1、Redis介绍
1.1、什么是 NoSql
为了解决高并发、可扩展用大数据存储问题而产生的库方案,就是 NoSql数据库。
NoSQL泛指非关系型的数据库,NoSQL即 Not-Only SQL,它可以作为关系型数据库的良好补充。
1.2、kv存储数据库
键值 (Key-Value)存储数据库
相关产品: 相关产品: Tokyo Cabinet/Tyrant、Redis、Voldemort、Berkeley DB
典型应用: 内容缓存,主要用于处理大量数据的高访问负载
数据模型: 一系列键值对
优势: 快速查询
劣势: 存储的数据缺少结构化
1.3、什么是 Redis
Redis是用 C语言开发的一个源高性能键值 对( key-value)数据库。它通过提供多种键 )数据库。 值数据类型来适应不同场景下的存储需求,目前为止Redis支持的键值数据类型如 下:
字符串类型 string
散列类型 hash
列表类型 list
集合类型 set
有序集合类型 。
1.4、redis的应用场景
缓存( 数据查询、短连接、新闻内容、商品等)
分布式集群架构中的 session分离。
聊天室的在线好友列表。
任务队列。(秒杀、 抢购任务队列)。
应用排行榜。
网站访问统计。
数据过期处理(可以精确到毫秒)
1.5、redis安装
这里直接使用docker进行安装,想学习docker的话推荐可以看docker入门到实践 截止至20180419我还在学习这软件. 自学-章1
Dockerfile文件
Host # Dockerfile
FROM centos
# 解压redis到这个目录下
ADD redis-4.0.9.tar.gz /usr/local
COPY redis.sh /tmp/redis.sh
# 安装必须要的gcc make工具包,并创建一个软链接用于识别,并安装
RUN yum -y install gcc gcc-c++ make \
&& ln -sv /usr/local/redis-4.0.9 /usr/local/redis \
&& cd /usr/local/redis-4.0.9 \
&& make && make install PREFIX=/usr/local/redis \
&& rm -rf /var/lib/yum/* \
&& chmod +x /tmp/redis.sh
ENV PATH /usr/local/redis/bin:$PATH
EXPOSE 6379
# 运行脚本,如果不指定那么密码就是123456
ENTRYPOINT ["/tmp/redis.sh","123456"]附上脚本
Host # cat redis.sh
#!/bin/bash
#
# 设置一个password的默认值
Password=$1
Password=${Password:-123456}
mkdir /data/
# 将配置文件跟redis存储文件保存到/data目录下,方便未来的持久化
/usr/bin/cp -i /usr/local/redis/redis.conf /data/redis.conf
