Training spaCy’s Statistical Models训练spaCy模型
This guide describe show to train new statistical models for spaCy's part-of-speech tagger, named entity recognizer and dependency parser. Once the model is trained, you can then save and load it.
本指南介绍如何训练新的spaCy模型:词性标注器,NER和依存句法分析模型。模型训练完成后可以存储和加载。
Training basics 训练基础
spaCy's models are statistical and every "decision" they make – for example, which part-of-speech tag to assign, or whether a word is a named entity – is a prediction. This prediction is based on the examples the model has seen during training. To train a model, you first need training data – examples of text, and the labels you want the model to predict. This could be a part-of-speech tag, a named entity or any other information.
spaCy的模型是统计学的,作出的每一个“判别”都是预测,例如:词性标注,或者是否命名实体。其预测基于模型在训练过程中见过的样本。训练一个模型,首先需要训练数据(文本样本),以及希望模型预测出的标记。可以是词性标签,命名实体或其他信息。
The model is then shown the unlabelled text and will make a prediction. Because we know the correct answer, we can give the model feedback on its prediction in the form of an error gradient of the loss function that calculates the difference between the training example and the expected output. The greater the difference, the more significant the gradient and the updates to our model.
之后,模型会找出未标记的文本并作出预测。因为我们知道真确答案,就可以给模型计算输出的错误结果反馈其与预期输出的偏差。差异越大,对模型的提升更重要。
Training data: Examples and their annotations. 样本及其注释。
Text: The input text the model should predict a label for. 模型应预测出的标记内容。
Label: The label the model should predict. 模型应预测出的标记。
Gradient: Gradient of the loss function calculating the difference between input and expected
output. 损失函数计算的输入值和预期输出之间的差异度

When training a model, we don't just want it to memorise our examples – we want it to come up with theory that can be generalised across other examples. After all, we don't just want the model to learn that this one instance of "Amazon" right here is a company – we want it to learn that "Amazon", in contexts like this, is most likely a company. That's why the training data should always be representative of the data we want to process. A model trained on Wikipedia, where sentences in the first person are extremely rare, will likely perform badly on Twitter. Similarly, a model trained on romantic novels will likely perform badly on legal text.
训练模型时,不仅仅希望其记住样本,还希望模型能够进行广义的跨样本推测。毕竟我们不仅仅希望模型学到Amazon在这里公司这么一个实例,还希望它能够学到Amazon在这样的上下文语境中,最可能是一个公司。这就是为什么训练数据对于要处理的数据来说应该具有代表性。用维基数据训练的模型,在句子中第一人称极为罕见,那么该模型在Twitter中很可能会表现不佳。同样的,用言情小说训练出的模型,在法律文本中也很可能表现不佳。
This also means that in order to know how the model is performing, and whether it's learning the right things, you don't only need training data – you'll also need evaluation data. If you only test the model with the data it was trained on, you'll have no idea how well it's generalising. If you want to train a model from scratch, you usually need at least a few hundred examples for both training and evaluation. To update an existing model, you can already achieve decent results with very few examples – as long as they're representative.
这也意味着为了了解模型的效果如何,是否学习了正确的内容,不仅需要训练数据,还需要评估数据。如果只用其训练数据进行测试,不会知道其表现如何。如果想从零开始训练模型,通常需要至少几百个训练和评估样本。要更新一个已有模型,可以用很少的样本(只要具有代表性)即可获得好的效果。
How do I get training data? 如何获取训练数据
Collecting training data may sound incredibly painful – and it can be, if you're planning a large-scale annotation project. However, if your main goal is to update an existing model's predictions – for example, spaCy's named entity recognition –the hard part is usually not creating the actual annotations. It's finding representative examples and extracting potential candidates. The good news is, if you've been noticing bad performance on your data, you likely already have some relevant text, and you can use spaCy to bootstrap a first set of training examples. For example, after processing a few sentences, you may end up with the following entities, some correct, some incorrect.
收集训练数据可能听起来非常的痛苦(而且是如果计划大规模的标注目标的话,确实痛苦)。然而,如果主要目标是升级已有模型的预测能力,例如:spaCy的NER,最难的部分通常不是创建实际的标注。好消息是,如果曾注意到过数据的不良效果,那么看来已经有了一些相关文本,就可以用spaCy来构建第一组训练样本。例如:处理一批段落后,可以以一些正确和不正确的实体结束。
HOW MANY EXAMPLES DO I NEED? 需要多少样本
As a rule of thumb, you should allocate at least 10% of your project resources to creating training and evaluation data. If you're looking to improve an existing model, you might be able to start off with only a handful of examples. Keep in mind that you'll always want a lot more than that for evaluation – especially previous errors the model has made. Otherwise, you won't be able to sufficiently verify that the model has actually made the correct generalisations required for your use case.
按经验估计,应该用项目数据资源的10%来创建训练和评估数据。如果要升级已有模型,或许可以仅从极少数样本开始。要记住始终需要更多评估,特别是模型之前发生过的错误。否则,不能够充分验证模型确实对指定情况做出了正确处理。

Alternatively, the rule-based matcher can be a useful tool to extract tokens or combinations of tokens, as well as their start and end index in a document. In this case, we'll extract mentions of Google and assume they're an ORG.
或者,提取tokens或tokens组及其在文档中开始和结束的位置时,基于规则的匹配是比较有用的。下例中是对涉及Google的提取,并识别为ORG的结果。
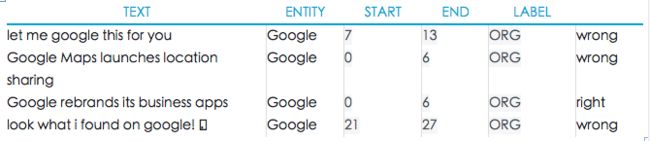
Based on the few examples above, you can already create six training sentences with eight entities in total. Of course, what you consider a "correct annotation" will always depend on what you want the model to learn. While there are some entity annotations that are more or less universally correct –like Canada being a geopolitical entity – your application may have its very own definition of the NER annotation scheme.
