作者介绍:姜生,PP云高级技术经理,10余年视频编解码算法设计优化,流媒体应用等领域开发经验。
一 、VMAF 技术介绍:
VMAF 的全称是:Visual Multimethod Assessment Fusion,视频质量多方法评价融合。这项技术是由美国Netflix公司开发的一套主观视频质量评价体系。2016年1月,VMAF 正式开源;
下载地址:
https://github.com/Netflix/vmaf
二 、通行视频质量评价方法的局限:
评价一个编码后的视频流与压缩前的视频流质量对比值,通行的方法是PSNR(峰值信噪比),或者SSIM(结构相似度)。这些是客观评价方法。这些方法评价的结果与主观的感受有时候相差很大,请看下图(来自Netflix 的官网):

图一
上面四幅图,取自4幅静态画面,畸变程度不一样。用PSNR指标来评分,上面两幅图的PSNR值大约为31dB, 下方两个的PSNR值约为34dB,这表明上面两幅图PNSR 值相当,下面两幅图的PSNR值也相当。如果让人眼来主观评价呢,对于左侧上下两幅“人群”图片,很难察觉有何差异,但是右侧两幅“狐狸”视频的差异就很明显了。Netflix综合不同观众的评价,对上下两个“人群”给出的主观分数是82(上方)和96(下方),而两个“狐狸”的分数分别是27(上方)和58(下方)。
上面的示例说明PSNR一类的客观评价与实际的主观感受相差较大。这说明这种方法不足以全面正确的评价视频的质量,为此Netflix 决定寻找新的方法。
三、Neflix对视频源特性的分析:
- 收集与用例密切相关的数据集:
虽然针对视频质量指标的设计和测试已经有可以公开使用的数据库,但这些数据库的内容缺乏多样性。而多样性正是流媒体服务的最大特点。由于视频质量的评估远不仅仅是压缩失真的评估,所以应该考虑更广范围的画质损失,不仅有压缩导致的损失,还有传输过程中的损失、随机噪声,以及几何变形等情况。
- 视频源的特性:
作为流媒体公司, Netflix 提供了适合各类人群观看的大量影视内容,例如儿童内容、动漫、动作片、纪录片,视频讲座等. 另外这些内容还包含各种底层源素材特征,例如胶片颗粒、传感器噪声、计算机生成的材质、始终暗淡的场景或非常明亮的色彩等。过去通行的质量指标并没有考虑不同类型的源内容,如动漫或者视频讲座一类,也未考虑胶片颗粒,而在专业娱乐内容中这些都是非常普遍的信号特征。
- 失真的来源:
一般而言,流播视频是通过TCP传输的,丢包和误码绝对不会导致视觉损失。这就使得编码过程中的两类失真最终影响到观众所感受到的体验质量(QoE):压缩失真以及缩放失真。
为了针对不同的用例构建数据集,Netflix选择了34个源短片作为样本(参考视频),每个短片长度是6秒,主要来自于流行的电视剧和电影。源短片包含具备各种高级特征的内容(动漫、室内/室外、镜头摇移、面部拉近、人物、水面、显著的物体、多个物体)以及各种底层特性(胶片噪声、亮度、对比度、材质、活动、颜色变化、色泽浓郁度、锐度)。将这些源短片编码为H.264/AVC格式的视频流,分辨率介于384x288到1920x1080之间,码率介于375kbps到20,000kbps之间,最终获得了大约300个畸变(Distorted)视频。这些视频涵盖了很大范围的视频码率和分辨率,足以反映实际生活中多种多样的网络环境。
