译一下就完事儿了。我不仅让我自己懂,更要让听我讲的人懂。即使讲论文,本文的百分之60以上的内容,也都是我自己思考总结的东西,以及拓展引申的东西。所以论文只是一个线索,下面请开始我的表演......)
一、作者想解决的问题

招聘启事(J)由多条要求(requirements)组成:
- 每条要求中的各个词/短语的重要性不同;
- 每条要求的重要性不同(体现在内容和顺序上)
求职者的简历(R)由多条经历(experiences)组成:
- 每条经历中的各个词/短语的重要性不同;
- 每条经历对于每条要求的重要性也不同(内容、顺序)
然而,传统的方法,直接从J和R中挖掘关键词进行匹配,忽视了不同词语、短语、句子的重要性和相互关系。
二、作者的思路和想法
基于上面提到的问题,该论文希望构建一个模型:
- 能够捕获一条requirement或者experience中各个词的重要性(感觉类似于关键词提取,只不过不需要把关键词真的拿出来),从而获得句子的向量表示。
- 能够对发掘出同一个J(或R)中,不同requirements(或experiences)的重要性。
- 能够衡量一条requirement与不同experiences之间的相关性。
思来想去,作者拿出了三大武器:
Word Embedding,Bi-LSTM , Hierarchical Attention.
用这三种武器,作者希望能够很好地得到J和R各自的表示,涵盖了各个词的重要性,不同语句之间的权重关系以及J和R的内在相互关系。
于是,作者们使出九牛二虎之力,打造出了这款你从未玩过的船新模型:
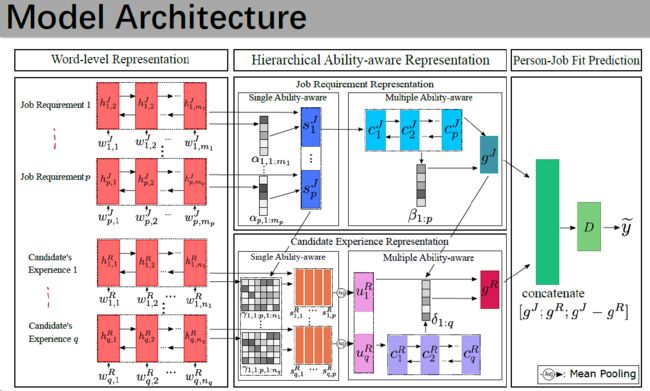

怕了怕了,这文章怕是读不下去了...这模型看起来比Bert都吓人...
诶,莫慌,这写论文,就讲究个说学逗唱(删),想法再朴素,你也得添砖加瓦上色仿佛造了个变形金刚一样。
所以,为了搞清楚这个庞然大物到底是什么,我把每个步骤分解,用亲切的笔法重新画图。
Loading... ...
... ...
灵魂画手已上线!
三、模型解析
首先,我们用符号把我们的问题描述一下:

我们的训练样本,是一个个Person-Job对,其中y对应的是应聘结果。
J是由p个requirements(条件)组成,分别为j1,j2,......,jp;
R是由q个experiences(经历)组成,分别为r1,r2,......,rq.
而每一个条件或者经历,都是由若干个词组成。
所以整体有三个层次:
段落、句子、词。
我们最终的目的,就是为了找到一个模型M,可以对J和R分别得到一个表示,然后对二者进行匹配度的计算。
整个模型分为三个大步骤:
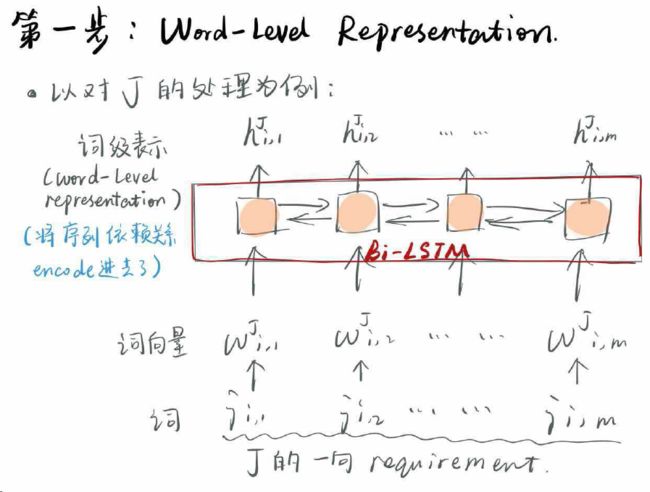
1.Word-Level Representation
2.Hierarchical Ability-Aware Representation
3.Person-Job Fit Prediction

