这些优秀的数据库管理员(以下简称数据库管理员为DBA),原本可以靠自己的本事,享受高薪,可是,好景不长了,因为即便是资质平平的DBA,以后借助AI的力量,也能瞬间达到优秀DBA的水平。
来看最近来自卡耐基梅隆数据库小组的最新研究成果,他们正用最新的深度学习技术,完成数据库的调优工作。
如果这项技术在未来进一步普及,那么,很无奈,这个行业不得不接受AI对于人员结构的改造。
DBA迎来新的革命
卡内基·梅隆大学数据库小组采用机器学习实现了数据库的自动化管理,其在线版的自动化管理服务 OtterTune 稍后即会上线。
OtterTune 所要解决的是数据库管理中最为繁杂的问题:诸如缓存大小分配、写入频率管理等因素在内的数百项参数的动态设置。过去,这项工作只能由经验丰富的数据库专家手动来完成。
这其中采用了怎样的原理呢?
OtterTune 到底用了什么原理?
采用机器学习后,OtterTune 把数据库管理系统(DBMS)的工作流程变成这样:
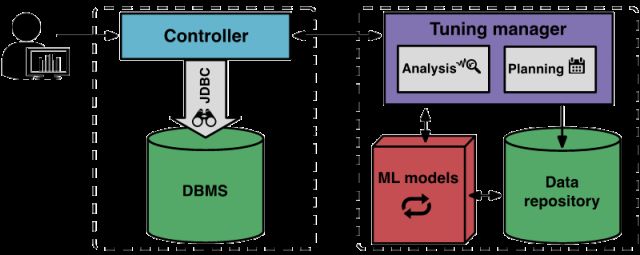
一开始,OtterTune 需要被告知明确的优化目标,如延迟、吞吐量等;其客户端 Controller 会自动关联目标 DBMS 及其亚马逊 EC2 副本的类型与当前设置。
而后,Controller 便开启第一个观察周期,观察 DBMS 并记录目标项。观察结束时,Controller 会搜集好 DBMS 的内部参数,并将它和目标项发送给 Tuning Manager。
收到参数后,Tuning Manager 便把它们存储入库。OtterTune 用这些参数计算出 DBMS 的目标配置,并将其发回至 Controller,Controller 部署并运行新的配置,以提升数据库性能。
管理人员可随时启用或终止 OtterTune 服务。
简而言之:
首先,需要设置一些优化目标,连接到数据库系统,使用初始化的设置去运行;
然后控制器开启第一次观察周期,记录下当前设置模式下的所有系统性能度量,并返回这些结果给调优器;
调优器记录这些结果,并根据这些度量信息和系统信息计算出新的数据库配置;
最后调优器把调优结果配置传回控制器,同时可以有效评估系统提升的期望值;
用户根据评估值决定是否使用新的配置。
其中最核心的步骤就是:计算出新的数据库管理系统DBMS 的目标配置,即这里面用到的主要是机器学习。
下面详细解释一下机器学习在里面的作用。
机器学习的作用
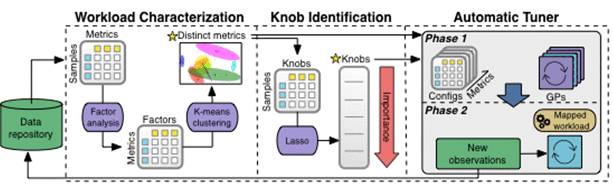
机器学习模块分为三部分:获取 Controller 观察到的工作负载参数(Workload Characterization 组件),识别并学习这些参数(Knob Identification 组件),自动管理数据库(Automatic Tuner 组件)。
下面一一来说:
Workload Characterization:OtterTune 使用 DBMS 的内部运行参数来提取数据库的工作负载特征。机器学习模块使用聚类方法来衡量这些参数的相关性,尽可能地裁剪参数量,以降低计算的复杂程度。
