上一篇说到了Google Spanner--全球级分布式数据库,但我觉得Spanner不能称作NewSQL,因为Spanner虽然有外部一致性、类SQL接口和常见事务支持,但和传统关系型数据库相比功能仍不够丰富,对此,Google在Spanner上开发了F1,扩展了Spanner已有特性成为名副其实的NewSQL数据库;F1目前支撑着谷歌的AdWords核心业务。
简介
AdWords业务本来使用MySQL+手工Sharding来支撑,但在扩展和可靠性上不能满足要求,加上Spanner已经在同步复制、外部一致性等方面做的很好,AdWords团队就在Spanner上层开发了混合型数据库F1(F1意味着:Filial 1 hybrid,混合着关系数据的丰富特性和NoSQL的扩展性),并于2012年在生产环境下替代MySQL支撑着AdWords业务(注意:F1和Spanner之间关系并不是MariaDB基于MySQL再开发的关系,而是类似InnoDB存储引擎和MySQL Server层的关系--F1本身不存储数据,数据都放在Spanner上)。
F1设计目标
1.可扩展性:F1的用户经常有复杂查询和join,F1提供了增加机器就能自动resharding和负载均衡。
2.高可用性:由于支撑着核心业务,分分钟都是money,不能因为任何事故(数据中心损坏、例行维护、变更schema等)而出现不可用状况。
3.事务:Spanner的外部一致性的是不够的,标准ACID必须支持。
4.易用性:友好的SQL接口、索引支持、即席查询等特性能大大提高开发人员的效率。
F1规模
截止这篇论文发表之时(2013年)F1支撑着100个应用,数据量大概100TB,每秒处理成百上千的请求,每天扫描数十万亿行记录,和以前MySQL相比,延迟还没增加;在这样规模下,可用性竟达到了惊人的99.999%!
F1架构总览
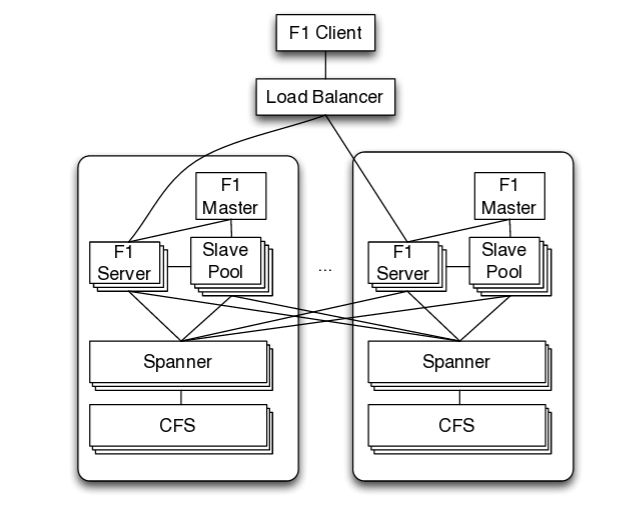
使用F1的用户通过client library来连接,请求再负载均衡到一个F1节点,F1再从远Spanner读写数据,最底层是分布式文件系统Colossus.负载均衡器会优先把请求连到就近的数据中心里的F1,除非这数据中心不可用或高负载.通常F1和对应Spanner都在同一个数据中心里,这样能加快访问Spanner的速度,假如同处的Spanner不可用,F1还能访问远程的Spanner,因为Spanner是同步复制的嘛,随便访问哪个都行。
大部分的F1是无状态的,意味着一个客户端可以发送不同请求到不同F1 server,只有一种状况例外:客户端的事务使用了悲观锁,这样就不能分散请求了,只能在这台F1 server处理剩余的事务。
你可能会问上图的F1 Master和Slave Pool干嘛的?它们其实是并行计算用的,当query planner发现一个SQL可以并行加速执行的话,就会将一个SQL分拆好多并行执行单位交到slave pool里去执行,F1 Master就是监控slave pool健康情况和剩余可用slave数目的.除了SQL,MapReduce任务也可用F1来分布式执行。
F1数据模型
F1的数据模型和Spanner很像--早期Spanner的数据模型很像Bigtable,但后来Spanner还是采用了F1的数据模型.
