实现后的结果
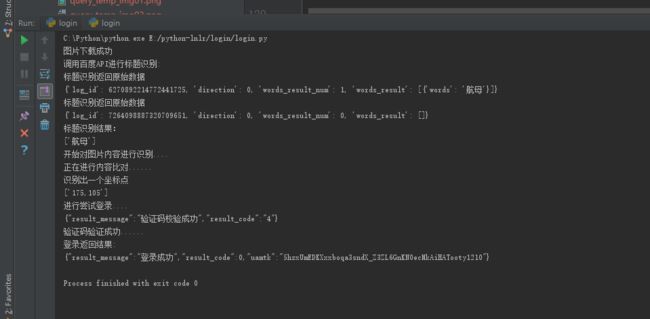
可以看到使用我本人的用户名和密码登录成功了,验证码也验证成功了。
前因
前段时间看到了py,就准备学习学习,但是学习的是py3,网络上很多练手的项目都是py2写的,很多在3是跑不起来,所以就自己搞了搞py3的12306自动登录,在我前面的文章还写了查询某天的车票情况。
为什么要写12306呢?
首先是前面项目查票的前缀,其次就是在网络上看到了某个学院有个老师讲12306,但是是收费课程,当时我问他,能不能提示一下自动登录所使用到的技术,但是他回答我他要讲一个月才能讲完,然后就没有下文了。这个回答明显的就是敷衍。但是我并没有生气,对于处在互联网时代的我们,并没有什么东西不能自己学习的(夸张了),但是确实是很多资源都可以找到。在这里吐槽一句,在国内的资源问题真的很严重,很多人都是不愿意教别人。不知道各位有没有遇到这种情况。
我所经历的事儿
在动手做这个项目的时候,我了解人工智能,机器学习,深度学习(deep learning),但是由于时间,个人能力的问题,目前还不打算基础深度学习和机器学习。但是我所做的这个项目又必须用到深度学习的知识,所以我选择了google treeseract 和百度的图像识别技术来帮助我完成这个项目。
第一次标题识别使用的是google的开源项目,但是效率很低很低,可能是中文支持问题,还有就是12306字体问题。
第二次使用百度文字识别技术,效率不错,是不是给李彦宏打广告了。
然后就是识别八张小图片的问题,该问题受到了fuck12306项目的帮助,在调用百度识图接口上。目前百度的接口上传文件应该是有变化。
在开发中最郁闷的就是,正在尝试识别登录,在有一天下午我突然发现,mmp以前是只有一个类型(只有一个类型的选择),现在穿插了两种出来,有可能订书机,后面在跟一个其他的。这就让我郁闷的很,说明我的代码是需要更改来提高比对效率。说改就改,撸起袖子就开干。
代码那点事儿
现在聊聊代码那点事儿,程序猿不就是一个卖字母为生的人么?至少我就是这样的,分享一个我遇到的事情,有个公司周六叫员工去帮忙搬一下桌子,改变一个办公室布局,这是一个小事情,帮个忙而已。但是那个头说的是,周六去公司搬桌子,然后下午公司聚餐,没去搬桌子的就没有,她好定位子,这都让人忍了,最后还要请假,请假,惊不惊喜,意不意外。毁三观的公司。
好吧,我多嘴了,开始我们简单的代码讲解。
库
- request http请求
- pillow 图形处理
- baidu-aip 百度文字识别
由着三个库搞定,还有py的库就不说了。自带的技能。
开发思路
- 下载验证码图片
- 切图,识别标题文字
- 切图,分别识别八张小图片
3.1 识别内容,没有最佳内容再次识别相似内容,提高对比度(自己发明的) - 进行内容比对,找到坐标点,了解过这种形式的验证码的都知道这种是坐标验证码,不明白的童鞋自行百度。
- 尝试登陆
- 搞定
卖字母咯
语调请读成安琪拉的的语调,因为我最近在玩农药。
对了,下面的代码都是部分代码,完整代码在文尾github上。
下载验证码
def get_picture(get_pic_url, img_code):
response = req.get(get_pic_url, headers=headers, verify=False)
response.encoding = 'utf-8'
if response.status_code == 200:
with open(img_code, "wb") as f:
f.write(response.content)
print("图片下载成功")
return True
else:
print("图片下载失败,正在重试....")
