前言
很多人学习Python就是为了写爬虫的,给大家的印象就是Python=爬虫,既然如此,那我们也从最简单的爬虫开始学习吧,
先介绍一波爬虫的原理吧,爬虫也就是Python写的脚本,对特定的url提取需要的信息
所以爬虫总共飞为三部,获取页面数据,解析页面数据,保存数据。
网址处理器,用来提供抓取网址对象
网页解析器,用来提取网页中稀疏分散着的目标数据
数据存储器,用来保存提取的数据。
网址处理器
做爬虫前,先分析要抓网页的网址规律,通过规律构建每一个待抓页面的网址
网址解析器
做爬虫,先分析一个网址上的数据提取规则,推而广之将规律应用到待爬网站的所有的网址上。注意可能有些网页数据是空的,应该考虑try。。。except。。。处理异常情况出现。
数据存储器
入门的爬虫,要爬的数据量一般不是很大,可以用txt,csv等进行保存,保存时注意读写方式(‘a’ , w',‘a+’),推荐使用'a+'。,编码方式使用utf-8即
f = open(path,'a+',encoding='utf-8')来建保存数据的文件。
爬虫注意事项:
1、爬虫的访问速度不要太快,尽量使用time.sleep(1),降低访问网站的频率,做有道德合法公民。如果你太狠了,造成人家服务器瘫痪,属于犯法行为。
2、咱们的访问的网页数目比较少,如果特别多,访问到一定程度之后,人家网站可能就封锁你,因为你用的是python访问的。
3、即使使用了上面两种策略,人家仍然封锁你了,那么要用到代理服务器抓数据,让网站不知道你是谁,也就没法封锁你了。
一个基础的爬虫就是由这三部分构成,爬虫去提取信息和人为的提取信息,还是有很大的不同的,所以,我们需要和网站管理者斗智斗勇,让自己的爬虫尽量绕过监管,不被封了,
我们有三种方法:
伪装请求报头(request header)
减轻访问频率,速度(模仿的和人为的一样)
使用代理IP
那我们就需要使用代理,并且,让爬虫的行为和人为的更像,
例子
我们爬取淘宝的评论
第一步,我们要找到评论的网址,分析网址特点。
淘宝评论这种动态网页,在静态源码中是找不到评论数据的,因为像淘宝这样的大公司,数据太多了,他们使用ajax请求来显示数据,我们可以进行抓包,来分析数据
就拿我最近购买的一个物品的网址吧, 格力取暖器小太阳远红外电暖器家用电暖气办公室速热电热取暖迷你
打开该网址,打开评论。如图中红色圈中的评论,分析发现,在网页源码中查找不到。
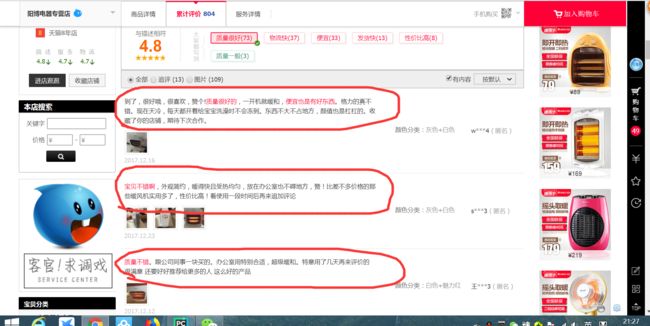
我们打开浏览器的开发者模式

点击消息头,红方框中的请求网址就是这个评论数据包传递的网址
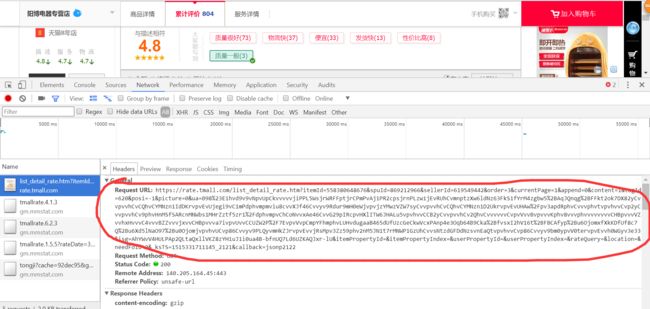
网址如下
https://rate.tmall.com/list_detail_rate.htm?itemId=558380648676&spuId=869212966&sellerId=619549442&order=3¤tPage=1&append=0&content=1&tagId=620&posi=-1&picture=0&ua=098%23E1hvd9v9vNpvUpCkvvvvvjiPPL5WsjrWRFFptjrCPmPvAj1PR2cpsjrnPLzw1jEvRUhCvmnptzXw6ldNz63FkS1fYrM4zgbw5%2BAqJQnqg%2BFFkt2ok7DX82yCvvpvvhCvCQhvCYMNzn1IdDKrvpvEvUjegi9vC1mPdphvmpmviu8cvvXJf46Cvvyv9Rdur9mH0eWjvpvjzYMwzVZW7syCvvpvvhCvCQhvCYMNzn1D2UkrvpvEvUHAw%2Fpv3apdRphvCvvvphvtvpvhvvCvp2yCvvpvvhCv9phvHnMSfSARcnMNWbs1MHrZztf5zr1%2FdphvmpvChCoNvvxAe46CvvG29pIRcpvHXlITW6JHALu5vpvhvvCCB2yCvvpvvhCv2QhvCvvvvvvCvpvVvvBvpvvvKphv8vvvphvvvvvvvvCHBpvvvVZvvhxHvvvC4vvvBZZvvvjxvvCHBpvvva7ivpvUvvCCUZW2P%2F7EvpvVvpCmpYFhmphvLUHvdugaaB465dUfUzcGeCkwVcxPAnp4e3Oqb64B9Cka%2BfvsxI2hV16t%2BFBCAfyp%2Bu6OjomxfXkKDfUf8c7Q%2Bu6Xd5lNaO97%2Bu0OjomjvpvhvUCvp86Cvvyv9PLQyvmHkZJrvpvEvvjRsMpv3Zz59phv2nM5JN1t7rMNWP1GzUhCvvsNtzdGFDdNzsvnEaQtvpvhvvCvp86Cvvyv9bm0ypvV0tervpvEvvh0WGyv3e33&isg=AhYWvV4HULPAp2QLtaQxllVKZ8zYH1uJ1i0ua4B-bfnUQ7Ld6UZKAQJxr-lU&itemPropertyId=&itemPropertyIndex=&userPropertyId=&userPropertyIndex=&rateQuery=&location=&needFold=0&_ksTS=1515331711145_2121&callback=jsonp2122
看起来网址太长,太复杂(稍安勿躁),那么先复制网址,在浏览器上打开看看是什么东西,复杂的网址中,有些乱七八糟的可以删除,有意义的部分保留。切记删除一小部分后先尝试能不能打开网页,如果成功再删减,直到不能删减。最后保留下来的网址,如下https://rate.tmall.com/list_detail_rate.htm?itemId=558380648676&spuId=869212966&sellerId=619549442&order=3&callback=jsonp979¤tPage=1
currentPage=1意思是当前页码是第一页。如果改动为currentPage=3表示是第三页。
第二步,分析数据
import requests
import json
import time
headers = {
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
}
base_url = 'https://rate.tmall.com/list_detail_rate.htm?itemId=558380648676&spuId=869212966&sellerId=619549442&order=3&callback=jsonp979'
#在base_url后面添加¤tPage=1就可以访问不同页码的评论
#抓取98页评论
for i in range(2, 98, 1):
url = base_url + '¤tPage=%s' % str(i)
#将响应内容的文本取出
r = requests.get(url, headers=headers)
tb_req = r.text[12:-1]
#print(type(tb_req))
#print(tb_req)
#将str格式的文本格式化为字典
Data = json.loads(tb_req)
#print(type(Data))
for p in range(1, 20, 1):
print(Data["rateDetail"]["rateList"][p]['rateContent'])
time.sleep(1)
在这个案例中,数据就是类似于字典的数据,print(type(tb_req))查看数据类型,大部分是src,我们需要用dict[key]这种方式获取我们想要的数据
这里首先要将str转换为dict,解决办法有两个:
方法一:
import json
Data = json.loads(r.text)
方法二:
直接使用requests的方法
Data = r.json()
第三步,保存数据。
import os
获取当前代码所在的文件夹路径
path = os.getcwd()
filename = '淘宝评论.txt'
file = path + '/' + filename
f = open(file, 'a+', encoding='utf-8')
文本写入txt文件
f.write(要写入的数据)
待续----------------------------------------------------------------------------------------------------------------------------