传说有两个乌鸦,名为Huginn和Muninn,它们被视为奥丁的左肩右臂。奥丁在黎明时送出Huginn和Muninn,它们飞到世界各地,然后在晚餐时间回来,告诉奥丁它们看到和听到的一切,奥丁则赐予它们食物作为报酬。——Huginn命名的由来
什么是Huginn?
Huginn是一个强大的自动化工具,它就像iFTTT,if 1 then 2,当事件1出现,自动完成事件2。它可以帮助你设置感应器,收集信息并完成从信息的搜集—过滤—通知这样一连串的任务。比起iFTTT,它更加强大,更加自动化,也更加难以搞定。不过,使用Huginn,你可以做到比iFTTT更加多样、更加有趣的事情,其缺点仅仅是——你需要一笔小小的精力,去学习相关知识,去配置相关程序,去在每天的实践中debug,让它成熟起来。
关于Huginn的大概介绍,有两篇文章写的很好。我承认,自己的huginn之路就是从这里开始的:不过,我并没有按照这样的思路来做,不管怎么样,首先阅读以下这些文章,总是有好处的。
第一篇是关于Huginn的大致结构,它是怎么帮助我们完成任务的:
Huginn: 烧录RSS的神器
我起初了解Huginn是因为想要为没有RSS的网站制作RSS种子。我尝试过Feed43,但是免费版本种子更新速度太慢,频率是六小时一次,通知不及时。加上我特别担心这些看不清楚盈利模式,同时在CN网络打开又特别慢的网站,怕他哪一天就完蛋了,在这个时候,我通过百度知道了Huginn。到今天为止,Huginn也还是个“小众”的东西,在百度的搜索结果,中文页面只有两个能看,并且这两个里面只有一篇教程,这篇教程限制还很多,并且一大群人在下面提issure,各种各样的安装错误。
Huginn 官方网站/WIKI
里面的安装写的是很详细,不过如果你真的照着做,出问题的概率几乎是100%。作者们假定你已经了解了Xpath,CSS,JS还有Docker、Negix、Linux基础,当我刚开始着手准备搭建的时候,我真的感到非常痛苦,各种错误出现在各种位置。不过——这显然也不是作者的问题,当我现在,想要写一个人人都能看得懂的教程的时候,才发现,这其中的工作量,何其之大,未免生出放弃的念头。
尝试部署Huginn到你的服务器
关于huginn的安装,如果自己没有服务器的,可以参看这篇文章:
- Huginn 安装教程—建立你自己的IFTTT
当然,如果英文基础尚可的话,可以参考一下官方给的安装资料:
Deploying Huginn 在服务器上部署Huginn
-
Installation guide for Ubuntu/Debian
我尝试在在EC2上这样安装,尝试了13遍,最后还是放弃了,国内的话,安装gem可能会遇到qiang的问题,所以想要在阿里云或者腾讯云上安装的,请做好心理准备
-
Run Huginn on Heroku
这个方法和上面提到的中文安装教程其实是一种思路,部署在第三方平台。
-
Deployment with Capistrano
这个也是第三方平台。
-
Using Huginn on predeployed Docker container
安装docker是最简单的方法,不过之后的配置需要docker基础,不过一般人也用不到这些高级的设置,所以还是推荐用这种方法安装,备注:阿里云好像占用了一些端口,安装docker会有问题,请自行百度更改这些设置,搜索“阿里云安装docker”就可以。
Linux安装指南(最好还是点开链接去看官方的wiki)
Install docker using the install instructions;首先要有docker环境,docker的安装参考 这里 , 非常简单。
