6.1 聚类分析
聚类算法有很多,K均值算法是比较常用的一类,我们通常说它简单但够用了
- K-means算法
1.任意选择k个对象作为初始的聚类中心
2.然后对每个点确认它的聚类中心点,这里就是计算距离,一般采用均方差作为标准测度函数
3.计算每个新聚类的聚类中心,直到确认的聚类点不再收敛(直到质心与原来的质心相等或小于相应的阈值)
import numpy as np
from scipy.cluster.vq import vq, kmeans, whiten
list1 = [88.0, 74.0, 96.0, 85.0]
list2 = [92.0, 99.0, 95.0, 94.0]
list3 = [91.0, 87.0, 99.0, 95.0]
list4 = [78.0, 99.0, 97.0, 81.0]
list5 = [88.0, 78.0, 98.0, 84.0]
list6 = [100.0, 95.0, 100.0, 92.0]
data = np.array([list1, list2, list3, list4, list5, list6])
#whiten()主要实现的是将data数据的标准差求出,返回各个值除以其标准差的ndarray
whiten = whiten(data)
centroids,_ = kmeans(whiten, 2) #对数据进行聚类
result, _ = vq(whiten, centroids) #矢量量化函数,对每一个数据进行归类,获得结果
print(result)
- 用专业的机器学习包来解决 scikit-learn
import numpy as np
from sklearn.cluster import KMeans
list1 = [88.0, 74.0, 96.0, 85.0]
list2 = [92.0, 99.0, 95.0, 94.0]
list3 = [91.0, 87.0, 99.0, 95.0]
list4 = [78.0, 99.0, 97.0, 81.0]
list5 = [88.0, 78.0, 98.0, 84.0]
list6 = [100.0, 95.0, 100.0, 92.0]
X = np.array([list1, list2, list3, list4, list5, list6])
kmeans = KMeans(n_clusters = 2).fit(X)
pred = kmeans.predict(X)
print(pred)
- 分类
将数据分为两部分,一类为训练集,另外一类为测试集,从训练集中得出模型,在对测试集运用得到相应的标记(以上班数据为例)
from sklearn import datasets
from sklearn import svm
clf = svm.SVC(gamma = 0.001, C = 100.)
digits = datasets.load_digits()
clf.fit(digits.data[:-1], digits.target[:-1]) #对n-1份训练集学习
clf.predict(digits.data[-1]) #对一份测试卷预测
- 基于一个实际例子来进行聚类分析
import requests
import re
import json
import pandas as pd
from sklearn.cluster import KMeans
import numpy as np
def retrieve_quotes_historical(stock_code):
quotes = []
url = 'https://finance.yahoo.com/quote/%s/history?p=%s' % (stock_code, stock_code)
r = requests.get(url)
m = re.findall('"HistoricalPriceStore":{"prices":(.*?),"isPending"', r.text)
if m:
quotes = json.loads(m[0])
quotes = quotes[::-1]
return [item for item in quotes if not 'type' in item]
def create_df(stock_code):
quotes = retrieve_quotes_historical(stock_code)
list1 = ['close', 'date', 'high', 'open', 'volume']
