内存优化前我们先了解一些和内存相关的概念:
- 垃圾回收
- 内存抖动
- 四种引用
- 内存泄露
下面我们回到正题, 讲一下如何进行内存优化:
- 数据类型
- 自动装箱
- SparseArray ArrayMap HashMap应该如何选择与使用
- 枚举
- 常量
- 对象管理
- 字符串
- 字符串连接
- 本地变量
- 数组 VS 集合
- 流, Bitmap, Cursor等一系列使用后需要手动关闭的资源
- 内存设计模式
- 对象池模式(Message池)
- 享元模式
- Android组件泄露
- Activity
- 静态字段
- 非静态内部类
- 匿名内部类
- 单例
- Service
- Activity
- 和内存相关的API
- ActivityManager
- Runtime
- ComponentCallbacks和ComponentCallbacks2接口
- 调试工具
- LogCat
- ActivityManager API
- StrictMode
- Dumpsys
- Dump Heap
- Allocation Tracker
- MAT
- LeakCanary
垃圾回收
1. Java运行时内存区域
在JAVA运行时的内存区域中,由JVM管理的内存区域分为以下几个模块:
- 程序计数区:由当前线程独占,记录当前线程的字节码文件执行到哪一行。
- 虚拟机栈:由当前线程独占,存放当前线程调用方法的栈帧的栈。
- 本地方法栈:由当前线程独占,和虚拟机栈类似, 只不过虚拟机栈记录的是JAVA方法,本地方法栈记录的是native方法。
- 堆:由所有线程共享,存放对象实例。
- 方法区:由所有线程共享,存储已经被虚拟机加载的类信息,final常量,静态变量,编译器即时编译的代码等。
栈帧补充:每一个线程都有一个虚拟机栈,每当线程中执行一个方法的时候,就会向虚拟机栈中插入一个栈帧,当方法执行完后,再将栈帧出栈。栈帧中包含局部变量表,操作站,方法出口等。
局部变量表中存储着方法相关的局部变量,包括基本数据类型,对象的引用,返回地址等。
具体请参考Java内存区域与内存溢出
方法区补充:方法区属于垃圾回收机制中的永久代(一共有青年带,老年代,永久代三种),因此方法区的垃圾回收很少,但不代表不会发生垃圾回收,其上的垃圾回收主要针对常量池的内存回收和对已加载类的卸载。
2. JAVA对象的访问方式
一般来说,一个JAVA引用至少会涉及到三个内存区域,虚拟机栈、堆、方法区。
例如 Object obj = new Object();
- Object obj表示一个本地引用,存储在虚拟机栈的本地变量表中
- new Object()作为实例对象存放在堆中
- 堆中还存储了Object类的类型信息(接口,方法,field,对象类型等)的地址,这些地址所指向的内容存放在方法区中
3. JAVA内存分配及回收机制
分代分配,分代回收。
JAVA内存分为年轻代、老年代、永久代
- 年轻代:对象被创建时,内存分配首先创建在年轻代的Eden区(如果年轻代空间不足,则大对象直接分配在老年代上)。大部分对象很快就不再使用。年轻代的内存区域分为:一个Eden区和两个Survivor区(比例为8:1:1)
- 老年代:对象如果在年轻代存活了很长时间没有被回收掉,就会被复制到老年代。老年代的空间比年轻代大,发生的GC次数也比年轻代少。
- 永久代:方法区属于永久代,永久代的垃圾回收次数很少,但是也会发生GC。
GC分为两种:
- Minor GC
只会在年轻代的Eden区进行垃圾回收 - FULL GC
会在年轻代, 老年代, 永久带都进行垃圾回收
有如下原因可能导致Full GC:
1.年老代(Tenured)被写满;
2.持久代(Perm)被写满;
3.System.gc()被显示调用;
4.上一次GC之后Heap的各域分配策略动态变化.
GC机制:
- 年轻代:主要使用“停止-复制”算法,停止指的是,发生GC的时候会暂停除了GC线程以外的所有线程的运行。
复制的过程如下:- 绝大部分的对象刚创建的时候会被分配到Eden区,其中大部分的对象会很快消亡。Eden区是连续的内存空间,因此在其上分配内存是很快的。
- 最初一次,当Eden区满的时候,执行Minor GC,将Eden区的消亡对象清除掉,并将剩余的对象放到Survivor1中(此时Survivor2是空的,两个Survivor总有一个是空的)
- 下次Eden再满的时候,执行Minor GC,将Eden区的消亡对象清除掉,将剩余的对象放到Survivor1中
- 当Survivor1满了的时候则将Eden和Survivor1中的消亡的对象清除掉,并将Eden和Survivor1中剩余的对象复制到Survivor2中
- 当两个Survivor交换了几次后,就可以将剩下的对象复制到老年代中了
- 老年代:使用“标记-整理”算法,即将存活的对象向一边移动,以此来保证回收后,内存依然是连续的,不会出现内存碎片。每次年轻代的Eden发生Minor GC时,虚拟机都会检查每次晋级老年代的大小是否大于老年代的剩余大小,如果大于则会触发FULL GC。
- 永久代:永久代的回收有两种,常量池中的常量,无用的类的信息。
常量没有引用了就可以回收。
无用的类必须保证3点才可以回收:- 类的所有实例已经被回收
- 加载类的ClassLoader已经被回收
- 类对象的class对象没有被引用(即没有反射调用该类的地方)
上面描述的是JVM虚拟机的GC机制,那么Android中的GC和它有啥区别呢?