sed -i "s/# requirepass foobared/requirepass ${Password}/gi" /data/redis.conf
#默认值./,即当前目录,dump出的数据文件的存储路径
sed -i "s@dir ./@dir /data@gi" /data/redis.conf
sed -i "s/^bind 127.0.0.1//gi" /data/redis.conf
redis-server /data/redis.conf1.5.1、直接启动
启动
Host# docker run -dit --name r1 -p 12321:6379 redis:v1
71d73e114deaaa998d95ea36bf0b73bec10ee498a69c3085ddf042f6013e4aca
Host# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
0038d4d69937 redis:v1 "/tmp/redis.sh 123456" About a minute ago Up About a minute 0.0.0.0:12321->6379/tcp r1测试redis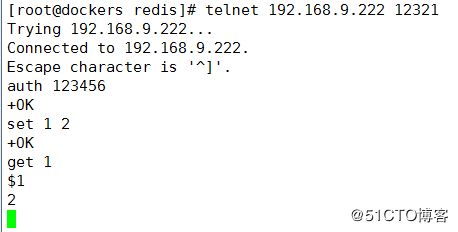
1.5.2、使用挂载的方式
Host# mkdir /redisdata/
Host# cp redis.conf !$
Host# docker run -dit -v /redisdata/data -p 12322:6379 --name r2 redis:v11.6、redis客户端图形化
github源码地址 安装说明 windows客户端下载地址 客户端快速入门指南
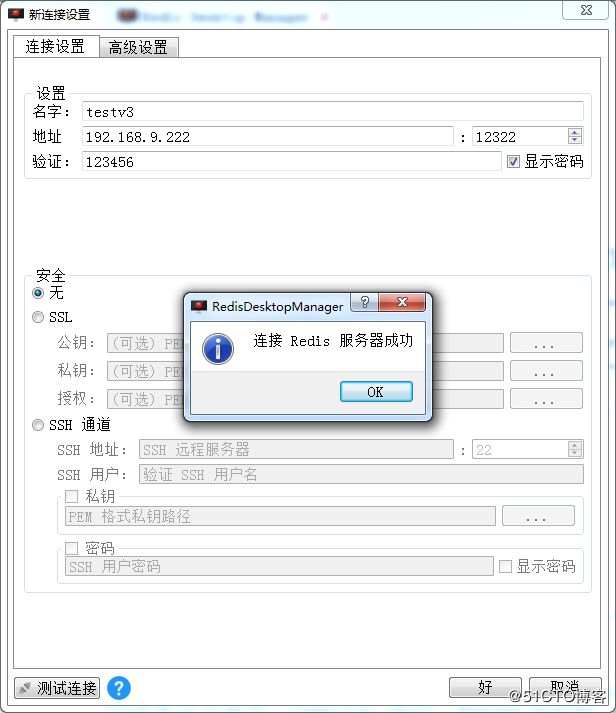
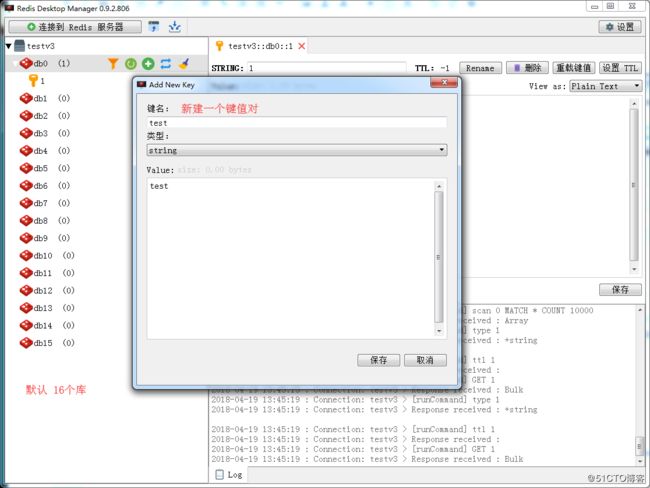
telnet 测试一下新建的值是否成功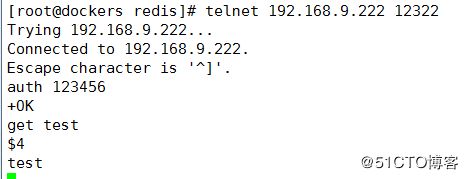
2、redis数据类型
redis中存储数据是通过 key-value存储的 ,对于 value的类型有以下几种:
- 字符串
- hash类型
- list
- set
- sortedsset (zset)
运维 用得最多的其实也就是做为持久化方案了
在redis中命令是忽略大小写的,而key是不忽略大小写的。
2.1、字符串string
注:这里使用的是reis客户端显示的是 主机名> 如果直接用redis-cli那就是 IP:port>
2.1.1、设置\查看\删除
1、单个键值对
命令: 语法: set key value
testv3:0>set test 123
"OK"
取值: 语法: get key
testv3:0>get test
"123"
2、多个键值对
命令: 语法: mset key value [key value ...]
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3
OK
取值: 语法:mget key [key ...]