基于上述样例,已经能够创建用8个实体创建6条训练语句了。当然,想要“正确的注释”,始终取决于想要模型学习的是什么。虽然有些实体很容易正确标注(例如Canada为地理实体),应用还是可以有自己私有的NER标注体系定义。
样例:
train_data = [
("Uber blew through $1 million a week", [(0, 4, 'ORG')]),
("Android Pay expands to Canada", [(0, 11, 'PRODUCT'), (23,30, 'GPE')]),
("Spotify steps up Asia expansion", [(0, 8, "ORG"),(17, 21, "LOC")]),
("Google Maps launches location sharing", [(0, 11,"PRODUCT")]),
("Google rebrands its business apps", [(0, 6,"ORG")]),
("look what i found on google! ", [(21, 27,"PRODUCT")])]
TIP: TRY THE PRODIGY ANNOTATION TOOL
If you need to label a lot of data, check out Prodigy, a new, active learning-powered annotation tool we've developed. Prodigy is fast and extensible, and comes with a modern web application that helps you collect training data faster. It integrates seamlessly with spaCy, pre-selects the most relevant examples for annotation, and lets you train and evaluate ready-to-use spaCy models.
ExplosionAI的自推广告:试试标注工具Prodigy(https://prodi.gy/)
确实是个很牛的东西,不过收费。是Explosion自己做的收费工具,必要情况下买吧,个人版$349,商业版$449。
Training with annotations 用标注训练
The GoldParse object collects the annotated training examples, also called the gold standard. It's initialised with the Doc object it refers to, and keyword arguments specifying the annotations, like tags or entities. Its job is to encode the annotations, keep them aligned and create the C-level data structures required for efficient access. Here's an example of a simple GoldParse for part-of-speech tags:
GoldParser对象收集了标注训练样本,也叫goldstandard。其以Doc对象进行初始化,并且关键词参数指定了标注,比如标签和实体。其工作是将标注进行编码,对齐并创建高效访问需要的C级数据结构。
vocab = Vocab(tag_map={'N': {'pos':'NOUN'}, 'V': {'pos': 'VERB'}})
doc = Doc(vocab, words=['I', 'like','stuff'])
gold = GoldParse(doc, tags=['N', 'V','N'])
Using the Doc and its gold-standard annotations, the model can be updated to learn a sentence of three words with their assigned part-of-speech tags. The tag map is part of the vocabulary and defines the annotation scheme. If you're training a new language model, this will let you map the tags present in the treebank you train on to spaCy's tag scheme.
使用Doc对象及其gold-standard标注,模型可以用其词性标签升级到学习三字短语。tag map是词汇和定义标注体系的一部分。如果训练新语言模型,tag map会以spaCy标签体系映射训练的treebank里的标签。
doc = Doc(Vocab(), words=['Facebook','released', 'React', 'in', '2014'])
gold = GoldParse(doc, entities=['U-ORG','O', 'U-TECHNOLOGY', 'O', 'U-DATE'])
The same goes for named entities. The letters added before the labels refer to the tags of the BILUO scheme – O is a token outside an entity, U an single entity unit, B the beginning of an entity, I a token inside an entity and L the last token of an entity.
命名实体也同样,参照BILUO标签体系在标记之前加一个字母(B/I/L/U/O)。
BILUO说明:
TAG DESCRIPTION
BEGIN The first token of a multi-tokenentity.
IN An inner token of a multi-tokenentity.
LAST The final token of a multi-tokenentity.
UNIT A single-token entity.
OUT A non-entity token.
WHYBILUO, NOT IOB? 为啥是BILUO而不是IOB
There are several coding schemes for encoding entity annotations as token tags. These coding schemes are equally expressive, but not necessarily equally learnable. Ratinov and Roth showed that the minimal Begin, In, Out scheme was more difficult to learn than the BILUO scheme that we use, which explicitly marks boundary tokens.
有很多实体标注为标签的编码体系,这些编码体系其实效果都一样,但是可学习型不同。Ratinov和Roth表示最小的IOB(In/Out/Begin)体系在学习是比BILUO体系要复杂困难,因为BILUO明确标识了边界tokens。
Training data: The training examples.
Text and label: The current example.
Doc: A Doc object created from theexample text.
GoldParse: A GoldParse object of the Docand label.
nlp: The nlp object with the model.
Optimizer: A function that holds statebetween updates.
Update: Update the model's weights.

Of course, it's not enough to only show a model a single example once. Especially if you only have few examples, you'll want to train for a number of iterations. At each iteration, the training data is shuffled to ensure the model doesn't make any generalisations based on the order of examples. Another technique to improve the learning results is to set a dropout rate, a rate at which to randomly"drop" individual features and representations. This makes it harder for the model to memorise the training data. For example, a 0.25 dropout means that each feature or internal representation has a 1/4 likelihood of being dropped.
当然,一次只有一个模型一个独立样本。特别是如果只有少量样本的时候,想要训练一堆迭代器。每个迭代器都清洗训练数据,以确保模型不基于样本顺序作任何输出。另一个提升学习结果的技术是设置流失率,一个随机“扔下”个体特征和表述的频率。这样的话模型很难做到记住训练数据。例如:0.25的流失率意味着每个特征或内部表述有1/4的可能性被扔掉。
begin_training() : Start the training and return an optimizer function to update the model's weights. Can take an optional function converting the training data to spaCy's training format.
update() : Update the model with the training example and gold data.
to_disk() : Save the updated model to adirectory.
EXAMPLE TRAINING LOOP
optimizer = nlp.begin_training(get_data)
for itn in range(100):
random.shuffle(train_data)
for raw_text, entity_offsets in train_data:
doc = nlp.make_doc(raw_text)
gold = GoldParse(doc, entities=entity_offsets)
nlp.update([doc], [gold], drop=0.5, sgd=optimizer)
nlp.to_disk('/model')
nlp.update函数有以下参数:
docs: Doc objects. The update method takes a sequence of them, so you can batch up your training examples. Alternatively, you can also pass in a sequence of raw texts.
