第一次接触Kafka和Spark,也没有前期去铺垫什么理论,直接上手,踩了一些坑,但现在再来过程会很快很简单。
先声明下,我的搭建环境是Ubuntu
1. 安装Kafka,5分钟
还是老规矩,参考官网,并按照官网说的去启动kafka的服务。这个过程只需要5分钟。
https://kafka.apache.org/quickstart
2. 安装Spark,5分钟
官网下载https://spark.apache.org/downloads.html最新的包
wget http://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.3/spark-2.4.3-bin-hadoop2.7.tgz
tar xvf spark-2.4.3/spark-2.4.3-bin-hadoop2.7.tgz
启动spark
./spark_shell
3. 安装 Fluent-bit,并配置日志同时采集到Kafka和ES,5分钟
依然参照官网,这里也只需要3分钟左右:https://fluentbit.io/documentation/0.13/installation/ubuntu.html
安装完毕后,到/etc/td-agent-bit下修改td-agent-bit.conf文件,最开始,这里我的input是从fluent-bit采集到的日志转发到kafka和elasticsearch
[INPUT]
Name forward
Listen 0.0.0.0
Port 24224
[OUTPUT]
Name kafka
Match *
Brokers localhost:9092
Topics messages
[OUTPUT]
Name es
Match *
Host localhost
Port 9200
Index fluentbit-gw
Type docker
后来测试发现,这种方式的日志会被不断的从头到尾的重复采集,不符合我的期望,我期望的是只得到最新的日志信息,而不是从头再拿一次日志,于是将[INPUT]这里改成“tail”插件来完成日志的采集工作。这里的Path是Ubuntu系统,docker容器日志的输出路径。
[INPUT]
Name tail
Path /var/lib/docker/containers/*/*-json.log
修改完毕以后需要重启服务
sudo service td-agent-bit restart
以及查看服务状态
sudo service td-agent-bit status
4. 示例: 启动一个docker服务,它的日志会被Fluent-bit采集
这里我启动了Nginx的docker服务来验证。这里给容器打一个tag标签,方便后面spark过滤使用。
docker run --name nginx --log-opt tag="nginx-service" -p 8081:80 -d nginx
这样日志信息就会被送往到kafka和es了,通过kibana查看数据
docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" --name elasticsearch docker.elastic.co/elasticsearch/elasticsearch:6.7.1
docker run --link elasticsearch:elasticsearch -p 5601:5601 -e "elasticsearch.hosts=http://elasticsearch:9200" --name kibana docker.elastic.co/kibana/kibana:6.7.1

5. Java完成Spark消费和监控Kafka的日志数据
这里有一个国外大神写的demo,我做了自己需求的修改。
https://github.com/eugenp/tutorials/tree/master/apache-spark
直接拉下code,首先在pom.xml里面,增加后面需要用到的fastjson的库。
com.alibaba
fastjson
1.2.58
然后,增加自己的类LogMonitor, 来监控(打印出)错误的日志信息,并外接钉钉来触发错误日志报警。
package com.baeldung.data.pipeline;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import org.apache.http.HttpResponse;
import org.apache.http.HttpStatus;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.apache.spark.SparkConf;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import scala.Tuple2;
import java.io.IOException;
import java.util.*;
/**
* @Author You Jia
* @Date 6/4/2019 4:53 PM
*/
public class LogMonitor {
public static void main(String[] args) throws InterruptedException {
Logger.getLogger("org")
.setLevel(Level.OFF);
Logger.getLogger("akka")
.setLevel(Level.OFF);
Map kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", "139.24.217.54:9092");
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer", StringDeserializer.class);
kafkaParams.put("group.id", "use_a_separate_group_id_for_each_stream");
// kafkaParams.put("auto.offset.reset", "latest");
// kafkaParams.put("enable.auto.commit", false); //这里是个坑,如果设置为false,那么消息一直还在kafka里, so注释掉这里。
Collection topics = Arrays.asList("messages");
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local[2]");
sparkConf.setAppName("LogMonitor");
JavaStreamingContext streamingContext = new JavaStreamingContext(sparkConf, Durations.seconds(10));
JavaInputDStream> messages = KafkaUtils.createDirectStream(streamingContext, LocationStrategies.PreferConsistent(), ConsumerStrategies.Subscribe(topics, kafkaParams));
JavaDStream lines = messages.map(ConsumerRecord::value);
lines.count().print();
JavaDStream errorLines = lines.filter(x->x.toLowerCase().contains("nginx-service") && x.toLowerCase().contains("[error]"));
errorLines.print();
errorLines.foreachRDD(javaRdd ->{
long count = javaRdd.count();
System.out.println("number is " + count);
//如果10秒里有3个错误信息,就把报警信息发给钉钉
if(count >= 3){
List alertLines = Arrays.asList(javaRdd.collect().toArray());
