方法引用详解
方法引用: method reference
方法引用实际上是Lambda表达式的一种语法糖
我们可以将方法引用看作是一个「函数指针」,function pointer
方法引用共分为4类:
- 类名::静态方法名
- 引用名(对象名)::实例方法名
- 类名::实例方法名 (比较不好理解,个地方调用的方法只有一个参数,为什么还能正常调用呢? 因为调用比较时,第一个对象来调用getStudentByScore1. 第二个对象来当做参数)
- 构造方法引用: 类名::new
public class StudentTest {
public static void main(String[] args) {
Student student = new Student("zhangsan",10);
Student student1 = new Student("lisi",40);
Student student2 = new Student("wangwu",30);
Student student3 = new Student("zhaoliu",550);
List list = Arrays.asList(student, student2, student3, student1);
// list.forEach(item -> System.out.println(item.getName()));
//1. 类名 :: 静态方法
// list.sort((studentpar1,studentpar2) -> Student.getStudentByScore(studentpar1,studentpar2));
list.sort(Student::getStudentByScore);
list.forEach(item -> System.out.println(item.getScore()));
System.out.println(" - - - - - - - -- ");
// 2. 引用名(对象名)::实例方法名
StudentMethod studentMethod = new StudentMethod();
list.sort(studentMethod::getStudentBySource);
list.forEach(item -> System.out.println(item.getScore()));
System.out.println(" - - - -- -- ");
// 3. 类名:: 实例方法名
// 这个地方调用的方法只有一个参数,为什么还能正常调用呢? 因为调用比较时,第一个对象来调用getStudentByScore1. 第二个对象来当做参数
list.sort(Student::getStudentByScore1);
list.forEach(item -> System.out.println(item.getScore()));
System.out.println("- - - - - - - -");
// 原生的sort 来举个例子
List list1 = Arrays.asList("da", "era", "a");
// Collections.sort(list1,(city1,city2) -> city1.compareToIgnoreCase(city2));
list1.sort(String::compareToIgnoreCase);
list1.forEach(System.out::println);
System.out.println("- - - - - - -- ");
//4. 构造方法引用
StudentTest studentTest = new StudentTest();
System.out.println(studentTest.getString(String::new));
}
public String getString(Supplier supplier) {
return supplier.get()+"hello";
}
} 默认方法
defaute method
默认方法是指实现此接口时,默认方法已经被默认实现。
引入默认方法最重要的作用就是Java要保证向后兼容。
情景一: 一个类,实现了两个接口。两个接口中有一个相同名字的默认方法。此时会报错,需要从写这个重名的方法
情景二: 约定:实现类的优先级比接口的优先级要高。 一个类,实现一个接口,继承一个实现类。接口和实现类中有一个同名的方法,此时,此类会使用实现类中的方法。
Stream 流介绍和操作方式详解
Collection提供了新的stream()方法。
流不存储值,通过管道的方式获取值。
本质是函数式的,对流的操作会生成一个结果,不过并不会修改底层的数据源,集合可以作为流的底层数据源。
延迟查找,很多流操作(过滤、映射、排序等)等可以延迟实现。
通过流的方式可以更好的操作集合。使用函数式编程更为流程。与lambda表达式搭配使用。
流由3部分构成:
- 源
- 零个或多个中间操作(操作的是谁?操作的是源)
- 终止操作(得到一个结果)
流操作的分类:
- 惰性求值(中间操作)
- 及早求值(种植操作)
使用链式的调用方式sunc as : stream.xxx().yyy().zzz().count(); 没有count的时候前边的三个方法不会被调用。后续会进行举例。
掌握流常用的api,了解底层。
流支持并行化,可以多线程操作。迭代器不支持并行化。
流怎么用?
流的创建方式
- 通过静态方法 : Stream stream = Stream.of();
- 通过数组:Arrays.stream();
- 通过集合创建对象:Stream stream = list.stream;
流的简单应用
public static void main(String[] args) {
IntStream.of(1,2,4,5,6).forEach(System.out::println);
IntStream.range(3, 8).forEach(System.out::println);
IntStream.rangeClosed(3, 8).forEach(System.out::println);
}举例:将一个数组中的数字都乘以二,然后求和。
public static void main(String[] args) {
List list = Arrays.asList(1, 2, 3, 4, 5);
System.out.println(list.stream().map(i -> i*2).reduce(0,Integer::sum));
} 函数式编程和传统面向对象编程根本上有什么不同?