Golds: GoldParse objects. The update method takes a sequence of them, so you can batch up your training examples. Alternatively, you can also pass in a dictionary containing the annotations.
Drop: Dropout rate. Makes it harder for the model to just memorise the data.
Sgd: An optimizer, i.e. a callable to update the model's weights. If not set, spaCy will create a new one and save it for further use.
Instead of writing your own training loop, you can also use the built-in train command, which expects data in spaCy's JSON format. On each epoch, a model will be saved out to the directory. After training, you can use the package command to generate an installable Python package from your model.
也可以直接使用内置的train命令进行训练,需要数据是spaCy要求的JSON格式。每次,一个模型会被存储于目录中。训练后,可以用package命令生成模型的python安装包。
python -m spacy convert /tmp/train.conllu/tmp/data
python -m spacy train en /tmp/model/tmp/data/train.json -n 5
Simple training style
Instead of sequences of Doc and GoldParse objects, you can also use the "simple training style" and pass raw texts and dictionaries of annotations to nlp.update .The dictionaries can have the keys entities, heads, deps, tags and cats. This is generally recommended, as it removes one layer of abstraction, and avoids unnecessary imports. It also makes it easier to structure and load your training data.
可以使用simpletrain style替代Doc和GoldParse对象序列,然后把原始文本和标注字典传递给nlp.update。字典可以含有关键实体,heads,deps,tags和cats。通常推荐此做法,因为它去除了一个抽象层,而且避免了不必要的import。它也简化了构建和加载训练数据。
EXAMPLE ANNOTATIONS
{
'entities': [(0, 4, 'ORG')],
'heads': [1, 1, 1, 5, 5, 2, 7, 5],
'deps': ['nsubj', 'ROOT', 'prt', 'quantmod', 'compound', 'pobj', 'det','npadvmod'],
'tags': ['PROPN', 'VERB', 'ADP', 'SYM', 'NUM', 'NUM', 'DET', 'NOUN'],
'cats': {'BUSINESS': 1.0}
}
SIMPLE TRAINING LOOP
TRAIN_DATA = [
("Uber blew through $1 million a week", {'entities': [(0, 4,'ORG')]}),
("Google rebrands its business apps", {'entities': [(0, 6,"ORG")]})]
nlp = spacy.blank('en')
optimizer = nlp.begin_training()
for i in range(20):
random.shuffle(TRAIN_DATA)
for text, annotations in TRAIN_DATA:
nlp.update([text], [annotations], sgd=optimizer)
nlp.to_disk('/model')
The above training loop leaves out a few details that can really improve accuracy – but the principle really is that simple. Once you've got your pipeline together and you want to tune the accuracy, you usually want to process your training examples in batches, and experiment with minibatch sizes and dropout rates, set via the drop keyword argument. See the Language and Pipe API docs for available options.
上述训练环节遗漏了一些可以真正提升精度的细节,但是原理就是那么简单。有时整理好pipline就想调整精度,想要批量处理训练样本就试试minibatch,大小和流失率呢可以通过drop参数来设置。参见Languige和pip API文档。
Training the named entity recognizer 训练命名实体识别(NER)
All spaCy models support online learning, so you can update a pre-trained model with new examples. You'll usually need to provide many examples to meaningfully improve the system — a few hundred is a good start, although more is better.
spaCy的所有模型都支持在线学习,所以你可以用新样本更新预训练模型。通常需要提供很多样本来提升系统,几百个起步,多多益善。
You should avoid iterating over the same few examples multiple times, or the model is likely to"forget" how to annotate other examples. If you iterate over the same few examples, you're effectively changing the loss function. The optimizer will find a way to minimize the loss on your examples, without regard for the consequences on the examples it's no longer paying attention to. One way to avoid this "catastrophic forgetting" problem is to "remind"the model of other examples by augmenting your annotations with sentences annotated with entities automatically recognised by the original model.Ultimately, this is an empirical process: you'll need to experiment on your data to find a solution that works best for you.
应该避免同一批样本的多次迭代,不然模型可能会“忘记”如何标注其他样本的。迭代同一批样本,会有效改变损失率。优化器会为样本找到最小化损失的方法,不顾后果的忽视样本。避免这种“灾难性遗忘”问题的方法是通过用普通模型自动识别实体的段落标注增加标注,来提醒其他样本的模型,最后,经验之谈:需要数据试验找到最好的解决方案。
TIP:CONVERTING ENTITY ANNOTATIONS 转换实体标注
You can train the entity recognizer with entity offsets or annotations in the BILUO scheme. The spacy.gold module also exposes two helper functions to convert offsets to BILUO tags, and BILUO tags to entity offsets.
可以用实体集或BILUO标注体系来训练实体识别。spaCy.gold模块也有两个函数可以进行实体集和BILUO标签的相互转换。
Updating the Named Entity Recognizer 更新NER
This example shows how to update spaCy's entity recognizer with your own examples, starting off with an existing, pre-trained model, or from scratch using a blank Language class. To do this, you'll need example texts and the character offsets and labels of each entity contained in the texts.
下例为如何用自己的样本更新spaCy的实体识别,基于已有的预训练模型或以空白语言类从零开始。为此,需要样本文本和字符集以及文本中每个实体的标记。
spacy/examples/training/train_ner.py
Step by step guide
1、Load the model you want to start with, or create an empty model using spacy.blank with the ID of your language. If you're using a blank model, don't forget to add the entity recognizer to the pipeline. If you're using an existing model, make sure to disable all other pipeline components during training using nlp.disable_pipes . This way, you'll only be training the entity recognizer.
2、Shuffle and loop over the examples. For each example, update the model by calling nlp.update ,which steps through the words of the input. At each word, it makes a prediction. It then consults the annotations to see whether it was right. If it was wrong, it adjusts its weights so that the correct action will score higher next time.
3、Save the trained model using nlp.to_disk .
4、Test the model to make sure the entities in the training data are recognised correctly.
