这里的“堆”与操作系统或运行环境中的“内存堆”(Memory heap)没有任何直接联系。
一,堆的定义及性质
实现优先队列最高效的方式,就是借助堆(Heap)结构。
前面文章说到的基于有序列表的优先队列之所以效率都不高,原因在于对优先队列定义的理解过于机械,任何时刻都分毫不差地保存了整个集合的全序关系,也就是说,所有元素始终都是按照全序排列的。只要稍微深入地对优先队列的定义做一推敲就不难发现,实际上,只要能够随时给出全局的最小条目即可,至于次小者、第三个最小者以及第i 个最小者,我们并不关心。
堆结构正是充分利用了优先队列的这一特点,在任何时候只保存了整个集合的一个偏序关系,从而这一结构在时间复杂度方面有了实质性的改进。
堆结构
由若干条目组成的一个堆H,就是满足以下两条性质的一棵二叉树:
结构性:H 中各元素的联结关系应符合二叉树的结构要求(其根节点称作堆顶);
堆序性:就其关键码而言,除堆顶外的任何条目都不小于其父亲。
在上下文不致发生歧义时,我们将直接用节点来指代其中存放的条目。

下面这则定理,指出了堆结构最重要的一个特性:
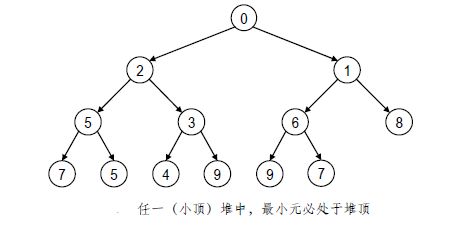
H 中的最小条目必处于堆顶。
当然,也可以对称地定义堆序性:除堆顶外的任何条目都不大于其父亲。
相应地,在如此定义的堆中,最大条目必处于堆顶。因此,按前一种形式定义的堆称作“小顶堆”,后者则称为“大顶堆”。小顶堆和大顶堆是相对的,甚至可以相互转换。
我们注意到,节点之间的大小关系完全取决于所使用的比较器。只要将比较器的compare()方法对称地改写,就可以得到一个新的比较器,而按照新的比较器,无需对原有结构做任何更动,原先的小(大)顶堆即可转化为大(小)顶堆。
完全性
为了降低堆的高度以提高操作的效率,我们对其增加一项要求:
- 完全性:堆必须是一棵完全二叉树
在具有这一附加性质的堆中,除堆顶外还有一个特殊的节点⎯⎯末节点(Last node),亦即在层次遍历该堆时最后接受访问的那个节点。以如上图所示的堆为例,其末节点为“1970, J. Wilkinson”。
二,主要操作分析
利用堆结构表示的优先队列,包括以下要素:
堆H,即一棵完全二叉树,其中各节点存有条目并根据其关键码满足堆序性
比较器C,各关键码之间的全序关系

getSize()操作和getMin()操作也可以在O(1)时间内完成,现在我们来讨论如何实现堆 H 的插入操作insert(key, e)。
我们可以通过完全二叉树的addLast()方法,直接将条目v = (key, e)作为最末尾的节点插入H中。
但是除非H 原先是空的,否则新节点v 必然有个父亲。此时,就v 与其父亲(记作u)关键码的大小关系而言,有两种可能。
1,若key(v) ≥ key(u),则v 的引入没有破坏H 的堆序性,节点插入操作顺利完成。
2,若key(v) < key(u),则在此局部的堆序性不再满足。
在这种情况下,如何恢复这一局部的堆序性呢?
最简单而直接的办法,就是交换v和u,交换之后,v和u之间的堆序性就
得到了恢复。但是,随着v向上移动一层,它与新的父节点之间依然可能不满足堆序性。
为了解决这一问题,我们可以再次采用上面的办法,将v与新的父节点交换,我们注意到,每经过一次交换,新插入的节点v就会向上移动一层。尽管这种情况有可能会持续发生,但v的高度不可能超过堆的高度h,因此在经过至多h交换后,全剧的堆序性最终必将恢复。
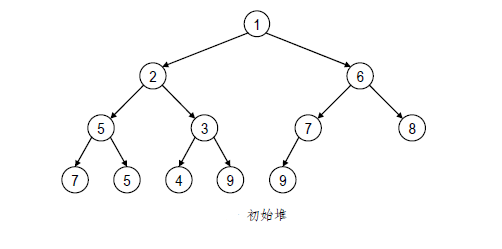

