今天来扒一扒Square公司的IO流的库Okio,现在越来越多Android项目都在使用Square公司的网络开源全家桶,即 Okio + OkHttp + Retrofit。这三个库的层级是从下网上来看,Okio用来处理IO流,OkHttp用来实现Http协议,Retrofit用来做Android端的网络使用接口,关于Retrofit,之前写过源码分析。但是相对于Retrofit和OkHttp,Okio就比较低调,因为它偏底层,大部分同学对它可能不太熟悉,我们今天就来看看这个幕后英雄吧。
Square功德无量,著名的JakeWharton大神之前就一直在这家公司(据说今年7月份离职了)。
一 为什么需要Okio
首先我们需要强调Okio是一个Java库,所以它的底层流肯定都是JavaIO中定义的基础流。基础流指的是Java中对于从不同数据来源抽象的流,比如是FileInputStream ByteInputStream PipedInputStream等,Okio只是优化了Java IO库中对于基础流包装的API。
1.1 更加简洁
我们经常说Java的IO库是JDK设计的比较精妙的一个API,由于使用了装饰者模式,大大减少了类的数目。然而即便如此,大家使用时仍然感觉比较麻烦,比如我们想要从一个文件中读取出来一个int数据,我们至少要创建如下几个对象:
FileInputStream //用于打开文件流
BufferedInputStream //对FileInputStream做装饰,添加buffer功能,避免频繁IO
DataInputStream //用于将字节流转化成Java基本类型
此时,通过DataInputStream.readInt()就可以读出来一个int了。但是机智的你已经发现了,我们需要和至少三个跟输入相关的类打交道,而Okio把这些都做了集中处理,你可能只需要一个类就可以很方便的进行以上的各种操作了。
1.2 提高性能
首先okio内部用一个Segment对象来描述内存数据,Segment对象中就有byte[]作为数据的载体。对于Segment来说,Okio不是每次都去创建,而且通过一个对象池来做复用,这样就可以减少对象创建,销毁代价,实际上也可以减少byte[]数组zero-fill的代价。关于Segment,我们会在第四章专门进行介绍。
其次,Okio中多个流之间的数据是可以共享的,而不需要进行内存拷贝。我们举个栗子,如果我使用Java IO从一个文件中读取数据,写入另外一个文件中,代码大致如下:
BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream(new File("in.file")));
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(new FileOutputStream(new File("out.file")));
byte[] bytes = new byte[2048];
int count;
while ((count = bufferedInputStream.read(bytes)) != -1) {
bufferedOutputStream.write(bytes,0,count);
}
bufferedOutputStream.flush();
BufferedInputStream内部有个缓存,每次read的时候,先看看自己缓存中是否满足读取方的需要,如果满足,直接从内部缓存中做内存copy到读取方传入的byte数组(步骤一);如果不满足,调用fill方法从原始流中读取数据到内部缓存,重复步骤一。同时,BufferedOutPutStream中也有个内部缓存,写入方先把数据写入到内部缓存,然后再由内部缓存统一写入到原始输出IO,如果使用okio,应该可以减少两份数据copy,第二节我们对两种方式从使用和性能进行了对比。
1.3 超时看门狗
Java IO对于数据流的处理是没有超时概念的,比如从某个流中读取数据如果输入流一直没有数据,那么当前工作线程就会一直阻塞(当然NIO里面是异步的,我们这里不讨论)。Okio中所有关于流的操作都可以设置超时器,用来做超时处理。比如,从一个InputStream读取数据,如果3S没有响应数据,应用就可以考虑这个数据源头可能已经发生错误了,可以尝试过段时间再尝试。
二 流程总述
2.1 来个栗子
为了更加深入了解Okio的原理,我们把第一节中的栗子用Okio重新实现一遍。
BufferedSource bufferedSource = Okio.buffer(Okio.source(new File("in.file")));
BufferedSink bufferedSink = Okio.buffer(Okio.sink(new File("out.file")));
bufferedSink.writeAll(bufferedSource);
bufferedSink.flush();
这里功能还是一样的,从一个文件读取数据,写入另外一个文件。你可以看到,这里代码比之前使用JavaIO库的代码简洁了不少,连我们经常写的while读取都省下来了。我能告诉你这段代码的性能也比上面使用Java IO的好吗?我做了一个简单的测试,读取一个20M左右的文件,对比JavaIO和Okio分别进行2000次重复操作,打印一下大概的耗时:

COOL!