- Start your Huginn container using `docker run -it -p 3000:3000 cantino/huginn`
- Open Huginn in the browser `http://localhost:3000`
- Log in to your Huginn instance using the username `admin` and password `password`
Guided VirtualBox installation using shell scripts and Vagrant
Deploying huginn on any server or virtualbox using chef solo and/or vagrant
Apache Huginn configuration
Backing up Huginn
Running Many Job Workers
Mini Tutorial for installing huginn on dokku
Installation Guide for Huginn on C9 or Cloud 9
Automated deployment on DigitalOcean with Fodor.xyz
安装好之后,就可以进行以下的任务了。
初见Huginn
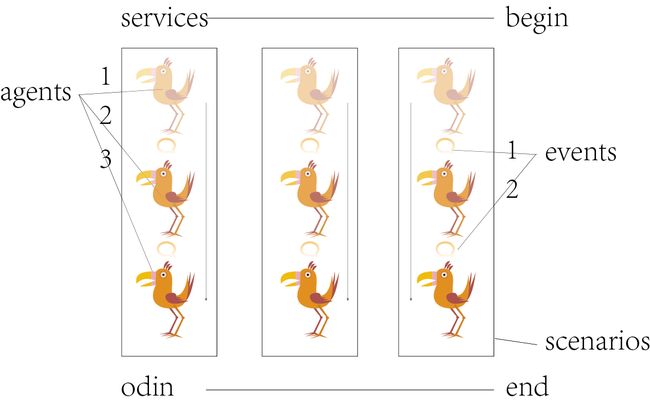
Huginn的状态栏很简单,agents指的是机器鸟,鸟儿们被分成组,执行不同的计划,这些分组称之为scenarios,同一组的鸟儿彼此间互相合作,在一个组里,第一只鸟儿的指令是主人下发的,第二只鸟儿的指令则是从第一只鸟儿执行完指令后生成的事件events中获取的。换句话说,当一只鸟儿获取到情报后,它会生成一个事件,同一组的鸟儿可以从这些事件中获取指令,开始自己的任务。Credentials和services指这些鸟儿常去的地点,其实就是别的服务程序的API接口,这些鸟儿从这里获得相关服务的信息。
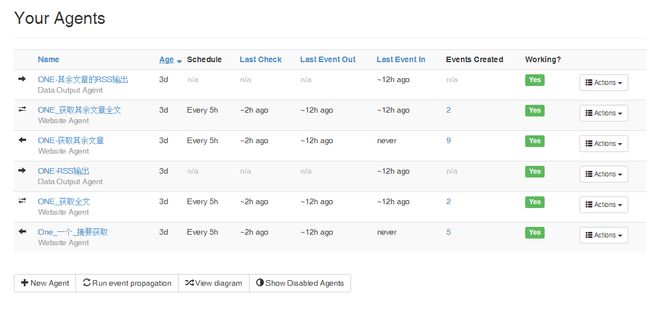
这个是我的agents。点击 view diagram可以查看相关的agent之间的关系,比如这样:
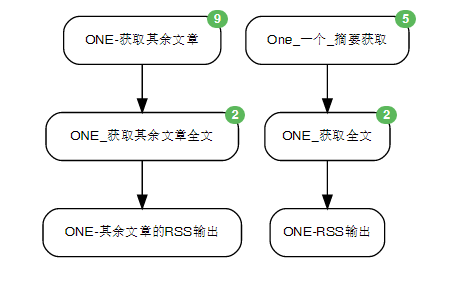
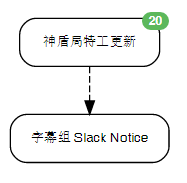
以右边为例,第一只鸟儿打开一个网页,然后获取到相关的条目url,第二只鸟儿打开这个url,然后从新的页面里提取全文。要知道,第一只鸟可能获取多个url,它获取的这些url称之为事件event,这些事件被交给第二只鸟,这只鸟比较悲催,需要一个个打开这些事件中的url,然后分别获取全文,然后再生成与之对应的自己的event。第二只鸟的event里面是获取到的url内的全文,然后这些内容被交给第三只鸟,第三只鸟把这些内容合起来,生成一个RSS种子,它自己的event,是一个网址,这个网址就是我们最终得到的RSS源。
示例一:当美剧更新的时候推送通知到我的iPhone
0、需求分析
这个任务设计两大部分,首先是美剧网站更新的检测,二是如果有更新,把生成的huginn event推送到手机端。第一部分很简单,利用website agent抓取on_charge的数据即可,第二部分则需要选择一个服务商,并且将huginn event的内容推送到这个平台。
这样的服务商比较不错的有三个:
- 邮件agent
- slack agent
- pushover agent