127.0.0.1:6379> mget k1 k2 k3
1) "v1"
2) "v2"
3) "v3"
3、取值并赋值
命令: 语法: getset key value
第一次获取 kg1没有所以就是nil 第二次有了那么取出然后重新赋值
127.0.0.1:6379> getset kg1 vg1
(nil)
127.0.0.1:6379> get kg1
"vg1"
127.0.0.1:6379> getset kg1 vg2
"vg1"
127.0.0.1:6379> get kg1
"vg2"
4、追加
语法:APPEND key value
127.0.0.1:6379> set app1 hello
OK
127.0.0.1:6379> APPEND app1 world
(integer) 10
127.0.0.1:6379> get app1
"helloworld"
5、获取string长度
strlen 命令返回键值的长度,如果键不存在返回0
127.0.0.1:6379> STRLEN app1
(integer) 10
127.0.0.1:6379> STRLEN app2 # 找一个不存在的值
(integer) 0
6、删除
命令:语法:DEL key [key ...]
127.0.0.1:6379> DEL kg1
(integer) 1
127.0.0.1:6379> del k1 k2
(integer) 2
127.0.0.1:6379> mget k1 k3 # 这个是mset 设置的值。
1) (nil)
2) "v3"
2.1.2、数值增减
1、递增
递增数字,当存储的字符串是整数时,使用INCR,其作用是让当前键值递增,并返回递增后的值。
命令:语法:incr key
127.0.0.1:6379> set num 1
OK
127.0.0.1:6379> INCR num
(integer) 2
127.0.0.1:6379> INCR num2 # 没有设定,默认为1
(integer) 1
127.0.0.1:6379> INCR num2
(integer) 2
增加指定的整数
127.0.0.1:6379> INCRBY num2 3
(integer) 5
127.0.0.1:6379> INCRBY num2 3
(integer) 8
2、递减
递增数字,当存储的字符串是整数时,使用DECR,其作用是让当前键值递减,并返回递减后的值。
127.0.0.1:6379> DECR num2
(integer) 7
127.0.0.1:6379> DECR num2
(integer) 6
减少指定的整数
127.0.0.1:6379> DECRBY num2 3
(integer) 3
127.0.0.1:6379> DECRBY num2 3
(integer) 02.2、hash类型
假设有 假设有 User对象以 JSON序列化的形式存储到 Redis中, User对象有 id,username、 password、age、name等属性,存储的过程如下:
保存、更新: User对象 --> json(string) --> redis
如果在业务上只是更新 age属性,其他的并不做更新我应该怎么呢? 如果仍然采用上边的方法在传输、处理时会造成资源浪费,下讲hash可以很好的解决这个问题
hash叫散列类型,它提供了字段和值的映射。字符段只能是字符串类型,不支持散列类型、集合类型等其它类型,如下

2.2.1、设定值
HSET命令不区分插入和更新操作,当执行插入操作时HSET命令返回1,当执行更新操作时返回0。
1、一个设置一个字段值
语法:HSET key field value
按上图理解就是 id是表为 uid是字段 1是值
127.0.0.1:6379> HSET id uid 1
(integer) 1
2、一次设置多个字段值
127.0.0.1:6379> HMSET id name xiong age 111 addr bj
OK
3、当字段不存在时赋值,类似HSET,区别在于如果字段存在,该命令不执行任何操作
语法: HSETNX key field value
如果 id表中 uid字段不存在那么就设置值为2,存在就不操作
语法: HSETNX key field value
127.0.0.1:6379> HSETNX id uid 2
(integer) 0
4、增加值
语法: HINCRBY key field increment
127.0.0.1:6379> HSET id age 111
(integer) 1
127.0.0.1:6379> HINCRBY id age 10
(integer) 1212.2.2、获取值
1、获取单个字段
语法: HGET key field
127.0.0.1:6379> HGET id name
"xiong"
2、获取多个字段
语法: HMGET key field [field ...]