1、加载模型,或者用spacy.blank和语言ID创建一个空的模型。如果使用空模型,别忘了在pipline中加入实体识别。如果使用已有模型,确认在训练时关闭其他的pipline组件(nlp.disable_pips)。这个方法仅训练实体识别。
2、shuffle和loopover样本。对于每个样本,调用nlp.update来升级模型(词单步输入)。对每个词都会做一个预测。之后对比标注是否正确。如果错了,就调整比重,所以下一次得分会更高些。
3、nlp.to_disk,保存模型。
4、测试。
Training an additional entity type
This script shows how to add a new entity type ANIMAL to an existing pre-trained NER model, or an empty Language class. To keep the example short and simple, only a few sentences are provided as examples. In practice, you'll need many more — a few hundred would be a good start. You will also likely need to mix in examples of other entity types, which might be obtained by running the entity recognizer over unlabelled sentences, and adding their annotations to the training set.
下面的脚本是给已有的NER模型(或空语言类)添加一个ANIMAL的实体类型。样例为了保持简短,仅使用了很少的样本。实操中需要很多,几百个起步吧。此外,最好在样本中混入其他实体类型,以及未标记的句子,并在训练集中加入其标注。
spacy/examples/training/train_new_entity_type.py
IMPORTANTNOTE
If you're using an existing model, make sure to mix in examples of other entity types that spaCy correctly recognized before. Otherwise, your model might learn the new type, but "forget" what it previously knew. This is also referred to as the"catastrophic forgetting" problem.
如果使用已有模型,一定要在样本中加入经spaCy正确识别的其他类型实体。否则,模型可能会狗熊掰棒子,属于“灾难性遗忘”问题。
Step by step guide
1、Load the model you want to start with, or create an empty model using spacy.blank with the ID of your language. If you're using a blank model, don't forget to add the entity recognizer to the pipeline. If you're using an existing model, make sure to disable all other pipeline components during training using nlp.disable_pipes . This way, you'll only be training the entity recognizer.
2、Add the new entity label to the entity recognizer using the add_label method. You can access the entity recognizer in the pipeline via nlp.get_pipe('ner').
3、Loop over the examples and call nlp.update , which steps through the words of the input. At each word, it makes a prediction. It then consults the annotations, to see whether it was right. If it was wrong, it adjusts its weights so that the correct action will score higher next time.
4、Save the trained model using nlp.to_disk .
5、Test the model to make sure the new entity is recognised correctly.
1、加载模型,或者用spacy.blank和语言ID 创建一个空的模型。如果使用空模型,别忘了在pipline中加入实体识别。如果使用已有模型,确认在训练时关闭其他的pipline组件(nlp.disable_pips)。这个方法仅训练实体识别。
2、用add_label函数给实体识别添加新的实体标记。通过nlp.get_pip(‘ner’)可在pipline中获得实体识别。
3、loop over样本,调用nlp.update,单步输入词。对每个词都会做一个预测。之后对比标注是否正确。如果错了,就调整比重,所以下一次得分会更高些。
4、nlp.to_disk,保存模型。
5、测试模型。
Training the tagger and parser
Updating the Dependency Parser
This example shows how to train spaCy's dependency parser, starting off with an existing model ora blank model. You'll need a set of training examples and the respective heads and dependency label for each token of the example texts.
训练spaCy依存句法分析的样例,基于已有或空的模型都可以。需要一组训练样本,还有每个样本文本中的每个token的head和依存关系标记。
spacy/examples/training/train_parser.py
Step by step guide
1、Load the model you want to start with, or create an empty model using spacy.blank with the ID of your language. If you're using a blank model, don't forget to add the parser to the pipeline. If you're using an existing model, make sure to disable all other pipeline components during training using nlp.disable_pipes . This way, you'll only be training the parser.
2、Add the dependency labels to the parser using the add_label method. If you're starting off with a pre-trained spaCy model, this is usually not necessary – but it doesn't hurt either, just to be safe.
3、Shuffle and loop over the examples. For each example, update the model by calling nlp.update ,which steps through the words of the input. At each word, it makes a prediction. It then consults the annotations to see whether it was right. If it was wrong, it adjusts its weights so that the correct action will score higher next time.
4、Save the trained model using nlp.to_disk .
5、Test the model to make sure the parser works as expected.
1、加载模型,或者用spacy.blank和语言ID创建一个空的模型。如果使用空模型,别忘了在pipline中加入parser。如果使用已有模型,确认在训练时关闭其他的pipline组件(nlp.disable_pips)。这个方法仅训练parser。
2、用add_label函数为parser添加依存关系标记。用已经预训练的spaCy模型也没啥关系,无伤害。
3、shuffle和loopover样本,对于每个样本,调用nlp.update来升级模型(词单步输入)。对每个词都会做一个预测。之后对比标注是否正确。如果错了,就调整比重,所以下一次得分会更高些。
4、nlp.to_disk,保存模型。
5、测试模型。
Updating the Part-of-speech Tagger
In this example, we're training spaCy's part-of-speech tagger with a custom tag map. We start off with a blank Language class, update its defaults with our custom tags and then train the tagger. You'll need a set of training examples and the respective custom tags, as well as a dictionary mapping those tags to theUniversal Dependencies scheme.
下面的样例用自定义的tagmap训练spaCy的词性标注器。用一个空语言类来开始,再用自定义标签更新默认的,之后训练tagger。需要一组训练样本及其自定义标签,此外还要一个标签与UD体系的映射字典。
spacy/examples/training/train_tagger.py
Step by step guide
1、Load the model you want to start with, or create an empty model using spacy.blank with the ID of your language. If you're using a blank model, don't forget to add the tagger to the pipeline. If you're using an existing model, make sure to disable all other pipeline components during training using nlp.disable_pipes . This way, you'll only be training the tagger.
2、Add the tag map to the tagger using the add_label method.The first argument is the new tag name, the second the mapping to spaCy's coarse-grained tags, e.g. {'pos': 'NOUN'}.
3、Shuffle and loop over the examples. For each example, update the model by calling nlp.update ,which steps through the words of the input. At each word, it makes a prediction. It then consults the annotations to see whether it was right. If it was wrong, it adjusts its weights so that the correct action will score higher next time.
