本文主要记录Scrapy的常用命令,用于备忘。适用于Windows平台。
例如,我们要爬取这个网站:https://www.tudinet.com/market-252-0-0-0/ 重庆地区的土地转让信息。
整体流程如下:
1、使用scrapy startproject cq_land命令创建项目
2、修改settings.py,使爬虫生效(ITEM_PIPELINES、 USER_AGENT 等)
3、修改items.py,用于存储爬取回来的数据
4、使用scrapy genspider tudinet tudinet.com 命令,创建爬虫文件,用于爬取网页内容
5、编写上一步生成的tudinet.py爬虫文件,完成网页内容解析
6、修改pipelines.py文件,对获取到的信息进行整理,完成存储
1、万事第一步:创建工程
首先在cmd或powershell窗口,CD到想要创建项目的目录,然后输入以下命令,创建了一个名为cq_land的项目。
scrapy startproject cq_land
PS C:\WINDOWS\system32> e:
PS E:\> cd E:\web_data
PS E:\web_data> scrapy startproject cq_land
New Scrapy project 'cq_land', using template directory 'c:\\programdata\\anaconda3\\lib\\site-packages\\scrapy\\templates\\project', created in:
E:\web_data\cq_land
You can start your first spider with:
cd cq_land
scrapy genspider example example.com
PS E:\web_data>
这样就生成了一个cq_land的文件目录(完成后先不要关闭终端窗口,后面第4步还会用到)。接下来,我们主要针对items.py、settings.py、pipelines.py和spiders文件夹进行修改。
2、修改settings.py,使爬虫生效
将settings.py中,ITEM_PIPELINES 附近的注释去掉,修改为:
修改前:
#ITEM_PIPELINES = {
# 'cq_land.pipelines.CqLandPipeline': 300,
#}
修改后:
ITEM_PIPELINES = {
'cq_land.pipelines.CqLandPipeline': 300,
}
有些网站可能需要设置USER_AGENT,所以,加上USER_AGENT防止一般的网站反爬。
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"
3、修改items.py,用于存储爬取回来的数据
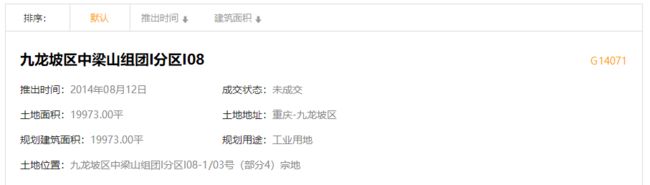
观察数据结构,主要信息有很多字段,以获取标题和推出时间为例,定义两个item项目(items里面定义的内容,可以理解为定义了一个命名为item的字典,每个定义的项目最为键值对存储在item字典中——键值对存储的内容可以是任何Python对象[常用的字符串、列表等]),修改items.py文件内容如下:
class CqLandItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() # 出让地标题
list_time = scrapy.Field() # 推出时间
4、创建爬虫文件,用于爬取网页内容
这时候返回到cms或powershell终端,cd进入cq_land目录,然后创建名为tudinet的爬虫文件,用于爬取土流网的数据。
PS E:\web_data> cd cq_land
PS E:\web_data\cq_land> scrapy genspider tudinet tudinet.com
Created spider 'tudinet' using template 'basic' in module:
cq_land.spiders.tudinet
PS E:\web_data\cq_land>
完成后,将在spider文件夹下产生一个叫tudinet.py的文件。这个文件就是定义爬虫怎么解析网页的文件,解析的内容怎么存储到刚才定义好的item中。
5、编写tudinet.py文件,完成网页内容解析
首先需要将刚才定义好的item内容import进来,然后修改start_urls为我们要爬取的网页(这里我们只爬取一个网页作为示例)。然后在parse函数中定义处理过程,并返回结果,代码如下:
import scrapy
from cq_land.items import CqLandItem
class TudinetSpider(scrapy.Spider):
name = 'tudinet'
allowed_domains = ['tudinet.com']
start_urls = ['https://www.tudinet.com/market-252-0-0-0']
def parse(self, response):
item=CqLandItem()
item['title']=response.xpath("//div[@class='land-l-bt']/text()").extract()
item['list_time']=response.xpath("//div[@class='land-l-cont']/dl/dd/p[1]/text()").extract()
return item
以上是针对单个网页,但实际上我们爬虫多半是需要针对整个网站的所有土地转让信息进行爬取的,因此,我们根据网站翻页的变化,一共有100页可以供我们爬取。因此,我们可以在开头对start_urls进行重新定义,用以爬取这100个页面。
这里有2种处理方式,第一种处理方式,就是直接把这100个url作为列表放到start_urls 中。其他的就不用改动了。
第二种处理方式,就是重新定义start_requests函数。实际上定义这个函数就是把start_urls列表里面的地址用函数生成,然后再通过callback参数设置回调函数,让parse函数来处理Request产生的结果。
import scrapy
from cq_land.items import CqLandItem
from scrapy.http import Request
class TudinetSpider(scrapy.Spider):
name = 'tudinet'
allowed_domains = ['tudinet.com']
# start_urls = ['https://www.tudinet.com/market-252-0-0-0']
def start_requests(self):
init_url='https://www.tudinet.com/market-252-0-0-0/list-pg'
for i in range(1,101):
yield Request("".join([init_url,str(i),'.html']),callback=self.parse)
def parse(self, response):
item=CqLandItem()
item['title']=response.xpath("//div[@class='land-l-bt']/text()").extract()
