摘要: 只有掌握了Java的高级特性,这门语言才算真正地登堂入室。本文将带领大家一同了解Java语言的三个常用的高级特性——泛型、反射和注解。
数十款阿里云产品限时折扣中,赶紧点击这里,领劵开始云上实践吧!
本次直播视频精彩回顾,戳这里!
专家简介:
澳明,阿里巴巴高级开发工程师,来自于阿里巴巴研发效能事业部-研发平台-代码智能化团队。
以下内容根据演讲嘉宾视频分享以及PPT整理而成。
本次的分享主要围绕以下三个方面:
一、泛型介绍
二、反射机制
三、注解的使用
一、泛型介绍
在日常编程的过程中,泛型在这三个特性之中使用频率是最高的。”泛型”一词中的泛字可以理解为泛化的意思,即由具体的、个别的扩大为一般的。Oracle对泛型的官方定义是:泛型类型是通过类型参数化的泛型类或接口。一言以蔽之,泛型就是通过类型参数化,来解决程序的通用性设计和实现的若干问题。
Java泛型是1.5版本后引入的特性,它主要被用于解决三类问题:
1、编译器类型检查

例如上图中的实例1设计了一个简单的Box类,在其中定义了一个private的object的属性,同时定义了get()和set()两个行为,其中set()用于保存object到Box内,set()用于获取Box中的object对象。从抽象的角度看,Box类抽象了一个用于在盒子中存放物品对象和存取的行为,存取的方法接受或者返回Object类型的对象。在这个抽象的基础上,可以存放除原始类型外任意类型的对象,Object类型的声明体现了面向对象中继承的理念。
在实例2中,实现了不同业务场景下对Box的使用方式。其中列举了两种不同的业务场景,场景一需要在Box中存放String类型的对象,场景二需要在Box中存放Integer类型的对象,这种情况下,在实际开发时,场景二中很有可能会错误地传入一个String对象,导致运行时错误的发生,而这正是因为Box可以被只有传入任意类型的对象导致的,这种情况在集合类操作时尤为突出。例如实例3中的情况:
首先声明了一个List类型的boxes对象,其中存放了两个对象,一个是String类型的“aaaaa”,另一个是Integer类型的11111。在业务场景一下,使用者认为boxes中存放的所有对象都是String类型的,因此在取出第二个对象并进行类型转换的时候就发生了错误。这种情况往往让使用者十分迷惑,明明编译时没有问题,但是在运行时却产生了异常。也就是说,在这种面向对象的抽象过程中,无法通过编译来验证类型该如何进行使用。
那么泛型是如何解决这类问题的呢?