127.0.0.1:6379> HMGET id name age
1) "xiong"
2) "111"
3、获取全部的值 奇数是key 偶数是值
127.0.0.1:6379> HGETALL id
1) "uid"
2) "1"
3) "name"
4) "xiong"
5) "age"
6) "111"
7) "addr"
8) "bj"
4、获取键值内容
语法: HKEYS KEY KVALS KEY HLEN KEY
4.1、获取表的键
127.0.0.1:6379> HKEYS id
1) "addr"
2) "age"
4.2、获取表的值
127.0.0.1:6379> HVALS id
1) "bj"
2) "121"
4.3、获取表的字符数
127.0.0.1:6379> HLEN id
(integer) 2
2.2.3、删除
1、删除单个
127.0.0.1:6379> HDEL id uid
(integer) 1
2、删除多个
127.0.0.1:6379> HDEL id name age
(integer) 2
3、查看状态
127.0.0.1:6379> HGETALL id
1) "addr"
2) "bj"
4、判断是否存在
存在返回1,不存在为0
4.1、不存在
127.0.0.1:6379> HEXISTS id s
(integer) 0
4.2、存在
127.0.0.1:6379> HEXISTS id age
(integer) 12.3、List类型
列表类型(list)可以存储一个有序的字符串列表,常用的操作是向列表两端添加元素,或者获得列表的某一个片段。
列表类型内部是使用双向链表(double linked list)实现的,所以向列表两端添加元素的时间复杂度为0(1),获取越接近两端的元素速度就越快。这意味着即使是一个有几千万个元素的列表,获取头部或尾部的10条记录也是极快的。
2.3.1、ArrayList与LinkedList的区别
ArrayList使用数组方式存储数据,所以根据索引查询数据速度快,而新增或者删除元素时需要设计到位移操作,所以比较慢。
LinkedList使用双向链表方式存储数据,每个元素都记录前后元素的指针,所以插入、删除数据时只是更改前后元素的指针指向即可,速度非常快。然后通过下标查询元素时需要从头开始索引,所以比较慢,但是如果查询前几个元素或后几个元素速度比较快。
Arraylist查询快,而新增删除慢
Linkedlist查询慢,而新增快。
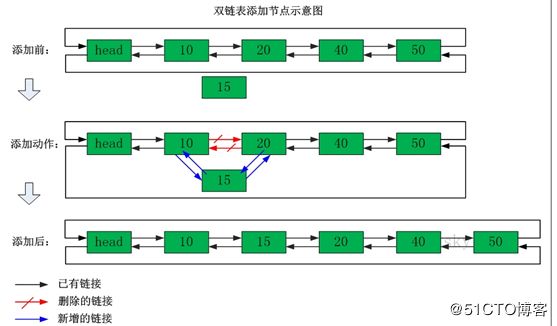

2.3.2、插入\删除
插入:LPUSH, RPUSH 删除:LPOP, RPOP
1、从列表右边插入
语法:LPUSH key value [value ...]
127.0.0.1:6379> LPUSH list1 1 2 3
(integer) 3
2、从列表右边插入
语法:RPUSH key value [value ...]
127.0.0.1:6379> RPUSH list1 3 2 1
(integer) 6
删除命令会分二步完成:
第一步是将列表左边或右边的元素从列表中移除
第二步是返回被移除的元素值。
3、LPOP 从左边删除一个元素
语法: LPOP key
127.0.0.1:6379> LPOP list1
"3"
4、RPOP 从最边删除一个元素
语法: RPOP key
127.0.0.1:6379> RPOP list1
"1"
5、LREM 删除第coune 个值为 你定义 的值 如
语法: LREM key count value
当count>0时, LREM会从列表左边开始删除。
当count<0时, LREM会从列表后边开始删除。
当count=0时, LREM删除所有值为value的元素。
# 这里的意思是: 删除 list1 key 总共删除2个 值为2的值 count删除多个少
127.0.0.1:6379> LRANGE list1 0 -1
1) "2"
2) "3"
3) "2"
127.0.0.1:6379> LREM list1 2 2
(integer) 2
再次查看就只有3了
关系图 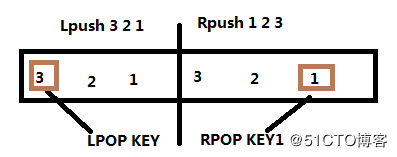
2.3.3、查看
1、查看列表
语法:LRANGE key start stop
127.0.0.1:6379> LRANGE list1 0 -1
1) "2"
2) "1"
3) "3"
4) "2"
2、获取列表的个数
语法: LLEN KEY
127.0.0.1:6379> LLEN list1
(integer) 4
先插入几个值,用于下面的测试 , LPUSH 是 倒过来 插入 比如 l1 l2 l3 那插入就是 l3 l2 l1 , 是键盘上的L不是1
127.0.0.1:6379> LPUSH list1 l1 l2 l3 l4
(integer) 5
127.0.0.1:6379> RPUSH list1 l1 l2 l3 l4
(integer) 9
3、获取指定的值
语法:LINDEX key index
索引是从0开始比如
127.0.0.1:6379> LRANGE list1 0 -1
1) "l4"
2) "l3"
3) "l2"
127.0.0.1:6379> LINDEX list1 1
"l3"
127.0.0.1:6379> LINDEX list1 0
"l4"2.3.4、向列表中插入元素
通过prvot 查找元素 然后通过 before|after选择插在前面还是后面
1、插入元素
可选择在元素前 before 或者元素后 after pivot: 元素, value:元素前或后的值
语法: LINSERT key BEFORE|AFTER pivot value
127.0.0.1:6379> LRANGE list1 0 -1
1) "l4"
2) "l3"
3) "l2"
....
