CoreText 是用于处理文字和字体的底层技术。它直接和 Core Graphics(又被称为 Quartz)打交道。Quartz 是一个 2D 图形渲染引擎,能够处理 OSX 和 iOS 中的图形显示。
Quartz 能够直接处理字体(font)和字形(glyphs),将文字渲染到界面上,它是基础库中唯一能够处理字形的模块。因此,CoreText 为了排版,需要将显示的文本内容、位置、字体、字形直接传递给 Quartz。相比其它 UI 组件,由于 CoreText 直接和 Quartz 来交互,所以它具有高速的排版效果。
CoreText使用的优势:
1.api调用更底层,效率更高
2.可以在后台渲染
3.实现复杂的图文混排需求
4.渲染速度相比于uikit 跟 uiwebview更快
缺点:
1.基于c的api对于ios开发者不是很友好
2.内存需要自己去控制,容易出现内存泄露
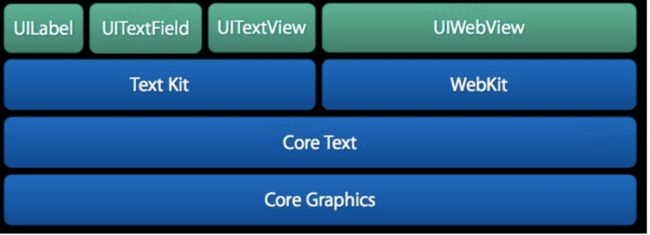
下图是 CoreText 的架构图,可以看到,CoreText 处于非常底层的位置,上层的 UI 控件(包括 UILabel,UITextField 以及 UITextView)和 UIWebView 都是基于 CoreText 来实现的。
CTRun

origin表示的是原点 基线表示的是过原点的x轴,ascent表示的是CTRun顶线距离基线的距离,descent表示的是底线距离底线的距离
首先需要设置一个回调的结构体,主要用来获取图片的宽高,图片距离顶部基线的距离,还有图片距离底部基线的距离

下图中绿色线条表示基线,黄色线条表示下行高度,绿色线条到红框最顶部的距离为上行高度,而黄色线条到红框底部的距离为行间距。因此行高的计算公式是lineHeight = Ascent + |Descent| + Leading
CoreText几个比较重要的概念

CoreText会把一行里连在一起相同属性的文字合在一起作为一个CTRun,每一行是一个CTLine,多行合在一起组成CTFrame。如上图,第一行的文字有两种样式,第一部分是加粗,第二部分是斜体,因为样式不同所以分成了两个CTRun,CTLine包含了这两个CTRun,CTFrame包含了所有CTLine。
下面这个是coreText 绘制富文本的工作流程