Oracle意识到了上述的问题,在引入泛型之后,通过将代码中的“public class Box”更改为“public class Box”来创建泛型类型的声明,而这个声明的背后实质上是引入了可以在类中任何地方使用的类型变量T。如实例4中所示:可以看到,除了新增的泛型类型声明外,所有在原来代码中出现的Object都被类型变量T所替换。
乍一看类型变量这个词,感觉有点晦涩难懂,但其实如果仔细思量一番会发现它其实并不难理解,上面的实例4可以理解为“在使用泛型时,可以将类型参数T传递给Box类型本身”,结合Oracle给出的官方定义“泛型的本质是类型参数化”会有更深的理解。
在实例5中,在对象声明和初始化的时候,都指定了类型参数T,在场景一种,T为String;在场景二中,T为Integer。这样,在场景二中向IntegerBox中传入String类型的数据“aaaaa”时,程序会报错。实例6中的泛型集合对象的操作也与之类似,在声明了一个List的boxes对象之后,如果向boxes中传入Integer对象11111,程序会报错。
可以看到,通过对于泛型的使用,之前的多业务场景中的问题都得到了解决,因为现在在编译阶段就可以解决之前类型不匹配的问题,而不用等到运行时才暴露问题,只要合理使用泛型,就能在很大程度上规避此类风险。对于泛型的使用,这种参数化类型的作用表面上看是声明,背后其实是约定。
2、强制类型转换
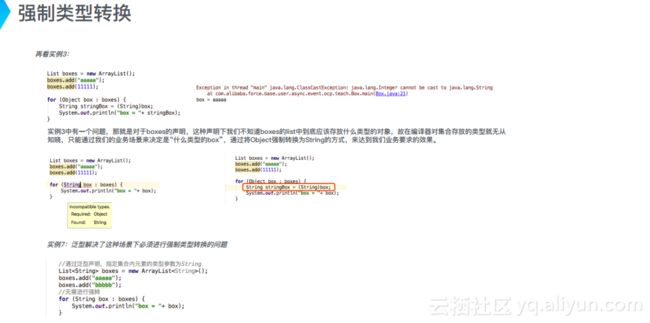
再回顾一下实例3,在List类型的boxes对象中存放了两个对象,分别是String类型的“aaaaa”和Integer类型的11111。其中存在一个问题,在对于boxes的声明中,使用者不知道boxes的list中到底应该存放什么类型的对象,而编译器也不知道集合存放的数据类型,只能通过实际的业务场景来决定这个box是什么类型,采用将Object强制转换成String的方式,来达到业务要求的效果。
在使用泛型之后,解决了这种场景下必须进行强制类型转换的问题。如实例7中,通过泛型声明,指定集合内元素的类型参数为String类型,这样编译器就直接知晓了元素的类型,而无需依靠实际的业务逻辑进行转换,从而解决了这类类型强制转换的问题。
3、可读性和灵活性

泛型除了能进行编译器类型检查和规避类型强制转换外,还能有效地提高代码的可读性。对于实例3,如果不使用泛型,当一个不清楚业务场景的人在对集合进行操作时,无法知道list中存储的是什么类型的对象,如果使用了泛型,就能够通过其类型参数判断出当前的业务场景,也增加了代码的可读性,同时也可以大胆地在抽象继承的基础上进行开发了。
泛型使用上的灵活性体现在很多方面,因为它本身实质上就是对于继承在使用上的一种增强。因为泛型在具体工作时,当编译器在编译源码的时候,首先要进行泛型类型参数的检查,检查出类型不匹配等问题,然后进行类型擦除并同时在类型参数出现的位置插入强制转换指令,从而实现泛型。
除了上述的基础用法之外,泛型还有几种特殊的高阶用法:

通配符的设计存在一定的场景,例如在使用泛型后,首先声明了一个Animal的类,而后声明了一个继承自Animal类的Cat类,显然Cat类是Animal类的子类,但是List却不是List的子类型,而在程序中往往需要表达这样的逻辑关系。为了解决这种类似的场景,在泛型的参数类型的基础上新增了通配符的用法,具体来说有三种用法:、、。其中前两者被称为限定通配符,被称为非限定通配符。
1、 上界通配符
上界通配符顾名思义,表示的是类型的上界(包含自身),因此通配的参数化类型可能是T或T的子类。正因为无法确定具体的类型是什么,add方法受限(可以添加null,因为null表示任何类型),但可以从列表中获取元素后赋值给父类型。如上图中的第一个例子,第三个add()操作会受限,原因在于List和List是List的子类型。
2、 下界通配符
下界通配符表示的是参数化类型是T的超类型(包含自身),层层至上,直至Object,编译器无从判断get()返回的对象的类型是什么,因此get()方法受限。但是可以进行add()方法,add()方法可以添加T类型和T类型的子类型,如第二个例子中首先添加了一个Cat类型对象,然后添加了两个Cat子类类型的对象,这种方法是可行的,但是如果添加一个Animal类型的对象,显然将继承的关系弄反了,是不可行的。
3、 无界通配符
在理解了上界通配符和下界通配符之后,其实也自然而然的理解了无界通配符。无界通配符用表示,?代表了任何的一种类型,能代表任何一种类型的只有null(Object本身也算是一种类型,但却不能代表任何一种类型,所以List和List的含义是不同的,前者类型是Object,也就是继承树的最上层,而后者的类型完全是未知的)。
二、反射机制
反射是Java语言本身具备的一个重要的动态机制。用一句话来解释反射的定义:自控制,自描述。即通过反射可以动态的获取类、属性、方法的信息,也能构造对象并控制对象的属性和行为。