其中邮件推送最经济实惠,不受平台约束;pushover这个服务最方便,APP界面简洁美观,但是需要购买许可,每份许可一次性售价30人民币。slack是一个和企业微信比较像的国外交流软件,可能面临着封杀的危险,但是功能丰富,支持桌面端、Chrome插件、iOS和Android端,界面漂亮,并且可以自己选择把消息推送到哪一个群组。
因为我不太希望自己的邮箱堆满消息,所以选择了slack。
1、获取美剧信息更新
这一部分很简单,利用website agent即可。
假设我们需要获取字幕组的资源,那么我们的网址就应该选择字幕组的搜索页面。(因为字幕组的网站需要登录才能在美剧详情的页面显示资源,提供下载,如果不注册账户则不能看到资源,也就无法判断目前更新的状态,但是搜索页面提供最新更新的“字幕”信息,我们可以在第一时间得知此剧有更新。)
如果有实力的话,建议每次自动登陆自己的账户,在美剧的详情页查看是否有更新,并且获取最新更新的地址,自动发送到远程迅雷等NAS接口并自动下载,然后通过slack通知你美剧有更新并且已经下载好了,不过这样比较麻烦。
我们先从简单的开始,website agent 信息如下所示:

注意,这里选择mode:on_change即可,比较节省资源。至于url和title的css信息,分别指的是fl-info这个class下的a元素,中间的//指的是a元素包括这个class的子、孙、重孙等,如果使用一个/则表示,这个a元素则仅仅指的是class的子元素(而不能是子元素的元素)。@href表示href属性,text()表示获取其文本信息。
这个agent的网址是(2017年):
http://www.zmz2017.com/search?keyword=%E7%A5%9E%E7%9B%BE%E5%B1%80%E7%89%B9%E5%B7%A5&type=subtitle
在没更换网址之前是这个:
http://www.zimuzu.tv/search?keyword=神盾局特工&type=subtitle
2、创建过滤器
这不是一个必选项。因为,当我们获取更新后,直接可以把title的内容作为通知的信息发送到我们的手机。但是,一般情况下,当我们获取了目录之后,需要过滤掉我们不希望出现的信息,这样推送的消息会更有针对性。
创建过滤器利用的是TriggerAgent。
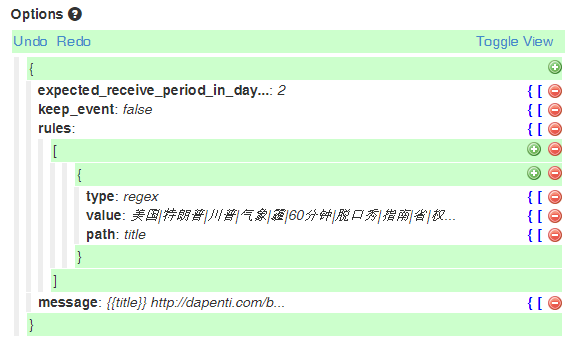
如图所示,是另外一个任务的过滤器,这里作为实例。keep event这里我选择的是false,意思是不生成过滤之后的事件,直接传递message的内容给下一个agent。如果你希望对过滤后余下的信息进一步利用,比如再次过滤之类,可以选择true以保留事件。
type指的是类型,regex指的是匹配,系统会检测上一个agent生成的内容(这里选择的是path:title,意思是把传递过来的事件中的title作为过滤的对象),和value中内容进行比较,如果这个event中包含这些value,那么生成事件,否则不生成。value中的竖分割线指的是或的意思,出现其中任何一个词即可通过过滤器,生成事件。!regix 指的是不匹配,它会检测path和value的相似程度,如果path中出现value的值,则不输出,反之,则通过过滤器并输出、生成事件。
3、通过Slack推送通知
首先,前往https://slack.com/ 注册一个Slack账户。
接着,配置incoming webhook:
前往https://my.slack.com/services/new/incoming-webhook
选择或者新建一个群组 (channel),点击继续,复制Webhook URL ,然后选择一个标签(Descriptive Label,可选) 和昵称(Customize Name),自定义通知的图标,保存设置。