逐行绘制

第一步
获取上下文 也就是获取画布
CGContextRef context = UIGraphicsGetCurrentContext();
第二步
做的是坐标系的反转,因为UIKit原点是在左上角 而CoreText原点是在左下角(CoreText使用的是笛卡尔坐标系)
CGContextSetTextMatrix(contextRef, CGAffineTransformIdentity);
CGContextTranslateCTM(contextRef, 0, self.bounds.size.height);
CGContextScaleCTM(contextRef, 1.0, -1.0);
第三步
创建一块区域,用于展示coreText,可以自定义展示文字的范围
比如我绘制了一个椭圆形 作为展示的区域
CGMutablePathRef path = CGPathCreateMutable();
CGPathAddRect(path, NULL, self.bounds);
[图片上传失败...(image-ef1f52-1517822365469)]
第四步
通过NSAttributeString来生成CTFramesetter,可以通过coreText提供的api来完成
CTFramesetterRef framesetter = CTFramesetterCreateWithAttributedString((CFAttributedStringRef)attributed);
后面的传参就是一个NSAttributeString类型的属性字符串
第五步
创建CTFrame,通过coreText提供的一个API
CTFrameRef ctFrame = CTFramesetterCreateFrame(framesetter, CFRangeMake(0, attributed.length), path, NULL);
第一个参数就是上面创建的CTFramesetter实例,第二个参数传入需要绘制的文字范围
第三个参数传入的是创建的展示范围
最后
调用CTFrameDraw函数来绘制文字 传入的参数一个是第五步创建的CTFrame实例,第二个是画布
CTFrameDraw(ctFrame, contextRef);
最后 也是非常重要的一步 就是释放掉创建的实例,因为ARC是不能管理CF开头的对象
CFRelease(path);
CFRelease(framesetter);
CFRelease(ctFrame);
CoreText 图文混排的原理
其原理就是 在要插入图片的位置插入一个富文本类型的占位符,通过CTRunDelegate来设置图片
|
/* 设置一个回调结构体,告诉代理该回调那些方法 */
CTRunDelegateCallbacks callBacks;//创建一个回调结构体,设置相关参数
memset(&callBacks,0,sizeof(CTRunDelegateCallbacks));//memset将已开辟内存空间 callbacks 的首 n 个字节的值设为值 0, 相当于对CTRunDelegateCallbacks内存空间初始化
callBacks.version = kCTRunDelegateVersion1;//设置回调版本,默认这个
callBacks.getAscent = ascentCallBacks;//设置图片顶部距离基线的距离
callBacks.getDescent = descentCallBacks;//设置图片底部距离基线的距离
callBacks.getWidth = widthCallBacks;//设置图片宽度
|
然后创建一个CTRunDelegateRef
|
NSDictionary * dicPic = @{@"height":@129,@"width":@400};//创建一个图片尺寸的字典,初始化代理对象需要
CTRunDelegateRef delegate = CTRunDelegateCreate(& callBacks, (__bridge void *)dicPic);//创建代理
|
将上面创建的回调结构体传到CTRunDelegateRef中,目前就完成了图片尺寸与代理之间的绑定
三个回调的代理方法
|
static CGFloat ascentCallBacks(void * ref) { return [(NSNumber *)[(__bridge NSDictionary *)ref valueForKey:@"height"] floatValue]; }
static CGFloat descentCallBacks(void * ref) { return 0; }
static CGFloat widthCallBacks(void * ref) { return [(NSNumber *)[(__bridge NSDictionary *)ref valueForKey:@"width"] floatValue]; }
|
图片插入之前的准备工作已经完成了,下面是图片的插入操作:
首先创建一个富文本类型的图片占位符,绑定我们代理
|
unichar placeHolder = 0xFFFC;//创建空白字符
NSString * placeHolderStr = [NSString stringWithCharacters:&placeHolder length:1];//已空白字符生成字符串
NSMutableAttributedString * placeHolderAttrStr = [[NSMutableAttributedString alloc] initWithString:placeHolderStr];//用字符串初始化占位符的富文本
CFAttributedStringSetAttribute((CFMutableAttributedStringRef)placeHolderAttrStr, CFRangeMake(0, 1), kCTRunDelegateAttributeName, delegate);//给字符串中的范围中字符串设置代理
CFRelease(delegate);//释放(__bridge进行C与OC数据类型的转换,C为非ARC,需要手动管理)
|
然后将我们创建的占位符插入到富文本中
|
[attributeStr insertAttributedString:placeHolderAttrStr atIndex:12];
|
现在我们就拿到了一个带有空白占位符的属性字符串。如果把现在的属性字符串绘制到屏幕上,就是一个带有宽度400 高度129的富文本。
如何做到图文混排呢,我们只需要拿到占位符的坐标,然后在占位符的位置绘制相应的图片大小就可以了。这个就是图文混排的原理了,是不是非常简单。
首先将上面带有空白占位符的文本绘制出来
|
CTFramesetterRef frameSetter = CTFramesetterCreateWithAttributedString((CFAttributedStringRef)attributeStr);//一个frame的工厂,负责生成frame
CGMutablePathRef path = CGPathCreateMutable();//创建绘制区域
CGPathAddRect(path, NULL, self.bounds);//添加绘制尺寸
NSInteger length = attributeStr.length;
CTFrameRef frame = CTFramesetterCreateFrame(frameSetter, CFRangeMake(0,length), path, NULL);//工厂根据绘制区域及富文本(可选范围,多次设置)设置frame
CTFrameDraw(frame, context);//根据frame绘制文字
|
要绘制图片调用一个函数即可
CGContextDrawImage(context,imgFrm, image.CGImage)
上面函数中 context表示的是画布的上下文,image.cgimage也可以拿到。最重要的就是imgFrm的获取了。
首先获取到CTFrame中所有CTLine的起点
|
NSArray * arrLines = (NSArray *)CTFrameGetLines(frame);//根据frame获取需要绘制的线的数组
NSInteger count = [arrLines count];//获取线的数量
CGPoint points[count];//建立起点的数组(cgpoint类型为结构体,故用C语言的数组)
CTFrameGetLineOrigins(frame, CFRangeMake(0, 0), points);//获取起点
|
最后就是遍历我们frame中所有的CTRun,检查每一个CTRun是否绑定了图片。如果绑定了图片,那么根据CTRun所在的CTLine的origin以及CTRun在CTLine中的横向偏移来计算出CTRun的原点。
