在Unix的设计哲学中,do one thing 被广大软件设计开发人员奉为圭臬,很多底层的基础代码只需要做成库,就可一劳永逸重复使用。但由于软件的升级,很多采用了包发布的方式,虽然方便了开发者免受“晨后综合症”的困扰,却也带来了依赖地狱这个问题。本文试图阐述库开发过程中的问题以及应对事项。
菱形依赖
菱形依赖(diamond denpendency)是指当主模块所依赖的两个库引用了同一库的不同版本的情况。如图所示:
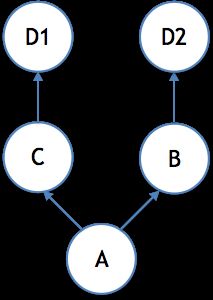
A模块使用了B和C,但B依赖D的version-2,C依赖D的version-1. 这种情况下,很多依赖管理工具就会直接(或提示你)将D的版本统一到version-2链接到最终的可执行文件中。但实际上,这是存在风险的。
分散式编译:lib.a的头文件陷阱
为了简化表达,我们将模块B省略,直接让A依赖D的version-2,并在最终的仲裁机制中选择了D的version-2. C原本依赖D的version-1,现在改为依赖version-2. 如图。
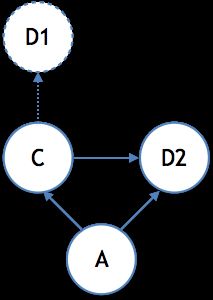
这样会有什么问题呢?
C/C++编译步骤
我们知道,C/C++的编译需要4步:

第一步预处理则是针对头文件中的#define 或者 #include等。假设D中某个常量,比如SHOW_ME_THE_MONEY 从100升级到1000. 那么libc.a中所使用的就是100,但A中被编译进去的则是1000. 原理其实很简单,正是因为编译发生在两个时间,仅仅通过发布头文件和.a文件的方式,导致时间和空间的耦合。
如果不相信,我们稍后见代码
链接的困惑
更难以接受的是某些功能不兼容的修改。比如下图这种情况:

本来X期望A库中的
f是
return 0的实现,但依赖仲裁将其升级到
return 1。
干说了这么多,你可能不相信,我们上代码:
/*base.h version-1*/
#ifndef BASE_H
#define BASE_H
const int SHOW_ME_THE_MONEY = 100;
#define I_AM_BLIND "But not d"
struct Base{
int id;
Base(int id):id(id){}
Base(const Base & other):id(other.id){}
void foo();
};
#endif
/*base.cpp version-1*/
#include
#include "base.h"
void Base::foo(){
std::cout << "old base, id:" << id << std::endl;
}
这里的base相当与我们最底层的库,它在一次升级中增加了我的MONEY和类中的一个flag。
/*base.h, upgrade to version-2, more money, add a flag member*/
#ifndef BASE_H
#define BASE_H
const int SHOW_ME_THE_MONEY = 1000;
#define I_AM_BLIND "But not deaf"
struct Base{
int id;
bool flag;
Base(int id, bool flag):id(id),flag(flag){}
Base(const Base & other):id(other.id),flag(other.flag){}
void foo();
};
#endif
/***new version: base.cpp****/
#include
#include "base.h"
void Base::foo(){
std::cout << "i'm new foo, id:" << id << " flag: " << flag << std::endl;
flag = false;
}
我们的另外一个依赖库x正在依赖version-1的base:
/*libx.h*/
#ifndef LIBX_H
#define LIBX_H
#include "base.h"
void call_libx();
#endif
----------------cpp below------------
/*libx.cpp : remeber , base version-1 in use..*/
#include
#include "base.h"
void call_libx(){
std::cout << "my money in lib: "
<< SHOW_ME_THE_MONEY
<< " DH: " << I_AM_BLIND
<< std::endl;
Base b(110);
b.foo();
}
接下来是我们的主模块,他同时依赖x和base:
#include
#include "base.h"
#include "libx.h"
int main(int argc, char* argv[]){
std::cout << "my money in app:"
<< SHOW_ME_THE_MONEY
<< " DH:" << I_AM_BLIND
<< std::endl;
call_libx();
return 0;
}
我们将新旧base.h,base.cpp都编译成libbase.a,然后将libx也编译成.a,供主模块编译链接,运行后的结果和前文所说一致:
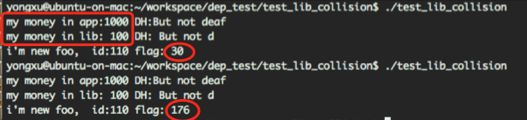
常量在不同的模块有不同的值,flag字段则出现随机值。(这很危险哦)
如何应对
一般来讲,如果你只负责上图中A模块或者APP的代码,并无库的权限,也许只能向库作者提交ISSUE单了。不过假设我们负责整个架构的代码,如何应对呢?
源码依赖
对于分散式编译的问题,只要在我们的代码中废弃.a这种方式,就能将编译时刻统一到当前。
后向兼容和末端依赖
对于库开发者,除非历史包袱特别的重,应后向兼容所有版本号小于自己的版本。类似Python,最新的2.7可以运行2.5或者2.6的代码.
而对应使用者,则应永远依赖最新的发布。在依赖管理工具上,提供依赖最新的这种抽象依赖手段。
更新
git ci --amend -m "thanks to 微笑的鱼Lilian"
谢谢微笑的鱼Lilian, 提出了一个为什么libx中使用了Base(int)的构造函数仍然可以链接通过的问题。
原因是第一个版本的base.h的构造函数是inline在头文件中的,当编译libx.cpp的时候,#include将其展开在了libx.cpp中导致的。
这让我警醒到,原来不同版本的inline函数,和常量、宏一样,容易发生分散式编译的问题。