get_picture(get_pic_url, img_code)
这就把验证码图片保存起来了。
识别标题
识别标题得说一下百度的文字识别api,这是一个百度应用吧,我上一篇专门讲了这个,传送门,怎么申请key,使用等等,代码也托管了的。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from aip import AipOcr
__author__ = "雷洪飞"
"""
利用百度图像识别api做文字识别,目的是为了做12306的图片校验。
"""
# 定义常量
APP_ID = '10508877'
API_KEY = 'kpFtUgtOaxmKkNa2C0x7Q7mN'
SECRET_KEY = 'TTX5ginIXZyfGtdH8UTO4kF5M41lf3fb '
# 初始化AipFace对象
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
# 定义参数变量
options = {
'detect_direction': 'true',
'language_type': 'CHN_ENG',
}
class BaiDu(object):
# 获取图片
def get_file_content(self, file_path):
"""获取图片数据"""
with open(file_path, 'rb') as fp:
return fp.read()
def get_result(self, image_url):
"""
识别结构
:return: 返回识别结果
"""
image = self.get_file_content(image_url)
return client.basicGeneral(image, options)
if __name__ == "__main__":
# 获取图片
baidu = BaiDu()
# 得到识别结果
result = baidu.get_result("../images/code.png")
# 输出识别结果
print(result['words_result'][0]['words'])
完整代码都在这里,我将他封装成了对象,方面各个模块的调用。
识别八张图片内容
这个算是比较大的工程了,需要切图,识别,提取识别内容,保存坐标点,返回内容...
文字走一走:
使用百度图片搜索功能进行识别,百度有一个上传图片进行百度的功能,google也有的。没用过的赶紧去试试,这就是用到了深度学习的知识,神经网络xxx,噼里啪啦一大堆。关注人工智能的童鞋就知道Ng(吴恩达大神)以前就是在百度。
百度的识别图片是分为两步走:
-
需要上传图片或者使用图片uri进行识别的,所以就需要上传,我下载了百度的源代码分析。最后也没上传成功。py不行。所以就找了fuck12306的上传方式来进行上传的。百度现在使用https,http两个不同的上传地址,最后都是返回一个包含图片地址的json格式。我们就需要图片地址,大小等。。
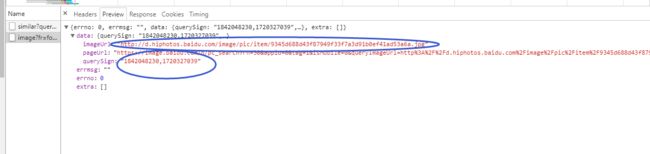 百度上传返回结果
百度上传返回结果 带上上传了图片的地址,大小等信息进行深度学习。然后染回结果。
https://image.baidu.com/n/pc_search?rn=30&appid=0&tag=1&isMobile=0&queryImageUrl=http%3A%2F%2Fc.hiphotos.baidu.com%2Fimage%2Fpic%2Fitem%2Fa8014c086e061d95802389b570f40ad163d9cad2.jpg&querySign=1842048230%2C1720327039&uptype=upload_pc&fromProduct=&productBackUrl=&uptype=upload
刚才上传地地址,大小等信息就被编码到url地址中了。
这个接口返回的结果就是我们的所识别图片的结果,是以网页的形式返回。
但是会出现图片搜索不到东西的情况下,那么百度javascript将会再次发送一个请求,查询相似结果。
https://image.baidu.com/n/similar?queryImageUrl=http%3A%2F%2Fc.hiphotos.baidu.com%2Fimage%2Fpic%2Fitem%2Fa8014c086e061d95802389b570f40ad163d9cad2.jpg&querySign=1842048230,1720327039&word=&querytype=0&t=1513414228966&rn=60&sort=&fr=pc&pn=
这个就是返回的相似图片的接口,返回的是json格式。
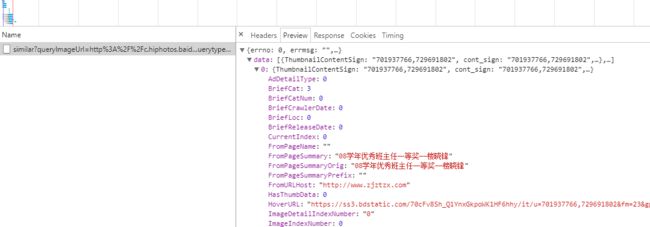 相似图片接口内容.png
相似图片接口内容.png
篇幅有限,截图就小点了。
我会获取其中的一个title属性。那就是我们鼠标放到图片上面显示的文字。用来比对验证码标题问题的。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import requests
import urllib3
from PIL import Image, ImageFilter, ImageEnhance
from bs4 import BeautifulSoup
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
__author__ = "雷洪飞"
class RecoginitionContainer(object):
def __init__(self, base_img_url):
self.base_img_url = base_img_url
url = "http://image.baidu.com/pictureup/uploadshitu?fr=flash&fm=index&pos=upload"