传统面向对象编程传递的是数据。函数式编程通过方法传递的是一种行为,行为指导了函数的处理,根据行为对数据进行加工。
举例:流转换成list的练习
public static void main(String[] args) {
Stream stream = Stream.of("hello", "world", "hello world");
// String[] stringArray = stream.toArray(length -> new String[length]);
//替换成方法引用的方式 --> 构造方法引用.
String[] stringArray = stream.toArray(String[]::new);
Arrays.asList(stringArray).forEach(System.out::println);
System.out.println("- - - - - - - - - - -");
//将流转换成list, 有现成的封装好的方法
Stream stream1 = Stream.of("hello", "world", "hello world");
List collect = stream1.collect(Collectors.toList());// 本身是一个终止操作
collect.forEach(System.out::println);
System.out.println("- - - - - - ");
//使用原生的 collect 来将流转成List
Stream stream2 = Stream.of("hello", "world", "hello world");
// List lis = stream2.collect(() -> new ArrayList(), (theList, item) -> theList.add(item),
// (theList1, theList2) -> theList1.addAll(theList2));
// 将上面的转换成方法引用的方式 -- 这种方法不好理解.
List list = stream2.collect(LinkedList::new, LinkedList::add, LinkedList::addAll);
//这种方法,如果想要返回ArrayList也可以实现.
// List list1 = stream2.collect(ArrayList::new, ArrayList::add, ArrayList::addAll);
list.forEach(System.out::println);
} Collectors类中包含了流转换的多个辅助类
举例: 将流 转成各种类型的数据。
public static void main(String[] args) {
Stream stream = Stream.of("hello", "world", "hello world");
//将流转换成List 另一种方法
// List list= stream.collect(Collectors.toCollection(ArrayList::new));
// list.forEach(System.out::println);
//将流转成set
// Set set = stream.collect(Collectors.toSet());
//转成TreeSet
// TreeSet set = stream.collect(Collectors.toCollection(TreeSet::new));
// set.forEach(System.out::println);
//转成字符串
String string = stream.collect(Collectors.joining());
System.out.println(string);
//Collectors 类中有多重辅助的方法.
} 遇到问题的时候,先思考一下能否用方法引用的方式,使用流的方式来操作。因为用起来比较简单。
举例:将集合中的每一个元素 转换成大写的字母, 给输出来。
public static void main(String[] args) {
//将集合中的每一个元素 转换成大写的字母, 给输出来
List list = Arrays.asList("hello","world","hello world");
//转成字符串,然后转成大写.
// System.out.println(list.stream().collect(Collectors.joining()).toUpperCase());
//上面的代码 可以转换成下边的代码.
// System.out.println(String.join("", list).toUpperCase());
//视频上给出的 还是List的大写
list.stream().map(String::toUpperCase).collect(Collectors.toList()).forEach(System.out::println);
//将集合 的数据给平方一下输出.
List list1 = Arrays.asList(1, 2, 3, 4, 5);
list1.stream().map(item -> item * item).collect(Collectors.toList()).forEach(System.out::println);
} 流中的 .map () 方法,是对集合中的每一个数据进行一下操作。
stream 的 flat操作。 打平操作。
public static void main(String[] args) {
// 举例: flag 的操作, 打平. 一个集合中有三个数组, 打平之后,三个数组的元素依次排列.
Stream> stream = Stream.of(Arrays.asList(1), Arrays.asList(2, 3), Arrays.asList(4, 5));
//将里边每一个ArrayList的数据 做一个平方. 然后打平. 输出一个list
stream.flatMap(theList -> theList.stream()).map(item -> item * item).forEach(System.out::println);
} Stream 其他方法介绍:
public static void main(String[] args) {
// stream 其他方法介绍.
// generate(). 生成stream对象
Stream stream = Stream.generate(UUID.randomUUID()::toString);
// System.out.println(stream.findFirst().get());
// findFirst,找到第一个对象.然后就短路了,会返回一个Optional对象(为了避免NPE),不符合函数式编程
// stream.findFirst().isPresent(System.out::print);
// iterate() 会生成 一个 无限的串行流.
// 一般不会单独使用. 会使用limit 来限制一下总长度.
Stream.iterate(1, item -> item + 2).limit(6).forEach(System.out::println);
} Stream 运算练习:(Stream提供了各种操作符)
举例:找出该流中大于2的元素,然后每个元素*2 ,然后忽略掉流中的前两个元素,然后再取流中的前两个元素,最后求出流元素中的总和.
Stream stream = Stream.iterate(1, item -> item + 2).limit(6);
//找出该流中大于2的元素,先使用filter()过滤.
//每个元素*2 使用mapToInt 避免重复拆箱.
