进行最大池化操作主要提供以下5个函数:
- image get_maxpool_image(maxpool_layer l);
- maxpool_layer make_maxpool_layer(int batch, int h, int w, int c, int size, int stride, int padding);
- void resize_maxpool_layer(maxpool_layer *l, int w, int h);
- void forward_maxpool_layer(const maxpool_layer l, network net);
- void backward_maxpool_layer(const maxpool_layer l, network net);
image get_maxpool_image(...)##
获取这一层的 max pool 处理过后的图像
image get_maxpool_image(maxpool_layer l)
{
int h = l.out_h;
int w = l.out_w;
int c = l.c;
return float_to_image(w,h,c,l.output);
}
maxpool_layer make_maxpool_laer(...)##
构建 maxpool_layer,参数详情见layer
maxpool_layer make_maxpool_layer(int batch, int h, int w, int c, int size, int stride, int padding)
{
maxpool_layer l = {0};
l.type = MAXPOOL;
l.batch = batch;
l.h = h;
l.w = w;
l.c = c;
l.pad = padding;
l.out_w = (w + 2*padding)/stride;
l.out_h = (h + 2*padding)/stride;
l.out_c = c;
l.outputs = l.out_h * l.out_w * l.out_c;
l.inputs = h*w*c;
l.size = size;
l.stride = stride;
int output_size = l.out_h * l.out_w * l.out_c * batch;
l.indexes = calloc(output_size, sizeof(int));
l.output = calloc(output_size, sizeof(float));
l.delta = calloc(output_size, sizeof(float));
l.forward = forward_maxpool_layer;
l.backward = backward_maxpool_layer;
#ifdef GPU
l.forward_gpu = forward_maxpool_layer_gpu;
l.backward_gpu = backward_maxpool_layer_gpu;
l.indexes_gpu = cuda_make_int_array(output_size);
l.output_gpu = cuda_make_array(l.output, output_size);
l.delta_gpu = cuda_make_array(l.delta, output_size);
#endif
fprintf(stderr, "max %d x %d / %d %4d x%4d x%4d -> %4d x%4d x%4d\n", size, size, stride, w, h, c, l.out_w, l.out_h, l.out_c);
return l;
}
这里重点提一下 indexes ,用来标示输出 feature map 中元素对应的输入 feature map 元素的下标
void resize_maxpool_layer(...)##
调整 maxpool layer的大小,主要是更改 height 和 width,并修改它们所影响到的其他值,并为参数值 or feature map 值重新分配存储空间。
void resize_maxpool_layer(maxpool_layer *l, int w, int h)
{
l->h = h;
l->w = w;
l->inputs = h*w*l->c;
l->out_w = (w + 2*l->pad)/l->stride;
l->out_h = (h + 2*l->pad)/l->stride;
l->outputs = l->out_w * l->out_h * l->c;
int output_size = l->outputs * l->batch;
l->indexes = realloc(l->indexes, output_size * sizeof(int));
l->output = realloc(l->output, output_size * sizeof(float));
l->delta = realloc(l->delta, output_size * sizeof(float));
#ifdef GPU
cuda_free((float *)l->indexes_gpu);
cuda_free(l->output_gpu);
cuda_free(l->delta_gpu);
l->indexes_gpu = cuda_make_int_array(output_size);
l->output_gpu = cuda_make_array(l->output, output_size);
l->delta_gpu = cuda_make_array(l->delta, output_size);
#endif
}
forward_maxpool_layer(...)##
对输出 feature map 的每个元素进行遍历,求其在输入 feature map 对应的 max 位置,并把它拷贝下来
void forward_maxpool_layer(const maxpool_layer l, network net)
{
int b,i,j,k,m,n;
int w_offset = -l.pad;
int h_offset = -l.pad;
int h = l.out_h;
int w = l.out_w;
int c = l.c;
for(b = 0; b < l.batch; ++b){
for(k = 0; k < c; ++k){
for(i = 0; i < h; ++i){
for(j = 0; j < w; ++j){
int out_index = j + w*(i + h*(k + c*b));
float max = -FLT_MAX;
int max_i = -1;
//输出 feature map element 对应的输入 feature map 的滑窗
for(n = 0; n < l.size; ++n){
for(m = 0; m < l.size; ++m){
int cur_h = h_offset + i*l.stride + n;
int cur_w = w_offset + j*l.stride + m;
int index = cur_w + l.w*(cur_h + l.h*(k + b*l.c));
int valid = (cur_h >= 0 && cur_h < l.h &&
cur_w >= 0 && cur_w < l.w);
float val = (valid != 0) ? net.input[index] : -FLT_MAX;
max_i = (val > max) ? index : max_i;
max = (val > max) ? val : max;
}
}
l.output[out_index] = max;
l.indexes[out_index] = max_i;
}
}
}
}
}
backward_maxpool_layer(...)##
可以参见 network 中的 backward 函数,其中的 net.delta 指的是前一层的 delta,也即每一层的 delta 是由前一层算出来的,最后一层的 delta 是前馈的时候就算出来的。
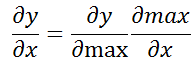
链式法则
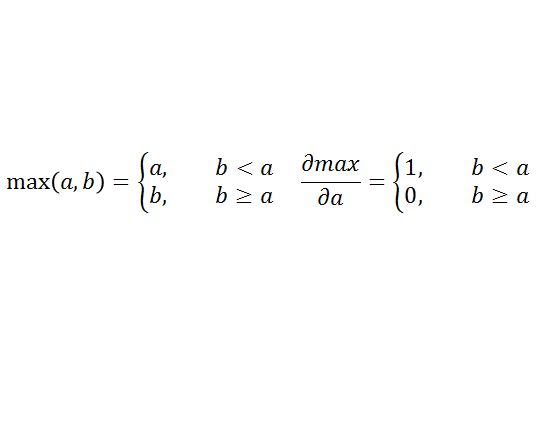
Paste_Image.png
所以就是:
是 max值所属的 index ,直接把前一层的 delta 直接拿过来
非 max值, 置 0(default init value)
void backward_maxpool_layer(const maxpool_layer l, network net)
{
int i;
int h = l.out_h;
int w = l.out_w;
int c = l.c;
for(i = 0; i < h*w*c*l.batch; ++i){
int index = l.indexes[i];
net.delta[index] += l.delta[i];
}
}