上面的两个图已经讲的很清楚了。我再补充一下:
(Oh...上面的图片中有两个字母写反了。太明显了,所以我也不说是哪里了)
为什么我们通过word embedding得到了每个词的词向量表示之后,还要搞一个BiLSTM去得到新的表示?词向量不是已经挺好了吗?
其实不是,如果直接用词向量作为输入,那每个词都是独立的,不受上下文影响的,忽略了句子内部的序列依赖信息。因此,希望通过BiLSTM来把这种序列的信息给编码进去。
经过这样的操作,我们的J和R中的句子(这里的句子,指的是一条条要求、经历),就被表示成了一个个向量序列。

第二大步,即多层能力感知表示,其实,什么狗屁能力感知,只是名字取的酷炫一点,说白了就是使用Attention对不同的词,不同的句子进行一个权重的分配,而训练的结果就是很多跟“能力”密切相关的词,得到了高权重,所以说是“能力感知”。
这4个小步,分别是对J的句子、整个J,以及R的句子、整个R进行表示。
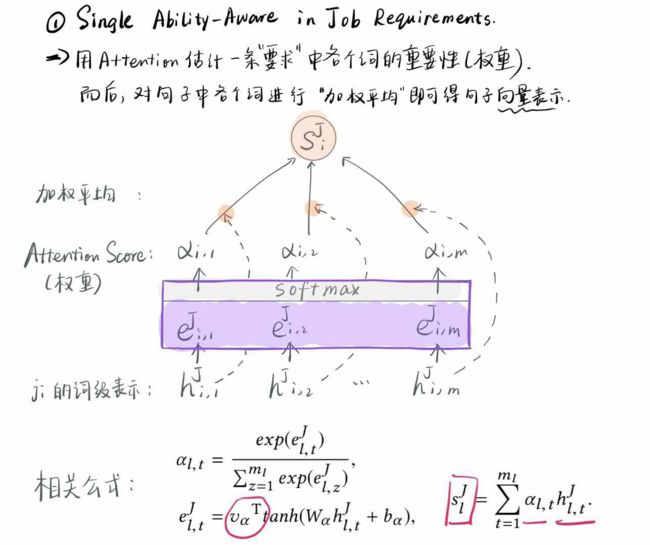

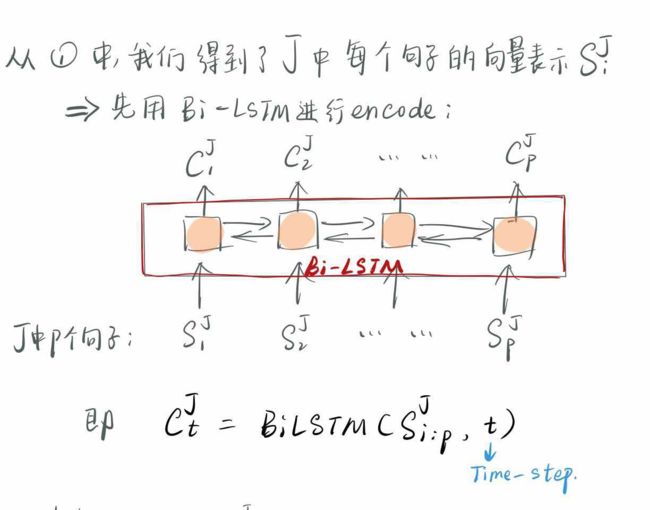
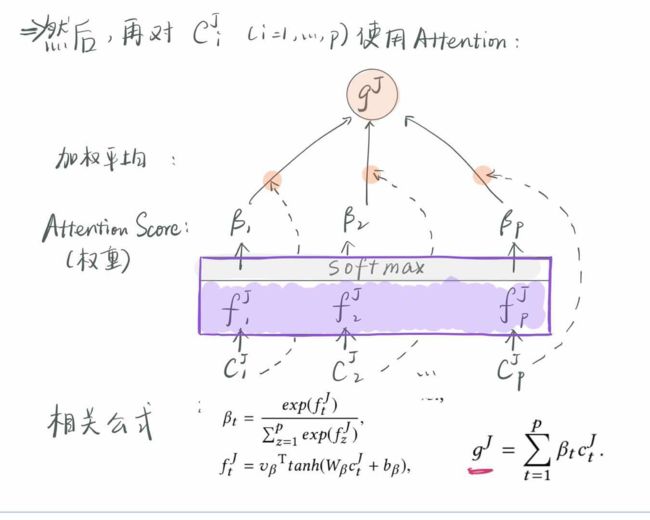
前两步比较容易理解,第3小步就稍微复杂一点:

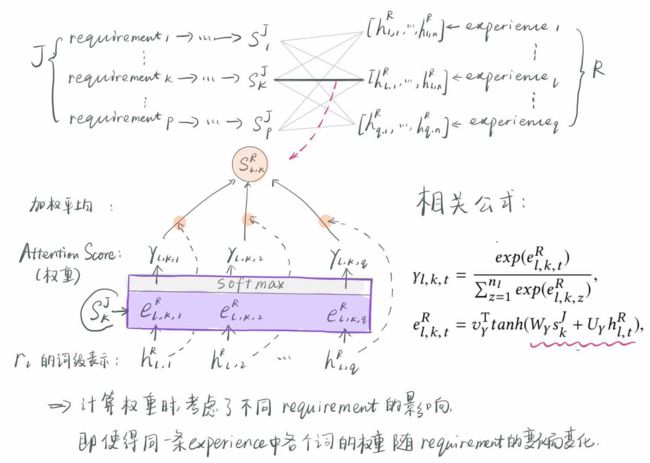
注意对比这里的attention和前面的attention的不同,就是这里计算R的句子的权重,额外考虑了针对不同的requirement的影响。
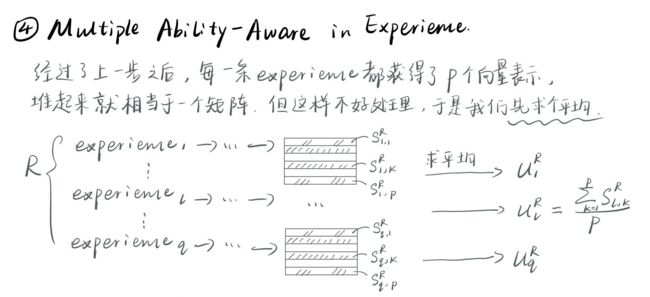
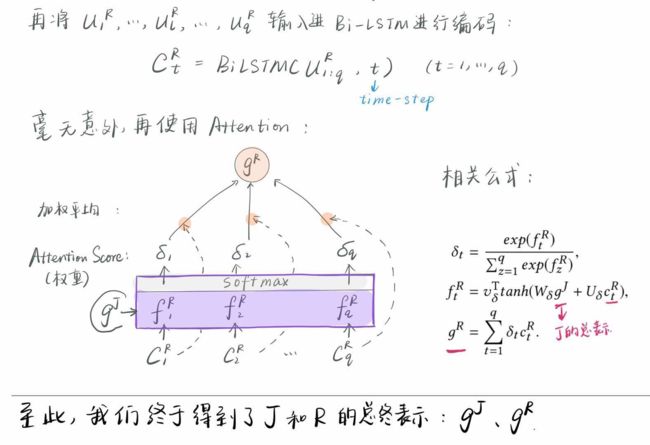
经过了上面的4个小步骤,J和R分别得到了自己的一个综合表示,蕴含了不同词,不同句子之间的重要性和J和R内部的关系。
最后一步最简单:

干杯!都在图里了!!
现在,再回看之前作者给出的那个大大大图,就发现,其实很简单,很多内容都是重复的,每一步都是BiLSTM+Attention,只不过作者把每个细节都画上去了。
四、模型性能、效果展示
作者通过对一家大型科技公司的真实数据进行测试,理所当然地发现他们的模型效果最好(毕竟其他的模型都太太太基础了):

真正有意思的,不是上面的分数,而是对各层的attention进行可视化的效果:
再回顾一下,我们有4中attention score,分别是:
α:J的句子中各个词的权重;
β:J的不同句子的权重;
γ:R的句子中各个词的权重(随着J中的要求而变化)
δ:R的不同句子的权重。
作者将前三者可视化了:

可以看出,关键信息基本被highlight了,还是比较准确的(当然,毕竟是作者自己挑选出来的,肯定是比较好的例子)。

从这里可以看出,招聘公司写的各条要求实际的重要性。

而这个,则可以看出,针对一条requirement,简历中哪些词被赋予高权重了。
五、该论文的亮点
- 充分利用attention机制的能力,设置了4处attention,使得模型的学习能力十分强大。尤其是考虑了同样的experience对不同的requirements的效果不同,相当于“动态关键词提取”。
- 4处的attention score使得模型的具有一定的解释性,可视化效果好。
- 人力成本低,端到端的模型。
六、更多的反思
模型本身很漂亮,十分简洁,尤其是多层级的表示方法,确实可以某种意义上上大幅提高对长文本的表示效果。另外作者还讨论了很多其他的问题,例如Word2vec与bag-of-words的对比,实证发现在很多模型中后者居然更好。还讨论了如何消除招聘中的歧视问题。这里暂不一一赘述。这里更想讨论的是,这种深度学习端到端的做法,到底有哪些问题?这是值得我们思考的。毕竟深度学习被吹得太厉害,仿佛什么事情就是拿来足够的数据,无脑的塞进模型,管他三七二十一,盘它就完了!这在理论上,确实是解决问题的一个不错方法,因为从效果上看确实比较好,但是在实际场景中,就会有很多问题了。
1. 模型的解释性,依然薄弱。
虽然attention可以很好地可视化,但是这更多的只是“好看”。
对于预测成功的简历,比如两个分别打分0.6和0.8,这个模型无法告诉我们0.8的那个简历为什么比0.6的好。就算知道了各自的attention score又怎么样?
对于预测失败的简历,这个模型也无法告诉我们这份简历哪里写的不好,而在实际场景中,我们不光是需要知道是否匹配,很多简历提供方,如猎头,如各种招聘平台,需要知道怎么匹配,哪里不匹配,这样他们才能在之后的业务中有所改进。
2.泛化能力差,只在训练样本的分布上有效果保证
本文的训练样本是选自4个领域的招聘实例:技术、UI设计、产品、其他。实际上是很局限的,因为真实场景中的领域还有很多很多,那实际的分布可能和训练样本的分布相差巨大。当我们需要对一个全新的岗位进行这样的人岗匹配时,我们就需要重新训练,这就需要很多时间,而是不一定会有足够的真实数据拿来训练。
3.功能单一,只能做J和R的匹配一件事
这个模型依然是一个黑匣子,加上了attention的装饰之后,是一个五彩斑斓的黑匣子,能给你输入的文字“上点儿色”,然而不管怎么上色,它输出的,只有一个分数,一个匹配分。也只有这么一个分数,是有实际意义的,是我们可以用的。这个应用场景是十分狭窄了,我们无法通过这个模型得到对一个候选人的精确表示,或者一个用户画像,因为这里模型的表示只是一串向量表示,跟词向量类似。词向量如果不用来互相比较、计算,也就失去了实际意义,这里的向量表示也是类似。我们都无法通过这个模型获取关于J和R的一个完整的关键词列表,也就失去了实际的表达能力。
上面的三点是一个实际场景中的应用问题,毕竟我们不想仅仅停留在理论上,跑个分就完了,而是希望尽可能多的发挥作用。
下面要说的几点,则是对论文本身的一些反思:
4.语言的表达形式,也许对attention有巨大影响。
经过对attention可视化的分析,发现attention机制有这样的倾向:在面试成功的简历中,越是“独特”的词attention score的分数往往越高。这到底有失偏颇还是的确是事实?这个问题值得研究。
5.上下位词的匹配问题没有被考虑
J和R中的词,往往在层次上会有很大差异。J的要求“熟悉常用的深度学习框架”,R中可能不会写“深度学习框架”这个词,而是多半会写“熟悉TensorFlow、Keras”。这就是层级的不同。这个问题,一种做法是通过知识图谱,获得一个词的上下位词,从而知道两者的关系。其他的方法还有待探究。但是不管怎样,这个问题都是一个在实际中经常出现,也是十分影响匹配效果的一个问题,所以这个问题也应该在后面的研究中得到考虑。
以上就是对这篇论文的全面的讲解了,给人的思考很多。相比一个论文、模型的亮点,我们更需要思考的是它的问题,养成自己的批判性思维,这样才能在思维上不断创新,无论是做研究还是做项目都是大有益处的。
论文原文:
arXiv上搜索“Enhancing Person-Job Fit for Talent Recruitment:
An Ability-aware Neural Network Approach”