逻辑层面上,F1有个和RDBMS很像的关系型schema,额外多了表之间层级性和支持Protocol Buffer这种数据类型.那表之间层级性怎么理解呢?其实就是子表的主键一部分必须引用父表,譬如:表Customer有主键(CustomerId),它的子表Campaign的主键必须也包含(CustomerId),就变成这种形式(CustomerId, CampaignId);以此可推假如Campaign也有子表AdGroup,则AdGroup的主键必须这种形式--(CustomerId,CampaignId, AdGroupId).最外面父表Customer的主键CustomerId就叫一个root row,所有引用这个root row的子表相关row组成了Spanner里的directory(这个解释比Spanner那篇论文反而清楚,囧),下图比较了RDBMS和F1、Spanner的层级结构区别:
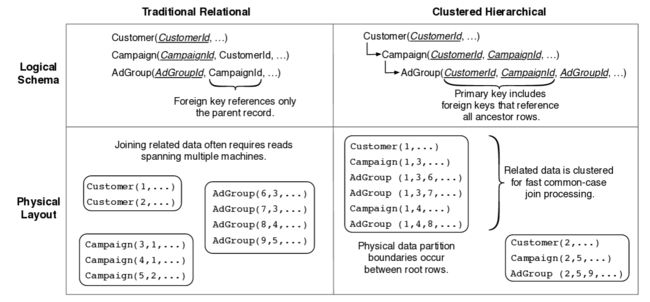
那为什么F1、Spanner要使用这种层级存储方式呢?有多方面的好处:1.可以并行化:想象一下假如要取Campaign和AdGroup表里所有CustomerId=1的记录,在传统RDBMS里,因为Adgroup不直接包含有CustomerId字段,所以这种情况下只好顺序化先取Campaign表里满足条件的行再处理AdGroup表;而在层级存储方式下,Campaign和AdGroup表都包含CustomerId字段,就能并行处理了.2.可以加速update操作:update一般都有where 字段=XX这样的条件,在层级存储方式下相同row值的都在一个directory里,就省的跨Paxos Group去分布式2PC了.
Protocol Buffer
不要听名字感觉Protocol Buffer是个缓存什么之类的,其实Protocal Buffer是个数据类型,就像XML、Json之类,一个数据类型而已;因为在谷歌内部的广泛使用,所以F1也支持它,但是是当做blob来对待的.Protocol Buffer语义简单自然,还支持重复使用字段来提高性能(免得建子表)。
索引
所有索引在F1里都是单独用个表存起来的,而且都为复合索引,因为除了被索引字段,被索引表的主键也必须一并包含.除了对常见数据类型的字段索引,也支持对Buffer Protocol里的字段进行索引.
索引分两种类型:
Local:包含root row主键的索引为local索引,因为索引和root row在同一个directory里;同时,这些索引文件也和被索引row放在同一个spanserver里,所以索引更新的效率会比较高.
global:同理可推global索引不包含root row,也不和被索引row在同一个spanserver里.这种索引一般被shard在多个spanserver上;当有事务需要更新一行数据时,因为索引的分布式,必须要2PC了.当需要更新很多行时,就是个灾难了,每插入一行都需要更新可能分布在多台机器上的索引,开销很大;所以建议插入行数少量多次.
无阻塞schema变更
考虑F1的全球分布式,要想无阻塞变更schema几乎是mission impossible,不阻塞那就只好异步变更schema,但又有schema不一致问题(譬如某一时刻数据中心A是schema1,而数据中心B是对应确是schema2),聪明的谷歌工程师想出了不破坏一致性的异步变更算法,详情请参见--Online, Asynchronous Schema Change in F1
ACID事务
像BigTable的这样最终一致性数据库,给开发人员带来无休止的折磨--数据库层面的一致性缺失必然导致上层应用使用额外的代码来检测数据一致性;所以F1提供了数据库层面的事务一致性,F1支持三种事务:
1.快照事务:就是只读事务,得益于Spanner的全局timestamp,只要提供时间戳,就能从本地或远程调用RPC取得对应数据.
2.悲观事务:这个和Spanner的标准事务支持是一样的,参见Google NewSQL之Spanner.
3.乐观事务:分为两阶段:第一阶段是读,无锁,可持续任意长时间;第二阶段是写,持续很短.但在写阶段可能会有row记录值冲突(可能多个事务会写同一行),为此,每行都有个隐藏的lock列,包含最后修改的timestamp.任何事务只要commit,都会更新这个lock列,发出请求的客户端收集这些timestamp并发送给F1 Server,一旦F1 Server发现更新的timestamp与自己事务冲突,就会中断本身的事务.
可以看出乐观事务的无锁读和短暂写很有优势:
1.即使一个客户端运行长时间事务也不会阻塞其他客户端.
2.有些需要交互性输入的事务可能会运行很长时间,但在乐观事务下能长时间运行而不被超时机制中断.
3.一个悲观事务一旦失败重新开始也需要上层业务逻辑重新处理,而乐观事务自包含的--即使失败了重来一次对客户端也是透明的.
4.乐观事务的状态值都在client端,即使F1 Server处理事务失败了,client也能很好转移到另一台F1 Server继续运行.
但乐观事务也是有缺点的,譬如幻读和低吞吐率.
灵活的锁颗粒度
F1默认使用行级锁,且只会锁这行的一个默认列;但客户端也能显示制定锁其他栏;值得注意的是F1支持层级锁,即:锁定父表的几列,这样子表的对应列也会相应锁上,这种层级锁能避免幻读.