1.1、元素后
127.0.0.1:6379> LINSERT list1 after l3 l3.5
(integer) 10
127.0.0.1:6379> LRANGE list1 0 -1
1) "l4"
2) "l3"
3) "l3.5"
4) "l2"
.....
1.2、元素前
注意:它这只能是插在前面几行,例
127.0.0.1:6379> LINSERT list1 BEFORE l2 l2.5
(integer) 11
127.0.0.1:6379> LRANGE list1 0 -1
1) "l4"
2) "l3"
3) "l3.5"
4) "l2.5"
5) "l2"
2、将元素从一个列表转移到另一个列表中
语法: RPOPLPUSH source destination
127.0.0.1:6379> RPOPLPUSH list1 list2
"l4"
貌似只能复制第一个值
127.0.0.1:6379> LRANGE list2 0 -1
1) "l4"
2.4、Set类型(集合类型)
集合中的数据是不重复且没有顺序。 类似py中 {a,b,c},自动去重功能
集合类型和列表类型的对比:
2.4.1、增加\删除元素\查看
1、增加多个元素 存在返回0,不存在直接添加
语法:SADD key member [member ...]
127.0.0.1:6379> SADD set1 s1 s2 s3 s4
(integer) 4
127.0.0.1:6379> SADD set1 s5
(integer) 1
127.0.0.1:6379> SADD set1 s1
(integer) 0
2、删除多个元素,存在直接删除,不存在返回0
语法: SREM key member [member ...]
127.0.0.1:6379> SREM set1 s5 s4
(integer) 2
127.0.0.1:6379> SREM set1 s6
(integer) 0
3、随机删除
语法: SPOP KEY
127.0.0.1:6379> SPOP set1
"4"
127.0.0.1:6379> SMEMBERS set1
1) "2"
2) "1"
3) "3"
4、查看所有元素
语法: SMEMBERS key
127.0.0.1:6379> SMEMBERS set1
1) "s2"
2) "s3"
3) "s1"
5、查看元素是否在集合中,在返回1,不存在返回0
语法:SISMEMBER key member
127.0.0.1:6379> SISMEMBER set1 s1
(integer) 1
127.0.0.1:6379> SISMEMBER set1 sa
(integer) 0
6、获取key的长度
语法 SCARD KEY
127.0.0.1:6379> SCARD set1
(integer) 4
2.4.2、运算命令(差集,并集,交集)
sdiff: 差集 sinter: 交集 并集:SUNION
基础选项
127.0.0.1:6379> SADD set1 1 2 3 4
(integer) 4
127.0.0.1:6379> SADD set2 1 2 5 6 7
(integer) 5
1、集合的差集运算 A-B
意为: 只属于私有的属性, 比如A有1 2 3 ,B有2 3 4 那么就意味着 A的私有只有1,B的私有只有4
127.0.0.1:6379> SDIFF set1 set2
1) "3"
2) "4"
127.0.0.1:6379> SDIFF set2 set1
1) "5"
2) "6"
3) "7"
2、集合的交集运算 A ∩ B
意为: 属于A,B共同有的属性
127.0.0.1:6379> SINTER set1 set2
1) "2"
2) "1"
3、集合的并集运算A ∪ B
意为: 属于A的又属于B的,大杂烩
127.0.0.1:6379> SUNION set1 set2
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"2.5、SortedSet类型zset 有序集合
在某些方面有序集合和列表类型有些相似。
- 1、二者都是有序的。
- 2、二者都可以获得某一范围的元素。
但是,二者有着很大区别:- 1、列表类型是通过链表实现的,获取靠近两端的数据速度极快,而当元素增多后,访问中间数据的速度会变慢。
- 2、有序集合类型使用散列表实现,所有即使读取位于中间部分的数据也很快。
- 3、列表中不能简单的调整某个元素的位置,但是有序集合可以(通过更改分数实现)
- 4、有序集合要比列表类型更耗内存。
2.5.1、新建\查看\删除
1、新建一个有序列表
语法: ZADD key [NX|XX] [CH] [INCR] score member [score member ...]