df_totalvolume = pd.DataFrame(quotes, columns = list1)
# 用数据的平均值代替数据中的空值(NaN)
df_totalvolume = df_totalvolume.fillna(df_totalvolume.mean())
return df_totalvolume
listDji = ['MMM', 'AXP', 'AAPL', 'BA', 'CAT', 'CVX', 'CSCO', 'KO', 'DIS', 'DD']
listTemp = [0] * len(listDji)
for i in range(len(listTemp)):
listTemp[i] = create_df(listDji[i]).close
status = [0] * len(listDji)
for i in range(len(status)):
status[i] = np.sign(np.diff(listTemp[i])) #对数据做一个预处理
#简单处理某一只或几只股票数据没有获得(值为[])的问题,删除此数据
for i in range(len(status)):
if len(status[i]) == 0:
status.pop(i)
break
kmeans = KMeans(n_clusters = 3).fit(status)
pred = kmeans.predict(status)
print(pred)
6.2Matplotlib绘图基础
Matplotlib是其中非常重要的数据库,可以绘制高质量的图形来实现数据可视化的目的

Matplotlib简介
Matplotlib可画图像
- 绘图API——pylot模块
- 折线图
import matplotlib.pyplot as plt
closeMeansKO = tempdf.groupby('month').close.mean()
print(closeMeansKO)
x = closeMeansKO.index
y = closeMeansKO.values
plt.plot(x, y)
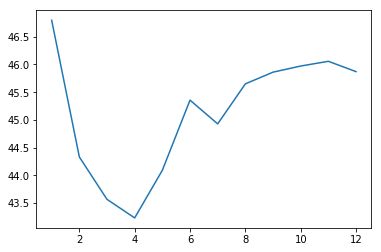
输出示例图
#NumPy数组也可以作为Matplotlib的参数
import numpy as np
import matplotlib.pyplot as plt
t = np.arange(0., 4., 0.1 )
plt.plot(t, t, t, t+2, t, t**2)
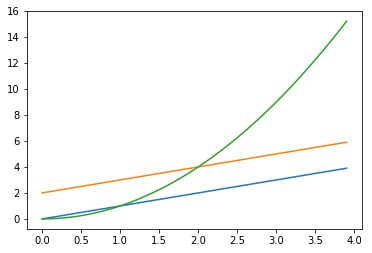
输出图像.png
- 散点图
plt.plot(x, y, 'o')
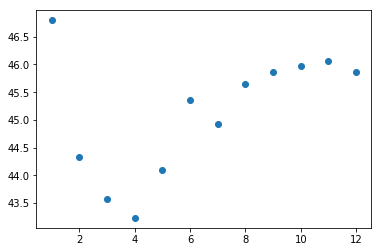
输出图像—散点图.png
- 柱状图
plt.bar(x, y)
- 集成库——pylab模块(包含NumPy和pylot中的常用函数)
import numpy as np
import pylab as pl
t = np.arange(0., 4., 0.1 )
pl.plot(t, t, t, t+2, t, t**2)
输出图像和利用matplotlib是一致的
6.3Matplotlib图像属性设置
-
色彩和样式
1.蓝色实线 'b-'
2.绿色虚线 'g--'
......
 Matplotlib图像属性设置.
Matplotlib图像属性设置. 文字
图像中可以添加相应的文字信息,比如
1.标题 "title"
2.横轴 "xlabel"
3.纵轴 "ylabel"
x = closeMeansKO.index
y = closeMeansKO.values
plt.title('Stock Statistics of Coca-Cola')
plt.xlabel('Month')
plt.ylabel('Average Close Price')
plt.plot(x, y)

带文字信息的图像
- 其他属性
import pylab as pl
import numpy as np
pl.figure(figsize = (8,6), dpi = 100)
t = np.arange(0., 4., 0.1)
pl.plot(t, t, color = 'red', linestyle = '-', linewidth = 3, label = 'Line1')