在Android5.0以前,Dalvik虚拟机使用的其实是另一种算法来进行垃圾回收——Mark-Sweep(标记-清除)算法,这种算法需要一次标记,一次清除来回收垃圾。因此Dalvik的垃圾回收分为两个阶段:
- 第一个阶段,Dalvik暂停所有的线程来分析堆的使用情况。
- 第二个阶段,Dalvik暂停所有线程来清理堆。这就会导致应用在性能上的“卡顿”。
这种算法除了造成性能上的卡顿之外,还会造成很多内存碎片,因此很容易发生OOM。
在Android5.0推出的ART虚拟机,对垃圾回收算法做了改进。ART改进后的垃圾回收算法只暂停线程一次。ART 能够做到这一点,是因为应用本身做了垃圾回收的一些工作。垃圾回收启动后,不再是两次暂停,而是一次暂停。在遍历阶段,应用不需要暂停,同时垃圾回收停时间也大大缩短,因为 Google使用了一种新技术(packard pre-cleaning),在暂停前就做了许多事情,减轻了暂停时的工作量。
而且还增加了Moving GC策略,目的是清理堆栈以减少内存碎片。由于这个工作会导致应用程序长时间中断,所以它必须等程序退到后台时才能开展。核心思想是,当应用程序运行在后台时,将程序的堆空间做段合并操作。
具体可以参考Android 5.0 ART GC 对比 Android 4.x Dalvik GC
4. 减少GC开销的措施
根据上述GC的机制,程序的运行会直接影响系统环境的变化,从而影响GC的触发。若不针对GC的特点进行设计和编码,就会出现内存驻留等一系列负面影响。为了避免这些影响,基本的原则就是尽可能地减少垃圾和减少GC过程中的开销。具体措施包括以下几个方面:
不要显式调用System.gc()
此函数建议JVM进行主GC,虽然只是建议而非一定,但很多情况下它会触发主GC,从而增加主GC的频率,也即增加了间歇性停顿的次数。尽量减少临时对象的使用
临时对象在跳出函数调用后,会成为垃圾,少用临时变量就相当于减少了垃圾的产生,从而延长了出现上述第二个触发条件出现的时间,减少了主GC的机会。对象不用时最好显式置为Null
一般而言,为Null的对象都会被作为垃圾处理,所以将不用的对象显式地设为Null,有利于GC收集器判定垃圾,从而提高了GC的效率。尽量使用StringBuffer,而不用String来累加字符串
由于String是固定长的字符串对象,累加String对象时,并非在一个String对象中扩增,而是重新创建新的String对象,如Str5=Str1+Str2+Str3+Str4,这条语句执行过程中会产生多个垃圾对象,因为对次作“+”操作时都必须创建新的String对象,但这些过渡对象对系统来说是没有实际意义的,只会增加更多的垃圾。避免这种情况可以改用StringBuffer来累加字符串,因StringBuffer是可变长的,它在原有基础上进行扩增,不会产生中间对象。能用基本类型如Int,Long,就不用Integer,Long对象
基本类型变量占用的内存资源比相应对象占用的少得多,如果没有必要,最好使用基本变量。尽量少用静态对象变量
静态变量属于全局变量,不会被GC回收,它们会一直占用内存。分散对象创建或删除的时间
集中在短时间内大量创建新对象,特别是大对象,会导致突然需要大量内存,JVM在面临这种情况时,只能进行主GC,以回收内存或整合内存碎片,从而增加主GC的频率。集中删除对象,道理也是一样的。它使得突然出现了大量的垃圾对象,空闲空间必然减少,从而大大增加了下一次创建新对象时强制主GC的机会。
内存抖动
在内存管理中有一种异常叫做内存抖动,它指的是,在短时间内,大量的新对象被实例化,运行时无法承载这样的内村分配,在这种情况下,垃圾回收时间被大量调用,影响到应用程序以及UI的整体性能。
例如:如果我们在自定义View的onDraw()中进行内存的分配,则很容易产生内存抖动。这样会导致我们在绘制每一帧的时候都会触发一次或多次GC,GC减少了留给帧绘制的可用时间,更容易造成界面卡顿。
四种引用
JAVA定义了四中级别的引用强度:
- 强引用(StrongReference)
效果:存在强引用的对象,不会被JVM回收。
回收:当所有的强引用都断开后,在JVM进行垃圾回收时,该对象会被回收。// 强引用 String str = new String("Reference");// 置空 obj = null; // 指向另一对象 obj= newObject(); - 软引用(SoftReference)
效果:存在软引用的对象,在内存不足时,才会被JVM回收。
应用:缓存数据,提高数据的获取速度。// 软引用:缓存数据 SoftReferencesr = newSoftReference (new String("CacheData")); // 获取数据 String str = sr.get(); // 断开强引用 str= null; - 弱引用(WeakReference)
效果:存在弱引用的对象,每次JVM进行垃圾回收时,该对象都会被回收。
应用:短时间缓存某些次要数据。// 弱引用 WeakReferencewr = newWeakReference (new String("CacheData")); // 获取数据 String str = wr.get(); // 断开强引用 str= null; // 弱引用Map WeakHashMap - 幽灵引用/虚引用(PhantomReference)
效果:相当于无引用,使对象无法被使用,必须与引用队列配合使用。
应用:使对象进入不可用状态,等待下次JVM垃圾回收,从而使对象进入引用列队中。// 引用队列 ReferenceQueuerq = newReferenceQueue (); // 幽灵引用 PhantomReference pr = newPhantomReference (new String(""),rq); // 永远为null(幽灵引用相当于无引用) System.out.println(pr.get()); - 引用队列(ReferenceQueue)
效果:引用队列可以配合软引用、弱引用及幽灵引用使用,当引用的对象将要被JVM回收时,会将其加入到引用队列中。
应用:通过引用队列可以了解JVM垃圾回收情况。// 引用队列 ReferenceQueuerq = newReferenceQueue (); // 软引用 SoftReference sr = newSoftReference (new String("Soft"),rq); // 弱引用 WeakReference wr = newWeakReference (new String("Weak"),rq); // 幽灵引用 PhantomReference pr = newPhantomReference (new String("Phantom"),rq); // 从引用队列中弹出一个对象引用 Reference ref = rq.poll();
内存泄漏
内存泄漏指的是:一个不再被使用的对象被另外一个还存活的对象所引用着。在这种情况下,垃圾回收器会跳过它,因为这种引用关系足以让该对象继续驻留在内存中。
实际上,内存泄漏是在组织垃圾回收器为未来的内存分配空间。这些泄漏的对象会一直占用着我们的内存空间,导致我们的堆内存空间变的更小,也加剧了GC的频繁程度,当没有更多内存可用于分配一个新对象时,系统就会抛出OOM异常。
数据类型
Java有下面这几种基本类型
byte:8 bit
short:16 bit
int:32 bit
long:64 bit
float:32 bit
double:64 bit
boolean:通常是8 bit,具体的bit由虚拟机决定
char:16 bit
如果我们不是特别需要的话,不要使用一个比需求更大的基本类型,因为每次CPU在处理时,会浪费不必要的内存和计算量。在计算一个表达式时,内存需要做一个隐式转换,将表达式中的基本类型转化为其中最大的那个基本类型。
-
自动装箱与自动拆箱
自动装箱指的是基本类型和它对应的包装类之间的自动转换。
包装类包含以下几种:Byte Short Integer Long Float Double Boolean Character例如:
Integer i = 0;等同于Integer i = Integer.valueOf(0);
当执行int j = i;的时候等同于int j = i.intValue();这个过程就是于自动装箱对应的自动拆箱
所以我们从上面可以看到,自动装箱虽然为我们提供了便利,但是它却会带来许多额外的消耗。首先,包装后的对象要比基本类型大的多,例如一个Integer的对象需要16byte,而int对象只需要16bit。其次,如果我们对一个基本类型包装类做任意操作的话都会至少带来一个额外的对象分配。比如下面的代码:Integer integer = 0; integer++;我们来解释一下这个简单的代码块,看看每一步都发生了什么。
- 首先,integer的值是通过integer对象得到的, 接着该值加1
int temp = integer.intValue() + 1; - 然后,将得到的结果赋值给integer对象,但这也意味着需要执行一个新的自动装箱操作
integer = Integer.valueOf(temp);
从上面的代码我们可以发现,对基本类型包装类的对象integer执行一次integer++的操作,就触发了一次自动拆箱,一次自动装箱和一个临时变量。但是如果我们使用基本类型的话就不会有这么多麻烦。如果integer++发生在循环中,那么……
Integer integer = 0; for(int i = 0; i < 100; i++) { integer += i; }因此我们应该尽可能的避免使用自动装箱。因为,在应用程序执行期间,自动装箱使用的越多,造成的内存浪费就越多。如果在循环中使用自动装箱,浪费会大大的增加,不仅影响内存,而且还会影响CPU的计算量。
