信用评分:第三部分 - 数据准备和探索性数据分析
上一篇:信用评分:第二部分 - 信用评分卡建模方法
基本原理

“垃圾输入,垃圾输出”是计算机科学中常用的公理,也是项目成功的威胁 - 输出质量在很大程度上取决于输入质量。因此,数据准备是任何数据挖掘项目的关键方面,包括信用评分卡的开发。这是CRISP-DM周期中最具挑战性和最耗时的阶段。项目总时间的至少70%,有时甚至超过90%专门用于此活动。它涉及数据收集,结合多个数据源,聚合,转换,数据清理,“切片和切割”,并查看数据的广度和深度,以获得清晰的理解,并将数据量转换为数据质量,以便我们可以自信地准备下一阶段 - 模型建设。
本系列的前一篇文章,信用评分卡建模方法讨论了模型设计的重要性,并确定了其主要组成部分,包括分析,人群框架,样本大小,标准变量,建模窗口,数据源和数据收集方法。仔细考虑每个组件对于成功的数据准备是必不可少的。该阶段的最终产品是挖掘视图,包括正确的分析级别,建模人群,自变量和因变量。

数据源
“越多越好” - 作为数据理解步骤的一部分,任何外部和内部数据源都应保障数量和质量。所使用的数据必须具有相关性,准确性,及时性,一致性和完整性,同时具有足够和多样化的数量,以便在分析中提供有用的结果。对于申请评分卡而言,内部数据有限,外部数据较为普遍。相反,行为评分卡使用更多的内部数据,并且在预测能力方面通常更优越。下面概述了客户验证,欺诈检测或信用补助所需的通用数据源。

The data preparation process starts with data collection, commonly referred as ETL process (Extract-Transform-Load). Data integration combines different sources using data merging and concatenation. Typically, it requires manipulation of relational tables using a number of integrity rules such as entity, referential and domain integrity. Using one-to-one, one-to-many or many-to-many relationships, the data is aggregated to the desired level of analysis so a unique customer signature is produced.
过程
数据准备过程从数据收集开始,通常称为ETL过程(Extract-Transform-Load)。数据集成使用数据合并和连接组合不同的源。通常,它需要使用许多完整性规则来操纵关系表,例如实体,引用和域完整性。使用一对一,一对多或多对多关系,使数据会聚合到所需的分析级别,从而生成唯一的客户签名。
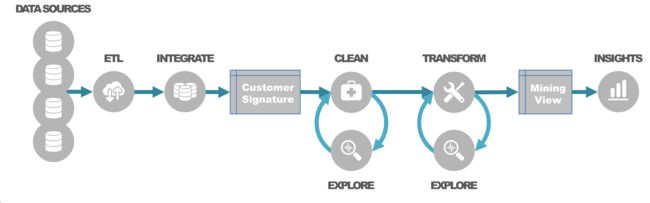
数据探索和数据清理是相互迭代的步骤。数据探索包括单变量和双变量分析,范围从单变量统计和频率分布,到相关性分析,交叉表分析和特征分析。