//忽略掉流中的前两个元素; 使用 skip(2)
//再取流中的前两个元素; 使用limit(2)
//求出流元素中的总和. 使用sum()
System.out.println(stream.filter(item -> item>2).mapToInt(item -> item * 2).skip(2).limit(2).sum()); 举例:找出该流中大于2的元素,然后每个元素*2 ,然后忽略掉流中的前两个元素,然后再取流中的前两个元素,最后找到最小的元素.
// .min() 返回的是IntOptional.
// System.out.println(stream.filter(item -> item>2).mapToInt(item -> item * 2).skip(2).limit(2).min());
//应该这样调用. 上边的可能会出NPE异常
stream.filter(item -> item>2).mapToInt(item -> item * 2).skip(2).limit(2).min().ifPresent(System.out::println);举例:获取最大值,最小值,求和等各种操作。 .summaryStatistics();
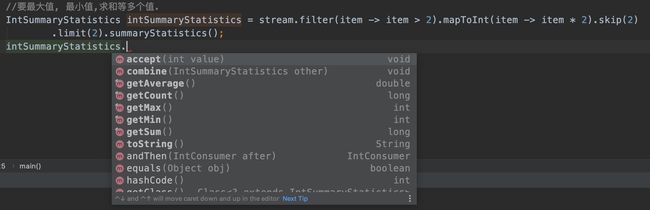
在练习的过程中发现了一个问题。如果是这样连续打印两条对流操作之后的结果。会报流未关闭的异常。


注意事项:流被重复使用了,或者流被关闭了,就会出异常。
如何避免:使用方法链的方式来处理流。 具体出现的原因,后续进行详细的源码讲解。
举例 :中间操作(惰性求值) 和中止操作(及早求值)本质的区别
public static void main(String[] args) {
List list = Arrays.asList("hello", "world", "hello world");
//首字母转大写
list.stream().map(item ->{
String s = item.substring(0, 1).toUpperCase() + item.substring(1);
System.out.println("test");
return s;
}).forEach(System.out::println);
//没有遇到中止操作时,是不会执行中间操作的.是延迟的
// 遇到.forEach() 中止操作时,才会执行中间操作的代码
} 举例:流使用顺序不同的区别
//程序不会停止
IntStream.iterate(0,i->(i+1)%2).distinct().limit(6).forEach(System.out::println);
//程序会停止
IntStream.iterate(0,i->(i+1)%2).limit(6).distinct().forEach(System.out::println);Stream底层深入
和迭代器不同的是,Stream可以并行化操作,迭代器只能命令式地、串行化操作
- 当使用穿行方式去遍历时,每个item读完后再读下一个item
- 使用并行去遍历时,数据会被分成多个段,其中每一个都在不同的线程中处理,然后将结果一起输出。
Stream的并行操作依赖于Java7中引入的Fork/Join框架。
流(Stream)由3部分构成:
- 源(Source)
- 零个或多个中间操作(Transforming values)(操作的是谁?操作的是源)
- 终止操作(Operations)(得到一个结果)
内部迭代和外部迭代
描述性的语言:sql和Stream的对比
select name from student where age > 20 and address = 'beijing' order by desc;
===================================================================================
Student.stream().filter(student -> student.getAge >20 ).filter(student -> student.getAddress().equals("beijing")).sorted(..).forEach(student -> System.out.println(student.getName));
上述的描述,并没有明确的告诉底层具体要怎么做,只是发出了描述性的信息。这种流的方式就叫做内部迭代。针对于性能来说,流的操作肯定不会降低性能。
外边迭代举例: jdk8以前的用的方式。
List list = new ArrayList<>();
for(int i = 0 ;i <= students.size();i++){
Student student = students.get(i);
If(student.getAge() > 20 )
list.add(student);
}
Collections.sort(list.....)
list.forEach().....