headers = {
"User-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"}
def __upload_pic__(slef, img, filex, url):
"""上传图片,得到图片地址"""
img.save(slef.base_img_url + "/query_temp_img" + filex + ".png")
raw = open(slef.base_img_url + "/query_temp_img" + filex + ".png", 'rb').read()
files = {
'fileheight': "0",
'newfilesize': str(len(raw)),
'compresstime': "0",
'Filename': "image.png",
'filewidth': "0",
'filesize': str(len(raw)),
'filetype': 'image/png',
'Upload': "Submit Query",
'filedata': ("image.png", raw)
}
resp = requests.post(url, files=files, headers=slef.headers, verify=False)
redirect_url = "http://image.baidu.com" + resp.text
return redirect_url
def __get_query_content__(slef, query_url):
response = requests.get(query_url, headers=slef.headers, verify=False)
li = list()
if response.status_code == requests.codes.ok:
bs = BeautifulSoup(response.text, "html.parser")
re = bs.find_all("a", class_="guess-info-word-link guess-info-word-highlight")
for link in re:
li.append(link.get_text())
# print(link.get_text())
# 再次获取图中动物可能是
te = bs.find_all("ul", class_="shituplant-tag")
for l in te:
# 得到有可能包含的数据
for child in l.children:
try:
li.append(child.get_text())
except:
pass
# 再次获取相似图片,其中在有一个图片描述,进行获取就知道,重新掉了一个接口
# pc_search 替换成similar在搜索一次
if len(li) == 0:
once_url = query_url.replace("pc_search", "similar")
resp = requests.get(once_url, headers=slef.headers, verify=False)
js = resp.json()
#print("查找相似图片")
for fromTitle in js['data']:
li.append(fromTitle['fromPageTitle'])
return "|".join(x for x in li)
def get_pic_content(slef, img_url):
box = (0, 41, 295, 186)
Image.open(img_url).crop(box).save(img_url)
def get_text(slef, img_url):
li = list()
ImageEnhance.Contrast(Image.open(img_url)).enhance(1.3).save(img_url)
imgs = Image.open(img_url)
imgs.filter(ImageFilter.BLUR).filter(ImageFilter.MaxFilter(23))
imgs.convert('L')
x_width, y_heigth = imgs.size
# 得到每一张图片应该的大小
width = x_width / 4
heigth = y_heigth / 2
for x_ in range(0, 2):
for y_ in range(0, 4):
left = y_ * width
right = (y_ + 1) * width
# 得到图片位置
index = (x_ * 4) + y_
if x_ == 0:
box = (left, x_ * heigth + 21, right, (x_ + 1) * heigth + 21)
else:
box = (y_ * width, x_ * heigth + 21, (y_ + 1) * width, (x_ + 1) * heigth)
# 得到查询地址
query_url = slef.__upload_pic__(imgs.crop(box), str(x_) + str(y_), slef.url)
# 进行查询,返回结果
text = slef.__get_query_content__(query_url)
# 计算坐标
# 由于12306官方验证码是验证正确验证码的坐标范围,我们取每个验证码中点的坐标(大约值)
yanSol = ['35,35', '105,35', '175,35', '245,35', '35,105', '105,105', '175,105', '245,105']
# 将坐标保存
li.append({yanSol[index]: text})
