Hive是构建在Hadoop HDFS上得一个数据仓库
数据仓库是一个面向主题的、集成的、不可更新的、随时间不变化的数据集合,它用于支持企业或组织的决策分析处理
搭建数据仓库的时候最基本的两个模型:星型模型和雪花模型(雪花是在星型的基础上发展起来的)
OLTP应用(比如银行转账)、OLAP应用(比如商品推荐系统)
Hive是建立在Hadoop HDFS上的数据仓库
Hive可以用来进行数据抽取转换加载(ETL)
Hive定义了简单的类似SQL的查询语言,称为HQL,它允许熟悉SQL的用户查询数据
Hive允许熟悉MapReduce开发者开发自定义的mapper和reducer来处理内建的maprper和reducer无法完成的复杂的分析工作
Hive是SQL(其实是HQL)解析引擎,他将SQL语句转移成M/R Job,然后在Hadoop执行
Hive的表其实就是HDFS的目录/文件
-
Hive的元数据
Hive将元数据存储在数据库中(metastore),支持mysql/derby等数据库
Hive中的元数据包括表的名字、表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等

-
HQL的执行过程:
解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划(Plan)的生成。生成的查询计划存储在HDFS中,并在随后又MapReduce调用执行


下载apache已发布版(release)安装包网站:http://archive.apache.org/
-
Hive的安装模式:
- 嵌入模式:
元数据信息被存储在Hive自带的Derby数据库中
只允许创建一个链接
多用于Demo - 本地模式:
元数据信息被存储在MySql数据库中
MySql数据库与Hive允许在同一台物理机器上
多用于开发和测试 - 远程模式:
Hive和MySql运行在不同机器(操作系统)上
- 嵌入模式:
-
Hive的启动方式:
CLI(命令行)方式:
/bin/hive或者hvie --service cli
常用CLI命令:
Ctrl+L或者!clear 清屏
show tables; //show tables --查看表列表;
show functions;
desc 表名;
dfs -ls 目录 //查看hdfs上得文件
!命令 //执行linux操作系统命令
select *** from *** //执行hql语句
select tname from test1;//会转换为mapreduce作业
source SQL文件 //执行sql脚本
注:
hive -S表示静默模式,不会打印mapreduce作业等的日志信息
hive -e可以不进入命令行,直接在操作系统提示符下执行hive语句,比如:hive -S -e 'show tables';-
Web界面方式
端口号:9999
启动方式:hive --service hwi
通过浏览器访问:http://ip:9999/hwi
解压源码包hive-1.1.0-cdh5.7.0-src.tar.gz进入到hive-1.1.0-cdh5.7.0-src\hive-1.1.0-cdh5.7.0\hwi中使用
jar cvfM0 hive-hwi-1.1.0.war -C web/ . 命令打包得到hive-hwi-1.1.0.war
把war包拷贝到hive的lib目录下
修改hive-site.xml添加如下配置:hive.hwi.listen.host 0.0.0.0 This is the host address the Hive Web Interface will listen on hive.hwi.listen.port 9999 This is the port the Hive Web Interface will listen on hive.hwi.war.file lib/hive-hwi- .war This is the WAR file with the jsp content for Hive Web Interface 拷贝jdk的tools.jar拷贝到hive的lib目录下
启动 hive --service hwi 远程服务启动方式
端口号:10000
启动方式:hive --service hiveserver
(以JDBC或ODBC的程序登录到hive中操作数据时,必须选用远程服务启动方式)
-
Hive的数据类型:
- 基本数据类型:
tinyint/smallint/int/bigint:整数类型
float/double:浮点数类型
boolean:布尔类型
string:字符串类型
create table person(pid int,pname string,married boolean,salary double);
desc person;
create table test1(vname varchar(20),cname char(20));
desc test1; - 复杂数据类型:
Array:数组类型,由一系列想同数据类型的元素组成
Map:集合类型,包含key-value键值对,可以通过key来访问元素
Struct:结构类型,可以包含不同数据类型的元素。这些元素可以通过“点语法”的方式来得到所需要的元素
create table student(sid int,sname string,grade array);
插入数据时应该是这样的数据:{1,Tom,[80,90,75]}
desc student;
create table student2(sid int,sname string,grade map
{1,'Tom',<"语文",88>}
desc student2;