- 首先,integer的值是通过integer对象得到的, 接着该值加1
-
SparseArray ArrayMap HashMap应该如何选择与使用
-
HashMap
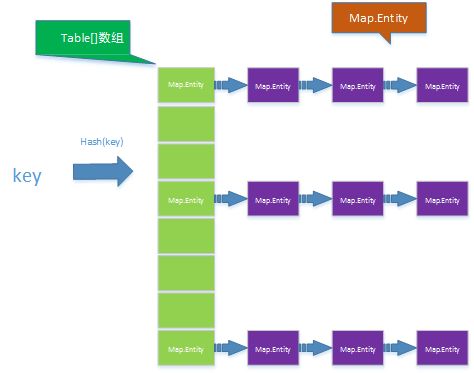 hashMap.png
hashMap.png
从hashMap的结构中可以看出,首先对key值求hash,根据hash结果确定在table数组中的位置,当出现哈希冲突时采用开放链地址法进行处理。Map.Entity的数据结构如下:
static class HashMapEntryHashMap中会有一个利用率不超过负载因子(默认为0.75, 这个值在JAVA中可以配置, 但是在Android中是写死不可更改的)的table数组(Android中默认大小是4),其次,对于HashMap的每一条数据都会用一个HashMapEntry进行记录,除了记录key,value外,还会记录下hash值,及下一个entity的指针。
时间效率方面,利用hash算法,插入和查找等操作都很快,且一般情况下,每一个数组值后面不会存在很长的链表(因为出现hash冲突毕竟占比较小的比例),所以不考虑空间利用率的话,HashMap的效率非常高。
HashMap的扩容: HashMap在插入新数据的时候, 每次都会判断是否需要扩容(如果当前HashMap中的数据量 >= length * 负载因子), 如果需要扩容, 就将当前HashMap的容量扩大一倍, 并且需要重新建立Hash映射. -
ArrayMap
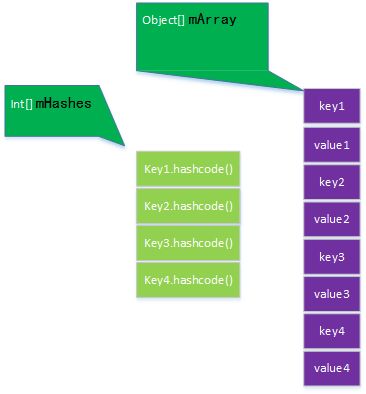 arrayMap.png
arrayMap.png
ArrayMap利用两个数组,mHashes用来保存每一个key的hash值,mArrray大小为mHashes的2倍,依次保存key和value。
//用于保存key对应的hashCode; int[] mHashes; //用于保存键值对(key,value),其结构为[key1,value1,key2,value2,key3,value3,......]; Object[] mArray; mHashes[index] = hash; mArray[index<<1] = key; mArray[(index<<1)+1] = value;ArrayMap的内部会有两个缓存数组分别用来缓存size大小是4和8的mArray和mHashes, 每个缓存数组的最大缓存数量都是10个, 这两个缓存数组是属于ArrayMap类的, 而不是某一个ArrayMap对象
//ArrayMap最小的增长大小, size一般为 4 8 8*1.5 8*1.5*1.5 private static final int BASE_SIZE = 4; //mBaseCache和mTwiceBaseCache最大缓存的次数 private static final int CACHE_SIZE = 10; //缓存,如果ArrayMap的数据量从4,增加到8,用该数组保存之前使用的mHashes和mArray, //这样如果数据量再变回4的时候,可以再次使用之前的数组,不需要再次申请空间,这样节省了一定的时间; static Object[] mBaseCache; static int mBaseCacheSize; //与mBaseCache对应,不过触发的条件是数据量从8增长到12。 static Object[] mTwiceBaseCache; static int mTwiceBaseCacheSize;从上面的源码中我们可以看到它的实现原理了。下面我们就分析一下它的插入, 删除操作。
插入操作
当插入时,根据key的hashcode()方法得到hash值,计算出在mArrays的index位置,然后利用二分查找找到对应的位置进行插入,当出现哈希冲突时,会在index的相邻位置插入。
插入前会判断当前ArrayMap中是否已经存储满了(这个是实打实的放不下了, 不像HashMap只要size到了75%就扩容).
如果满了, 就调用private void allocArrays(final int size)按照4 8 8*1.5 8*1.5*1.5...的顺序扩容(当然, 在扩容前会有限从两个缓存数组中去取, 如果有可用的缓存数组就直接拿来用, 省去了开辟空间的消耗), 然后调用private static void freeArrays(final int[] hashes, final Object[] array, final int size)来看刚才废弃的mArrays和mHashes是不是可以放到两个缓存数组中, 如果可以就缓存起来, 供后面使用.
如果没满, 就将这对public V put(K key, V value) { final int hash; int index; //key是空,则通过indexOfNull查找对应的index;如果不为空,通过indexOf查找对应的index if (key == null) { hash = 0; index = indexOfNull(); } else { hash = key.hashCode(); index = indexOf(key, hash); } //index大于或等于0,一定是之前put过相同的key,直接替换对应的value。因为mArray中不只保存了value,还保存了key。 //其结构为[key1,value1,key2,value2,key3,value3,......] //所以,需要将index乘2对应key,index乘2再加1对应value if (index >= 0) { index = (index<<1) + 1; final V old = (V)mArray[index]; mArray[index] = value; return old; } //取正数 index = ~index; //mSize的大小,即已经保存的数据量与mHashes的长度相同了,需要扩容啦 if (mSize >= mHashes.length) { //扩容后的大小,有以下几个档位,BASE_SIZE(4),BASE_SIZE的2倍(8),mSize+(mSize>>1)(比之前的数据量扩容1/2) final int n = mSize >= (BASE_SIZE*2) ? (mSize+(mSize>>1)) : (mSize >= BASE_SIZE ? (BASE_SIZE*2) : BASE_SIZE); if (DEBUG) Log.d(TAG, "put: grow from " + mHashes.length + " to " + n); final int[] ohashes = mHashes; final Object[] oarray = mArray; //扩容方法的实现 allocArrays(n); //扩容后,需要把原来的数据拷贝到新数组中 if (mHashes.length > 0) { if (DEBUG) Log.d(TAG, "put: copy 0-" + mSize + " to 0"); System.arraycopy(ohashes, 0, mHashes, 0, ohashes.length); System.arraycopy(oarray, 0, mArray, 0, oarray.length); } //看看被废弃的数组是否还有利用价值 //如果被废弃的数组的数据量为4或8,说明可能利用价值,以后用到的时候可以直接用。 //如果被废弃的数据量太大,扔了算了,要不太占内存。如果浪费内存了,还费这么大劲,加了类干啥。 freeArrays(ohashes, oarray, mSize); } //这次put的key对应的hashcode排序没有排在最后(index没有指示到数组结尾),因此需要移动index后面的数据 if (index < mSize) { if (DEBUG) Log.d(TAG, "put: move " + index + "-" + (mSize-index) + " to " + (index+1)); System.arraycopy(mHashes, index, mHashes, index + 1, mSize - index); System.arraycopy(mArray, index << 1, mArray, (index + 1) << 1, (mSize - index) << 1); } //把数据保存到数组中。看到了吧,key和value都在mArray中;hashCode放到mHashes mHashes[index] = hash; mArray[index<<1] = key; mArray[(index<<1)+1] = value; mSize++; return null; }删除操作
remove方法在某种条件下,会重新分配内存,保证分配给ArrayMap的内存在合理区间,减少对内存的占用。
具体的收缩规则是这样的:
如果当初申请的数组最大容纳数据个数大于BASE_SIZE的2倍(8),并且现在存储的数据量只用了申请数量的1/3,需要调用private void allocArrays(final int size)重新分配空间,已减少对内存的占用, 需要注意的是收缩后最小的大小就是8, 不会到达4, 源码里解释是为了减少size在BASE_SIZE和2*BASE_SIZE之间抖动.