pl.plot(t, t+2, color = 'green', linestyle = '', marker = '*',linewidth = 3, label = 'Line2')
pl.plot(t, t**2, color = 'blue', linestyle = '', marker = '+',linewidth = 3, label = 'Line3')
pl.legend(loc = 'upper left') #图例放在左上方,图例内容为label内容
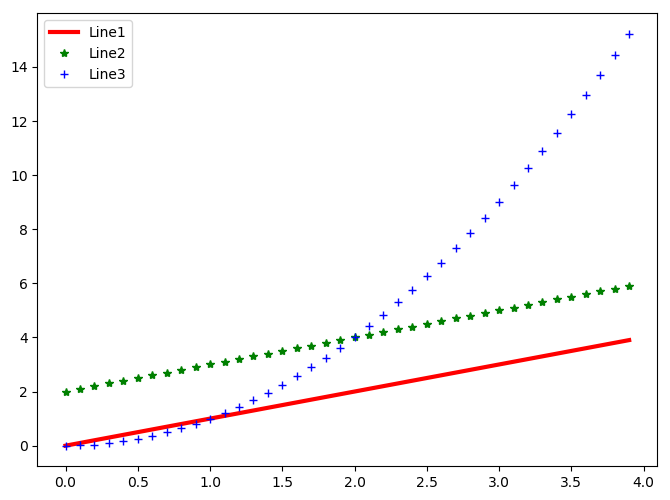
输出pylab图形
#多子图
import matplotlib.pyplot as plt
plt.subplot(211)
plt.plot(x, y, color = 'r', mraker = 'o')
plt.subplot(212)
plt.plot(x, y, color = 'green', marker = 'o')
#另一种形式表现多子图
plt.axes([.1, .1, 0.8, 0.8])
plt.plot(x, y, color = 'r', mraker = 'o')
plt.axes([.3, .15, 0.4, 0.3])
plt.plot(x, y, color = 'green', mraker = 'o')
6.4 Pandas作图
除了能对Series进行绘图以外,对DataFrame的绘图功能比pyplot和pylab更加高效
#eg1
closeMeansKO.plot()
#eg2
quotesdfIBM.close.plot()
#用柱状图比较Intel和IBM这两家公司近一年来股票成交量
INTC_volumes = create_volumes('INTC')
IBM_volumes = create_volumes('IBM')
quoteslldf = pd.DataFrame()
quoteslldf['INTC'] = INTC_volumes
quoteslldf['IBM'] = IBM_volumes
quoteslldf.plot(kind = 'bar') #kind参数控制图形形式
#箱型图
quoteslldf.boxplot()
6.5数据存取
- csv格式数据存取
#存储
import pandas as pd
...
quotes = retrieve_quotes_historical('AXP')
df = pd.DataFrame(quotes)
df.to_csv('stockAXP.csv')
#读取csv文件
pd.read_csv('test.csv')
Python的理工类运用
- 简单的三角函数问题
#三角函数运算
import numpy as np
import pylab as pl
#利用林space生成的一组从-pi到pi的等差数据
x = np.linspace(-np.pi, np.pi, 256)
s = np.sin(x)
c = np.cos(x)
pl.title('Trigonometric Function')
pl.xlabel('X')
pl.ylabel('Y')
pl.plot(x, s)
pl.plot(x, c)
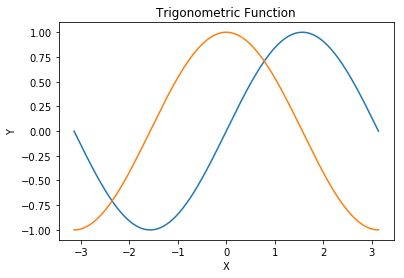
三角函数图像
#快速傅里叶变换
import scipy as sp
import pylab as pl
listA = sp.ones(500)
listA[100:300] = -1
f = sp.fft(listA)
pl.plot(f)
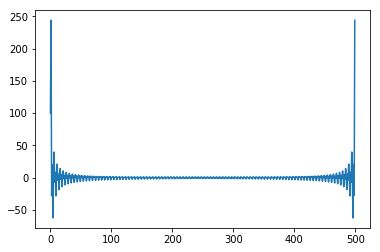
快速傅里叶变换
- 常用Python图像处理库
Pillow(PIL)
OpenCV
Skimage
from PIL import Image
im1 = Image.open('1.png')
#输出图片的大小、格式、模式
print(im1.size, im1.format, im1.mode)
Image.open('1.png').save('2.png')
im2 = Image.open('2.png')
size = (288, 180)
#创建第二张图的缩略图
im2.thumbnail(size)
#逆时针旋转45度
out = im2.rotate(45)
im1.paste(out, (50,50))
-
Biopython
处理常用的生物信息学处理对象,最重要的数据结构就是序列
 Biopython示例简介
Biopython示例简介