alertLines.forEach(alertLine -> dingtalk(alertLine.toString()));
}
}
);
streamingContext.start();
streamingContext.awaitTermination();
}
//告警信息发往钉钉。
public static void dingtalk(String alertLines){
//jiangbiao dingtalk
String WEBHOOK_TOKEN = "https://oapi.dingtalk.com/robot/send?access_token=xxxxx";
HttpClient httpclient = HttpClients.createDefault();
String textMsg = "{ \"msgtype\": \"text\", \"text\": {\"content\": \"this is msg\"}}";
JSONObject testMsgJson = JSON.parseObject(textMsg);
testMsgJson.getJSONObject("text").put("content","Alert!!! " + "\r\n" + alertLines);
textMsg = testMsgJson.toString();
HttpPost httppost = new HttpPost(WEBHOOK_TOKEN);
httppost.addHeader("Content-Type", "application/json; charset=utf-8");
StringEntity se = new StringEntity(textMsg, "utf-8");
httppost.setEntity(se);
HttpResponse response = null;
try {
response = httpclient.execute(httppost);
if (response.getStatusLine().getStatusCode()== HttpStatus.SC_OK){
String result= EntityUtils.toString(response.getEntity(), "utf-8");
System.out.println(result);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
生成jar包,然后在spark的安装目录(spark-2.4.3-bin-hadoop2.7/bin)下执行
./spark-submit --class com.baeldung.data.pipeline.LogMonitor --master local[2] /home/ubuntu/apache-spark-1.0-SNAPSHOT-jar-with-dependencies.jar
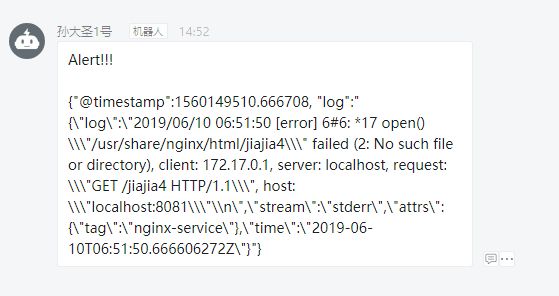
然后你会看到消息为nginx-service且是[error]的日志会被捕获并打印。示例是Error信息大于3条,于是触发报警到钉钉:
ubuntu@ubuntu:~/spark-2.4.3-bin-hadoop2.7/bin$ ./spark-submit --class com.baeldung.data.pipeline.LogMonitor --master local[2] /home/ubuntu/apache-spark-1.0-SNAPSHOT-jar-with-dependencies.jar
19/06/05 02:15:12 WARN Utils: Your hostname, ubuntu resolves to a loopback address: 127.0.1.1; using 139.24.217.54 instead (on interface enp0s17)
19/06/05 02:15:12 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
19/06/05 02:15:13 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
-------------------------------------------
Time: 1560149520000 ms
-------------------------------------------
{"@timestamp":1560149498.468915, "log":"{\"log\":\"2019/06/10 06:51:38 [error] 6#6: *17 open() \\\"/usr/share/nginx/html/jiajia1\\\" failed (2: No such file or directory), client: 172.17.0.1, server: localhost, request: \\\"GET /jiajia1 HTTP/1.1\\\", host: \\\"localhost:8081\\\"\\n\",\"stream\":\"stderr\",\"attrs\":{\"tag\":\"nginx-service\"},\"time\":\"2019-06-10T06:51:38.468823865Z\"}"}
{"@timestamp":1560149503.747338, "log":"{\"log\":\"2019/06/10 06:51:43 [error] 6#6: *17 open() \\\"/usr/share/nginx/html/jiajia2\\\" failed (2: No such file or directory), client: 172.17.0.1, server: localhost, request: \\\"GET /jiajia2 HTTP/1.1\\\", host: \\\"localhost:8081\\\"\\n\",\"stream\":\"stderr\",\"attrs\":{\"tag\":\"nginx-service\"},\"time\":\"2019-06-10T06:51:43.747309379Z\"}"}
{"@timestamp":1560149506.673414, "log":"{\"log\":\"2019/06/10 06:51:46 [error] 6#6: *17 open() \\\"/usr/share/nginx/html/jiajia3\\\" failed (2: No such file or directory), client: 172.17.0.1, server: localhost, request: \\\"GET /jiajia3 HTTP/1.1\\\", host: \\\"localhost:8081\\\"\\n\",\"stream\":\"stderr\",\"attrs\":{\"tag\":\"nginx-service\"},\"time\":\"2019-06-10T06:51:46.673326784Z\"}"}
{"@timestamp":1560149510.666708, "log":"{\"log\":\"2019/06/10 06:51:50 [error] 6#6: *17 open() \\\"/usr/share/nginx/html/jiajia4\\\" failed (2: No such file or directory), client: 172.17.0.1, server: localhost, request: \\\"GET /jiajia4 HTTP/1.1\\\", host: \\\"localhost:8081\\\"\\n\",\"stream\":\"stderr\",\"attrs\":{\"tag\":\"nginx-service\"},\"time\":\"2019-06-10T06:51:50.666606272Z\"}"}
number is 4
{"errcode":0,"errmsg":"ok"}
{"errcode":0,"errmsg":"ok"}
{"errcode":0,"errmsg":"ok"}
{"errcode":0,"errmsg":"ok"}
这段代码只是基本示例。
基本过程就是酱紫。
后面还是要恶补一下理论。