你的 webhook URL 类似这个样子: https://hooks.slack.com/services/some/random/characters
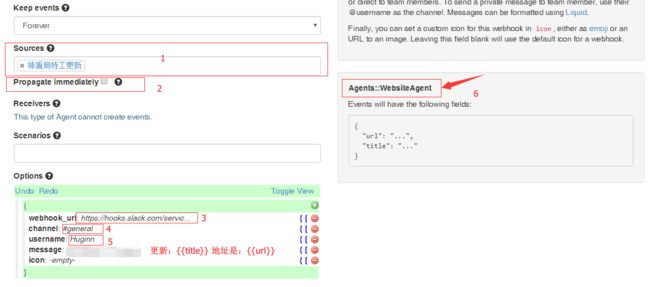
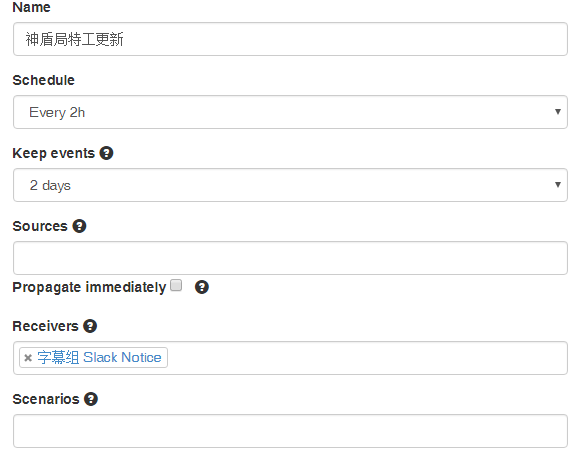
注意,Sources来源(1处)选择上一个Agent,这里用的是我们website agent中的神盾局特工更新,当然你也可以用TriggerAgent作为通知的来源。
Propagate immediately(2处)的意思是当上一个Agent生成事件后立马唤醒此Slack Agent。一般,这样会造成较高的CPU使用,我选择不理会这个选项,默认情况下,Huginn会每分钟检查一下你的Agent,看有没有事件需要处理,所以不选的话,顶多1分钟后再推送消息,对我的差别不大。
webhook_url(3处)选择刚才我们生成的Webhook URL,channel(4处)选择我们之前设置的群组(Chanel),username指的是昵称,message指的是我们需要推送的消息。icon建议留空,这样它会默认使用你在Slack设置界面中指定的图标。
如果我们选择了“神盾局特工”作为此Slack Agent的来源(Source),那么,你在右面会看到这样一个东西(6处),这里指的是Slack Agent来源事件的Agent,即神盾局特工更新这个Website agent 。下面显示了此website agent传递过来的参数,我们看到有一个url,有一个title,在message栏内填入红色字部分,那么通知将会变成这个样子:
更新:[美剧字幕]《神盾局特工 第四季 第十集【精校】》Marvel's Agents of S.H.I.E.L.D 地址是:/subtitle/51114
其中被双括号包裹的东西是上一个agent中传递过来的事件对应部分的内容,其余部分我们可以自己填写。比如,默认生成的url是/subtitle/51114,我们需要在前面加上http://www.zmz2017.com/,即:
这样一来,我们收到的通知就变成下面这个样子了。
更新:[美剧字幕]《神盾局特工 第四季 第十集【精校】》Marvel's Agents of S.H.I.E.L.D 地址是:http://www.zmz2017.com/subtitle/51114
看一下我们的流程,是这个样子的:
示例二:为没有RSS的网站创建订阅
下面给出我为了获取ONE的RSS使用的代码,注意,真正想要了解它的使用方法,仅仅看懂以下代码是没什么作用的,每个类型的agent都给出了详细的使用指南,就在你新建agent的右侧,虽然它是英文,请务必读懂,这非常重要。
1、摘要获取
单击任务栏新建一个agent,这里选择website agent,之后按照要求填入相关信息。注意:agent的名称是必填项。当你新建一个agent之后,从这个agent的菜单中选择“show”,你就可以见到如下的agent详细信息。
Type: Website Agent ;这是一类获取公开网页信息的agent
Schedule: Every 5h ;每5小时运行一次,对于RSS来说足够了
Last checked: ~2h ago
Keep events: 5 days; 保留这个agent生成的事件的时间
Last event created: ~17h ago ;最后事件的创建时间
Last received event: never
Events created: 6 ;创建的事件数目
Event sources: None
Propagate immediately: No