2.2 流程分析
既然Okio看起来这么叼叼的,我们这一小节就来看看它大概流程是怎么走的。
2.2.1 输入输出
对于IO来说,就是两件事情,输入和输出,所谓输入就是从IO设备(硬盘、网络、外设等)中读取数据到内存,输出就是把内存中的数据输出到IO设备。
Java中对于IO流的定义有内存流的概念,比如将一个字符串或者一个byte数组作为输入数据源,上面定义并没有涵盖这个例外。
不管是在JavaIO或者是Okio中输入输出都是对称的,JavaIO中有你熟悉的InputStream和OutputStream,在Okio中对应为 Source 和 Sink,由于输入输出是对称的,下面我们只聊输入流就好了。
首先我们看一下InputStream的接口定义:
public abstract int read() throws IOException;
public int read(byte b[]) throws IOException;
我们看到InputStream的接口定义很清晰,read方法要不通过返回值返回数据,要不通过外面传入的byte数组来带回数据,数据的来源就是原始流。
相对于InputStream,Source的定义稍微有点绕,
public interface Source extends Closeable {
long read(Buffer sink, long byteCount) throws IOException;
Timeout timeout();
}
你会看到这个地方的read方法的入参是一个Buffer参数,表示从当前Source流中读出byteCount个字节放到Buffer中(参数名为sink,代表输出),那Buffer是什么?不要着急,我们第四节将会单独来说,这里我们先结合一个最简单的栗子一步步看调用流程吧。
从文件test.file中读出来内容当成UTF-8编码的字符串。
BufferedSource bufferedSource = Okio.buffer(Okio.source(new File("test.file")));
String s = bufferedSource.readUtf8();
2.2.2 适配InputStream
Okio.source(new File("test.file")),就可以创建一个Source了,当然这个Source的基础流肯定是个FileInputStream:
public static Source source(File file) throws FileNotFoundException {
return source(new FileInputStream(file));
}
看起来,所有的逻辑应该是在Okio.source(InputStream in)这个方法中,它就是把一个普通的JavaIO的InputStream适配成Okio的Source的过程(这就是一个典型的适配器模式的应用)。
public static Source source(InputStream in) {
return source(in, new Timeout());
}
我们可以看到这里出现了Timeout类,这就是我们所说的超时器,我们在第五章会重点介绍,这里先忽略。
private static Source source(final InputStream in, final Timeout timeout) {
return new Source() {
public long read(Buffer sink, long byteCount) throws IOException {
//将数据读入Buffer
return bytesRead;
}
@Override public void close() throws IOException {in.close();}
@Override public Timeout timeout() {return timeout;}
@Override public String toString() {return "source(" + in + ")";}
};
}
我们看到source方法的逻辑很简单,生成一个Source类的内部类,主要逻辑就是代理基础流的各种方法,read方法就是从基础流中读出数据加入到Buffer中。
到此,我们就通过Okio这个适配器,将一个普通的Java InputStream适配成了一个Source类。
装饰Source