加上CTRun的尺寸,也就变成了CTRun的尺寸。
|
for (int i = 0; i < count; i ++) {//遍历线的数组
CTLineRef line = (__bridge CTLineRef)arrLines[i];
NSArray * arrGlyphRun = (NSArray *)CTLineGetGlyphRuns(line);//获取GlyphRun数组(GlyphRun:高效的字符绘制方案)
for (int j = 0; j < arrGlyphRun.count; j ++) {//遍历CTRun数组
CTRunRef run = (__bridge CTRunRef)arrGlyphRun[j];//获取CTRun
NSDictionary * attributes = (NSDictionary *)CTRunGetAttributes(run);//获取CTRun的属性
CTRunDelegateRef delegate = (__bridge CTRunDelegateRef)[attributes valueForKey:(id)kCTRunDelegateAttributeName];//获取代理
if (delegate == nil) {//非空
continue;
}
NSDictionary * dic = CTRunDelegateGetRefCon(delegate);//判断代理字典
if (![dic isKindOfClass:[NSDictionary class]]) {
continue;
}
CGPoint point = points[i];//获取一个起点
CGFloat ascent;//获取上距
CGFloat descent;//获取下距
CGRect boundsRun;//创建一个frame
boundsRun.size.width = CTRunGetTypographicBounds(run, CFRangeMake(0, 0), &ascent, &descent, NULL);
boundsRun.size.height = ascent + descent;//取得高
CGFloat xOffset = CTLineGetOffsetForStringIndex(line, CTRunGetStringRange(run).location, NULL);//获取x偏移量
boundsRun.origin.x = point.x + xOffset;//point是行起点位置,加上每个字的偏移量得到每个字的x
boundsRun.origin.y = point.y - descent;//计算原点
CGPathRef path = CTFrameGetPath(frame);//获取绘制区域
CGRect colRect = CGPathGetBoundingBox(path);//获取剪裁区域边框
CGRect imageBounds = CGRectOffset(boundsRun, colRect.origin.x, colRect.origin.y);
return imageBounds;
}
|
外层for循环呢,是为了取到所有的CTLine。
类型转换什么的我就不多说了,然后通过CTLineGetGlyphRuns获取一个CTLine中的所有CTRun。
里层for循环是检查每个CTRun。
通过CTRunGetAttributes拿到该CTRun的所有属性。
通过kvc取得属性中的代理属性。
接下来判断代理属性是否为空。因为图片的占位符我们是绑定了代理的,而文字没有。以此区分文字和图片。
如果代理不为空,通过CTRunDelegateGetRefCon取得生成代理时绑定的对象。判断类型是否是我们绑定的类型,防止取得我们之前为其他的富文本绑定过代理。
如果两条都符合,ok,这就是我们要的那个CTRun。
开始计算该CTRun的frame吧。
获取原点和获取宽高被。
通过CTRunGetTypographicBounds取得宽,ascent和descent。有了上面的介绍我们应该知道图片的高度就是ascent+descent了吧。
接下来获取原点。
CTLineGetOffsetForStringIndex获取对应CTRun的X偏移量。
取得对应CTLine的原点的Y,减去图片的下边距才是图片的原点,这点应该很好理解。
至此,我们已经获得了图片的frame了。因为只绑定了一个图片,所以直接return就好了,如果多张图片可以继续遍历返回数组。
获取到图片的frame,我们就可以绘制图片了,用上面介绍的方法。
记录一个coreText中 获取点击字符 range的方法
// 将点击的位置转换成字符串的偏移量,如果没有找到,则返回-1
-
(CFIndex)touchContentOffsetInView:(UIView *)view atPoint:(CGPoint)point data:(HTLSearchOptimizeCoreTextData *)data {
CTFrameRef textFrame = data.ctFrame;
CFArrayRef lines = CTFrameGetLines(textFrame);
if (!lines) {
return -1;}
CFIndex count = CFArrayGetCount(lines);
// 获得每一行的origin坐标
CGPoint origins[count];
CTFrameGetLineOrigins(textFrame, CFRangeMake(0,0), origins);
// 翻转坐标系
CGAffineTransform transform = CGAffineTransformMakeTranslation(0, view.bounds.size.height);
transform = CGAffineTransformScale(transform, 1.f, -1.f);
CFIndex idx = -1;
for (int i = 0; i < count; i++) {
CGPoint linePoint = origins[i]; CTLineRef line = CFArrayGetValueAtIndex(lines, i); // 获得每一行的CGRect信息 CGRect flippedRect = [self getLineBounds:line point:linePoint]; CGRect rect = CGRectApplyAffineTransform(flippedRect, transform); if (CGRectContainsPoint(rect, point)) { // 将点击的坐标转换成相对于当前行的坐标 CGPoint relativePoint = CGPointMake(point.x-CGRectGetMinX(rect), point.y-CGRectGetMinY(rect)); // 获得当前点击坐标对应的字符串偏移 idx = CTLineGetStringIndexForPosition(line, relativePoint); }}
return idx;
}
-
(CGRect)getLineBounds:(CTLineRef)line point:(CGPoint)point {
CGFloat ascent = 0.0f;
CGFloat descent = 0.0f;
CGFloat leading = 0.0f;
CGFloat width = (CGFloat)CTLineGetTypographicBounds(line, &ascent, &descent, &leading);
CGFloat height = ascent + descent;
return CGRectMake(point.x, point.y - descent, width, height);
}
http://ivanyuan.farbox.com/post/coretextyu-textkitru-men
http://qilishare.org/2016/03/01/IOS%E5%AF%8C%E6%96%87%E6%9C%AC-Coretext%E5%AD%A6%E4%B9%A0%E6%95%99%E7%A8%8B%EF%BC%88%E4%B8%80%EF%BC%89/
http://www.saitjr.com/ios/use-coretext-make-typesetting-picture-and-text.html
https://juejin.im/entry/57ce6d5767f3560057b3002c(swift)
https://junyixie.github.io/2017/03/04/iOS-Core-Text/