接着,通过主观测试确定非专业观察者对于源短片编码后视频画质损失的评价。参考视频和畸变视频将按顺序显示在家用级别的电视机上。如果畸变视频编码后的分辨率小于参考视频,则会首先放大至源分辨率随后才显示在电视上。将所有观察者针对每个畸变视频的分数汇总在一起计算出微分平均意见分数(Differential Mean Opinion Score)即DMOS,并换算成0-100的标准分,其中100分是指参考视频的分数。
四、评价的结果:
Netflix 推出了二维散点图来说明上面分析的结果,我从中选取四幅有代表性的散点图。
散点图中,横轴对应了观察者给出的DMOS分数,纵轴对应了不同质量指标预测的分数。每一个点代表了一个畸变视频。我们为下列四个指标绘制了散点图:
-
PSNR亮度分量(Luminancecomponent)
-
SSIM
-
Multiscale FastSSIM
- PSNR-HVS
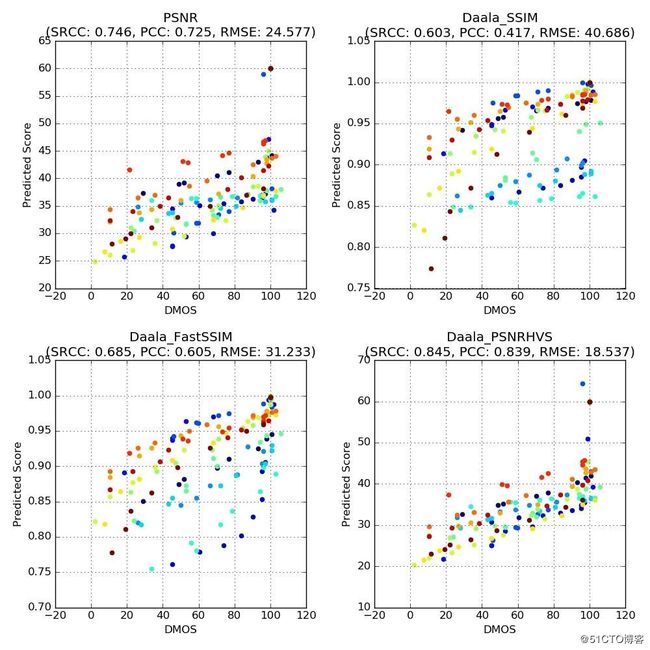
图二
注意:相同颜色的点对应了畸变视频和相应参考视频的结果。从图中可以看出,这些指标的分数与观察者给出的DMOS分数并非始终一致。以左上角的PSNR图为例,PSNR值约为35dB,而“人工校正”的DMOS值的范围介于10(存在恼人的画质损失)到100(画质损失几乎不可察觉)之间。
上图中的专有名词:
斯皮尔曼等级相关系数(Spearman’srank correlation coefficient,SRCC)
皮尔森积差相关系数(Pearsonproduct-moment correlation coefficient,PCC)
上面的SRCC, PCC属于概率统计的概念,可以参考相关文档,这两个值越大越好。
为了找到一个有效的评价标准,必须选定一个有效的指标,指标必须呈现与DMOS 有限的单调性。下图中选定了三个典型的参考视频:一个高噪声视频,一个CG动漫,一个电视剧,并用每个视频的不同畸变版本的预测分数与DMOS分数创建散点图。为了获得有效的相对质量分数,我们希望不同视频短片在质量曲线的相同范围内可以实现一致的斜率(Slope)。
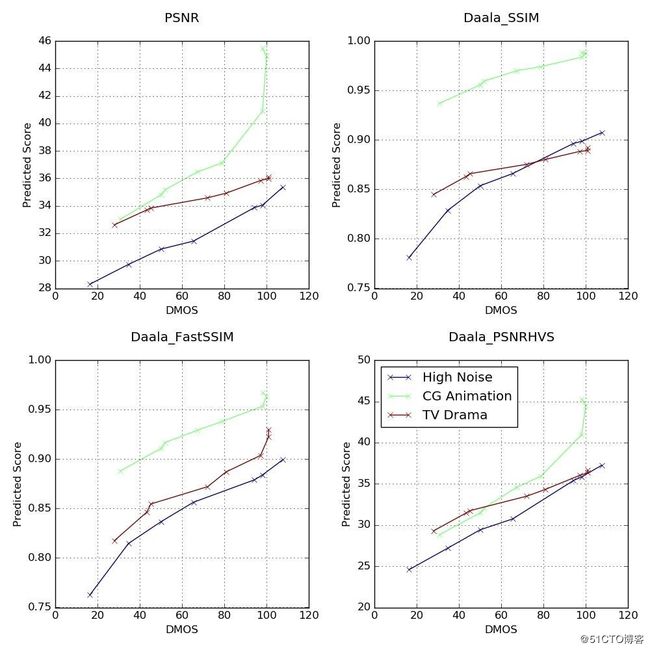
PSNR散点图中,在34dB到36dB的范围内,电视剧PSNR数值大约2dB的变化对应的DMOS数值变化约为50(50到100),但CG动漫同样范围内类似的2dB数值变化对应的DMOS数值变化低于20(40到60)。虽然CG动漫和电视剧短片的SSIM和FastSSIM体现出更为一致的斜率但表现依然不够理想。
简单总结来说,传统指标不适合用来评价视频质量。为了解决这一问题,我们使用了一种基于机器学习的模型设计能真实反映人对视频质量感知情况的指标。下文将介绍这一指标。
五、 VMAF 方法:
基本想法:
面对不同特征的源内容、失真类型,以及扭曲程度,每个基本指标各有优劣。通过使用机器学习算法(支持向量机(Support Vector Machine,SVM)回归因子)将基本指标“融合”为一个最终指标,可以为每个基本指标分配一定的权重,这样最终得到的指标就可以保留每个基本指标的所有优势,借此可得出更精确的最终分数。我们还使用主观实验中获得的意见分数对这个机器学习模型进行训练和测试。
VMAF可在支持向量机(SVM)回归因子中使用下列基本指标进行融合:
- 视觉信息保真度(Visual Information Fidelity,VIF):
VIF是一种获得广泛使用的图像质量指标,在最初的形式中,VIF分数是通过将四个尺度(Scale)下保真度的丢失情况结合在一起衡量的。在VMAF中我们使用了一种改进版的VIF,将每个尺度下保真度的丢失看作一种基本指标。
- 细节丢失指标(Detail LossMetric,DLM):
LM是一种图像质量指标,其基本原理在于:分别衡量可能影响到内容可见性的细节丢失情况,以及可能分散观众注意力的不必要损失。这个指标最初会将DLM和Additive Impairment Measure(AIM)结合在一起算出最终分数。
- 运动:
这是一种衡量相邻帧之间时域差分的有效措施。计算像素亮度分量的均值反差即可得到该值。
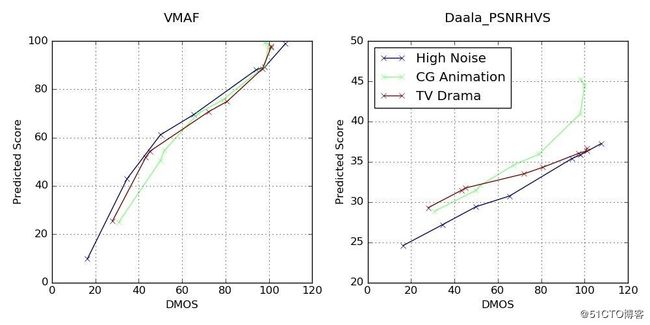
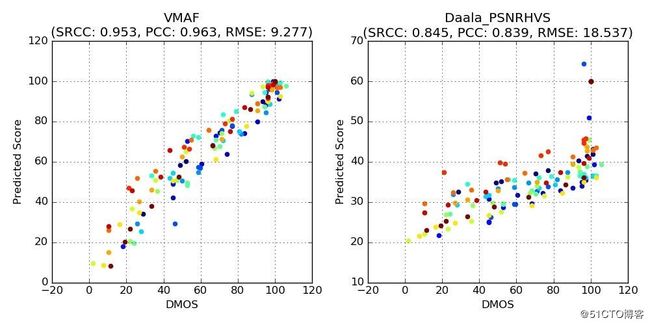
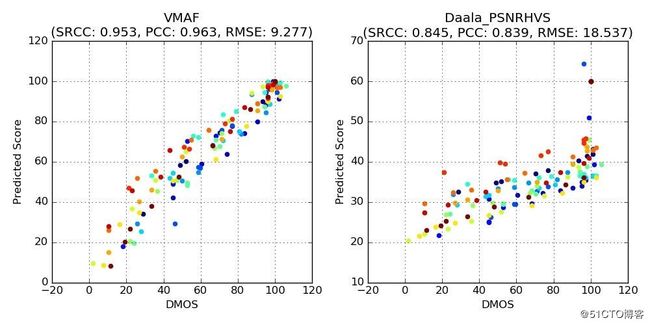
下列散点图对所选参考短片(高噪声视频、CG动漫、电视剧)得出的VMAF指标分数。为了方便对比,我们也附上了上文提到的结果最理想的PSNR-HVS指标散点图。无疑VMAF的效果更好。
六 总结:
改善视频压缩标准,以更智能的方式确定最实用的编码系统和编码一整套参数,这些要求在当今的互联网大环境中十分重要。我们认为,使用传统的指标会妨碍到视频编码技术领域的技术进步,然而单纯依赖人工视觉测试在很多情况下并不可行。因此我们希望VMAF能解决这一问题,使用来自我们内容中的样本帮助大家设计和验证算法。
七 、拓展:
- per title 编码:
我们希望能利用VMAF 绘制每一个clip 的不同分辨率下的bitrate vs MOS 的曲线图,并保存这个曲线图。在实际点播的时候,根据resolution,MOS 选择一个最佳的bitrate,来编码:
下面是我绘制的Bkimono_1920x1080_8_24_240.yuv 的散点图:
设置编码参数时,如果需要达到MOS=80的清晰度,bitrate 可以选择2.0MB. 可以看出当bitrate 超过3MB 后,MOS 值变化非常缓慢,对于指定的MOS 值,我们可以选择一个bitrate 下降20%甚至更多的bitrate的编码参数,但是MOS 不会下降1%。
这中方法相比单纯通过优化编码器的方法,效果要明显很多,智能很多,同时实现起来要容易。应该就是当前窄带高清的理念了。
- per trunk 编码:
对于每一个clip 而言,不同的gop,或者不同的时间段,视频流的细节和运动特点不一样,可以用VMAF 的方法为每一个时间段做评价,进而实时调整编码参数,在同样的质量前提下,尽量降低码率。