# print("识别结果:")
# print(text)
return li
if __name__ == "__main__":
img_url = "../images/code.png"
c = RecoginitionContainer("../images")
c.get_text(img_url)
阅读代码是小心我所使用的的切图位置,是使用两次循环得到的。不明白的多看下就明白了。返回的坐标点,是进行索引得到的。不明白的评论或仔细阅读,都是无难度的代码哦。
到了内容比对咯
思路:
内容比对三步走
第一步:整体比对
第二步:单个字比对
第三步:去掉重复坐标点(这步是放在第二步的)
第一步:从八张小图片处可以获取到图片识别的结果,可能从百度文字识别api接口得到验证码标题。通过循环我们就可以比对了。
第二步:在小图片或者验证码标题中我们可能识别的结果是不正确的,那么我们第一步就算是半费了,注意是半费。那么我们就增大准确性,引入了第二步,单个字的进行比对。这样比对出来坐标点就肯定很多了。注意重复,第三步该上场了。
第三步:通过以上的比对,我们可能得到较多的坐标点,但是其中可能包含重复,我们需要去掉。
def login_get_data(url, image_code, image_title):
# 删除images所有文件
del_file("../images")
get_picture(url, image_code)
# 由于验证码难度升级,成了两个东西,比如:本子,订书机这种形式,那么
# 我需要进行两次分割,并进行循环判断才可以
point = list()
result = get_title_context(image_code, image_title)
if len(result) == 0:
print("识别标题失败,正在重新尝试....")
login_get_data(url, image_code, image_title)
else:
print("标题识别结果:")
print(result)
# 对图片内容进行识别
print("开始对图片内容进行识别....")
c = RecoginitionContainer("../images")
# 得到了坐标和识别出来的内容,或者相似图片的标题
lists = c.get_text(image_code)
# 进行内容比对
print("正在进行内容比对......")
for li in lists:
# 得到每一个坐标点和内容
# 循环标题,进行比对
for title_text in result:
for po, value in li.items():
if title_text in value:
# 判断当前坐标点是否存在
if po not in point:
print("识别出一个坐标点")
point.append(po)
# 再次对标题进行分割
for tx in title_text:
for po, value in li.items():
if tx in value:
# 判断当前坐标点是否存在
if po not in point:
print("识别出一个坐标点")
point.append(po)
# 打印出图片的内容
print(point)
return point
该休息了
到了这个位置为止,所有的工作都基本是做完了的。
就差验证结果了。在12306官网找到验证码校验接口,然后封装数据进行提交校验验证码。
接口:https://kyfw.12306.cn/passport/captcha/captcha-check
def check_captcha(point):
# 验证码地址
check_url = "https://kyfw.12306.cn/passport/captcha/captcha-check"
data = {
"answer": ",".join(point),
"login_site": "E",
"rand": "sjrand"
}
# print(data)
response = req.post(check_url, data=data,
headers=headers, verify=False)
print(response.text)
if response.status_code != 200:
return False
code = response.json()['result_code']
# 取出验证结果,4:成功 5:验证失败 7:过期,8:我猜是不是同一个session,非法请求。
if str(code) == '4':
return True
else:
return False
注意:
在这里来了一定要注意,我们需要是同一个session,不然将返回8,一定要注意啊
这样就校验了,不成功继续请求验证码再次识别,校验,直到返回成功4为止。
在来一剂猛药--登录
这个就是非常简单简单简单.....的事情了。封装数据,请求接口,处理返回数据搞定的事情,直接贴代码。
loginUrl = "https://kyfw.12306.cn/passport/web/login"
data = {
'username': 'your account',
'password': "yours password",
'appid': 'otn'
}
result = req.post(url=loginUrl, data=data, headers=headers, verify=False)
print("登录返回结果:")
print(result.text)
看看自己的成果
从这张图片上看到,我们登录成功了的。
这次是运气好,一次就识别成功了。有的时候很多次都不会成功。识别效率低下。期待以后的deep learning技术更好。
总结下自己
需要完善异常信息。
学无止境
github包含了12306的所有文章代码
我发布了文章之后,又要忍不住先给自己来一颗小红心。你们来么???