一、推荐系统价值分析
推荐系统解决的是人与物品/信息的高效匹配问题。人与物品/信息之间的关系,主要受用户意图和物品数量两个维度影响,而解决方案经历了三个阶段:第一阶段是在物品/信息数量较少时,人直接通过逐个查看的方式即可解决;第二阶段是物品/信息数量较多,为方便查找,提供物品/信息分类以及搜索功能;第三阶段的推荐系统是为解决物品/信息数量多且用户意图模糊场景。
从推荐系统解决的主要问题场景看,推荐系统适用的用户为用户B和用户C。首先介绍下用户A、B、C的特征:
1、用户A :用户A对自己需要什么非常了解、属于目标清晰型 ,像男生买东西很多都属于这类用户。很多男生在打开购物app之前,已经明确要买什么,具体买哪家的,看品质和价格。
2、用户B:用户B对自己需求很模糊,比如像女生买裙子,买长款的、还是短款的?是买淑女风的、还是买休闲风的,傻傻搞不清楚。也许最后逛着逛着买了条短裤。
3、用户C:用户C在打开购物app前,其实没有购物需求,只是因为现在比较闲,想逛逛有什么好看的、时尚的、新颖的东东。
从用户A、B、C的购物特征看,推荐系统能发挥作用并能影响其购物路径的是用户B和用户C。
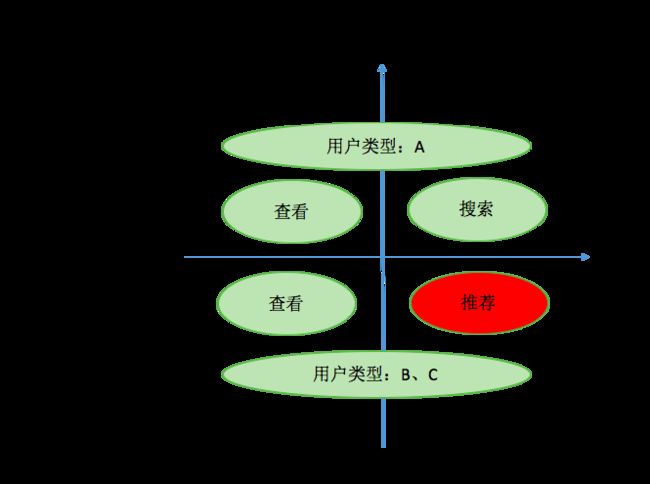
根据以上分析,推荐系统的价值总结如下:
1、用户价值:推荐系统主要服务于具有B和C特质的用户,在用户意图不清晰时将合适物品送到用户前、提升用户的体验,或者是在用户闲逛时,将适合他的物品呈现到他面前,提升用户的惊喜度。
2、公司价值:
1)由于每个网站或app的展台或者曝光点资源都有限,尽可能高效利用有限空间、为每个用户呈现其所需的物品,提升物品转化率和成交率;
2)尽可能提供用户感兴趣的物品,让用户愿意将时间消费在我们的产品上,只要用户愿意停留在我们产品上,物品的商业转化机会就越大;
3)挖掘用户的潜在兴趣,协助用户消费升级(如网购)或者知识结构扩展(如资讯或者电子书籍类)。
二、推荐系统的端到端流程架构
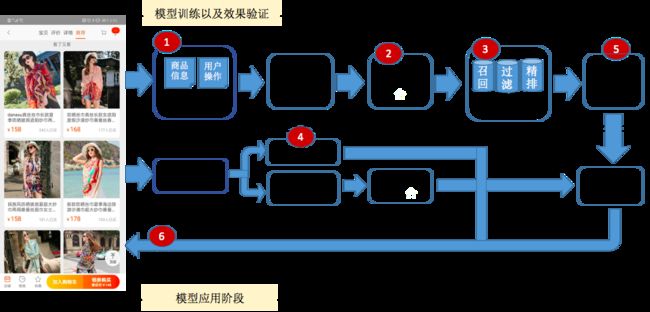
该图展示了推荐系统所包含的各个组件,以下章节对各关键组件进行简单介绍。
三、数据采集
对于推荐系统来说,数据问题是首要问题,是决定是否具有搭建推荐系统的基石。数据不仅仅是提供给用户的商品数据,还包括用户进入app后的操作数据,对于用户的操作数据、需要做好埋点,采集有效的数据。
为啥这里我强调有效数据呢?举个例子,如果系统的各个阶段都有数据埋点,但是各埋各的、没有统一标准,可能会导致采集回来的数据处理效率低甚至无法处理。所以这里的数据问题不仅仅指是否有数据,而且需要格式统一的结构化数据,埋点严格遵循数据格式与长度规范。在之前的工作中,遇到数据方面的问题主要表现在三个方面:
1、埋点缺失,数据无法收集或者收集不全
2、数据没有进行科学的存储,导致无法使用
3、数据存储无统一规范,采集的数据后处理效率低、甚至无法处理
四、特征提取
以电商场景为例,特征主要分为三个方面:
商品维度的特征。主要包括:商品上架时所带的一些基本属性,如商品的类别、品牌、价格,商品的物料、厚度,商品适合的季节,商品面向的客户性别、年龄等;用户行为隐性体现的特征,如:点击率、收藏率、加购物车、下单等,这些数据能体现商品的热度、受欢迎程度等;用户行为隐性反应各商品的质量,如评论信息。综合以上信息,一方面体现了商品本身的基本属性,另外还能从使用者角度体现了商品的真实质量。