否则的话就直接删除该index的数据并将数组中之后的数据前移.
remove最终使用的是removeAt方法,此处只说明removeAtpublic V removeAt(int index) { final Object old = mArray[(index << 1) + 1]; //如果数据量小于等于1,说明删除该元素后,没有数组为空,清空两个数组。 if (mSize <= 1) { // Now empty. if (DEBUG) Log.d(TAG, "remove: shrink from " + mHashes.length + " to 0"); //put中已有说明 freeArrays(mHashes, mArray, mSize); mHashes = EmptyArray.INT; mArray = EmptyArray.OBJECT; mSize = 0; } else { //如果当初申请的数组最大容纳数据个数大于BASE_SIZE的2倍(8),并且现在存储的数据量只用了申请数量的1/3, //则需要重新分配空间,已减少对内存的占用 if (mHashes.length > (BASE_SIZE*2) && mSize < mHashes.length/3) { // Shrunk enough to reduce size of arrays. We don't allow it to // shrink smaller than (BASE_SIZE*2) to avoid flapping between // that and BASE_SIZE. //新数组的大小 final int n = mSize > (BASE_SIZE*2) ? (mSize + (mSize>>1)) : (BASE_SIZE*2); if (DEBUG) Log.d(TAG, "remove: shrink from " + mHashes.length + " to " + n); final int[] ohashes = mHashes; final Object[] oarray = mArray; allocArrays(n); mSize--; //index之前的数据拷贝到新数组中 if (index > 0) { if (DEBUG) Log.d(TAG, "remove: copy from 0-" + index + " to 0"); System.arraycopy(ohashes, 0, mHashes, 0, index); System.arraycopy(oarray, 0, mArray, 0, index << 1); } //将index之后的数据拷贝到新数组中,和(index>0)的分支结合,就将index位置的数据删除了 if (index < mSize) { if (DEBUG) Log.d(TAG, "remove: copy from " + (index+1) + "-" + mSize + " to " + index); System.arraycopy(ohashes, index + 1, mHashes, index, mSize - index); System.arraycopy(oarray, (index + 1) << 1, mArray, index << 1, (mSize - index) << 1); } } else { mSize--; //将index后的数据向前移位 if (index < mSize) { if (DEBUG) Log.d(TAG, "remove: move " + (index+1) + "-" + mSize + " to " + index); System.arraycopy(mHashes, index + 1, mHashes, index, mSize - index); System.arraycopy(mArray, (index + 1) << 1, mArray, index << 1, (mSize - index) << 1); } //移位后最后一个数据清空 mArray[mSize << 1] = null; mArray[(mSize << 1) + 1] = null; } } return (V)old; }分析完ArrayMap的使用过程后, 我们来总结一下它的特点:
从空间角度考虑,ArrayMap每存储一条信息,需要保存一个hash值,一个key值,一个value值。对比下HashMap 粗略的看,减少了一个指向下一个entity的指针。多了两个缓存数组,可以在ArrayMap存储条目在8以下的时候最大化的减少内存的申请和释放的开销。每次插入和删除操作后,都会对ArrayMap的大小进行扩容或收缩,来保持其大小的合理,避免内存浪费。
时间效率上看,插入和查找的时候因为都用的二分法,查找的时候应该是没有hash查找快,插入的时候呢,如果顺序插入的话效率肯定高,但如果是随机插入,肯定会涉及到大量的数组搬移。同理, 删除的时候呢, 如果每次都删除最后一个,效率也会很高,但是如果随机删除,也会产生大量的数组搬移。因此插入和删除的操作都没有HashMap效率高,但是如果size小于1000的时候性能基本还是差不多的,太大就不适合用了。 -
SparseArray
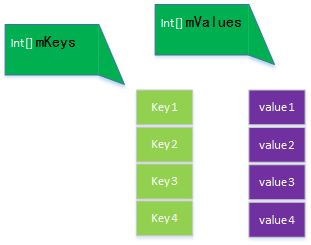 sparseArray.png
sparseArray.png
SparseArray相比于前两个,它使用基本类型int作为Key的类型(还有LongSparseArray,它的Key的类型为long等一大堆以基本类型作为Key的SparseArray),因此避免了自动装箱和自动拆箱的多余操作。
private int[] mKeys; private Object[] mValues;因为key为int也就不需要什么hash值了,只要int值相等,那就是同一个对象,简单粗暴。插入和查找也是基于二分法,所以原理和Arraymap基本一致,但是它的扩容不是按照ArrayMap的扩容规则来的,而是按照<=4 8 2*8 2*8*8的规则来的,而且它也没有缓存数组
下面我们主要分析一下它的延迟回收,延迟回收的意思就是,SparseArray删除的时候并不会立即回收这对,而是会将它的value置为DELETE,然后在它的 put(int, E), size(), keyAt(int), valueAt(int) setValueAt(int, E), indexOfKey(int), indexOfValue(E), append(int, E)这几个直接或间接需要真实的数组大小或者需要获取某一个index的Key或Value的时候,SparseArray才会触发它的gc()方法来回收之前延迟回收的那些public void delete(int key) { int i = ContainerHelpers.binarySearch(mKeys, mSize, key); if (i >= 0) { if (mValues[i] != DELETED) { mValues[i] = DELETED; mGarbage = true; } } } private void gc() { int n = mSize; int o = 0; int[] keys = mKeys; Object[] values = mValues; for (int i = 0; i < n; i++) { Object val = values[i]; if (val != DELETED) { if (i != o) { keys[o] = keys[i]; values[o] = val; values[i] = null; } o++; } } mGarbage = false; mSize = o; }分析完SparseArray的使用过程后,我们来总结一下它的特点:
从空间角度考虑,与HashMap相比,去掉了Hash值的存储空间,没有next的指针占用,还有其他一些小的内存占用,看着节省了不少。
从时间效率上看,插入和查找的情形和Arraymap基本一致,可能存在大量的数组搬移。但是它避免了装箱的环节,不要小看装箱过程,还是很费时的。对比SparseArray和包含自动装箱过程的HashMap,在查询时间上SparseArray其实是快于HashMap的(虽然SparseArray用的是二分查找,但是省略的自动装箱的时间已经足以弥补了),而且SparseArray使用了延迟回收,来提高它的回收效率。 -
最后对HashMap,ArrayMap和SparseArray做一个整体的总结:
- HashMap
优点:增、删、查找速度较快
缺点:双倍扩容、不做空间整理,内存使用效率低
适用场景:数据量较大或内存空间相对宽裕 - ArrayMap
优点:用两个缓存数组来减少size<=8时的内存申请和释放的开销,每次插入和删除操作后,都会对ArrayMap的大小进行扩容或收缩,来保持其大小的合理,避免内存浪费。
缺点:增、删、查速度较慢
适用场景:数据量小于1000时,速度相对差别不大,可替代HashMap - SparseArray
优点:避免了自动装箱,使用延迟回收机制,因此删除和查找的速度会比较快。矩阵压缩,大大减少了存储空间,节约内存。
缺点:插入的速度较慢
适用场景:在key是Integer、Long,且数据量较小场景下性能最优
因此,当我们数据量小于1000时,优先使用SparseArray,如果Key值不为基本类型,则使用ArrayMap,当数据量较大就要自己权衡是使用性能较好的HashMap还是内存占用较少的SparseArray和ArrayMap了。
- HashMap
-
-
枚举
枚举最简单的使用方法如下方:
public enum SHAPE { SQUARE, CIRCLE, RECTANGLE }他们可以被替换为以下代码片段
public class SHAPE { public static final int SQUARE = 0; public static final int CIRCLE = 1; public static final int RECTANGLE= 2; }那么从内存角度来看哪个消耗更大呢?枚举在使用中被转换为3个Enum对象, 每个Enum包含一个String类型的name,一个int类型的oridinal,以及一个array和一个包装类。相反,常量的实现方式只需要四个整形值。
在SHAPE的class文件中,会被解析成类似于这样的代码:public final class SHAPE extends java.lang.Enum{ public static final SHAPE VALUE1; public static final SHAPE VALUE2; public static final SHAPE VALUE3; private static final SHAPE [] values[]; static{} }更糟糕的是枚举不仅会加大我们运行时内存的占用,还会增加我们Dex包的大小。
所以我们需要在程序中尽量少的使用枚举。
那么如果我们已经在程序中使用了枚举,有没有比较简单的替换方法可以替换成常量呢?当然有!