变更历史记录
早前AdWords还使用MySQL那会,他们自己写java程序来记录数据库的变更历史,但却不总是能记录下来:譬如一些Python脚本或手工SQL的改变.但在F1里,每个事务的变更都会用Protocol Buffer记录下来,包含变更前后的列值、对应主键和事务提交的时间戳,root表下会产生单独的ChangeBatch子表存放这些子表;当一个事物变更多个root表,还是在每个root表下子表写入对应变更值,只是多了一些连接到其他root表的指针,以表明是在同一个事务里的.由于ChangeBatch表的记录是按事务提交时间戳顺序来存放,所以很方便之后用SQL查看.
记录数据库的变更操作有什么用呢?谷歌广告业务有个批准系统,用于批准新进来的广告;这样当指定的root row发生改变,根据改变时间戳值,批准系统就能受到要批准的新广告了.同样,页面展示要实时显示最新内容,传统方法是抓取所有需要展示内容再和当前页面展示内容对比,有了ChangeBatch表,变化的内容和时间一目了然,只要替换需要改变的部分就行了.
F1客户端
F1客户端是通过ORM来与F1 Server打交道了,以前的基于MySQL实现的ORM有些常见缺点:
1.对开发人员隐藏数据库层面的执行
2.循环操作效率的低下--譬如for循环这种是每迭代一次就一个SQL
3.增加额外的操作(譬如不必要的join)
对此,谷歌重新设计了个新ORM层,这个新ORM不会增加join或者其他操作,对相关object的负载情况也是直接显示出来,同时还将并行和异步API直接提供开发人员调用.这样似乎开发人员要写更多复杂的代码,但带来整体效率的提升,还是值得的.
F1提供NoSQL和SQL两种接口,不但支持OLTP还支持OLAP;当两表Join时,数据源可以不同,譬如存储在Spanner上表可以和BigTable乃至CSV文件做join操作.
分布式SQL
既然号称NewSQL,不支持分布式SQL怎么行呢.F1支持集中式SQL执行或分布式SQL执行,集中式顾名思义就是在一个F1 Server节点上执行,常用于短小的OLTP处理,分布式SQL一般适用OLAP查询,需要用到F1 slave pool.因为的OLAP特性,一般快照事务就ok了.
请看如下SQL例子:
SELECT agcr.CampaignId, click.Region,cr.Language, SUM(click.Clicks)FROM AdClick clickJOIN AdGroupCreative agcrUSING (AdGroupId, CreativeId)JOIN Creative crUSING (CustomerId, CreativeId)WHERE click.Date ='2013-03-23'GROUP BY agcr.CampaignId, click.Region,cr.Language
可能的执行计划如下:

上图只是一个最可能的执行计划,其实一个SQL通常都会产生数十个更小的执行单位,每个单位使用有向无闭环图((DAG)来表示并合并到最顶端;你可能也发现了在上图中都是hash partition而没有range partition这种方式,因为F1为使partition更加高效所以时刻动态调整partition,而range partition需要相关统计才好partition,所以未被采用.同时partition是很随机的,并经常调整,所以也未被均匀分配到每个spanserver,但partition数目也足够多了.repartition一般会占用大量带宽,但得益于交换机等网络设备这几年高速发展,带宽已经不是问题了.除了join是hash方式,聚集也通过hash来分布式--在单个节点上通过hash分配一小段任务在内存中执行,再最后汇总.
可能受到H-Store的影响,F1的运算都在内存中执行,再加上管道的运用,没有中间数据会存放在磁盘上,这样在内存中的运算就是脱缰的马--速度飞快;但缺点也是所有内存数据库都有的--一个节点挂就会导致整个SQL失败要重新再来.F1的实际运行经验表明执行时间不远超过1小时的SQL一般足够稳定.
前面已经说过,F1本身不存储数据,由Spanner远程提供给它,所以网络和磁盘就影响重大了;为了减少网络延迟,F1使用批处理和管道技术--譬如当做一个等值join时,一次性在外表取50M或10w个记录缓存在内存里,再与内表进行hash连接;而管道技术(或者叫流水线技术)其实也是大部分数据库使用的,没必要等前一个结果全部出来再传递整个结果集给后一个操作,而是第一个运算出来多少就立刻传递给下个处理.对磁盘延迟,F1没上死贵的SSD,仍然使用机械硬盘,而机械硬盘因为就一个磁头并发访问速度很慢,但谷歌就是谷歌,这世上除了磁盘供应商恐怕没其他厂商敢说对机械磁盘运用的比谷歌还牛--谷歌以很好的颗粒度分散数据存储在CFS上,再加上良好的磁盘调度策略,使得并发访问性能几乎是线性增长的.