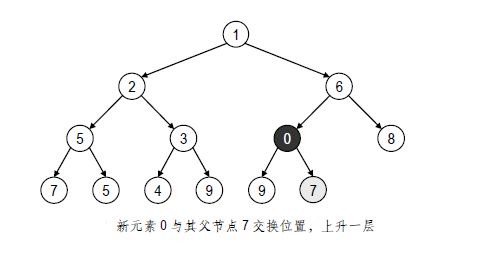


新插入节点通过与父亲交换不断向上移动的这一过程,称作上滤(Percolating up)
下面再来讨论 delMin()方法的实现。
- 1,直接取出堆顶

- 2,将末元素7 移至堆顶
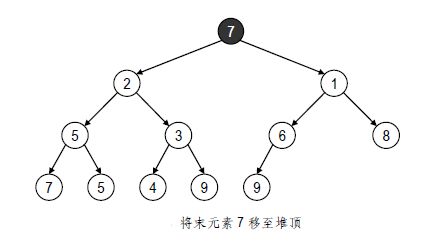
- 3,元素7 与其孩子1 交换位置

- 4,元素7 与其孩子6 交换位置,最终完成删除操作
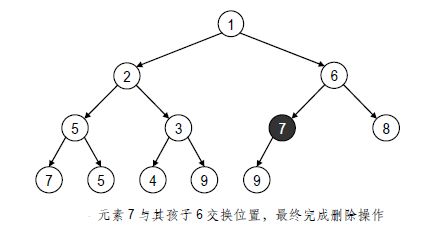
在这一过程中,v 的高度逐层下降,因此我们称之为下滤(Percolating down)。
三,具体实现
利用堆实现优先队列:
package dsa.PriorityQueue;
import dsa.BinTree.BinTreePosition;
import dsa.BinTree.ComplBinTree;
import dsa.BinTree.ComplBinTreeNode_Rank;
import dsa.BinTree.ComplBinTree_Vector;
import dsa.Sequence.Sequence;
/*
* 利用堆实现优先队列
*/
public class PQueue_Heap implements PQueue {
private ComplBinTree H;// 完全二叉树形式的堆
private Comparator comp;// 比较器
// 构造方法
public PQueue_Heap() {
this(new ComparatorDefault(), null);
}
// 构造方法:默认的空优先队列
public PQueue_Heap(Comparator c) {
this(c, null);
}
// 构造方法:根据某一序列直接批量式构造堆算法,S中元素都是形如(key, value)的条目
public PQueue_Heap(Sequence S) {
this(new ComparatorDefault(), S);
}
// 构造方法:根据某一序列直接批量式构造堆算法,s中元素都是形如(key, value)的条目
public PQueue_Heap(Comparator c, Sequence s) {
comp = c;
H = new ComplBinTree_Vector(s);
if (!H.isEmpty()) {
for (int i = H.getSize() / 2 - 1; i >= 0; i--)// 自底而上
percolateDown(H.posOfNode(i));// 逐节点进行下滤
}
}
/*-------- PQueue接口中定义的方法 --------*/
// 统计优先队列的规模
public int getSize() {
return H.getSize();
}
// 判断优先队列是否为空
public boolean isEmpty() {
return H.isEmpty();
}
// 若Q非空,则返回其中的最小条目(并不删除);否则,报错
public Entry getMin() throws ExceptionPQueueEmpty {
if (isEmpty())
throw new ExceptionPQueueEmpty("意外:优先队列为空");
return (Entry) H.getRoot().getElem();
}
// 将对象obj与关键码k合成一个条目,将其插入Q中,并返回该条目
public Entry insert(Object key, Object obj) throws ExceptionKeyInvalid {
checkKey(key);
Entry entry = new EntryDefault(key, obj);
percolateUp(H.addLast(entry));
return entry;
}
// 若Q非空,则从其中摘除关键码最小的条目,并返回该条目;否则,报错
public Entry delMin() throws ExceptionPQueueEmpty {
if (isEmpty())
throw new ExceptionPQueueEmpty("意外:优先队列为空");
Entry min = (Entry) H.getRoot().getElem();// 保留堆顶
if (1 == getSize())// 若只剩下最后一个条目
H.delLast();// 直接摘除之
else {// 否则
H.getRoot().setElem(((ComplBinTreeNode_Rank) H.delLast()).getElem());
// 取出最后一个条目,植入堆顶
percolateDown(H.getRoot());
}
return min;// 返回原堆顶
}
/*-------- 辅助方法 --------*/
// 检查关键码的可比较性
protected void checkKey(Object key) throws ExceptionKeyInvalid {
try {
comp.compare(key, key);
} catch (Exception e) {
throw new ExceptionKeyInvalid("无法比较关键码");
}
}
// 返回节点v(中所存条目)的关键码
protected Object key(BinTreePosition v) {
return ((Entry) (v.getElem())).getKey();
}
/*-------- 算法方法 --------*/
// 交换父子节点(中所存放的内容)
protected void swapParentChild(BinTreePosition u, BinTreePosition v) {
Object temp = u.getElem();
u.setElem(v.getElem());
v.setElem(temp);
}
// 上滤算法
protected void percolateUp(BinTreePosition v) {
BinTreePosition root = H.getRoot();// 记录根节点
while (v != H.getRoot()) {// 不断地
BinTreePosition p = v.getParent();// 取当前节点的父亲
if (0 >= comp.compare(key(p), key(v)))
break;// 除非父亲比孩子小
swapParentChild(p, v);// 否则,交换父子次序
v = p;// 继续考察新的父节点(即原先的孩子)
}
}
// 下滤算法
protected void percolateDown(BinTreePosition v) {
while (v.hasLChild()) {// 直到v成为叶子
BinTreePosition smallerChild = v.getLChild();// 首先假设左孩子的(关键码)更小
if (v.hasRChild() && 0 < comp.compare(key(v.getLChild()), key(v.getRChild())))
smallerChild = v.getRChild();// 若右孩子存在且更小,则将右孩子作为进一步比较的对象
if (0 <= comp.compare(key(smallerChild), key(v)))
break;// 若两个孩子都不比v更小,
swapParentChild(v, smallerChild);// 否则,将其与更小的孩子交换
v = smallerChild;// 并继续考察这个孩子
}
}
}