4、Save the trained model using nlp.to_disk .
5、Test the model to make sure the parser works as expected.
1、加载模型,或者用spacy.blank和语言ID创建一个空的模型。如果使用空模型,别忘了在pipline中加入tagger。如果使用已有模型,确认在训练时关闭其他的pipline组件(nlp.disable_pips)。这个方法仅训练tagger。
2、用add_label函数为tagger添加tag
map。第一个参数是新tag名,第二个是对spaCy的coarse-grained tag的映射,即{‘pos’:’NOUN’}。
3、shuffle和loopover样本,对于每个样本,调用nlp.update来升级模型(词单步输入)。对每个词都会做一个预测。之后对比标注是否正确。如果错了,就调整比重,所以下一次得分会更高些。
4、nlp.to_disk,保存模型。
5、测试模型。
Training a parser for custom semantics
spaCy's parser component can be used to be trained to predict any type of tree structure over your input text – including semantic relations that are not syntactic dependencies. This can be useful to for conversational applications, which need to predict trees over whole documents or chat logs, with connections between the sentence roots used to annotate discourse structure. For example, you can train spaCy's parser to label intents and their targets, like attributes, quality, time and locations. The result could look like this:
spaCy的parser组件可以用来训练成预测输入文本中的任何树结构,包括非句法依赖的语义关系。这对于会话应用很有用,可以对整个文档或聊天记录进行树预测(用连接线连接并标注语义)。例如,可以训练spaCy的parser来标记目的及其目标,比如属性、数量、时间和位置,效果如下:

doc = nlp(u"find a hotel with good wifi")
print([(t.text, t.dep_, t.head.text) fort in doc if t.dep_ != '-'])
# [('find', 'ROOT', 'find'), ('hotel','PLACE', 'find'),
# ('good', 'QUALITY', 'wifi'), ('wifi', 'ATTRIBUTE', 'hotel')]
The above tree attaches "wifi" to "hotel" and assigns the dependency labelATTRIBUTE. This may not be a correct syntactic dependency – but in this case, it expresses exactly what we need: the user is looking for a hotel with the attribute "wifi" of the quality "good". This query can then be processed by your application and used to trigger the respective action –e.g. search the database for hotels with high ratings for their wifi offerings.
上面的树中,将wifi附给hotel,并标注依存关系标记ATTRIBUTE。这不一定是正确的依存关系,但是在这个情况下,确切表述了需要的东西:用户想要找一个wifi质量good的hotel。这个检索就会被应用处理,且出发各自的动作,即:在数据库中搜索wifi评级高的hotels。
TIP:MERGE PHRASES AND ENTITIES
To achieve even better accuracy, try merging multi-word tokens and entities specific to your domain into one token before parsing your text. You can do this by running the entity recognizer or rule-based matcher to find relevant spans, and merging them using Span.merge . You could even add your own custom pipeline component to do this automatically – just make sure to add it before='parser'.
合并短语和实体
为达到更高精度,可以在parsing文本之前将多词(字)tokens和相关实体合并为一个token。可以通过运行基于规则的匹配或实体识别来找到有关段落,然后用Span.merge合并他们。还可以添加自定义pipline组件来自动合并,注意要添加在 =’parser’前面。
The following example shows a full implementation of a training loop for a custom message parser fora common "chat intent": finding local businesses. Our message semantics will have the following types of relations: ROOT, PLACE, QUALITY,ATTRIBUTE, TIME and LOCATION.
下例是自定义一个完整的聊天内容parser的训练:查找当地商业信息。信息语义包括如下关系类型:ROOT,PLACE,QUALITY,ATTRIBUTE,TIME以及LOCATION。
spacy/examples/training/train_intent_parser.py
Step by step guide
1、Create the training data consisting of words, their heads and their dependency labels in order. A token's head is the index of the token it is attached to. The heads don't need to be syntactically correct – they should express the semantic relations you want the parser to learn. For words that shouldn't receive a label, you can choose an arbitrary placeholder, for example -.
2、Load the model you want to start with, or create an empty model using spacy.blank with the ID of your language. If you're using a blank model, don't forget to add the custom parser to the pipeline. If you're using an existing model, make sure to remove the old parser from the pipeline, and disable all other pipeline components during training using nlp.disable_pipes . This way, you'll only be training the parser.
3、Add the dependency labels to the parser using the add_label method.
4、Shuffle and loop over the examples. For each example, update the model by calling nlp.update ,which steps through the words of the input. At each word, it makes a prediction. It then consults the annotations to see whether it was right. If it was wrong, it adjusts its weights so that the correct action will score higher next time.
5、Save the trained model using nlp.to_disk .
6、Test the model to make sure the parser works as expected.
1、创建由词组成的训练数据,及其head和依存关系label。一个token的head是token归属的索引。head不要求语法准确,只需能表述出语义关系即可。对于不应有label的字词,随便找个占位符就行了,比如“-”。
2、加载模型,或者用spacy.blank和语言ID创建一个空的模型。如果使用空模型,别忘了在pipline中加入自定义parser。如果使用已有模型,确认在训练时关闭其他的pipline组件(nlp.disable_pips)。这个方法仅训练parser。
3、用add_label函数为parser添加依存关系label。
4、shuffle和loopover样本,对于每个样本,调用nlp.update来升级模型(词单步输入)。对每个词都会做一个预测。之后对比标注是否正确。如果错了,就调整比重,所以下一次得分会更高些。
5、nlp.to_disk,保存模型。
6、测试模型。
Training a text classification model
Adding a text classifier to a spaCy modelV2.0
This example shows how to train a multi-label convolutional neural network text classifier on IMDB movie reviews, using spaCy's new TextCategorizer component. The dataset will be loaded automatically via Thinc's built-in dataset loader. Predictions are available via Doc.cats .