用户维度的特征。电商场景中用户年龄、性别、收入水平等都是关键特征。男性和女性所偏重的物品之间存在较大差异;不同年龄段的用户对物品的偏好也存在较大差异;不同消费水平的用户对物品的偏好也有很大差异。
应用场景和应用时机的特征。在国内大多数地区,衣服和鞋子是季节性商品,用户对当季商品的偏好会更大;衣服和鞋子也是具有区域性的商品,比如像杭州、苏州等地区,今年特别流行唐装;衣服和鞋子还会和场合有关系,比如像聚会、上班以及去海边游玩,这三种场合对衣服的诉求肯定会有所差异。
五、推荐算法
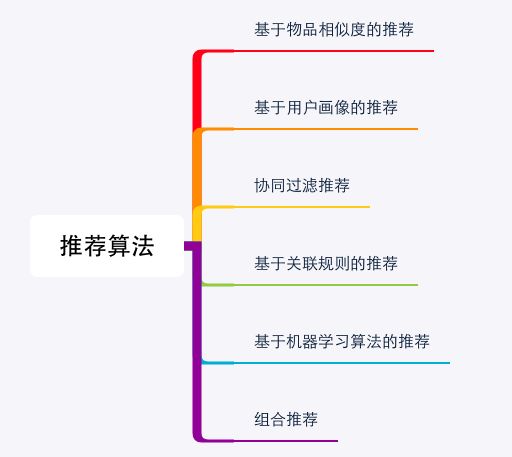
1、基于物品属性相似的推荐
这种推荐策略的逻辑很简单,即“物以类聚”,依赖物品本身属性地相似度来构建推荐关系。图中的各种分类就是一种相似性的体现。如女装-》连衣裙这种分类,其实就是将在“连衣裙”这个维度上相似性非常高的物品聚合在一起。

像实际使用中以下几种情况会导致该推荐方式失效。
1)用户浏览的当前物品本身就不是用户的偏好,而是由于其他外部信息导致的,比如我出于测试目的点击了某个物品或者手滑选择了某个物品,那这类信息对于系统来说是一种干扰信息,如果再基于该信息进行推荐就存在问题。
2)当前所浏览或者收藏的物品或信息是用户目标物品,但一直推荐和已选物品/信息相似的,对用户来说是一种信息冗余,尤其是在用户已经购买了该物品的情况下。比如我7月份买了华为p30手机,基于该推荐方法就会一直再给我推荐手机甚至是华为p系列手机,而像手机这种非易耗品,基本上短期内不会更换,那这种推荐显然是无效的。
所以,一方面由于用户行为的不可控,完全基于物品/内容本身属性相似的推荐,风险较高、无法直接广泛使用。另一方面由于当前物品/信息在某些场景下已解决用户问题,再一直推荐相似物品,不但不会带来转化,甚至会引起用户反感。
但存在即合理,那么究竟基于内容属性相似的推荐在什么场景下使用比较合适呢?在冷启动时,用户首次登录未留下用户信息或者才浏览了为数不多的几个产品时,此时用户信息匮乏,基于物品本身的属性给用户做推荐也许能带来不错的效果。
2、基于用户画像的推荐
基于物品本身属性的推荐,其实个性化程度很低,毕竟推荐候选集只跟物品本身有关,与用户关系不大,所以也没什么个性化可言。而基于用户画像(或基于用户标签)的推荐,更大程度上依赖于用户属性来推荐,这就体现了用户的偏好信息,推荐候选集和用户偏好关系较密切。
那么用户画像/兴趣标签如何构建呢?这是一个比较复杂的课题。一种方法是用户自己告诉你,比如很多app在首次登录时,让用户选择所喜欢的标签,其实就是让用户自己告诉你他的喜好,也就是让用户自己给自己打标签;第二种方法就是系统分析用户累积的行为数据,通过行为数据生成用户的兴趣标签。理论上看,这似乎是一种比较可行的做法,毕竟如果真把用户的爱好都分析清楚了、给用户做的推荐肯定是个性化的。
第一种方法是用户自己给自己的画像,这种方法在产品或者用户冷启动时比较有效,但用户提供的信息是当时当下的画像,是一种静态画像,但用户画像其实是会随时间变化的,如果让用户兴趣变化了主动刷新画像显然不现实。
第二种方法是系统基于用户历史行为分析用户画像,该方法实际使用中在以下场景会失效:
1)用户在该平台没有行为数据,那采用系统分析的方法此时无法构建用户画像,除非让用户自己告诉你他的喜好。