Android 提供了注解库,其中有TypeDef注解。这些注解能够确保一个特定的参数,返回值或者字段能够在特别一组常量中引用一个。它们能确保自动完成允许的常量中选择一个。
IntDef和StringDef是两个神奇的注解常量,可以用来替代Enum的使用。这些注解能够帮助我们在编译时对变量赋值进行检查。
如何使用请参考:Android 性能:避免在Android上使用ENUM -
常量
让我们来看看这两段在类前面的声明:
static int intVal = 42; static String strVal = "Hello, world!";编译器会生成一个叫做clinit的初始化类的方法,当类第一次被使用的时候这个方法会被执行。方法会将42赋给intVal,然后把一个指向类中常量表 的引用赋给strVal。当以后要用到这些值的时候,会在成员变量表中查找到他们。 下面我们做些改进,使用“final”关键字:
static final int intVal = 42; static final String strVal = "Hello, world!";现在,类不再需要clinit方法,因为在成员变量初始化的时候,常量会被存放在dex文件的静态字段初始化器中被直接访问。用到intVal的代码被直接替换成42,而使用strVal的会指向一个字符串常量,而不是使用成员变量。此规则只对基本类型和String类型有效。
对象管理
-
字符串
我们先讲一下"String常量池"这个概念,当我们创建String对象采用字面量形式时,JVM首先会对这个字面量进行检查,如果常量池中存放有该字面量,则直接使用,否则创建新的对象并将其引用放入常量池中。
上面的s1创建时会将"shehuilong"放到String常量池中,我们再次创建s2的时候,JVM检测到String常量池中已经存在了"shehuilong"这个字符串,所以就直接拿来用了,因此s1==s2是trueString s1="shehuilong"; String s2="shehuilong"; System.out.println(s1==s2);//true
这段代码中s2因为是用new创建的对象,所以JVM不会去String常量池中检查,而是直接在堆中创建s2的实例。当然如果我们想把new出来的String的值放到String常量池中也不是不可以,调用String的String s1="shehuilong"; String s2=new String("shehuilong"); System.out.println(s1==s2);//falseintern()方法就可以了。
当我们new新的对象时,之后再调用intern()方法,如果没有把s2重新引用则s2仍为原来的对象,此时s1不等于s2,若重新引用常量池中的对象,则s1等于s2String s1="shehuilong"; String s2=new String("shehuilong").intern(); System.out.println(s1==s2);//true
我们说了这么多,String常量池存在哪里呢?里面保存的是对象还是引用?String s1="shehuilong"; String s2=new String("shehuilong"); s2.intern(); System.out.println(s1==s2);//false; s2=s2.intern(); System.out.println(s1==s2);//true;
上面我们讲GC的时候其实已经说过了,String常量池保存在方法区中,它里面保存的其实是字符串对象的引用,"shehuilong"其实是保存在堆中的。当String常量池中的引用没有对象引用它时,它就会被GC回收! -
字符串拼接
String s="she"+"hui"+"long";
正常情况下,执行声明s代码会生成3个对象,即对象she、对象shehui、对象shehuilong,其中对象she和对象shehui都是中间的临时变量,最后的对象shehuilong才赋值给了s。因此在使用字符串拼接的时候,拼接的数量越多,性能越低!
但是java编译器在编译的时候做了优化,在编译时新建一个对象StringBuilder来拼接,这样就避免了产生很多临时对象,从而提升了性能!但是及时做了优化,我们在循环中拼接字符串的代码性能也很低下:
之所以低下的原因是因为循环内,每次都在做字符串拼接,每次都在产生一个StringBuilder对象,造成内存的浪费!因此这种错误要尽量避免,稍做以下优化即可完美改造:String s = ""; for (int i = 0; i < length; i++) { s += i; }
通过以上案例,我们就已经知道了字符串拼接时尽量使用StringBuilder或者StringBuffer对象,特别时循环中的拼接!String s = ""; StringBuilder sb = new StringBuilder(); for (int i = 0; i < length; i++) { sb.append(i); }
那么StringBuilder与StringBuffer有啥区别呢?
两者的共同点都是建立一个字符串缓冲区,然后调用相关方法操作字符串!不同点就是StringBuilder是非同步的,而StringBuffer是同步的,因此StringBuilder执行效率更高,在不需要同步的情况下优先使用StringBuilder,否则使用StringBuffer来保证数据的同步,即多线程的情况下! -
本地变量
有时候我们的方法内部存在某个对象,但是它在整个方法的过程中都没有被修改过。这种变量我们就可以把它移到方法外部。这样,他只需被分配一次,并且不会被回收,改善了内存管理。
上面代码中的dateFormat对象没必要每次都进行一次实例化。而且,每次分配的新对象直到垃圾回收器到达上限时才会被回收,在此期间占用了很多不必要的内存空间,因此把它移到方法外面更好。public String format(Date date) { DateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd"); return dateFormat.format(date); }private DateFormat mDateFormat = new SimpleDateFormat("yyyy-MM-dd"); public String format(Date date) { return mDateFormat.format(date); } -
数组 VS 集合
虽然集合可以根据需求自动扩大或者减小,并且提供了大量有用的方法,可以用于添加,获取,删除等操作,但这也使得集合的使用代价十分高昂,最明显的就是它不能使用基本类型,因此产生了很多自动装箱的操作,如果你细心观察的话,上面我们分析的ArrayMap,SparseArray内部使用的都是数组而不是集合。所以当我们的数据量很大或者对内存要求很高的时候应该尽量使用数组来代替集合。 -
流, Bitmap, Cursor等一系列使用后需要手动关闭的资源
Java中有一个接口叫做Closeable, 我们熟悉的Cursor,inputStream,outputStream和SQLiteDataBase等很多很多类都继承了这个接口,那这个接口是干什么用的呢?从上面的注释中我们可以了解到,它是用来手动释放这个对象所持有的资源。如果我们使用完继承了Closeable接口的对象后没有调用close方法,那么很大可能会产生内存泄露。/** * A {@code Closeable} is a source or destination of data that can be closed. * The close method is invoked to release resources that the object is * holding (such as open files). * * @since 1.5 */ public interface Closeable extends AutoCloseable { /** * Closes this stream and releases any system resources associated * with it. If the stream is already closed then invoking this * method has no effect. * * @throws IOException if an I/O error occurs */ public void close() throws IOException; }
那么有没有好的方法来检测我们已经写过的代码中是否存在没有调用close方法的对象呢?当然是有啊!!!