在探索性数据分析(EDA)之后,处理数据以提高质量。数据清理需要良好的业务理解和数据理解,以便以正确的方式解释数据。这是一个迭代过程,旨在消除不规则性,并在适当时替换,修改或删除这些不规则性。不干净数据的两个主要问题是缺失值和异常值; 两者都会严重影响模型的准确性,因此必须进行谨慎的干预。
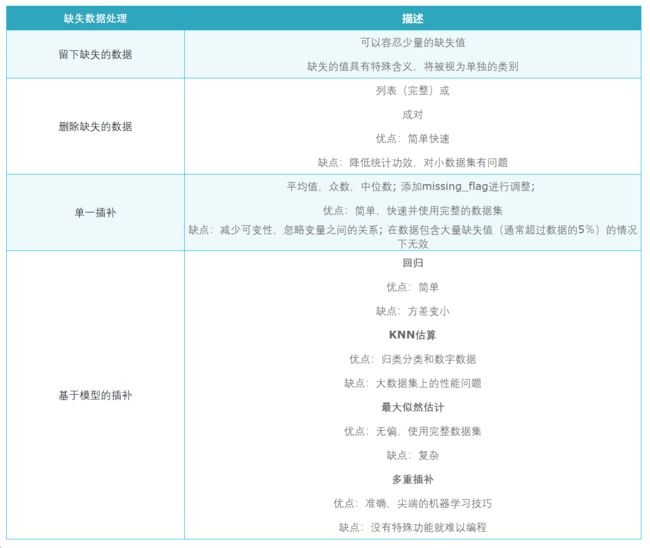
在决定如何处理缺失值之前,我们需要了解缺失数据的原因并理解缺失数据的分布,以便我们将其归类为:
- 随机丢失(Missing completely at random,MCAR);
- 随意丢失(Missing at random,MAR),或;
- 非随意丢失(Missing not at random,MNAR)。
缺失数据处理通常假设MCAR和MAR,而MNAR更难以处理。以下列表提供了按复杂程度排序的常见治疗方法。
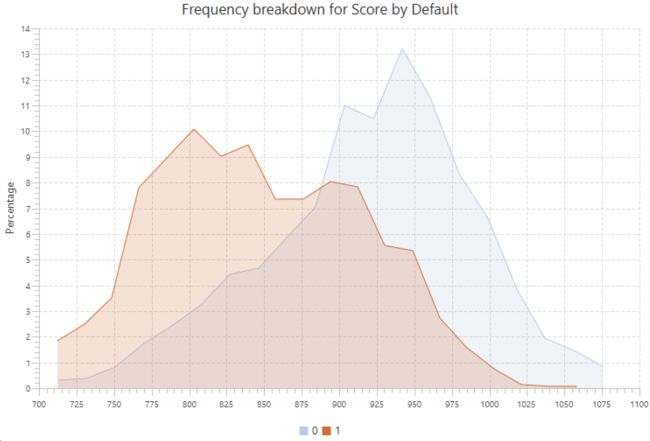
异常值是我们数据中的另一个“野兽”,因为它们的存在可能违反我们开发模型的统计假设。一旦确定为异常值,重要的是要在应用任何处理之前了解异常值出现的原因。例如,异常值可能是欺诈检测中有价值的信息来源; 因此,用平均值或中值替换它们是个坏主意。
应使用单变量和多变量分析来分析异常值。为了检测,我们可以使用直方图,箱形图或散点图等可视化方法和统计方法,如平均值和标准差,检查远距离聚类、小决策树叶节点、马哈拉诺比斯距离、库克D或格拉布斯测试进行聚类。异常值的判别并不像识别缺失值那样简单。决策应基于特定的标准,例如:±3标准差以外的任何值,或±1.5IQR,或第5-95百分位数范围将被标记为异常值。
可以用与缺失值类似的方式来处理异常值。还可以使用其他变换,包括:分箱,权重分配,转换为缺失值,对数变换以消除极值的影响或缩尾处理。
如上所述,数据清理可涉及实现不同的统计和机器学习技术。即使这些转换可以创建更优秀的评分卡模型,但实际上必须考虑实施问题,因为复杂的数据操作可能难以实现,成本高并且降低了模型处理性能。
一旦数据干净,我们就可以为更有创意的部分做准备 - 数据转换。数据转换或特征工程是创建额外的(假设的)模型变量,这些变量经过重要性测试。最常见的转换包括分箱和最佳分箱,标准化,缩放,独热码,交互项,数学变换(从非线性到线性关系,从偏斜数据到正态分布数据)和使用聚类和因子分析进行数据缩减。
除了关于如何处理此任务的一些一般性建议之外,数据科学家还有责任建议将客户数据签名转换为强大的信息假象的最佳方法 - 挖掘视图。这可能是数据科学家角色中最具创造性和最具挑战性的方面,因为除了统计和分析技能之外,它还需要牢固掌握业务理解。通常,创建良好模型的关键不是特定建模技术的强大功能,而是衍生变量的广度和深度,它们代表了对所检查现象的更高级别的了解。
其余的是创建特征的艺术......
上一篇:信用评分:第二部分 - 信用评分卡建模方法
下一篇:信用评分:第四部分 - 变量选择
本文翻译转载自https://www.worldprogramming.com/blog/credit_scoring_pt3。