2)并不是所有用户行为都能够用来表征其兴趣偏好,也就是说用户在该平台上留下的行为有可能存在一些干扰信息,这种情况下生成的用户画像可能是有偏差的。
3)用户的兴趣爱好并不是一直静止不变的,是会随时间的迁移而改变的,比如我今天刷小视频喜欢看美食类的,可能下周我就会喜欢美妆类的。
也就是说,实际上需要通过用户行为掌握用户的真实兴趣、兴趣程度以及兴趣迁移不是一件容易的事儿,更何况用户实际选择还会受很多意外因素影响,比如,我最近首次购买打印机,这在我购物信息轨迹中是没有的,那单纯地通过我历史行为构建出的兴趣期望能预测到我此次非常规的购买行为显然就不可行了。
3、协同过滤推荐算法
协同过滤推荐是推荐领域典型算法,协同过滤不研究物品本身属性,甚至也不关注用户的标签。那么它的机制又是怎样的呢?
协同过滤推荐算法主要分两大类:一类是基于用户的协同过滤推荐,另外一类是基于物品的协同过滤推荐。
基于用户的协同过滤推荐,简单地说,为用户A推荐物品,那么需要参考A周边的用户都购买了什么物品,而A暂时还未购买甚至不知道的物品。从上面的描述可以知道,这个方法主要要做两件事:1)如何限定“周边”的范围,即怎么判定哪些用户和用户A兴趣相似,根据A用户和其他用户的历史行为计算他们之间的相似度。2)在圈定了用户A的邻居后,筛选出A用户邻居们喜欢的但A还没购买甚至还未听说过的物品推荐给A。该方法的困难在于:
1)像电商或者视频网站用户,动不动就上亿的用户量,两两计算相似度计算量太大,时间复杂度太高。但实际上这么多用户中,两两之间有相似性的用户较少,很多用户两两之间并没有相似性,也就是说很多的相似计算是无用的,即相似度矩阵是稀疏矩阵。对于这种稀疏矩阵问题,可以建立一个物品到用户的倒排表,即对于每个物品建立对其有过行为的用户表。
2)选择多少个和A用户相似的邻居,对推荐效果影响较大。需要根据具体项目,比较不同邻居数时推荐效果从而选出该值。
3)物品的流行度或热度对推荐结果可能会存在影响。在实际评估算法效果时,需要考虑物品的热度,将热度过高的产品扣除后再评估算法效果会更加靠谱。
基于用户的协同过滤算法在一些网站中得到应用,但该算法有一些比较难解决的问题,除了上面提到的问题,另外,基于用户的协同过滤算法比较难对用户做出解释,推荐过程难以解释清楚的推荐,可信度会降低。
而基于物品的协同过滤算法就能很好对推荐结果做出解释,比如你经常能看到“购买了该商品的用户还购买了xxx”。那什么是基于物品的协同过滤算法呢?该算法不利用物品的内容属性计算物品间的相似度,主要通过分析用户的行为记录计算物品的相似度,即该算法认为物品A和物品B具有很大相似度是因为喜欢A的用户大都也喜欢物品B。
综上,相对于基于用户画像的推荐,协同过滤推荐有一定几率可以为用户发现新物品,即并不严格依赖用户的兴趣。比如,家长给孩子买辅导资料,去年买一年级的,今年买二年级的,明年买三年级的,这三年买的东西是一个循序渐进的,并且是层层递进的,而不是同一个东西。那么如果仅基于用户画像的推荐,通过对该用户历史轨迹的研究,发现他当前买的都是一年级的资料,而没有二年级的资料特征。也就是说该用户的兴趣偏好偏向于一年级资料,根据兴趣标签,其实是很难推荐这种递进相关的信息。但是,如果基于协同用户的推荐,就有能挖掘到这种递进关系。比如其他用户的购买轨迹都是一年级资料->二年级资料->三年级资料这种轨迹,这意味着三者之间存在潜在的逻辑关系,基于用户协同,在了解到用户已有一年级资料的基础上,可为该用户推荐二年级、三年级的资料。