Android在2.3的时候引入了一个叫做StrictMode的工具类,别着急,之后讲调试工具的时候会详细讲它。它包含两种检测策略:ThreadPolicy线程策略检测和VmPolicy虚拟机策略检测
我们就可以使用VmPolicy虚拟机策略检测中的detectLeakedClosableObjects()方法来对未关闭的Closeable对象进行检测。
除了Closeable接口外,Android中还存在像Bitmap同时申请了Java内存和Native内存的类型,正常的GC只能释放Java部分的内存,因此当我们不再需要使用Bitmap对象时我们还是需要手动调用recycle()方法来释放Native内存的。
内存设计模式
-
对象池模式
在众多富有创造性的设计模式中,对象池模式对于重用已分配对象非常有帮助。它避免了内存抖动,以及由此给应用带来的副作用。当我们要大量创建耗费资源的对象时,该模式很有用。
该模式背后的思想是,避免对一个将来可能被重用的对象进行垃圾回收,节省了创建对象所花费的时间。要实现这一点,需要一个被成为对象池的对象,它负责管理大量的可重用对象,是的这些可重用对象可以被请求者所使用。这些请求者被称为客户。因此,在该模式中,需要处理以下三种类型的对象。- ReusableObject:可重用对象,被客户使用,被对象池管理。
- Client:客户,需要一个可重用对象来做一些事情,所以它需要向对象池请求一个对象,并在使用后归还给对象池。
- ObjectPool:对象池,持有所有可重用对象,负责供给和回收这些对象。
ObjectPool应该是一个单例对象,以便集中管理所有的可重用对象,避免在不同的对象池之间,产生混乱的交换关系,并且使得每个可重用对象,共享统一的创建方式。
ObjectPool包含的对象数量有一个上限。也就是说,当一位客户在请求一个可重用的对象时,如果对象池已满,并且所有的可重用对象都在使用中,那么该请求会被阻塞,知道其他客户归还了一个可重用对象。
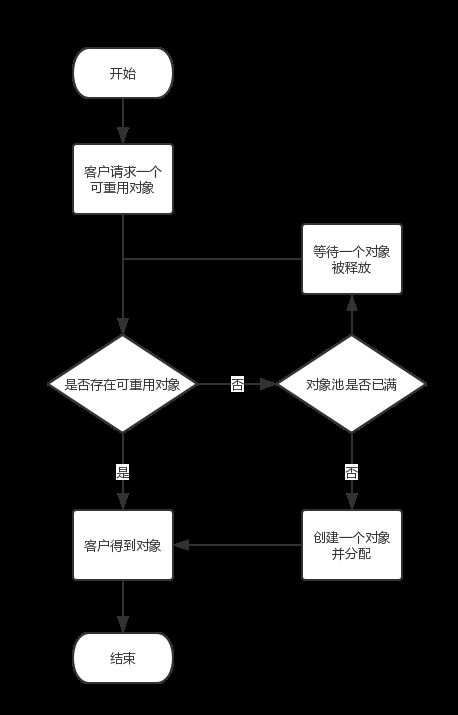 对象池模式.png
对象池模式.png在Android源码中有一个我们经常使用的类就用到了对象池模式。这个类就是Message。
Android建议我们在获取Message的时候会调用Message.obtain();方法来获取一个新的Message而不是使用Message message = new Message();来new一个Message,那这是不是因为Message内部给我维护了一个对象池呢?我们来看一下Message.obtain();的实现。public static Message obtain() { synchronized (sPoolSync) { if (sPool != null) { Message m = sPool; sPool = m.next; m.next = null; m.flags = 0; // clear in-use flag sPoolSize--; return m; } } return new Message(); }实现很简单,我们在代码里看到了一个sPool,难道这个就是我们之前所说的对象池?目前还不能确定,我们继续看一下源码里sPool是怎么定义的。
private static final Object sPoolSync = new Object(); private static Message sPool; private static int sPoolSize = 0;sPool居然是一个Message对象,难道我们猜错了?再仔细看看,发现上面还有一个next变量。
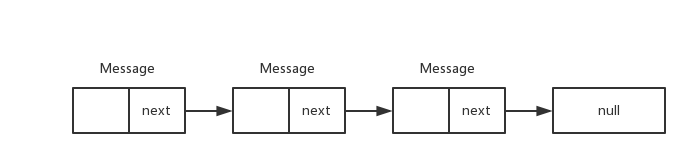
// sometimes we store linked lists of these things Message next;原来Message消息池并没有使用Map这样的容器,而是使用了链表,Message的结构如下图所示:
 Message结构.png
Message结构.png
每个Message对象都有一个Message类型的next字段,这个next指向的就是下一个可用的Message,最后一个Message的next为null。这样以来所有可用的Message对象就通过next串成了一个Message池。
那么这么Message对象什么时候被放到链表中呢?我们只看到了obtain方法中从链表中获取Message。
继续搜索Message类,我们发现一个和Bitmap类似的recycle函数。public void recycle() { //判断消息是否还在使用中 if (isInUse()) { if (gCheckRecycle) { throw new IllegalStateException("This message cannot be recycled because it " + "is still in use."); } return; } //清空状态,并将消息添加到消息池中 recycleUnchecked(); } void recycleUnchecked() { //清空消息状态,设置该消息的flags为FLAG_IN_USE flags = FLAG_IN_USE; what = 0; arg1 = 0; arg2 = 0; obj = null; replyTo = null; sendingUid = -1; when = 0; target = null; callback = null; data = null; //回收该消息到消息池中 synchronized (sPoolSync) { if (sPoolSize < MAX_POOL_SIZE) { next = sPool; sPool = this; sPoolSize++; } } }recycle方法会将一个Message对象回收到一个全局的池中,这个池就是我们上文所说的链表。recycle函数首先判断该消息是否还在使用,如果还在使用就抛出异常,否则调用recycleUnchecked方法来处理该消息。
recycleUnchecked方法中先清空Message的各个字段,并将flags置为FLAG_IN_USE,表明该消息已被使用,这个flags会在obtain方法中置为0,这样根据flags这个字段就可以追踪到该Message的状态。清空完字段后就判断是否要将该消息会受到该消息放到消息池中,如果池的大小小于MAX_POOL_SIZE,就讲该Message添加到链表的表头。
介绍完了recycle方法,我们会发现,我们在使用Message后几乎从来没有调用过它的recycle方法,那这样的话会不会导致消息池的消息越来越少,不会将用过的Message放回的消息池中呢?
