
新兴技术席卷全球。它们所带来的创新、机遇和威胁是独一无二的。随着它们的增长,对这些领域专家的需求也在增长。
根据最新的行业报告显示,新兴技术领域的工作,如人工智能和数据科学、机器学习等,都是最热门的新兴职业。从事人工智能或数据科学、机器学习等新兴技术领域的职业,既能带来丰厚的利润,也能激发智力。
在本文中,我整理了一些算法工程师面试问题,并给出了相应的答案。有志于算法工程师的人,以及有经验的ML专业人士,都可以在面试前利用这一点来完善一下他们的基础知识。
2019年深度学习面试必看问题
1. k -的意思和KNN是什么?
K-means是一种用于聚类问题处理的无监督算法,KNN或K近邻是一种用于回归和分类处理的有监督算法。
2.损失函数的梯度有正和负,如果随机的W值是负数,岂不是越减越小?例子中是不是只处理了梯度为正的情况。
首先说一下,梯度不是W,这个要注意。
前面也说过了,梯度是个向量,对于向量而言,正负指的是方向。我觉得这位同学想问的应该是,我们对W进行求导,值有正负的情况。
其实就是前面说的这条切线的斜率向左斜还是向右斜的问题。
不管切线向左斜还是向右斜,对于梯度下降法都是可以解决的。因为梯度的方向就是沿着该函数取较大值的方向。

而−α∇E(wτ)就是取梯度的反方向,如下图所示:因此无论如何都是可以取到最小值的。
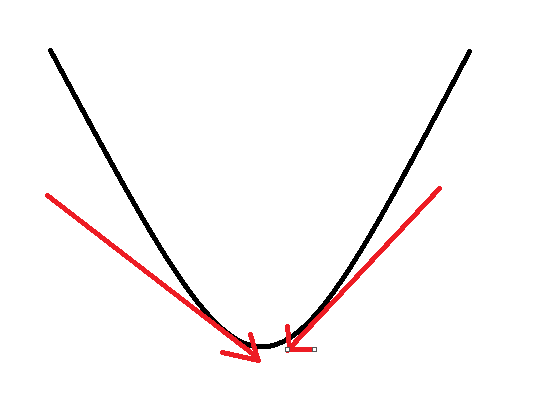
总结一下,可以简单记忆理解:导数指的就是该点函数的梯度,并且和梯度的方向相同。所谓梯度下降,就是要取最小值,要沿着函数较小的方向。因此要把导数变为负的,改变梯度的方向−∇E(wτ)。
改变了方向之后,我们还要让梯度产生变化,沿着函数的较小的方向进行移动,因此要乘以一个常数(步长)α,就变成了−α∇E(wτ)。
因此下一时刻W的取值就显而易见了w(τ+1)=wτ−α∇E(wτ)。这就是梯度下降法!!结合实际生活,就是一个下山的过程。
建议大家可以按照视频,实现其中的案例代码。自己实践一下对概念的理解会更深刻。
3.这个公式没有写底,那他的底是多少? 今天看了这个公式,没有搞懂如何推导的?
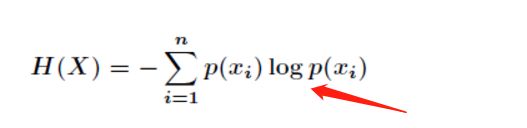
计算机里没写默认值是2,学校学习的时候,默认的底是e。
上学时候不写底是不对的,以e为底,得写成ln
就是目前来说很多数学公式哈,大家不要急着去看他的推导,给大家教个技巧哈,那就是我们在学新的东西的时候,我先达到我的目的,就是我先记住它,记住它的结论,就是他的这个最原始的公式,包括我们用的时候用的是哪个就可以了,先用。然后理解这一块儿的东西呢,就是随着大家的使用过程中,你首先要有一定的积累,然后呢,你再去尝试去理解他的一些过程。
4.如何处理数据集中丢失的数据?