分数在前,而键在后
127.0.0.1:6379> ZADD za1 80 zhangsan 99 lisi 99 wangwu
(integer) 3
127.0.0.1:6379> ZADD za1 99 zhangsan
(integer) 0
2、查看
语法: ZSCORE key member
127.0.0.1:6379> ZSCORE za1 zhangsan
"99"
3、删除
语法: ZREM key member [member ...]
127.0.0.1:6379> ZREM za1 zhangsan
(integer) 1
127.0.0.1:6379> ZREM za1 zhangsans
(integer) 0
4、按照排名范围删除
127.0.0.1:6379> ZREMRANGEBYRANK za1 0 -1
(integer) 2
127.0.0.1:6379> ZRANGE za1 0 -1
(empty list or set)
5、按照分数范围删除
zadd za1 80 zhangs 60 lisi 65 tom 77 xiaoge
(integer) 4
127.0.0.1:6379> ZREMRANGEBYSCORE za1 60 70
(integer) 2
127.0.0.1:6379> ZREVRANGE za1 0 -1 WITHSCORES
1) "zhangs"
2) "80"
3) "xiaoge"
4) "77"
2.5.2、获得排名在某个范围的元素列表
1、从小到大顺序排列
语法: ZRANGE key start stop [WITHSCORES]
127.0.0.1:6379> ZRANGE za1 0 -1
1) "lisi"
2) "wangwu"
2、从大到小顺序排列
语法: ZREVRANGE key start stop [WITHSCORES]
127.0.0.1:6379> ZREVRANGE za1 0 -1
1) "wangwu"
2) "lisi"
3、获得元素的分数
127.0.0.1:6379> ZRANGE za1 0 -1 WITHSCORES
1) "lisi"
2) "99"
3) "wangwu"
4) "99"
4、获得指定分数范围的元素
语法: ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
127.0.0.1:6379> ZRANGEBYSCORE za1 80 100 limit 0 3
1) "lisi"
2) "wangwu"
5、增加某个元素的值
返回值是更改后的分数
语法:ZINCRBY key increment member 如果存在则是直接叠加,不存在就新建一个
127.0.0.1:6379> ZINCRBY za1 80 lisi
"179"
6、获取元素的个数
语法: ZCARD KEY
127.0.0.1:6379> ZCARD za1
(integer) 2
7、获得指定分数范围
语法:ZCOUNT key min max
127.0.0.1:6379> ZCOUNT za1 80 100
(integer) 1
2.6、Keys (重要)
Redis在实际使用过程中更多的用作缓存,然而缓存的数据一般都是需要设置生存时间的,即:到期后数据销毁。
EXPIRE key seconds 设置key的生存时间(单位:秒)key在多少秒后会自动删除
TTL key 查看key生于的生存时间
PERSIST key 清除生存时间
PEXPIRE key milliseconds 生存时间设置单位为:毫秒例
127.0.0.1: 6379> set test 1 设置test的值为1
OK
127.0.0.1: 6379> get test 获取test的值
"1"
127.0.0.1: 6379> EXPIRE test 5 设置test的生存时间为5秒
(integer) 1
127.0.0.1: 6379> TTL test 查看test的生于生成时间还有1秒删除