和JavaIO一样,产生了Source之后,我们可以将它装饰成BufferedSource。什么是BufferedSource?就是为Source提供了一个内部的Buffer作为数据存储的地方,你还记得Source接口的read方法吗?它的入参需要一个Buffer,对于BufferedSource来说,传入的就是内部自己的Buffer。此外,BufferedSource提供了一堆快捷API,比如readString等。Okio提供了BufferedSource的具体实现RealBufferedSource。
readUtf8()
到此,我们已经得到了一个RealBufferedSource,通过调RealBufferedSource的readUtf8()我们就得到了文件二进制内容,并以UTF-8进行编码,我们看看readUtf8的实现吧:
public String readUtf8() throws IOException {
buffer.writeAll(source);
return buffer.readUtf8();
}
这里我们看到,首先从Source读取数据到Buffer中,然后调用Buffer的readUtf8()。
至此,我们已经分析了上面使用Okio读取一个文件内容,并进行的整个流程。使用Okio适配InputStream,使用BufferedSource进行装饰和接口加强,RealBufferedSource真正实现了BufferedSource,内部持有一个Buffer类,读取数据之前,通过将Source中数据写入Buffer,然后从Buffer中读出来数据。
四 Buffer详解
前面很多地方已经使用了Buffer这个类,但是我们并没有细说,现在来重点分析一下。这个类是整个Okio中最最核心的结构之一,也是设计的非常巧妙的一个类,所有关于Okio性能提升的地方都是通过这个类实现的。首先我们来看一下这个类的继承结构:
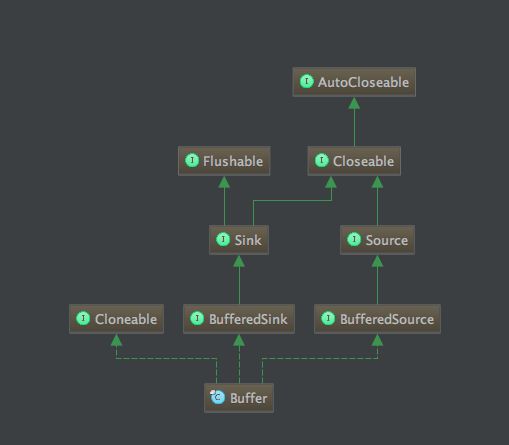
是不是毁三观?是不是很惊讶?Buffer居然同时实现了BufferedSink和BufferedSource,即你既可以对它进行数据写入,也可以从它做数据读出。仔细想想前面说的,Source是Okio对InputStream的抽象,从Source读取的数据被放到那里去了?入参的Buffer!那我要使用这些数据怎么办?肯定从Buffer中取啊!所以Buffer设计成可写可读理解起来就没有什么问题了吧!
4.1 数据队列
那Buffer是怎么实现的呢?很简单,Buffer本质上就是一个双向列表,每次做数据写入时都从表尾追加,读取的时候从表头进行读取。表的每一个节点就是一个Segment。
如果你仔细想想就会发现这个设计比原生的JavaIO里面的BufferedInputStream好在哪里了,官方的BufferedInputStream内部的缓存对外是不可见的,每次都是先读取到自己的缓存,然后从缓存中往外copy内存;Okio是先读取到Buffer中,外面使用的时候,直接把Buffer中的数据共享出来。
我们还以前面的栗子来分析吧,通过Okio.source做InputStream到Source代理的时候,Source的read方法的实现展开如下:
public long read(Buffer sink, long byteCount) throws IOException {
Segment tail = sink.writableSegment(1);
int maxToCopy = (int) Math.min(byteCount, Segment.SIZE - tail.limit);
int bytesRead = in.read(tail.data, tail.limit, maxToCopy);
if (bytesRead == -1) return -1;
tail.limit += bytesRead;
sink.size += bytesRead;
return bytesRead;
}
获取Buffer写入位置
Segment tail = sink.writableSegment(1);获取可写入的尾节点,我们看看Buffer是怎么做的:
Segment writableSegment(int minimumCapacity) {
//如果Buffer还没有数据,那么就初始化一个头
if (head == null) {
head = SegmentPool.take(); // Acquire a first segment.