上图中有一个Apple类,它有两个构造器、一个属性和get()、set()两个行为。在左侧的“自描述”中主要是尝试在动态的过程中借助反射获取Apple类的构造器信息和对应的参数个数、类的属性信息和类的方法信息。其中有一个Class类型,它可以产生Class对象被ClassLoader加载,从而在jvm中实现对它的调用。在这段程序中,打印了一些类的信息、类的属性信息和类的方法信息。在右侧的“自控制”的代码中,实现了在运行的过程中创建了一些对象并触发这个对象的一些行为,最后还尝试对对象的属性进行赋值。反射的基本使用方法较为简单,但是这种机制却增强了Java语言的灵活性。

如上图所示,非反射的Java类的大致运行流程是:编写源文件Apple.java,然后编译器将其编译成字节码文件Apple.class,最后加载到jvm中并运行。而采用反射的方式时,编译器一开始对其类型(编译类型和动态类型)是一无所知的,只有在运行过后,编译器才知道其真正的类型。
反射的优势主要在于两点:1、在一些场景中,这种“未知类型”实际上大大增强了程序运行时的灵活性,但是其性能会有一些损耗;2、对于对象的类型可以在运行时判断,这样的特性实质上是对多态极大地增强,进一步地将上层的抽象与下层的具体实现进行解耦。
这两点在JDBC Driver中体现的非常明显,例如上图中的实例中,JDBC的驱动加载方式是通过反射机制实现的,从而保证运行时可以动态选择要加载的驱动程序,程序灵活性大大增强。另外,JDBC只是设计了驱动需要实现的接口,并不关心驱动厂商的个数和实现方式,只要安装统一的规范即可,至于类型的判断和具体方法的触发,交给运行期动态判断即可,这种反射机制的使用淋漓尽致的体现了多态,并且降低了类与类之间的耦合度。
三、注解的使用
注解是在1.5版本引入的,现在已经成为日常程序开发中非常重要的一部分。注解是一种元数据,本身没有任何作用,如果要有,必须依附在具体的对象上,在日常使用中最常见的两个注解是@Override和@Deprecated。
先不考虑注解具体的概念、用法和如何工作等问题,注解与“标签”的概念十分相似,@Override可以理解为在方法上添加了一个标签,其代表的就是“这是一个继承关系中,子类已经重写的方法。”更进一步理解,这个标签在某个方法上加上之后,如果父类中没有该方法,那么在编译的时候就会报错,而且可以解决在继承场景下一些不留心将方法名拼错的情况,同时增强了一些程序的可读性。

如上图所示,同样以@Override为例,对注解进行进一步的提取和抽象。具体抽象出了四个方面:首先在作用域方面,它只能作用于子类重写的方法上;其次在生命周期方面,注解只是在编译时进行检查,在编译结束后便没有了任何作用;除此之外,在文档支持方面,为例解决可读性的问题,设计了@Documented的注解,用来表示注解的说明注释是否包含在JavaDoc中;在层级结构设计方面,设计了@inherited用来表示注解是否可以被子类继承。

在上图中定义了一个苹果描述注解,包含了@Target、@Retention、@Inherited和@Documented四个注解,表示它生命周期是程序运行的声明周期、可以被子类继承、文档可以被包含。在设计出这个注解之后,可以将其用在前文中的Apple实例上,如图中在类和方法上各添加了一个注解,在添加完后,便可以配合反射看到注解的效果,这样可以更好的加强其自描述的能力和配置的灵活性。
本文作者:汪星人1997
阅读原文
本文为云栖社区原创内容,未经允许不得转载。