CPU要求:在深度学习任务中,CPU并不负责主要任务,单显卡计算时只有一个核心达到100%负荷,所以CPU的核心数量和显卡数量一致即可,太多没有必要,但是处理PCIE的带宽要到40。
主板要求:需要支持X99架构,支持PCIe3.0,还要支持4通道DDR4内存架构。如果要搞四显卡并行,PCIE带宽支持要达到40,并且支持4-Way NVIDA SLI技术。
内存要求:达到显存的二倍即可,当然有钱的话越大越好。鉴于相对GPU和CPU而言内存所需要的资金投入比较少,建议至少配备32G,总投入大约1500,预算充裕的话,可以直接上64G。由于内存的扩展非常便捷,完全可以先使用32G以后根据情况考虑是否扩展。当然,前提是,你知道要选择的都是DDR4的内存。
电源要求:一个显卡的功率接近300W,四显卡建议电源在1500W以上,为了以后扩展,选择了1600W的电源。电源可以根据GPU和CPU功率来大致算一下,比如i7-6800k的功率大概是150W,GTX1080公版大概是180-200W,如果是单显卡的话,一个800W的电源就足够了,当然如果以后有显卡扩展的需求,你就需要支持更大功率的电源了。比如你要搞四个GPU集成,你可能就需要1500W以上的电源了。
机箱散热:因为各种部件相当庞大,需要有良好散热功能的大机箱,选择了Tt Thermaltake Core V51机箱,标配3个12cm风扇。未来如果需要还可以加装水冷设备。机箱的空间最好是大一些,毕竟这一堆高性能的东西,要保证足够好的散热,当然,有条件还是上水冷吧,那么多钱都花了。
硬盘要求:最好上SSD。大硬盘也是需要的。硬盘还是主流的SSD+HDD配置,SSD是必要的,程序启动和响应都的需求很大,大文件预处理也快很多。如果只用HDD,很有可能会让你怀疑人生。但是,对于深度学习来说,当你的输入维数很高,不能充分压缩数据时,这才是SSD必需的主要原因。
显卡:基于CUDA计算(CUDA 是NVIDIA开发的GPU并行计算环境),所以一般只推荐NVIDIA 系列的。在英伟达产品系列中,有消费领域的GeForce系列,有专业绘图领域的Quadro系列,有高性能计算领域的Tesla系列。太高的精度对于深度学习的错误率是没有提升的,而且大部分的环境框架都只支持单精度,所以双精度浮点计算是不必要,Tesla系列没必要。从显卡效能的指标看,CUDA核心数要多,GPU频率要快,显存要大,带宽要高。

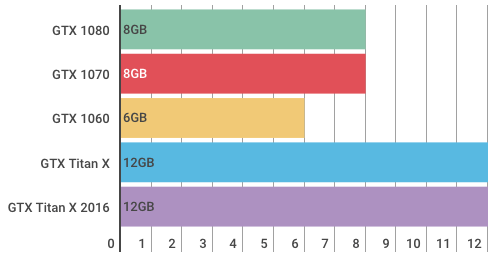


每个 GPU 的 RAM 或内存带宽等信息都展示在图表中。注意 Titan XP 和 GTX 1080 Ti 尽管价格相差非常多,但它们的性能却非常相近。

2017年底推出了一款Titan V,性能也是爆炸,不过价格也就水涨船高了。
Titan V
参数
- 现存(VRAM):12GB
内存带宽:653GB/s
处理器:5120个CUDA核心@1200MHz
价格:22999元
Titan V成为新旗舰,性能较XP有了提升,完整的GV100核心,峰值浮点性能高达110TFlops,相当于Titan XP 12Tflops的9倍,同时CUDA核心也向顶配的Tesla V100看齐,拥有5120个。显存更是使用了12GB的1.7Gbps HBM2,带宽达到653GB/sec,但价格同时水涨船高,一般人消费不起。
Titan XP
参数:
- 显存(VRAM):12 GB
- 内存带宽:547.7 GB/s
- 处理器:3840 个 CUDA 核心 @ 1480 MHz(约 5.49 亿 CUDA 核心频率)
- 英伟达官网价格:9700 元