return head.next = head.prev = head;
}
//拿到最后一个Segment
Segment tail = head.prev;
//如果不够放,或者不是owner,那么新加一个Segment放到队尾
if (tail.limit + minimumCapacity > Segment.SIZE || !tail.owner) {
tail = tail.push(SegmentPool.take());
}
return tail;
}
写入数据到Buffer
写入Buffer中,其实是写入到第一步返回的Segment的byte[]数组中,这里其实就是使用了JavaIO中InputStream的read(byte[])方法,可以一次读入多个字节,减少多次IO。
buffer.readUtf8()
从文件读取的内容已经被放到了Buffer的Segement单链表中,我们调用readUtf8()就是简单的把从表头开始遍历Segment,把数据解码成UTF-8编码的数据。
五 超时器
Okio提供了超时器的功能,之前我们通过Okio适配JavaIO时,默认都会给我们提供一个Timeout实例,现在我们来重点聊聊。
在Okio中对于超时的定义有两种:
1、执行时间限制,这个操作需要在指定的时间段内完成,通过timeout方法指定;
2、截至时间限制,这个操作需要在某个时间点之前完成,通过deadLine方法指定。
Okio为我们提供了两个默认的超时器实现 Timeout 和 它的子类AsyncTimeout。其中Timeout是同步超时器,也是大部分Okio默认会给JavaIO添加的超时器,比如:
private static Source source(final InputStream in, final Timeout timeout) {
return new Source() {
public long read(Buffer sink, long byteCount) throws IOException {
timeout.throwIfReached(); //判断是否已经超时
//do some thing
}
};
}
所谓同步,就是在执行操作的线程里面去判断当前是否已经超时,其实同步判断超时是不准的,我们知道使用JavaIO(非NIO)其实大部分操作都是阻塞的,那如果操作在阻塞阶段发生了超时,同步肯定就发现不了。这个时候我们就需要异步的超时器AsyncTimeout,针对socket,Okio默认添加了异步超时器(因为Okio的主要侧重点还是在网络IO方面,所以Socket有福利也很正常)。看看Okio中关于Socket的代码:
public static Source source(Socket socket) throws IOException {
AsyncTimeout timeout = timeout(socket); //(1)
Source source = source(socket.getInputStream(), timeout); //(2)
return timeout.source(source);//(3)
}
(1) 生成AsyncTimeout
private static AsyncTimeout timeout(final Socket socket) {
return new AsyncTimeout() {
protected IOException newTimeoutException(IOException cause) {
InterruptedIOException ioe = new SocketTimeoutException("timeout");
if (cause != null) {
ioe.initCause(cause);
}
return ioe;
}
@Override protected void timedOut() {
//超时器超时时需要进行的操作
socket.close();
}
};
}
我们看到生成的AsyncTimeout主要逻辑就是处理超时时应该怎么处理,这里是直接关闭socket。
(2) 生成Source,这个代码前面已经分析过了,不再赘述
(3)用AsyncTimeout装饰一下Source,不仅仅是在JavaIO中大量使用装饰者,在Okio中同样大量使用了。
public final Source source(final Source source) {
return new Source() {
@Override public long read(Buffer sink, long byteCount) throws IOException {
//进入工作
enter();
try {
//do some thing
} finally {
//退出工作
exit();
}
}
}
首先在每一次read之前,我们调用enter()方法,将前这个AsyncTimeout加入到一个加入单链表中,单链表中的AsyncTimeout按照最近到期的顺序插入。
后台有一个看门狗线程,WatchDog,它不断的从这个单链表中读取首个超时器,取出超时时间,并直接wait阻塞;如果一个超时器时间到了,就会直接调用它的timeout方法,就完成了超时的逻辑了。关于超时逻辑判断的这块逻辑有兴趣的自己可以查看,还挺有意思的。
需要第一步(1)中复写的timedOut,这是超时器能够工作的关键。你想想如果工作线程正和socket进行数据交换,此时是block的,异步的看门狗发现这个数据过程超时了,它怎么通知工作线程呢?这就是为什么AsyncTimeout需要持有socket的原因,看门狗发现超时了,它就会直接调用socket.close,(3)中的dosomething就必然会抛出一个异常,因为底下的流都被关闭了。
总结
Okio作为Square公司专门为网络IO设计的一个流加强库,极大简化了各种IO操作的使用。除了上面分析的,Okio还提供了ByteString作为Byte数组数据向各种格式做转化的Utils类,同时,作为网络中常用的Gzip压缩、Hash摘要,Okio也方便的提供了流操作。这些都比较简单,各位看官可以自己去看源码分析吧。