create table student3(sid int,sname string,grades array
desc student3;
{1,'Tom',[<'语文',99>,<'数学',88>]}
create table student4(sid int,info struct
{1,{'Tom',10,'男'}} - 时间类型:
Date:从Hive0.12.0开始支持
Timestamp:从Hive0.8.0开始支持
使用select unix_timestamp();查询当前系统时间的时间戳(偏移量)
- 基本数据类型:
-
Hive的数据存储:
基于HDFS(默认对应于/user/hive/warehouse/下的文件)
没有专门的数据存储格式(可以是csv/txt等等)
存储结构主要包括:数据库、文件、表、视图
可以直接加载文本文件(.txt文件等)
创建表时,指定Hive数据的列分隔符于行分隔符
其中:表包括Table(内部表)、Partition(分区表)、External Table(外部表)、Bucket Table(桶表)内部表:
与数据库中的Table在概念上类似
每个Table在Hive中都有一个相应的目录存储数据
所有Table数据(不包括External Table)都保存在这个目录中
删除表时,元数据与数据都会被删除
create table t1(tid int,tname string,age int);//默认会放在/user/hive/warehouse/下边
create table t2(tid int,tname string,age int) location '/mytable/hive/t2';//手动指定位置到/mytable/hive下边
create table t3(tid int ,tname string,age int) row format delimited fields terminated by ',';//列与列的分隔符用逗号,就可以导入csv文件了
create table t4 as select * from sample_data;
create table t5 row format delimited fields terminated by ',' as select * from sample_data;
alter table t1 add colums(english int);
drop table t1;-
分区表(Partition)
Partition 对应于数据库的Partition列的密集索引
在Hive中,表中的一个Partition对应于表下的一个目录,所有的Partition的数据都存储在对应的目录中.
创建一张基于性别的分区表:
create table partition_table (sid int,sname string) partitioned by (gender string) row format delimited fields terminated by ',';
insert into table partition_table partition(gender='M') select sid,sname from sample_data where gender='M';
insert into table partition_table partition(gender='F') select sid,sname from sample_data where gender='F';
 image.png
image.png
有了分区表,可以对别没有分区的表,执行计划的不同:
explain select * from sample_data where gender='M';
explain select * from partition_table where gender='M'; -
外部表(External Table):
指向已经在HDFS中存在的数据,可以创建Partition
它和内部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异
外部表只有一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中,只是与外部数据建立一个链接。当删除一个外部表时,仅删除该链接
 image.png
image.png
create external table external_student
(sid int,sname string,age int)
row format delimited fields terminated by ','
location '/input'; 桶表(Bucket Table)
桶表是对数据进行哈希取值,然后放到不同文件中存储
create table bucket_table
(sid int,sname string,age int)
clustered by (sname) into 5 buckets;视图(View)
视图是一种虚表,是一个逻辑概念,可以跨越多张表;
视图建立在已有表的基础上,视图赖以建立的这些表成为基表;
视图可以简化复杂的查询
create view empinfo
as
select e.empno,e.ename,e.sal,e.sal*12 annlsal,d.dname
from emp e,dept d
where e.deptno=d.deptno;
select * from empinfo;
-
Hive数据导入
-
load
上边创建的t2和t3表结构是一样的,只是t2采用的分隔符是默认的制表符,t3采用的是逗号分隔,现有如下数据:
student01.txt:
1,Tom,23
2,Mary,20
student02.txt:
3,Mike,25
student03.txt
4,Scott,21
5,King,20
将student01.txt数据导入t2
load data local inpath '/home/hadoop/data/hive/student01.txt' into table t2; //失败,因为分隔符不一致将student01.txt数据导入t3
load data local inpath '/home/hadoop/data/hive/student01.txt' into table t3; //成功导入将/home/hadoop/data/hive/下的所有数据文件导入t3表中,并且覆盖原来的数据:
load data local inpath '/home/hadoop/data/hive/' overwrite into table t3;将HDFS中/input/student01.txt 导入到t3
load data inpath '/input/student01.txt' overwrite into table t3;上边有一张分区表叫做partition_table,创建语句是这样的:
create table partition_table (sid int,sname string) partitioned by (gender string) row format delimited fields terminated by ',';
现有如下数据:
data1.txt:
1,Tom,M
3,Mike,M
data2.txt:
2,Mary,F
load data local inpath '/home/hadoop/data/hive/data1.txt' into table partition_table partition (gender='M');
load data local inpath '/home/hadoop/data/hive/data2.txt' into table partition_table partition (gender='F'); -
Sqoop(是apache社区的一个开源框架)
下载sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz并解压
设置环境变量:
export HADOOP_COMMON_HOME=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0
export HADOOP_MAPRED_HOME=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0
具体使用可以查看官网
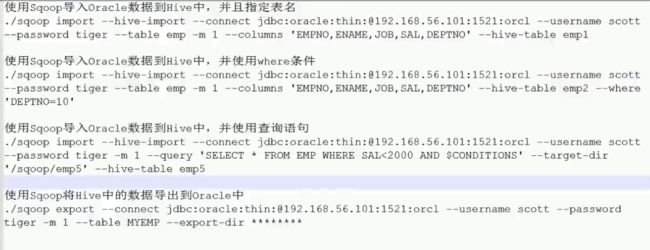 image.png
image.png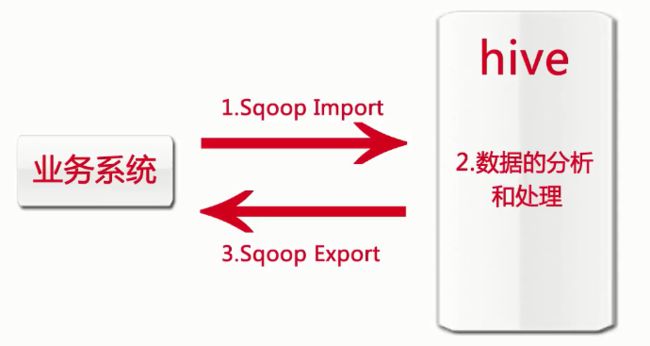 image.png
image.png
-
-
Hive的数据查询
--查询所有员工的所有信息
select * from emp;
--查询员工信息:员工号 姓名 月薪
select empno,ename,sal from emp;
--查询员工信息:员工号 姓名 月薪 年薪
select empno,ename,sal,sal12 from emp;
查询员工信息:员工号 姓名 月薪 年薪 奖金 年收入
select empno,ename,sal,sal12,comm,sal*12+nvl(com,0) from emp;
--查询奖金为null的员工
select * from emp where comm is null;
--使用distinct 来去掉重复记录
select distinct deptno,job from emp; 简单查询的Fetch Task功能,配置后简单查询就不会生成mapreduce作业,从Hive 0.10.0版本开始支持
配置方式:
set hive.fetch.task.conversion=more;
hive --hiveconf hive.fetch.task.conversion=more
-
修改hive-site.xml文件
hive.fetch.task.conversion
more
过滤查询:
--查询10部门的员工
select * from emp where deptno=10;
--查询名叫KING的员工
select * from emp where ename='KING';
--查询部门号是10,薪水小于2000的员工
select * from emp where deptno=10 and sal<2000;
--模糊查询:查询名字以S打头的员工
select empno,ename,sal from emp where ename like 'S%';
--模糊查询:查询名字含有下划线的员工
select empno,ename,sal from emp where ename like '%\\_%';
排序:
-- 查询员工信息:员工号 姓名 月薪 按照月薪排序
select empno,ename,sal from emp order by sal desc;
--order by 后面可以跟:列 ,表达式,别名,序号
select empno,ename,sal,sal12 annsal from emp order by annsal;
select empno,ename,sal,sal12 annsal from emp order by 4;//需要set hive.groupby.orderby.position.alias=true