下例是关于如何训练一个对IMDB影评进行多标签卷积神经网络的文本分类器,使用spaCy的TextCategorizer组件。数据集通过Thinc的内置数据集加载器自动加载。预测通过Doc.cats实现。
spacy/examples/training/train_textcat.py
Step by step guide
1、Load the model you want to start with, or create an empty model using spacy.blank with the ID of your language. If you're using an existing model, make sure to disable all other pipeline components during training using nlp.disable_pipes . This way, you'll only be training the text classifier.
2、Add the text classifier to the pipeline, and add the labels you want to train – for example,POSITIVE.
3、Load and pre-process the dataset, shuffle the data and split off a part of it to holdback for evaluation. This way, you'll be able to see results on each training iteration.
4、Loop over the training examples and partition them into batches using spaCy's minibatch and compounding helpers.
5、Update the model by calling nlp.update , which steps through the examples and makes a prediction.It then consults the annotations to see whether it was right. If it was wrong, it adjusts its weights so that the correct prediction will score higher next time.
6、Optionally, you can also evaluate the text classifier on each iteration, by checking how it performs on the development data held back from the dataset. This lets you print the precision, recall and F-score.
7、Save the trained model using nlp.to_disk .
8、Test the model to make sure the text classifier works as expected.
1、加载模型,或者用spacy.blank和语言ID创建一个空的模型。如果使用已有模型,确认在训练时关闭其他的pipline组件(nlp.disable_pips)。这个方法仅训练text classifier。
2、在pipline中添加textclassifier,在添加想要训练的labels,比如:POSITIVE。
3、加载预处理过的数据集,清洗数据并分离出一部分做评估。这样就能看到每个训练迭代器的结果。
4、用spaCy的minibatch等对样本进行分批反复训练
5、调用nlp.update升级模型,样本单步调试,做一个预测。之后对比标注是否正确。如果错了,就调整比重,所以下一次得分会更高些。
6、可选,还可以在每个迭代器上做评估,检查效果如何,输出precision,recall和F-score。
7、nlp.to_disk保存模型
8、测试模型。
Optimization tips and advice 优化建议
There are lots of conflicting "recipes" for training deep neural networks at the moment. The cutting-edge models take a very long time to train, so most researchers can't run enough experiments to figure out what's really going on.For what it's worth, here's a recipe that seems to work well on a lot of NLP problems:
训练深度神经网络时存在一些矛盾的方法。前端模型训练用时很长,所以多数人不能运行足够的试验来找出到底咋回事。无论怎样,这里有个方法似乎在一些NLP问题上还凑合,如下:
1、Initialise with batch size 1, and compound to a maximum determined by your data size and problem type.
2、Use Adam solver with fixed learning rate.
3、Use averaged parameters
4、Use L2 regularization.
5、Clip gradients byL2 norm to 1.
6、On small data sizes, start at a high dropout rate, with linear decay.
1、用batch size 1初始化,并赋予最大值取决于数据尺寸和问题类型。
2、用Adam solver固定学习率。
3、用平均值。
4、用L2正则化。
5、调整norm L2梯度为1。
6、小数据量,从高流失率开始线性衰减。
This recipe has been cobbled together experimentally. Here's why the various elements of the recipe made enough sense to try initially, and what you might try changing, depending on your problem.
此方法经过拼装试验,所以值得一试,再根据实际情况进行变更。
Compounding batch size
The trick of increasing the batch size is starting to become quite popular (see Smith et al., 2017). Their recipe is quite different from how spaCy's models are being trained, but there are some similarities. In training the various spaCy models, we haven't found much advantage from decaying the learning rate – but starting with a low batch size has definitely helped. You should try it out on your data, and see how you go. Here's our current strategy:
提升batchsize的手段颇受欢迎。他们的方法也和spaCy的模型训练颇有不同,但是也有很多相似。训练不同的spaCy模型时,没有发现学习率衰退有多好,反而低batchsize倒是很有用。你应该用自己的数据试试看咋样。下面是我们目前的策略:
BATCH HEURISTIC
def get_batches(train_data, model_type):
max_batch_sizes = {'tagger': 32, 'parser': 16, 'ner': 16, 'textcat': 64}
max_batch_size = max_batch_sizes[model_type]
if len(train_data) < 1000:
max_batch_size /= 2
if len(train_data) < 500:
max_batch_size /= 2
batch_size = compounding(1, max_batch_size, 1.001)
batches = minibatch(train_data, size=batch_size)
return batches
This will set the batch size to start at 1, and increase each batch until it reaches a maximum size. The tagger, parser and entity recognizer all take whole sentences as input, so they're learning a lot of labels in a single example. You therefore need smaller batches for them. The batch size for the text categorizer should be somewhat larger, especially if your documents are long.
在这里batch设置为从1开始,然后递增至最大size。tagger,parser和实体识别都以整个句子作为输入,所以他们在单样本中学到了很多labels,因此就需要给他们小一些的batch。text categorizer的batch size应该大一些,特别是面对长文档。
Learning rate, regularization and gradient clipping
By default spaCy uses the Adam solver, with default settings (learning rate 0.001, beta1=0.9, beta2=0.999). Some researchers have said they found these settings terrible on their problems – but they've always performed very well in training spaCy's models, in combination with the rest of our recipe. You can change these settings directly, by modifying the corresponding attributes on the optimizer object. You can also set environment variables, to adjust the defaults.
spaCy默认使用Adamsolver(learning rate 0.001, beta1=0.9, beta2=0.999)。有人说自己发现这样设置对于他们的问题来说很糟糕,但这些设置在spaCy模型的训练中一直表现很好,同时结合了我们其余的方法。可以直接修改这些设置,直接针对优化对象修改对应属性。也可以设置环境变量,以调整默认值。
There are two other key hyper-parameters of the solver: L2 regularization, and gradient clipping(max_grad_norm). Gradient clipping is a hack that's not discussed often, but everybody seems to be using. It's quite important in helping to ensure the network doesn't diverge, which is a fancy way of saying "fall over during training". The effect is sort of similar to setting the learning rate low.It can also compensate for a large batch size (this is a good example of how the choices of all these hyper-parameters intersect).