数据科学家面临的最大挑战之一与丢失数据的问题有关。您可以通过许多方式对缺失值进行属性设置,包括分配一个惟一的类别、行删除、使用均值/中值/模式替换、使用支持缺失值的算法以及预测缺失值等等。
5.有监督机器学习和无监督机器学习的区别?
在监督学习中,机器在有标记数据的帮助下进行训练,即,即带有正确答案标记的数据。而在无监督机器学习中,模型是通过自身发现信息来学习的。与有监督学习模型相比,无监督学习模型更适合于执行困难的处理任务。
6.机器学习和深度学习的区别是什么?
机器学习是人工智能的一个子集,它为机器提供了无需任何显式编程就能自动学习和改进的能力。而深度学习是机器学习的一个子集,人工神经网络能够做出直观的决定。
7.请问深度学习解决的是什么问题?和机器学习一样吗?和机器学习有什么关系?
其实啊,这个问题,我之前在公开课的时候已经给他讲过了,我这儿简单说一下,所谓的这个深度学习,他就指的是我们研究一个网络结构,或者网络产品比较深的一个模型,那为什么要深的,因为模型越大越深,他所能够代表的智能化程度就越高,而这个深度学习他要解决的就是如何让计算机具备学习能力,那么我们把这个可以简单称之为机器学习。
就简单的说,机器学习它本质上来说,研究的就是如何让计算机像人一样具备学习的能力,而这一学习主要有两个方向,一个是传统的机器学习,也就是大家现在口中所说的这个机器学习,它是基于数学算法的。那就比如说像SVM,KNN、K-means等等数学算法来做的那。另外一个方向就是我们现在也研究方向是基于仿生学方向的,主要研究的是神经网络,就是说,我们如何模拟人类的一个学习能力,然后搭建一个模型出来对吧,再把这个模型变成代码,让计算机来实现这个模型啊,就是说让计算机能够模拟人的行为去学习和思考。
其实现在所谓的这个人工智能这个东西呢,他其实大多数主要都是基于我们现在的这个仿生学去这个方向来了,虽然说仿生学这个方向是以前从机器学习里面出来的一个体系,但实际上目前来说这个体系已经非常完整了,就是说我们现在的这一套深度学习的体系呢,它足以解决以前的那种传统机器学习所解决了所有问题,并且可以解决的更好。
8.深度学习框架TensorFlow中有哪四种常用交叉熵?
(1) tf.nn.weighted_cross_entropy_with_logits
(2) tf.nn.sigmoid_cross_entropy_with_logits
(3) tf.nn.softmax_cross_entropy_with_logits
(4) tf.nn.sparse_softmax_cross_entropy_with_logits
9、LR和SVM的联系与区别是什么?
都是分类算法
如果不考虑核函数,LR和SVM都是线性分类算法,也就是说他们的分类决策面都是线性的。
LR和SVM都是监督学习算法
LR和SVM的损失函数不同
SVM只考虑局部的边界线附近的点 ,LR考虑全局,远离的点对边界线的确定也起作用。
10、什么叫过拟合,避免过拟合都有哪些措施?
过拟合:就是在机器学习中,我么测试模型的时候,提高了在训练数据集的表现力时候,但是在训练集上的表现力反而下降了。
解决方案:
1.正则化 ;
2.在训练模型过程中,调节参数。学习率不要太大;
3.对数据进行交叉验证;
4.选择适合训练集合测试集数据的百分比,选取合适的停止训练标准,使对机器的训练在合适;
5.在神经网络模型中,我们可以减小权重;
结语:
经过大佬十余年的工作经验以及学员反馈,所得出来在算法工程师岗位面试中总结出来的经典面试题。今天也是在其中挑选几个比较重要的面试题。

为了帮助大家让学习变得轻松、高效,给大家免费分享一大批资料,让AI越来越普及。有啥不懂的可以加QQ群:519970686 ,交流讨论,学习交流,共同进步。
当真正开始学习的时候难免不知道从哪入手,导致效率低下影响继续学习的信心。
但最重要的是不知道哪些技术需要重点掌握,学习时频繁踩坑,最终浪费大量时间,所以拥有有效资源还是很有必要的。