Titan XP 曾是目前英伟达消费级显卡的旗舰产品,正如性能指标所述,12GB 的内存宣示着它并不是为大多数人准备的,只有当你知道为什么需要它的时候,它才会位列推荐列表。
一块 Titan XP 的价格可以让你买到两块 GTX 1080,而那意味着强大的算力和 16GB 的显存。
GTX 1080 Ti
参数:
- 显存(VRAM):11 GB
- 内存带宽:484 GB/s
- 处理器:3584 个 CUDA 核心 @ 1582 MHz(约 5.67 亿 CUDA 核心频率)
- 英伟达官网价格:4600 元
这块显卡是一个完美的高端选项,拥有大容量显存和高吞吐量,物有所值。
如果资金允许,它是一个很好的选择。GTX 1080 Ti 可以让你完成计算机视觉任务,并在 Kaggle 竞赛中保持强势。
GTX 1080
参数:
- 显存(VRAM):8 GB
- 内存带宽:320 GB/s
- 处理器:2560 个 CUDA 核心 @ 1733 MHz(约 4.44 亿 CUDA 核心频率)
- 英伟达官网价格:3600 元
作为目前英伟达产品线里的中高端显卡,GTX 1080 的官方价格从 1080 Ti 的 700 美元降到了 550 美元。8 GB 的内存对于计算机视觉任务来说够用了。大多数 Kaggle 上的人都在使用这款显卡。
GTX 1070 Ti
参数:
- 显存(VRAM):8 GB
- 内存带宽:256 GB/s
- 处理器:2432 个 CUDA 核心 @ 1683 MHz(约 4.09 亿 CUDA 核心频率)
- 英伟达官网价格:3000 元
2017年11 月 2 日推出的 GTX 1070 Ti 是英伟达产品线上最新的显卡。如果你觉得 GTX 1080 超出了预算,1070 Ti 可以为你提供同样大的 8 GB 显存,以及大约 80% 的性能,价格也打了八折,看起来不错。
GTX 1070
参数:
- 显存(VRAM):8 GB
- 内存带宽:256 GB/s
- 处理器:1920 个 CUDA 核心 @ 1683 MHz(约 3.23 亿 CUDA 核心频率)
- 英伟达官网价格:2700 元
这款 GPU 主要用于虚拟货币挖矿。它的显存配得上这个价位,就是速度有些慢。如果你能用较便宜的价格买到一两个二手的,那就下手吧。
GTX 1060(6 GB 版本)
参数:
- 显存(VRAM):6 GB
- 内存带宽:216 GB/s
- 处理器:1280 个 CUDA 核心 @ 1708 MHz(约 2.19 亿 CUDA 核心频率)
- 英伟达官网价格:2000 元
相对来说比较便宜,但是 6 GB 显存对于深度学习任务可能不够用。如果你要做计算机视觉,那么这可能是最低配置。如果做 NLP 和分类数据模型,这款还可以。
GTX 1050 Ti
参数:
- 显存(VRAM):4 GB
- 内存带宽:112 GB/s
- 处理器:768 个 CUDA 核心 @ 1392 MHz(约 1.07 亿 CUDA 核心频率)
- 英伟达官网价格:1060 元
这是一款入门级 GPU。如果你不确定是否要做深度学习,那么选择这款不用花费太多钱就可以体验一下。
值得注意的问题
上代旗舰 Titan X Pascal 曾是英伟达最好的消费级 GPU 产品,而 GTX 1080 Ti 的出现淘汰了 Titan X Pascal,前者与后者有同样的参数,但 1080 Ti 便宜了 40%。
英伟达还拥有一个面向专业市场的 Tesla GPU 产品线,其中包括 K40、K80、P100 和其他型号。虽然你或许很少能够接触到,但你可能已经通过 Amazon Web Services、谷歌云平台或其他云供应商在使用这些 GPU 了。