Stream的出现和集合是密不可分的。
集合关注的是数据与数据存储本身,流关注的则是对数据的计算。
流与迭代器类似的一点是:流是无法重复使用或消费的。
如何区分中间操作和中止操作:
中间操作都会返回一个Stream对象,比如说返回Stream ,Stream ,Stream ;
中止操作则不会返回Stream类型,可能不返回值,也可能返回其他类型的单个值。
并行流的基本使用
举例: 串行流和并行流的简单举例比较
public static void main(String[] args) {
// 串行流和并行流的比较
List list = new ArrayList<>(5000000);
for (int i = 0; i < 5000000; i++) {
list.add(UUID.randomUUID().toString());
}
System.out.println("开始排序");
long startTime = System.nanoTime();
// list.parallelStream().sorted().count(); //串行流
list.parallelStream().sorted().count(); //并行流
long endTime = System.nanoTime();
long millis = TimeUnit.NANOSECONDS.toMillis(endTime - startTime);
System.out.println("排序时间为: "+ millis);
} 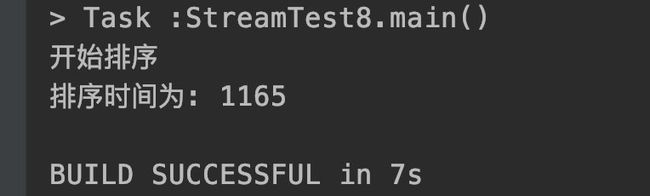
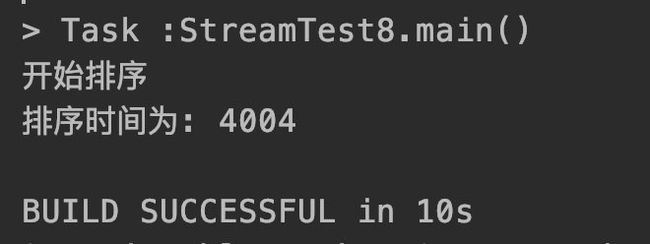
结果如图,并行流和串行流时间上错了4倍。
举例: 打印出列表中出来第一个长度为5的单词.. 同时将长度5打印出来.
public static void main(String[] args) {
List list = Arrays.asList("hello", "world", "hello world");
// list.stream().mapToInt(item -> item.length()).filter(length -> length ==5)
// .findFirst().ifPresent(System.out::println);
list.stream().mapToInt(item -> {
int length = item.length();
System.out.println(item);
return length;
}).filter(length -> length == 5).findFirst().ifPresent(System.out::println);
//返回的是hello , 不包含 world.
} 返回的是hello , 不包含 world.
流的操作原理: 把流想成一个容器,里边存储的是对每一个元素的操作。操作时,把操作串行化。对同一个元素进行串行的操作。操作中还包含着短路操作。
举例: 找出 这个集合中所有的单词,而且要去重. flatMap()的使用。
public static void main(String[] args) {
//举例; 找出 这个集合中所有的单词,而且要去重.
List list = Arrays.asList("hello welcome", "world hello", "hello world", "hello hello world");
// list.stream().map(item -> item.split(" ")).distinct()
// .collect(Collectors.toList()).forEach(System.out::println);
//使用map不能满足需求, 使用flatMap
list.stream().map(item -> item.split(" ")).flatMap(Arrays::stream)
.distinct().collect(Collectors.toList()).forEach(System.out::println);
//结果为 hello welcome world
} 举例:组合起来. 打印出 hi zhangsan , hi lisi , hi wangwu , hello zhangsan , hello lisi .... flatMap()的使用。
public static void main(String[] args) {
//组合起来. 打印出 hi zhangsan , hi lisi , hi wangwu , hello zhangsan , hello lisi ....
List list = Arrays.asList("Hi", "Hello", "你好");
List list1 = Arrays.asList("zhangsan", "lisi", "wangwu");
List collect = list.stream().flatMap(item -> list1.stream().map(item2 -> item + " " +
item2)).collect(Collectors.toList());
collect.forEach(System.out::println);
} 举例: 流对分组/分区操作的支持. group by / protition by
public static void main(String[] args) {
//数据准备.
Student student1 = new Student("zhangsan", 100, 20);
Student student2 = new Student("lisi", 90, 20);
Student student3 = new Student("wangwu", 90, 30);
Student student4 = new Student("zhangsan", 80, 40);
List students = Arrays.asList(student1, student2, student3, student4);
//对学生按照姓名分组.
Map> listMap = students.stream().collect(Collectors.groupingBy(Student::getName));
System.out.println(listMap);
//对学生按照分数分组.
Map> collect = students.stream().collect(Collectors.groupingBy(Student::getScore));
System.out.println(collect);
//按照年龄分组.
Map> ageMap = students.stream().collect(Collectors.groupingBy(Student::getAge));
System.out.println(ageMap);
//按照名字分组后,获取到每个分组的元素的个数.
Map nameCount = students.stream().collect(Collectors.groupingBy(Student::getName, Collectors.counting()));
System.out.println(nameCount);
//按照名字分组,求得每个组的平均值.
Map doubleMap = students.stream().collect(Collectors.groupingBy(Student::getName, Collectors.averagingDouble(Student::getScore)));
System.out.println(doubleMap);
//分区, 分组的一种特例. 只能分两个组 true or flase . partitioning By
Map> collect1 = students.stream().collect(Collectors.partitioningBy(student -> student.getScore() >= 90));
System.out.println(collect1);
}