Knob Identification:识别并学习数据库参数,OtterTune 所用的特征选取方法是 Lasso,以找出它们的重要程度。OtterTune 据此来计算 DBMS 的目标配置,它使用一种增量方法来找出数据库的最佳配置。
Automatic Tuner:而后的工作则交由 Automatic Tuner 组件。首先,它用 Workload Characterization 组件的性能数据来确定 DBMS 的目标负载;而后,它会选择一组不同的配置进行测试。
OtterTune 的目标总是优化下一组配置,尽可能地搜集数据来提升性能,而非紧盯住目标配置不放。
结果对比
OtterTune 在论文中测试了 MySQL 和 Postgres 这两个数据库的延迟和吞吐量,结果如下:
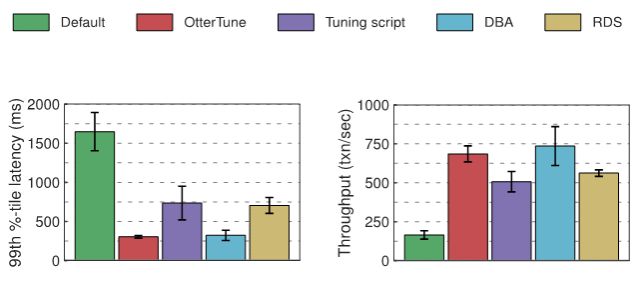
从图中可以看出,相比于 MYSQL 管理脚本,OtterTune 的延迟要低 60%,吞吐量则能提升 35%。
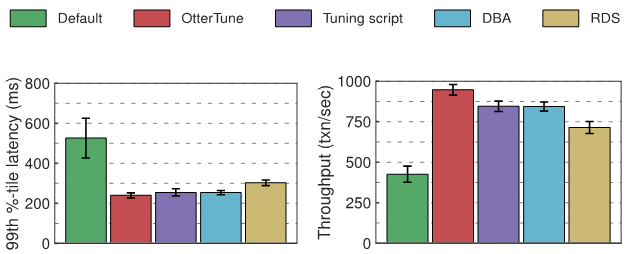
相比于 Postgres 的默认配置,OtterTune 与其他方法在延迟方面的提升大体相近;但吞吐量方面,OtterTune 比 DBA 的选择要好 12%。
总体来看,OtterTune可以在延迟和吞吐等性能指标上大幅领先传统的自动化配置脚本,并接近专业DBA的水平。
AI如何击中了这个行业的痛点?
为什么这个行业需要AI来改造?DBA的日常工作到底有哪些痛点?
让我们把目光拉近,看看这个行业到底有什么问题。
目前的数据库,主要采用专业的数据库管理员(以下称DBA)来设计数据系统的架构,调优等。
但是,由于业务系统极其复杂,且随着业务的快速迭代,需要数据库系统能跟上业务的节奏,快速响应,快速更新,这就导致调优任务也随之变得极其复杂。
DBA需要灵活掌握各项影响系统性能的控制因素,也必须对数据底层,甚至体系结构都有深入了解,才能很好地完成调优任务。
因此,真正满足优秀的DBA就非常少了,而且价格昂贵。
随着大数据行业的井喷式发展,这种人才一直都是严重供不应求。
不过,这部分原本可以享受高薪的人群,好日子貌似要走到头了。
因为,普通DBA也能借助AI抢饭碗了。
卡耐基梅隆的数据库小组整出来的这个新研究,就是要通过使用AI技术,简化了DBA对于数据库系统的调优过程,即便是普通的DBA,也能达到、甚至超过专业DBA调优系统的能力。
所以,一旦AI在此领域真正开始发挥作用,人力成本将大幅降低,工作又能快速响应,公司再也不会因为专业DBA短缺而影响业务发展了,这将是公司老板拍手称快的大好事。
原文地址
https://aws.amazon.com/cn/blogs/ai/tuning-your-dbms-automatically-with-machine-learning/?tag=vglnk-c1507-20
周末福利AI100
如果你想了解OtterTune的更多细节,可在AI科技大本营(rgznai100)微信后台回复“论文”,即可获得《Automatic Database Management System Tuning Through Large-scale Machine Learning》这篇论文。