高效的层级表之间join
当两个join的表是层级父子关系时,这时的join就非常高效了;请看下例:
SELECT * FROM Customer JOIN Campaign USING (CustomerId)
这这种类型的join,F1能一次性取出满足条件的所有行,如下面这样:
Customer(3)
Campaign(3,5)
Campaign(3,6)
Customer(4)
Campaign(4,2)
Campaign(4,4)
F1使用种类似merge join的cluster join算法来处理.
值得注意的是,一个父表即使包含多个子表,也只能与它的一个子表cluster join;假如两个子表A和B要join呢,那得分成两步走了:第一步就是上述的父表先和子表A做cluster join,第二步再将子表B也第一步的结果做join.
客户端的并行
SQL并行化后大大加速处理速度,但也以惊人速度产生产生运算结果,这对最后的总汇聚节点和接受客户端都是个大挑战.F1支持客户端多进程并发接受数据,每个进程都会收到自己的那部分结果,为避免多接受或少接受,会有一个endpoint标示.
Protocol Buffer的处理
Protocol Buffer既然在谷歌广泛使用着,F1岂有不支持之理?其实Protocol Buffer在F1里是被当做一等公民优先对待的,下面是个Protocol Buffer和普通数据混合查询的例子:
SELECT c.CustomerId, c.Info
FROM Customer AS c
WHERE c.Info.country_code ='US'
其中c是个表,c.Info是个Protocol Buffer数据,F1不但支持将c.Info全部取出,而且也能单独提取country_code这个字段; Protocol Buffer支持一种叫repeated fields的东东,可以看做是父表的子表,唯一区别是显式创建子表也就显式制定外键了,而repeated fields是默认含有外键;这么说还是太抽象,举个例子:
SELECT c.CustomerId, f.feature
FROM Customer AS c
PROTO JOIN c.Whitelist.feature AS f
WHERE f.status ='STATUS_ENABLED'
c是个表,c.Whitelist是Protocol Buffer数据,c.Whitelist.feature就是repeated fields了(当做c的子表);虽然看起来很奇怪c与它的Whitelist.feature做join,但把c.Whitelist.feature当做一个子表也就解释的通了.
Protocol Buffer还可以在子查询中使用,如下面例子:
SELECT c.CustomerId, c.Info,
(SELECT COUNT(*) FROM c.Whitelist.feature) nf
FROM Customer AS c
WHERE EXISTS (SELECT * FROM c.Whitelist.feature f WHERE f.status !='ENABLED')
Protocol Buffer虽然省了建子表的麻烦,却带来额外性能开销:1.即使只需要取一小段,也要获取整个Protocol Buffer,因为Protocol Buffer是被当做blob存储的;2.取得数据要经过解压、解析后才能用,这又是一笔不菲开销.
在谷歌使用规模
F1和Spanner目前部署在美国的5个数据中心里支撑Adwords业务,东西海岸各两个,中间一个;直觉上感觉3个数据中心就已经很高可用了,为什么谷歌要选择5个呢?假如只部署在3个数据中心,一个挂了后剩余两个必须不能挂,因为commit成功在Paxos协议里需要至少2节点;但如果第二个节点又挂了此时就真的无法访问了,为了高可用,谷歌选择了5个数据中心节点.
东海岸有个数据中心叫做preferred leader location,因为replica的Paxos leader优先在这个数据中心里挑选.而在Paxos协议里,read和commit都要经过leader,这就必须2个来回,所以客户端和F1 Server最好都在leader location这里,有助降低网络延迟.
性能
F1的读延迟通常在510ms,事务提交延迟高些50150ms,这些主要是网络延迟;看起来是很高,但对于客户端的总体延迟,也才200ms左右,和之前MySQL环境下不相上下,主要是新ORM避免了以前很多不必要的其他开销.
有些非交互式应用对延迟没太高要求,这时就该优化吞吐量了.尽量使用不跨directory的小事务有助于分散从而实现并行化,所以F1和Spanner的写效率是很高的.其实不光写效率高,查询也很迅速,单条简单查询通常都能在10ms内返回结果,而对于非常复杂的查询,得益于更好的并发度,也通常比之前MySQL的时候快.
之前MySQL的查询数据都是不压缩存储在磁盘上,磁盘是瓶颈,而在F1里数据都是压缩的,虽然压缩解压过程带来额外CPU消耗,但磁盘却不在是瓶颈,CPU利用率也更高,以CPU换空间总体还是值得的.
结尾
可以看到F1完善了Spanner已有的一些分布式特性,成为了分布式的关系型数据库,也即炒的火热的NewSQL;但毕竟谷歌没公布具体实现代码,希望尽早有对应开源产品面世可以实际把玩下.
参考资料
F1 - The Fault-Tolerant Distributed RDBMS Supporting Google's Ad Business
F1: A Distributed SQL Database That Scales