在实际使用中,基于协同过滤的推荐方法在以下场景下会失效:
1)推荐质量取决于历史数据,系统刚开始或者对于新用户,推荐质量会比较差,即有冷启动问题;
2)可扩展性问题,比如新闻资讯领域,由于新闻的更新非常快,可能每时每刻都有新内容出现,基于物品的协同过滤算法显然就有些力不从心了,因为基于物品的协同过滤算法需要维护一张物品相似度的表,在物品更新很快的情况下,这张表也需要快速更新,这在技术上很难实现。绝大多数的表都是一天更新一次,显然在新闻领域是不可接受的。
3)数据稀疏,比如淘宝用户都是上亿的,两两计算相似度,想想这个相似度矩阵就很大。但很多用户之间其实没有相似性,即这个相似度矩阵是个稀疏矩阵。
4、基于关联规则的推荐
基于关联规则的推荐算法是以关联规则为基础,从大量用户历史数据中统计强关联规则,是一种无监督的机器学习算法。在关联规则算法中,关键是如何找到最大频繁项。业界主要做法有Apriori算法、FP-Growth树和eclat。关联规则的经典应用是购物篮分析,比如经典的啤酒和尿布的故事。早期的亚马逊、京东、淘宝等购物推荐场景中经常使用,相对简单粗暴。该算法的优点是能从大量行为数据中挖掘出无法直接感受到的规则,往往能给出意想不到的结果。但在实际使用中可能存在以下问题:
1)难以进行模型评估,一般通过行业经验判断结果是否合理。
2)关联规则的发现计算复杂度较高,是算法的瓶颈。
3)物品名称的同义性问题也是关联规则的一个难点。
5、基于机器学习算法的推荐
推荐问题,直观上就是当前有个物品x和用户A,预估a物品是否适合推荐给用户A。该问题其实可以看作二分类问题,分类结果要么适合、要么不适合。即在有足够的用户数据情况下,通过用户历史行为数据构建预测模型y=f(x) ,预测用户是否会对某物品感兴趣。对于分类问题,机器学习中有各种算法,比如LR 、SVM、随机森林、 GBDT、贝叶斯、神经网络等等。机器学习算法的相关内容连载中再详细展开。
6、基于组合算法的推荐
由于各种推荐方法都有优缺点,所以在实际使用过程中,经常采用组合推荐。研究和应用最多的是基于物品属性推荐和协同过滤推荐的组合。最简单的做法就是分别用基于内容的方法和协同过滤推荐方法去产生一个推荐结果,然后用某方法组合其结果。尽管从理论上有很多种组合方法,但在某一具体问题中并不见得都有效,组合推荐一个最重要原则就是组合后能规避或弥补各自推荐技术的弱点。
在组合方式上,有研究人员提出了七种组合思路:
1)加权:加权多种推荐技术结果。
2)变换:根据问题背景和实际情况要求变换采用不同的推荐技术。
3)混合:同时采用多种推荐技术并给出多种推荐结果为用户提供参考。
4)特征组合:组合来自不同推荐数据源的特征,提供给另一种推荐算法用。
5)层叠:先用一种推荐技术产生一种粗糙的推荐结果,然后在此推荐结果的基础上采用第二种推荐技术进一步作出更精确的推荐。
6)特征扩充:将一种推荐技术产生的附加特征信息,嵌入到另一种推荐技术的特征输入中。
7)元级别:用一种推荐方法产生的模型作为另一种推荐方法的输入。
六、冷启动问题
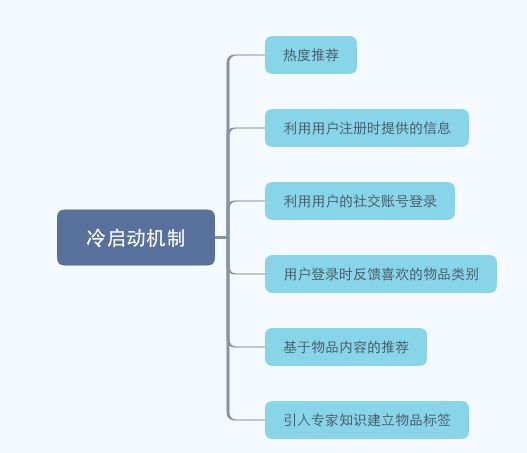
冷启动问题主要分三类:
1、用户冷启动:用户冷启动主要解决如何给新用户做个性化推荐的问题。当新用户到来时,系统未收集到用户的操作历史,所以无法根据用户的历史行为对用户进行推荐。