(integer) 1
127.0.0.1: 6379> TTL test
(integer) -2
127.0.0.1: 6379> get test 获取test的值,已经删除
(nil)2.6.1、查看\删除\重命名
1、查看键值
语法: KEYS pattern
127.0.0.1:6379> KEYS s*
1) "sa1"
2、删除
语法: DEL KEY
127.0.0.1:6379> DEL za1
(integer) 1
3、重命名
语法: RENAME key newkey
127.0.0.1:6379> KEYS s*
1) "s3"
127.0.0.1:6379> RENAME s3 ss3
OK
127.0.0.1:6379> KEYS s*
1) "sa1"
4、查看类型
语法: TYPE key
127.0.0.1:6379> TYPE ss3
string
127.0.0.1:6379> ZADD za1 80 zhangshi
(integer) 1
127.0.0.1:6379> type za1
zset
3、持久化方案
两种: RDB,AOF 详细优缺点比较
3.1、RDB持久化
RDB持久化是通过快照完成的,当符合一定条件时Redis会自动将内存中的数据进行快照并持久化到硬盘中。
RDB是redis默认采用的持久化方式。
3.1.1、持久化条件配置 :
save 900 1
save 300 10
save 60 10000save 开头的一行就是持久化配置,可以配置多个条件(每行配置一个条件),每个条件之间是“或”的关系。
“save 900 1”表示15分钟(900秒钟)内至少1个键被更改则进行快照。
“save 300 10”表示5分钟(300秒)内至少10个键被更改则进行快照。
“save 60 10000”表示1分钟(60秒)内至少1万个键被更改则进行快照。
3.1.2、配置快照文件的名称
设置dbfilename指定rdb快照文件的名称
dbfilename dump.rdb
设置dir指定rdb快照文件的位置
dir ./ # 这里指的是当前路径 Redis启动后会读取RDB快照文件,将数据从硬盘载入到内存。根据数据量大小与结构和服务器性能不同,这个时间也不同。通常将记录一千万个字符串类型键、大小为1GB的快照文件载入到内存中需要花费20~30秒钟。
通过RDB方式实现持久化,一旦Redis异常退出,就会丢失最后一次快照以后更改的所有数据。这就需要开发者根据具体的应用场合,通过组合设置自动快照条件的方式来将可能发生的数据损失控制在能够接受的范围。
如果数据很重要以至于无法承受任何损失,则可以考虑使用AOF方式进行持久化。
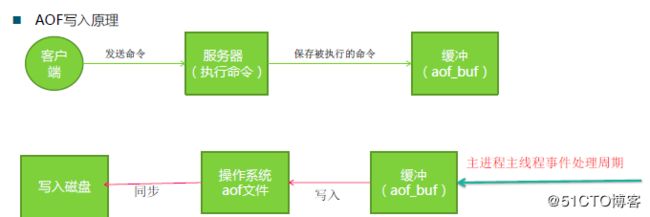
3.2、AOF持久化
AOF持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集。
默认情况下Redis没有开启AOF(append only file)方式的持久化
3.2.1、AOF启动配置方法
1、配置参数
appendonly yes 或 127.0.0.1:6379> CONFIG SET appendonly yes
开启AOF持久化后每执行一条会更改Redis中的数据的命令,Redis就会将该命令写入硬盘中的AOF文件。
2、设置dir指定rdb快照文件的位置
dir ./ # 这里指的是当前路径
3、文件名称设置
appendfilename append.aof
默认的文件名是appendonly.aof,可以通过appendfilename参数修改:
4、AOF与RDB同时共存时。
首先加载的是AOF文件,当AOF文件命令行因为最后一次导入失败文件出错,可以使用 redis-check-aof --fix file.aof文件可以进行修复
5、appenfsync 同步选择
always: 同步持久化,每次发生数据变更会立即记录到磁盘,性能较差但数据完整性比较好
everysec:默认配置,异步操作,每秒记录,如果一秒内宕机有数据丢失
no: 