有文章中对 GTX 1080 Ti 和 K40 进行了一些基准测试。1080 的速度是 K40 的 5 倍,是 K80 的 2.5 倍。K40 有 12 GB 显存,K80 有 24 GB 的显存。
理论上,P100 和 GTX 1080 Ti 应该性能差不多。但是,之前的对比(https://www.reddit.com/r/NiceHash/comments/77uxe0/gtx_1080ti_vs_nvidia_tesla_p100_xpost_from/)发现 P100 在每个基准中都比较落后。
K40 售价超过了 13,000元,K80 售价超过 20,000 元,P100 售价约 30,000 元。它们的市场正被英伟达自家的桌面级 GPU 无情吞噬。显然,按照现在的情况,我不推荐你去购买它们。
在挑选的时候要注意的几个参数是处理器核心(core)、工作频率、显存位宽、单卡or双卡。我觉得对深度学习计算而言处理器核心数和显存大小比较重要。这些参数越多越高是好,但是程序相应的也要写好,如果无法让所有的core都工作,资源就被浪费了。
所以综合来说,个人推荐 2 路 GPU,直接用上 2 块 GTX 1080Ti。
选择多 GPU 有两个理由:需要并行训练多个模型,或者对单个模型进行分布式训练。并行训练多个模型是一种测试不同原型和超参数的技术,可缩短反馈周期,你可以同时进行多项尝试。
分布式训练,或在多个显卡上训练单个模型的效率较低,但这种方式确实越来越受人们的欢迎。现在,使用 TensorFlow、Keras(通过 Horovod)、CNTK 和 PyTorch 可以让我们轻易地做到分布式训练。这些分布式训练库几乎都可以随 GPU 数量达成线性的性能提升。例如,使用两个 GPU 可以获得 1.8 倍的训练速度。
PCIe 通道:使用多显卡时需要注意,必须具备将数据馈送到显卡的能力。为此,每一个 GPU 必须有 16 个 PCIe 通道用于数据传输。Tim Dettmers 指出,使用两个有 8 个 PCIe 通道的 GPU,性能应该仅降低「0—10%」。
对于单个 GPU 而言,任何桌面级处理器和芯片组如 Intel i5 7500 和 Asus TUF Z270 需要使用 16 个通道。
然而,对于双 GPU,你可以使用 8x/8x 通道,或者使用一个处理器和支持 32PCIe 通道的主板。32 个通道超出了桌面级 CPU 的处理能力。使用 Intel Xeon 组合 MSI—X99A SLI PLUS 是可行的方案。
对于 3 个或 4 个 GPU,每个 GPU 可使用 8x 通道,组合支持 24 到 32 个 PCIe 通道的 Xeon。
如果需要使用 3 到 4 个有 16 个 PCIe 通道的 GPU,你得有一个怪兽级处理器。例如 AMD ThreadRipper(64 个通道)和相应的主板。
总之,GPU 越多,需要越快的处理器,还需要有更快的数据读取能力的硬盘。
选好 GPU 后,其他配置有多少钱就买多少菜。
例子(2017):
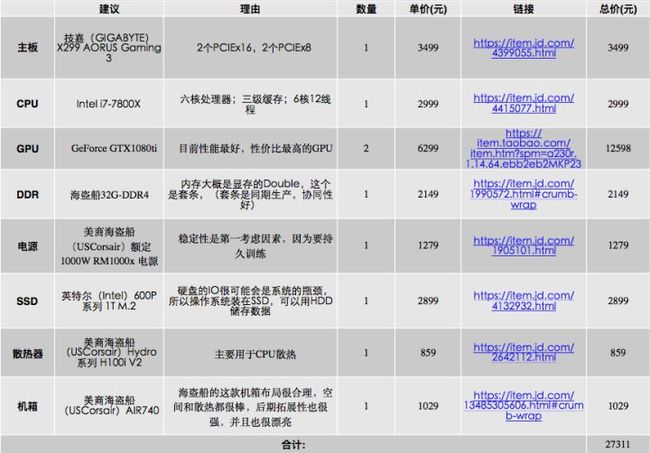


1080ti换成Titan也没问题。
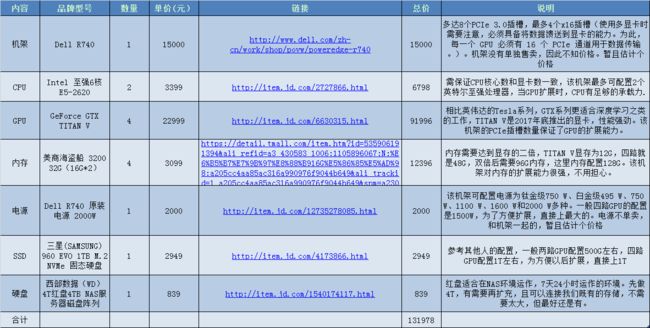
最后我综合调研情况和实验室需求及经费,选择了机架式的GPU服务器,选择的配置单如下:
参考资料:
- 码农的高薪之路,如何组装一台适合深度学习的工作站?
- 如何DIY自己的深度学习工作站
- 知乎:如何配置一台适用于深度学习的工作站?
- 深度学习主机攒机小记
- Titan XP值不值?一文教你如何挑选深度学习GPU