item['list_time']=response.xpath("//div[@class='land-l-cont']/dl/dd/p[1]/text()").extract()
return item
实际上,对于有多个层次的网页,例如某些论坛,有很多文章列表。我们首先需要访问首页获取页面总数,然后遍历所有页面获取每个帖子的url,最后通过访问每个帖子的地址获取文章的详细信息。那么我们的爬虫文件结构如基本如下:
class abc_Spider(scrapy.Spider):
name='abc'
allowed+domains=['abc.com']
start_urls=['论坛的首页']
# 获取总页数
def parse(self,response):
pages=response.xpath("//xxxx//").extract()
# 这里省略了将pages由字符转数字的过程
for i in range(1,int(pages)):
yield Request("".join(['xx.abc.com',str(i),"xxx"]),callback=self.get_detail_urls)
# 获取所有文章详情页的页面url
def get_detail_urls(self,response):
detail_urls=response.xpath("//xxxx//").extract()
for url in detail_urls:
yield Request(url,callback=self.parse_content)
# 对详情页内容进行解析,并返回结果
def parse_content(self,response):
item=abcitem()
item['xx']=response.xpath("//xxxx//").extract()
return item
6、修改pipelines.py,对获取到的信息进行整理,完成存储
将pipelines.py修改为如下内容,爬取的内容将会存储到cq_land.csv文件中。
import pandas as pd
class CqLandPipeline(object):
def process_item(self, item, spider):
title=item['title']
list_time=item['list_time']
data=pd.DataFrame([title,list_time],index=['标题','推出时间']).T
data.to_csv('cq_land.csv',index=False,encoding='gb2312')
return item
需要注意的是,上述存储方式适用于单个网页的爬取。如果是多个网页,需要在data.to_csv中添加参数,mode='a',表示以追加的方式添加数据,同时应注意数据的列标题问题。另外,也可以使用数据库等方式在这里将数据直接存储到数据库。
7、使用scrapy crawl tudinet 运行爬虫
完成上述文件编辑后,返回cmd或powershell终端,运行:scrapy crawl tudinet
PS E:\web_data\cq_land> scrapy crawl tudinet
2019-04-15 19:35:34 [scrapy.utils.log] INFO: Scrapy 1.5.1 started (bot: cq_land)
2019-04-15 19:35:34 [scrapy.utils.log] INFO: Versions:
……
……
没有意外的话,上述代码会产生一个cq_land.csv文件,打开文件如果内容正确就说明爬虫编写成功了。
当然,scrapy crawl tudinet还可以带参数,用于显示日志的级别:
CRITICAL - 严重错误(critical)
ERROR - 一般错误(regular errors)
WARNING - 警告信息(warning messages)
INFO - 一般信息(informational messages)
DEBUG - 调试信息(debugging messages)
可以使用以下方法按需要显示日志
# 完全不输出日志
scrapy crawl tudinet --nolog
# 按默认输入日志
scrapy crawl tudinet -L DEBUG
以上就是scrapy爬虫的基本形式。
通常情况下,对于不熟悉scrapy的情形下,可能对scrapy产生的内容不了解,不知道哪里出了问题,这里可能需要用到scrapy的另一命令,scrapy shell url。这个命令会直接爬取url的内容,然后在终端中,通过ipython终端的方式产生交互,用户可以使用response.xpath() 等方法测试返回结果。如response.url就是请求的url。
PS E:\web_data\cq_land> scrapy shell https://www.tudinet.com/market-252-0-0-0
2019-04-15 20:21:03 [scrapy.utils.log] INFO: Scrapy 1.5.1 started (bot: cq_land)
2019-04-15 20:21:03 [scrapy.utils.log] INFO: Versions: lxml 4.2.1.0, libxml2 2.9.8, cssselect 1.0.3, parsel 1.5.1, w3lib 1.19.0, Twisted 18.9.0, Python 3.6.5 |Anaconda, Inc.| (default, Mar 29 2018, 13:32:41) [MSC v.1900 64 bit (AMD64)], pyOpenSSL 18.0.0 (OpenSSL 1.0.2o 27 Mar 2018), cryptography 2.2.2, Platform Windows-10-10.0.17763-SP0
……
……
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler
[s] item {}
[s] request
[s] response <200 https://www.tudinet.com/market-252-0-0-0>
[s] settings
[s] spider
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
In [1]:
附:scrapy的命令列表
全局的命令有:
startproject :创建项目(常用必须)
genspider :创建爬虫(常用必须)
settings :获取当前的配置信息,通过scrapy settings -h可以获取这个命令的所有帮助信息
runspider :未创建项目的情况下,运行一个编写在Python文件中的spider
shell : 在终端窗口请求一个网址,可用于探索爬取获得的内容(常用)
fetch :过scrapy downloader 讲网页的源代码下载下来并显示出来
view :将网页document内容下载下来,并且在浏览器显示出来
version :查看版本信息,并查看依赖库的信息
项目命令有:
crawl :运行爬虫(常用必须)
check : 检查代码是否有错误
list :列出所有可用爬虫
edit :edit 在命令行下编辑spider ### 不建议运行
parse
bench