答案是并不会,机智的Looper已经帮我们回收了用过的Message了。public static void loop() { final Looper me = myLooper(); final MessageQueue queue = me.mQueue; for (;;) { Message msg = queue.next(); // might block try { msg.target.dispatchMessage(msg); } finally { if (traceTag != 0) { Trace.traceEnd(traceTag); } } //这里Looper已经帮我们回收了Message msg.recycleUnchecked(); } }所以我们不需要手动调用
Message.recycle();来回收Message了。
总结一下:我们之前说过,对象池模式需要三个角色ReusableObject,Client和ObjectPool。Message其实自己扮演了ReusableObject和ObjectPool两个角色,我们则扮演了Client。虽然和介绍的有些出入,但是还是可以看出Message用的是对象池模式来管理的。也许增加一个MessagePool来管理Message对象的回收和获取会更清晰一些吧。 -
享元模式
许多开发者会讲对象池模式和享元模式混淆。但他们面向的领域其实是不一样的。
- 对象池的目的是,面对需要大量分配高成本的对象时,通过对象重用尽量减少内存分配以及垃圾回收对系统产生的影响。
- 享元的目的是,通过节省所有对象内存的状态,以减少载入内存的量。
享元模式中客户请求的对象包含两种状态:
- Internal state:内部状态。由所有能够唯一标识一个对象的字段构成,并且这些字段不与其他对象共享。
- External state:外部状态。在所有可交换对象之间能够共享的字段的集合。
所以享元模式所做的是,为所有对象只创建一个实例,实现内部状态的重用,减少内存的消耗。
 享元模式.png
享元模式.png
享元模式一般有三个角色:- FlyWeightObjects:享元对象。它们可以改变内部状态,并访问内部对象。
- FlyWeightFactory:享元工厂。当客户请求享元对象时,享元工厂负责创建享元对象,管理享元对象的内部状态。他也负责将享元对象存储在一个池中,以便借给用户。
-
Clients:客户。请求享元对象。
用一张图来描述享元模式可能非常容易理解
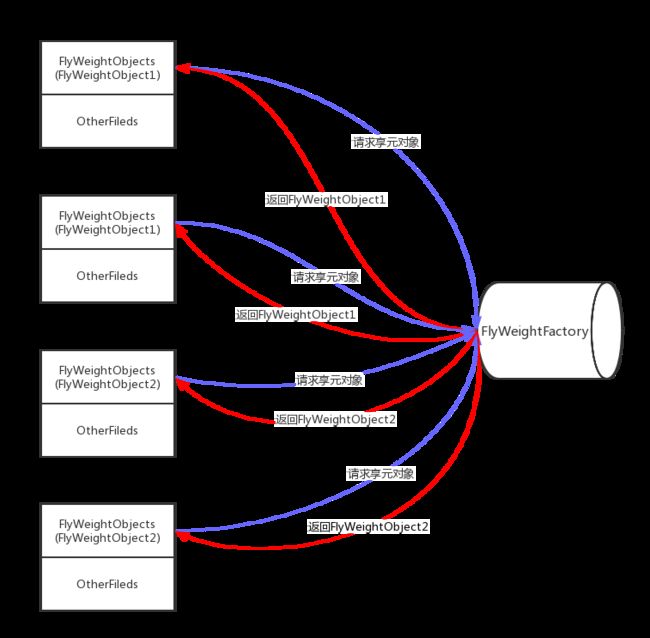 享元模式.png
享元模式.png
从上面的图可以看出来,享元模式其实就是当我们有很多对象时,恰巧这些对象内部有很多相似的对象(享元对象),这个时候我们就可以通过享元工厂来让这些对象公用相同的享元对象,来减少载入内存的量。
当然,从上图你也可以看出享元模式有一个很大的弊端,就是当很多对象公用一个享元对象时,我们就对享元对象的更改就要非常的小心谨慎。
Android组件泄露
-
Activity
Activity是Android应用中最常用的组件,也是唯一一个提供用户接口的组件。Activity和它包含的每个View之间都存在强引用的关系,这也使得他们特别容易造成内存泄露,许多不同的内存泄露问题都与Activity有关。
一个不在被引用的Activity如果仍然驻留在内存中,会带来很大的代价。Activity关联着大量的其他对象,如果Activity本身不能被回收,那么这些对象也不能被回收。此外,一个Activity在应用程序的生命周期内,可以被多次销毁和重建,比如,在配置发生变化(比如手机横竖屏变化,导致Activity重建)或内存回收(比如手机内存不够时,处在后台的Activity会被系统回收)的情况下。如果Activity存在内存泄露问题,那么每个泄露的Activity实例都会常驻在内存中,这会对内存造成很大的影响。
当我们需要使用的Context不是必须为Activity时,则尽量使用Application中的Context。
 几种Context的区别.png
几种Context的区别.png
下面列举一些常见的容易造成Activity泄露的场景:
- 静态字段
这种就属于典型的静态字段造成的内存泄露,Activity的实例一直被未销毁的sIoRunnable所引用,因此一直不会被回收,直到我们应用被销毁。public class MyActivity extends Activity { public static IORunnable sIoRunnable; @Override public void onCreate(@Nullable Bundle savedInstanceState, @Nullable PersistableBundle persistentState) { super.onCreate(savedInstanceState, persistentState); sIoRunnable = new IORunnable(this); } } public class IORunnable implements Runnable { public Context mContext; public IORunnable(Context context) { mContext = context; } @Override public void run() { // bala bala bala } }
解决方案:尽量避免在静态变量中关联Activity,如果需要使用Context则尽量使用Application的Context,实在不行就将静态变量和软引用或弱引用的Activity关联起来,这样就不会影响Activity被回收了(具体实现下面会实现)。 - 非静态内部类
这种就属于典型的非静态内部类造成的内存泄露,当我们主动或被动销毁Activity的时候,因为IORunnable对象在执行完任务前一直持有它的外部类引用(Activity),所以我们的Activity并不会被立即销毁,而是会等到IORunnable对象执行完任务后才会被关闭。public class MyActivity extends Activity { @Override public void onCreate(@Nullable Bundle savedInstanceState, @Nullable PersistableBundle persistentState) { super.onCreate(savedInstanceState, persistentState); new IORunnable().run(); } private class IORunnable implements Runnable { @Override public void run() { Thread.sleep(100000); } } }
解决方案:将IORunnable设置成静态内部类,然后将它和Activity的软引用或者弱引用关联起来。public class MyActivity extends Activity { @Override public void onCreate(@Nullable Bundle savedInstanceState, @Nullable PersistableBundle persistentState) { super.onCreate(savedInstanceState, persistentState); new IORunnable(this).run(); } private static class IORunnable implements Runnable { private WeakReferencemActivityRefrence; public IORunnable(Activity activity) { mActivityRefrence = new WeakReference<>(activity); } @Override public void run() { Thread.sleep(100000); if (mActivityRefrence.get() != null) { //bala bala bala } } } } - 匿名内部类
这种就属于典型的匿名内部类造成的内存泄露,我们的mHandler是一个匿名内部类的对象,它会持有它的外部类(Activity)的引用。因此,在上述代码中,我们通过这个mHandler延迟1000s发送了一条Message,那么在这1000s内如果Activity被主动或被动的销毁了,它都不会被回收,因为mHandler持有它的引用。public class MyActivity extends Activity { private Handler mHandler = new Handler() { @Override public void handleMessage(Message msg) { // do something } }; @Override public void onCreate(@Nullable Bundle savedInstanceState, @Nullable PersistableBundle persistentState) { super.onCreate(savedInstanceState, persistentState); mHandler.sendMessageDelayed(Message.obtain(), 1000000); } }
解决方案:我们依然可以按照上面的方法,实现一个继承Handler的静态内部类,然后将它和Activity的软引用或者弱引用关联起来。或者,我们可以在Activity的onDestory中对mHandler进行释放操作@Override protected void onDestroy() { mHandler.removeCallbacksAndMessages(null); super.onDestroy(); } - 单例