有其他两个solver的key超参,L2正则和gradient clipping(max_grad_norm)。Gradient clipping是一个不常讨论的hack,但是每个人似乎都在用,它对于确保网络不发散很重要,有一个有趣的说法“训练中被绊倒”。结果很多类似设置低学习率。这也可以补偿一个大的batch size(这是一个如何交叉选择所有这些超参数挺好的例子)。
Dropout rate
For small datasets, it's useful to set a high dropout rate at first, and decay it down towards amore reasonable value. This helps avoid the network immediately overfitting, while still encouraging it to learn some of the more interesting things in your data. spaCy comes with a decaying utility function to facilitate this. You might try setting:
对于小数据集,在一开始设置高流失率很有用,之后之后降低到一个更合理的值。这样有助于从数据中持续学习更多靠谱东西时避免网络很快过拟合。spaCy自带一个decaying工具函数来搞这个事情,可以试试:
from spacy.util import decaying
dropout = decaying(0.6, 0.2, 1e-4)
You can then draw values from the iterator with next(dropout), which you would pass to the drop keyword argument of nlp.update . It's pretty much always a good idea to use at least some dropout. All of the models currently use Bernoulli dropout, for no particularly principled reason – we just haven't experimented with another scheme like Gaussian dropout yet.
之后可以从迭代器中用next(dropout)写参数值了,传递给nlp.update的drop参数。多一些dropout几乎一直是个好主意。所有模型目前都使用Bernoulli dropout,没什么特殊原因,我们只是还没有用其他体系做过试验,比如Gaussian dropout之类的。
Parameter averaging
The last part of our optimization recipe is parameter averaging, an old trick introduced by Freundand Schapire (1999), popularised in the NLP community by Collins (2002), and explained in more detail by Leon Bottou. Just about the only other people who seem to be using this for neural network training are the SyntaxNet team (one of whom is Michael Collins) – but it really seems to work great on every problem.
最后一部分优化方法是参数平均, 从Freund and Schapire (1999)),Collins(2002),到Leon Bottou解释了更多细节。大概仅有Michael Collins所在团队SyntaxNet在用,不过看起来这个方法在所有问题上都运行良好。
The trick is to store the moving average of the weights during training. We don't optimize this average – we just track it. Then when we want to actually use the model, we use the averages, not the most recent value. In spaCy (and Thinc) this is done by using a context manager, use_params , to temporarily replace the weights:
其手段是存储训练过程中权重的平均移动值。我们不去优化这个平均值,只是跟踪它。然后当我们真的要用模型时,使用平均值而不是最近值。在spaCy和thinc中,用一个环境manager,use_params,去临时替换权重来实现。
with nlp.use_params(optimizer.averages):
nlp.to_disk('/model')
The context manager is handy because you naturally want to evaluate and save the model at various points during training (e.g. after each epoch). After evaluating and saving, the context manager will exit and the weights will be restored, so you resume training from the most recent value, rather than the average. By evaluating the model after each epoch, you can remove one hyper-parameter from consideration(the number of epochs). Having one less magic number to guess is extremely nice– so having the averaging under a context manager is very convenient.
Contextmanager很方便,因为在训练过程中肯定想要在不通地方评估并存储模型(例如:每个epoch之后)。评估和存储之后,context manager会退出并重置权重值,所以恢复训练是从最近值开始而不是平均值。通过每个epoch之后评估模型,可以考虑移除一个超参(epoch总数)。少猜一个数超爽,所以在contextmanager有个平均值很实用。
Transfer learning
Finally, if you're training from a small data set, it's very useful to start off with some knowledge already in the model. Word vectors are an easy and reliable way to do that, but depending on the application, you may also be able to start with useful knowledge from one of spaCy's pre-trained models, such as the parser, entity recogniser and tagger. If you're adapting a pre-trained model and you want it to retain accuracy on the tasks it was originally trained for, you should consider the "catastrophic forgetting" problem. See this blogpost to read more about the problem and our suggested solution, pseudo-rehearsal.
最后,如果用一个小数据集进行训练,使用一些已在模型中存在的知识非常有用。词向量是一个简单而直接的方法,但是取决于实际应用,或许还可以用一个spaCy的预训练模型,比如实体识别,parser,tagger。如果适配一个预训练模型,而且想在实际任务中再训练原有训练内容,恐怕会发生狗熊掰棒子问题。关于问题的更多内容及建议解决方案,参考下文https://explosion.ai/blog/pseudo-rehearsal-catastrophic-forgetting
Saving and loading models
After training your model, you'll usually want to save its state, and load it back later. You can do this with the Language.to_disk() method:
训练模型后,通常会保存,以便之后加载。Language。to_disk()函数nlp.to_disk( '/home/me/data/en_example_model' )
The directory will be created if it doesn't exist, and the whole pipeline will be written out. To make the model more convenient to deploy, we recommend wrapping it as a Python package.
如果指定目标目录不存在则会创建一个,并且整个pipline将被写入。要使模型更实用,推荐打包为Python包。
Generating a model package
IMPORTANTNOTE
The model packages are not suitable for the public pypi.python.org directory, which is not designed for binary data and files over 50 MB. However, if your company is running an internal installation of PyPi, publishing your models on there can be a convenient way to share them with your team.
spaCy comes with a handy CLI command that will create all required files, and walk you through generating the meta data. You can also create the meta.json manually and place it in the model data directory, or supply a path to it using the --meta flag.For more info on this, see the package docs.
spaCy自带一个方便的CLI命令用来创建所有需要的文件,且直接生成元数据。可以手动创建meta.json并放进模型的数据目录中,或者用 –meta flag提供一个路径。更多内容参见package文档:https://spacy.io/api/cli#package
META.JSON
{
"name": "example_model",
"lang": "en",
"version": "1.0.0",
"spacy_version": ">=2.0.0,<3.0.0",
"description": "Example model for spaCy",
"author": "You",
"email": "[email protected]",
"license": "CC BY-SA 3.0",
"pipeline": ["tagger", "parser","ner"]
}
python -m spacy package/home/me/data/en_example_model /home/me/my_models
This command will create a model package directory that should look like this:
上面的命令将创建一个模型包,其目录结构如下所示:
DIRECTORY STRUCTURE
└── /
├── MANIFEST.in #to include meta.json
├── meta.json #model meta data
├── setup.py #setup file for pip installation
└── en_example_model #model directory
├── __init__.py #init for pip installation
└── en_example_model-1.0.0 # model data
You can also find templates for all files on GitHub . If you're creating the package manually, keep in mind that the directories need to be named according to the naming conventions of lang_name and lang_name-version.