Event receivers: ONE_获取全文
本agent生成的事件传递给谁(因为这个agent是获取目录,当然下一步是获取全文,在新建website
agent的时候你不用填,到下一个生成全文的agent填写event接收来源就可以了,website
agent会自动把事件接收者指向生成全文的agent)
Working: Yes; 是否工作
Options: ;这里是填入的代码
{
"expected_update_period_in_days": "2", ;不用管
"url": "http://wufazhuce.com/", ;打开哪个网站
"type": "html", ;网页类型,一般是html
"mode": "on_change",
有三种可选,这里指的是把网页和上一次生成的事件比较,如果有变化则输出事件,如果和上次输出的一样则不输出,避免生成重复的事件。
"extract": {
"url": {
"css": ".one-articulo-titulo/a", 这里是xpath代码,前往w3c school自行学习,在xml的目录下。
"value": "@href"
@XXX表示属性,这里指的是“a”这个链接的href属性,其实就是指网址。
},
"title": {
"css": ".one-articulo-titulo/a",
"value": "normalize-space()" 这里什么意思,请查看xpath函数部分。
}
}
}
2、获取全文
Details
Type: Website Agent
Schedule: Every 5h
Last checked: ~2h ago
Keep events: 2 days
Last event created: ~17h ago
Last received event: ~17h ago
Events created: 2
Event sources: One_一个_摘要获取
Propagate immediately: Yes
Event receivers: ONE-RSS输出
Working: Yes
Options:
{
"expected_update_period_in_days": "2",
"url": "{{url}}",
"type": "html",
"mode": "merge",
"extract": {
"author": {
"css": ".articulo-autor",
"value": "substring(normalize-space(),4)"
},
"title": {
"css": ".articulo-titulo",
.XXX表示class属性,一般不写成XX[@class=’XXX’],而写成 “.XXX”
"value": "normalize-space()"
},
"hovertext": {
"css": ".articulo-contenido",
"value": "."
}
}
}
3、RSS输出
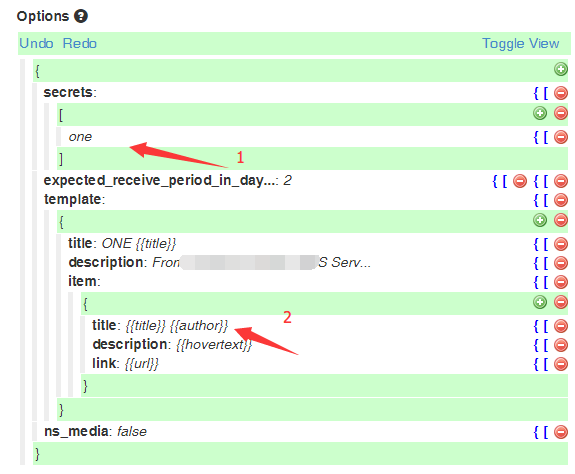
指的是你将要生成的RSS订阅网址的名称,它会显示在地址栏里,请自行填写(一般写这个项目的昵称就好)。
比如,上一步我们生成的事件内容是:
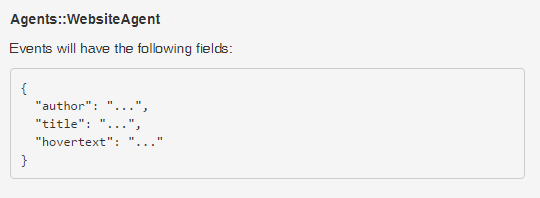
则这里的
title值,因为可能有很多同一agent生成的不同事件,所以这样表示,可以把所有上一个agent生成的事件结合在一起输出。
以上。
本文首发于blog.mazhangjing.com ; blog.mazj.me. © 版权所有,转载请联系作者:[email protected]