2、物品冷启动:物品冷启动主要解决如何将新加入的物品推荐给感兴趣的人。
3、系统冷启动:系统冷启动主要指的时如何在新开发的网站或者app上就给用户提供个性化推荐。
对于如上几种冷启动问题有不同的解决方案,一般有如下解决方案:
1、热度推荐,其实这是一种非个性化的推荐。给新用户推荐热门物品,待用户在平台上留下足迹后再切换为个性化推荐。
2、要求用户在注册时提供信息,注册信息一般分3类:
1)人口统计学信息:包括用户的年龄、性别、职业、民族、学历、出生地、所在地等等
2)用户兴趣:让用户提供一些兴趣标签
3)从其他网站导入用户站外的行为信息,常用的做法是让用户通过社交账号登录,就可以在社交账号获取用户的行为和社交数据,以此数据分析用户的兴趣。
基于注册信息的个性化推荐流程基本如下:
1)获取用户的注册信息
2)根据用户的注册信息分析用户,然后按照分析的用户标签对用户进行分类
3)给用户推荐他所属分类中用户喜欢的物品
3、用户登录时要求用户反馈对物品的喜好
在新用户第一次访问系统时,不立即给用户展示推荐结果,而是给用户提供一些物品试探用户的兴趣,让用户反馈对这些物品的兴趣,然后根据用户反馈提供个性化推荐。该方法的核心是选择什么样的物品试探用户的兴趣,一般能够用来启动用户兴趣的物品具有以下特点:
1)比较热门:如果要用户反馈对物品的兴趣,前提是用户对该物品很熟悉。如果选择一个冷门物品,很多用户都不知道这个物品是什么,显然这种试探就没有意义。
2)具有代表性和区分度:启动用户兴趣的物品不能是大众化或者老少皆宜的,因为这种物品试探不出用户的兴趣。
3)启动物品需要有多样性:用户的兴趣可能非常多,需要提供具有多样性的物品挖掘用户尽可能多的兴趣,通过多维兴趣特征构建用户兴趣模型。
4、引入专家经验
为了在推荐系统建立时就能让用户得到比较好的体验,有些系统会引入专家经验。比较经典的是pandora,这是一款个性化电台应用,非常好地建立音乐间相似性技术上比较有挑战。音乐是多媒体资源,如果从分析音频信息入手去计算歌曲之间地相似性,技术难度比较大。但如果仅仅是看专辑、歌手等信息去建立音乐地相似性,似乎又没有什么意义。pandora为了解决这个问题,引入音乐专家,从400多个维度对每首歌曲进行标注,构建了每首歌地音乐基因。标注完之后,每首歌都是一个400多维地向量,计算向量之间地相似度从而就可以了解歌曲之间地相似度。
七、展台
在电商场景中,会在用户路径的很多节点中进行推荐,这些路径可以归类为:购买前、购买中和购买后。
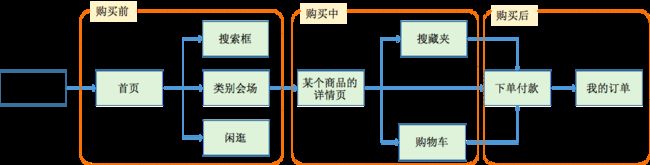
以淘宝为例,从用户打开app,在用户视野所到之处推进无处不在,梳理了下用户购物的可能路径,如上图所示,图中绿底色标示的用户路径中都有推荐的影子。进入app首页,在首页的banner中会看到推荐商品,不论是进入各类别商品、还是通过搜索框搜索都会看到推荐商品;用户点开某一个商品,进入详情页,在浏览详情页的过程中,会看到“店铺推荐”、“穿搭推荐”、“看了又看”等;用户将该商品收藏,在收藏夹中,用户会看到“相似”;用户将该商品加入购物车,在购物车后会看到“你可能还喜欢”;用户下单后,会看到“你可能还喜欢”;此次购物结束后,用户打开我的订单,在定单的“待付款”、“待发货”、“待收获”等页面下,会看到“你可能还喜欢”。
以上分析了推荐系统的价值以及基本内容,分析的还不够深入,待各位大侠指正,后续进一步完善。