这种就属于典型的单例模式造成的内存泄露,我们在单例中传入了我们的Activity作为context,因为单例的生命周期是存在于整个应用的生命周期中的,所以当我们主动或被动的销毁Activity时,由于Activity被单例所持有,所以不会被回收,因此造成了内存泄露。public class MyActivity extends Activity { @Override public void onCreate(@Nullable Bundle savedInstanceState, @Nullable PersistableBundle persistentState) { super.onCreate(savedInstanceState, persistentState); Singleton.getInstance().setContext(this); } } public class Singleton { private static volatile Singleton sInstance; private Context mContext; private Singleton() { } public static Singleton getInstance() { if (sInstance == null) { synchronized (Singleton.class) { if (sInstance == null) { sInstance = new Singleton(); } } } return sInstance; } public void setContext(Context context) { mContext = context; } }
解决方案:如果可以的话,尽量不要向单例中传入Activity作为context的引用,使用Application的context替代,替代不了的话,可以向之前一样,将单例和Activity的软引用或弱引用关联起来,使用完或者Activity销毁后,手动释放掉单例中的这个引用。
- 静态字段
-
Service
如果我们使用startService方法启动一个正常的Service的话,使用完毕后,系统并不会为我们停止这个Service,所以使用完毕后的Service依然占用着我们的资源。所以当我们使用完Service后,一定要记得将它关闭释放。停止一个Service有两种方式:
- 在Service内部,调用
Service.stopSelf()方法 - 在Service外部,调用
Context.stopService()方法
当然,如果你不想这么麻烦的话,可以使用IntentService,系统会在IntentService执行完后台工作后,自动关闭它。
- 在Service内部,调用
内存相关的API
-
ActivityManager
通过ActivityManager我们可以获取到上面这些对我们有价值的信息,比如,当我们处于低内存状态时,就会触发Android系统的LMK——Low Memory Kill来杀死一些优先级低的进程来释放内存空间。如果我们系统剩余内存低于内存阈值的话,就会进入低内存状态。当我们的应用申请内存超过单个APP申请的最大值就会触发OOM异常。Log.e("yitiaoxiaolong", "系统可用总内存:" + Formatter.formatFileSize(MainActivity.this, memoryInfo.totalMem)); Log.e("yitiaoxiaolong", "系统当前剩余内存:" + Formatter.formatFileSize(MainActivity.this, memoryInfo.availMem)); Log.e("yitiaoxiaolong", "系统是否处于低内存:" + memoryInfo.lowMemory); Log.e("yitiaoxiaolong", "系统内存阈值:" + Formatter.formatFileSize(MainActivity.this, memoryInfo.threshold)); Log.e("yitiaoxiaolong", "单个APP内存最大值:" + am.getMemoryClass() + "MB"); Log.e("yitiaoxiaolong", "单个APP内存最大值(申请large heap):" + am.getLargeMemoryClass() + "MB"); // 结果 E/yitiaoxiaolong: 系统可用总内存:2.80 GB E/yitiaoxiaolong: 系统当前剩余内存:1.39 GB E/yitiaoxiaolong: 系统是否处于低内存:false E/yitiaoxiaolong: 系统内存阈值:134 MB E/yitiaoxiaolong: 单个APP内存最大值:128MB E/yitiaoxiaolong: 单个APP内存最大值(申请large heap):512MB -
Runtime
Runtime是一个非常有用的类,可以获取很多运行时数据
通过Runtime我们可以获取到堆的大小,堆的最大值,和当前堆中剩余多少内存。Log.e("yitiaoxiaolong", "VM HEAP Size:" + Formatter.formatFileSize(MainActivity.this, Runtime.getRuntime().totalMemory())); Log.e("yitiaoxiaolong", "Free VM HEAP Size:" + Formatter.formatFileSize(MainActivity.this, Runtime.getRuntime().freeMemory())); Log.e("yitiaoxiaolong", "VM HEAP Size Limit:" + Formatter.formatFileSize(MainActivity.this, Runtime.getRuntime().maxMemory())); //结果 E/yitiaoxiaolong: VM HEAP Size:26.83 MB E/yitiaoxiaolong: Free VM HEAP Size:13.51 MB E/yitiaoxiaolong: VM HEAP Size Limit:128 MB -
ComponentCallbacks和ComponentCallbacks2接口
Android四大组件中除了Broadcast以外,都继承了ComponentCallbacks和ComponentCallbacks2接口,因此我们可以复写他们中的对应方法,来针对不同的内存情况做不同的应对措施。public interface ComponentCallbacks { // 当系统配置发生改变是会被调用 void onConfigurationChanged(Configuration newConfig); // 当LMK被触发,系统已经开始杀死其他进程时被调用 void onLowMemory(); } public interface ComponentCallbacks2 extends ComponentCallbacks { // 应用程序不可见 - 内存低 - 位于LRU(Least recently used,最近最少使用)底部 static final int TRIM_MEMORY_COMPLETE = 80; // 应用程序不可见 - 内存低 - 位于LRU中部 static final int TRIM_MEMORY_MODERATE = 60; // 应用程序不可见 - 内存低 - 位于LRU顶部 static final int TRIM_MEMORY_BACKGROUND = 40; // 应用程序不可见 - 位于LRU顶部 static final int TRIM_MEMORY_UI_HIDDEN = 20; // 应用程序可见 - 内存紧张 - 位于LRU顶部 static final int TRIM_MEMORY_RUNNING_CRITICAL = 15; // 应用程序可见 - 内存低 - 位于LRU顶部 static final int TRIM_MEMORY_RUNNING_LOW = 10; // 应用程序可见 - 内存较少 - 位于LRU顶部 static final int TRIM_MEMORY_RUNNING_MODERATE = 5; // 系统会根据上面这7中情况来调用onTrimMemory void onTrimMemory(int level); }
当然,除了复写以外,Context也给我们提供了两个方法来让我们更灵活的监听内存的变化。/** * Add a new {@link ComponentCallbacks} to the base application of the * Context, which will be called at the same times as the ComponentCallbacks * methods of activities and other components are called. Note that you * must be sure to use {@link #unregisterComponentCallbacks} when * appropriate in the future; this will not be removed for you. * * @param callback The interface to call. This can be either a * {@link ComponentCallbacks} or {@link ComponentCallbacks2} interface. */ public void registerComponentCallbacks(ComponentCallbacks callback) { getApplicationContext().registerComponentCallbacks(callback); } /** * Remove a {@link ComponentCallbacks} object that was previously registered * with {@link #registerComponentCallbacks(ComponentCallbacks)}. */ public void unregisterComponentCallbacks(ComponentCallbacks callback) { getApplicationContext().unregisterComponentCallbacks(callback); }
调试工具
---未完待续---