--查询员工信息,按照奖金排序(null排序:升序在最前面,降序在最后面)
select empno,ename,sal,comm from emp order by comm desc;
-
hive函数
包括内置函数和自定义函数
 image.png
image.png -
数学函数:
举几个例子
round //四舍五入 select round(45,926,2),round(45,926,1),round(45,926,0),round(45,926,-1),round(45,926,-2),
ceil //向上取整 ceil(45.9)
floor //floor(45.9)- 字符函数:
举几个例子
lower // select lower('Hello World'),upper('Hello World');
upper
length //字符数 select length('Hello World'),length('你好');
concat //拼加字符串 select concat('Hello','World');
substr //求子串 select substr('Hello World',3); select substr('Hello World',3,4);
trim //去掉首位空格
lpad //左填充select lpad('abcd',10,''),rpad('abcd',10,'');
rpad //右填充 - 收集函数和转换函数
收集函数:
size(map(
select size(map(1,'Tom',2,'Mary'));
转换函数:
cast
select cast(1 as bigint);
select cast(1 as float);
select cast('2015-04-10' as date); - 日期函数
to_date //select to_date('2015-04-23 11:23:11');
year //select year('2015-04-23 11:23:11'),month('2015-04-23 11:23:11'),day('2015-04-23 11:23:11');
month
day
weekofyear //select weekofyear('2015-04-23 11:23:11');
datediff //select datediff('2015-04-23 11:23:11','2014-04-23 11:23:11')
date_add //select date_add('2015-04-23 11:23:11',2),date_sub('2015-04-23 11:23:11',2)
date_sub - 条件函数
coalesce:从左到右返回第一个不为null的值 //select comm,sal,coalesce(comm,sal) from emp;
case...when...:条件表达式
``` select ename,job,sal, case job when 'PRESIDENT' then sal+1000 when 'MANAGER' then sal+800 else sal+400 end from emp; ``` * 聚合函数 count //select count(*),sum(sal),max(sal),min(sal),avg(sal) from emp; sum min max avg * 表生成函数 explode select explode(map(1,'Tom',2,'Mary',3,'Mike')); - 字符函数:
Hive的表连接
等值连接、不等值连接、外连接、自连接
select e.empno,e.ename,e.sal,d.dname from emp e,dept d where e.deptno=de.deptno;//等值
select e.empno,e.ename,e.sal,s.grade from emp e,salgrade s where e.sal between s.losal and s.hisal;//不等值
select d.deptno,d.dname,count(e.empno) from emp e,dept d where e.deptno=d.deptno group by d.deptno,d.dname;
通过外连接可以将对于连接条件不成立的记录仍然包含在最后的结果中
左外连接,右外连接
select d.deptno,d.dname,count(e.empno) from emp e right outer join dept d on (e.deptno=d.deptno) group by d.deptno,d.dname;
自连接
select e.ename,b.ename from emp e,emp b where e.mgr=b.empno;Hive子查询
hive只支持:from和where子句中的子查询
select e.ename from emp e where e.deptno in (select d.deptno from dept d where d.dname='SALES' or d.dname='ACCOUNTING');
select * from emp e where e.empno not in (select e1.mgr from emp e1 where e1.mgr is not null);Hive的客户端操作
需要通过hive --service hiveserver启动Hive远程服务
2种方式:JDBC和Thrift Client