所有模版文件都可以在GitHub(https://github.com/explosion/spacy-models/blob/master/template )上找到。自己创建包的时候注意目录的命名规则,lang_name和lang_name-version。
Customising the model setup
The meta.json includes the model details, like name, requirements and license, and lets you customise how the model should be initialised and loaded. You can define the language data to be loaded and the processing pipeline to execute.
Meta.json包括模型的细节,比如name,requirements和license,也允许自定义如何初始化和加载模型。还可以定义加载语言数据和运行处理pipline。

The load() method that comes with our model package templates will take care of putting all this together and returning a Language object with the loaded pipeline and data. If your model requires custom pipeline components or a custom language class, you can also ship the code with your model. For examples of this, check out the implementations of spaCy's load_model_from_init_py and load_model_from_path utility functions.
Load()函数自带了模型包模版,能够将所有内容整合并返回一个语言对象及其加载的pipline和数据。如果模型需要自定义pipline组件或自定义语言类,也可以将编码与模型一并封装。例如:参看spaCy以下实现工具:load_model_from_init_py以及load_model_from_path。
Building the model package
To build the package, run the following command from within the directory. For more information on building Python packages, see the docs on Python's Setuptools.
Build包命令如下(更多内容参见Python的Setuptools https://setuptools.readthedocs.io/en/latest/):
python setup.py sdist
This will create a.tar.gz archive in a directory /dist. The model can be installed by pointingpip to the path of the archive:
如上将在/dist目录中创建一个.tar.gz的压缩包。该模型可以用pip install加包路径进行安装:
pip install/path/to/en_example_model-1.0.0.tar.gz
You can then load the model via its name, en_example_model, or import it directly as a module and then call its load() method.
然后就可以用模型的名称加载模型了,或者直接引入模块后用load()函数加载。
Loading a custom model package
To load a model from a data directory, you can use spacy.load() with the local path. This will look for a meta.json in the directory and use the lang and pipeline settings to initialise a Language class with a processing pipeline and load in the model data.
从数据目录加载模型:spacy.load()加本地路径。之后会到指定目录中查找meta.json并用lang和pipline设置用pipline来初始化一个语言类,并加载模型数据。
nlp = spacy.load('/path/to/model')
If you want to load only the binary data, you'll have to create a Language class and call from_disk instead.
如果想加载bin,需要创建一个语言类,并使用from_disk。
nlp =spacy.blank('en').from_disk('/path/to/data')
IMPORTANT NOTE: LOADING DATA IN V2.X
In spaCy 1.x, the distinction between spacy.load() and the Language class constructor was quite unclear. You could call spacy.load() when no model was present, and it would silently return an empty object. Likewise, you could pass a path to English, even if the mode required a different language. spaCy v2.0 solves this with a clear distinction between setting up the instance and loading the data.
spaCy1.x版本中,spacy.load()和语言类构造器的区别很模糊。当前没有模型时,可以调用spacy.load()也可以直接返回一个空对象。而且还可以传递一个English的路径,即使模型需要其他语言。2.0版本解决了这个问题。
正确方法: nlp= spacy.blank('en').from_disk('/path/to/data')
错误方法: nlp= spacy.load('en', path='/path/to/data')
Example: How we're training and packaging models for spaCy
Publishing a new version of spaCy often means re-training all available models – currently, that's 13 models for 8 languages. To make this run smoothly, we're using an automated build process and a spacy train template that looks like this:
每发布一个新版本通常意味着重新训练所有模型—当前为8个语言的13个模型。为了平滑过渡,我们使用一个自动build处理和一个spacytrain模版,长相如下:
python -m spacy train {lang}{models_dir}/{name} {train_data} {dev_data} -m meta/{name}.json -V {version} -g{gpu_id} -n {n_epoch} -ns {n_sents}
META.JSON TEMPLATE
{
"lang": "en",
"name": "core_web_sm",
"license":"CC BY-SA 3.0",
"author":"Explosion AI",
"url":"https://explosion.ai",
"email":"[email protected]",
"sources": ["OntoNotes 5", "CommonCrawl"],
"description":"English multi-task CNN trained onOntoNotes, with GloVe vectors trained on common crawl. Assigns word vectors, context-specific token vectors, POS tags, dependency parse and named entities."
}
In a directory meta, we keep meta.json templates for the individual models, containing all relevant information that doesn't change across versions, like the name, description, author info and training data sources. When we train the model, we pass in the file to the meta template as the --meta argument, and specify the current model version as the --version argument.
在一个目录内,为每一个独立的模型保留一个meta.json模版,包括所有跨版本无需变更的有关信息,比如name,description,authorinfo还有training data sources。当训练模型时,传递meta模版的–meta参数,还有指定当前模型版本的—version参数。
On each epoch, the model is saved out with a meta.json using our template and added properties, like the pipeline, accuracy scores and the spacy_version used to train the model. After training completion, the best model is selected automatically and packaged using the package command.Since a full meta file is already present on the trained model, no further setup is required to build a valid model package.
每个epoch,模型都和一个meta.json一同保存并加入属性,比如pipline,accuracyscores以及spacy_version以用来训练模型。训练完成后,最好的模型被自动挑出来并用package命令打包。因为一个完整的meta文件已经在模型中存在了,所以不需要更多设置。
python -m spacy package -f {best_model}dist/
cd dist/{model_name}
python setup.py sdist
This process allows us to quickly trigger the model training and build process for all available models and languages, and generate the correct meta data automatically.
上述样例为快速出发模型的训练并build所有模型和语言的处理,并自动生成正确的meta数据。