摘要:前文数据挖掘与机器学习技术入门实战与大家分享了分类算法,在本文中将为大家介绍聚类算法和关联分析问题。分类算法与聚类到底有何区别?聚类方法应在怎样的场景下使用?如何使用关联分析算法解决个性化推荐问题?本文就为大家揭晓答案。
本次直播视频精彩回顾,戳这里!
演讲嘉宾简介:
韦玮,企业家,资深IT领域专家/讲师/作家,畅销书《精通Python网络爬虫》作者,阿里云社区技术专家。
以下内容根据演讲嘉宾视频分享以及PPT整理而成。
本文将围绕一下几个方面进行介绍:
1. 聚类问题应用场景介绍
2. K-Means算法介绍与实现
3. 使用K-Means算法对公司客户价值进行自动划分案例实战
4. 关联分析问题应用场景介绍
5. Apriori算法介绍
6. FP-Growth算法介绍
7. 使用关联分析算法解决个性化推荐问题
8. 作业练习:使用关联分析算法解决超市商品货品摆放调整问题
一. 聚类问题应用场景介绍
聚类问题主要用于解决没有明确分类映射关系的物品归类问题,即无监督学习。分类算法必须需要训练数据,训练数据包含物品的特征和类别(label, 也可以被称作标签),这相当于对这些数据建立了映射规则,这种映射规则可以通过机器学习相应的算法来建立,当需要对新的数据进行分类时,就可以直接调用模型,对数据进行相应的处理来实现分类。那么当没有历史数据的时候要对现存的物品进行归类,就需要使用聚类算法解决。比如,聚类算法可以实现公司客户价值自动划分,网页自动归类等。
二. K-Means算法介绍与实现
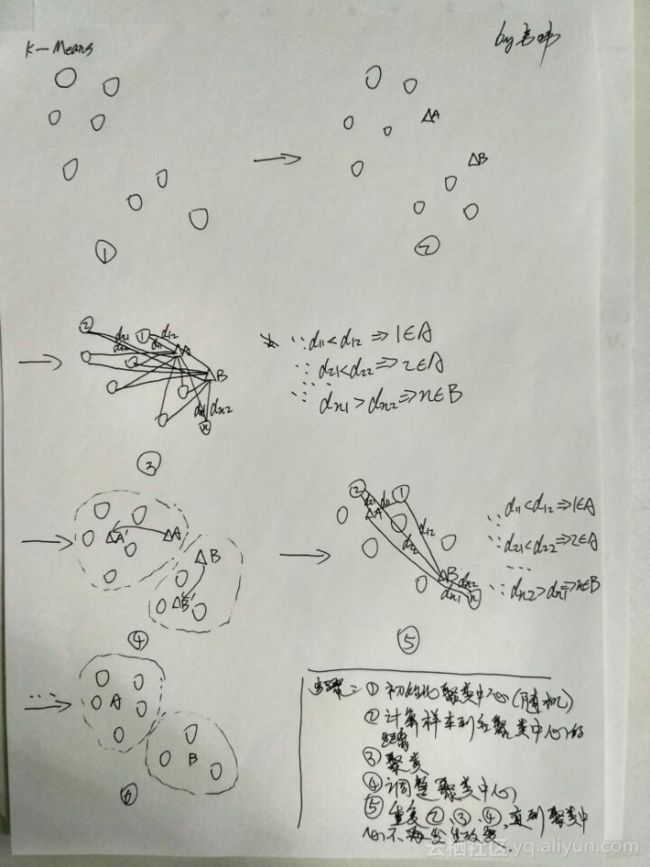
K-Means算法是一种经典的聚类算法,也称作K均值聚类算法,先为大家介绍K-Means算法的原理。
假设建立一个坐标系,这个坐标系的横坐标是价格,纵坐标是评论。然后根据每个物品的这两项特征将物品放置在该坐标系中,那么如何将这些物品划分为k类,此处k为自定义。例如,可以定义k为2,即将所有物品划分为两类。首先,随机选择两类的中心点AB,这两个点称为聚类中心。初始的聚类中心是随机选择,很大概率上并不是真正的类中心,因此这两点会在后续的聚类过程中不断调整,直至趋于真正的聚类中心。其次,分别计算各个物品距两个聚类中心AB的距离,将其划分至距离较近的聚类中心点一类。例如,点1距A的距离小于点1距B的距离,因此将点1划分至A类。如此,初步将所有点划分为两类,接着需要对每类的聚类中心进行调整。这个阶段,需要对每一类计算重心位置,将这类的聚类中心移动到该重心位置,得到两类的新聚类中心A’ B’。然后再一次计算各个物品距两个新的聚类中心A’ B’的距离,进行距离比较,得到新的聚类结果。按照这样的方法不断迭代,不断的向正确结果靠拢,最终聚类过程会收敛,得到的聚类中心不再变化,便已经得到最终的聚类结果,也就是将物品分成了两类。
按照上述过程,K-Means的步骤大致如下:1. 初始化聚类中心(随机选择);2. 计算样本点到各聚类中心的距离;3. 将样本点归为距离较近的聚类中心一类;4. 移动聚类中心到类别的重心位置,调整聚类中心; 5. 重复234步骤,直到聚类中心不再改变。
from sklearn.cluster import
KMeanskms=KMeans(n_clusters=3)
y=kms.fit_predict(x)
接下来就使用K-Means算法来解决公司客户价值自动划分的问题。
三. 使用K-Means算法对公司客户价值进行自动划分案例实战
开始聚类时,公司的客户只是具有某些特征,没有具体的分类标准。那么可以直接根据特征进行聚类,得出聚类结果后再分析研究这些类别的真实含义。
假设初始时存在部分客户的数据如下,包含客户年龄,平均每次消费金额,平均消费周期等数据。
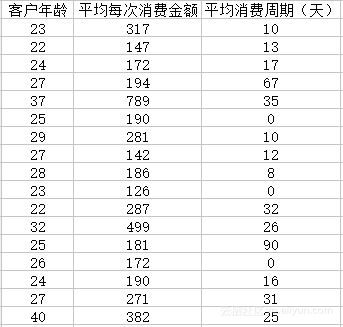
现需要对上述客户进行聚类,以帮助公司快速区别出普通客户,VIP客户和超级VIP客户。在有其他历史数据的情况下,可以将这些用户的特征和客户类型建立起映射关系,通过机器学习训练便可以得到未知的客户类型。但在没有历史数据的情况下,这就是典型的聚类问题。具体代码如下:
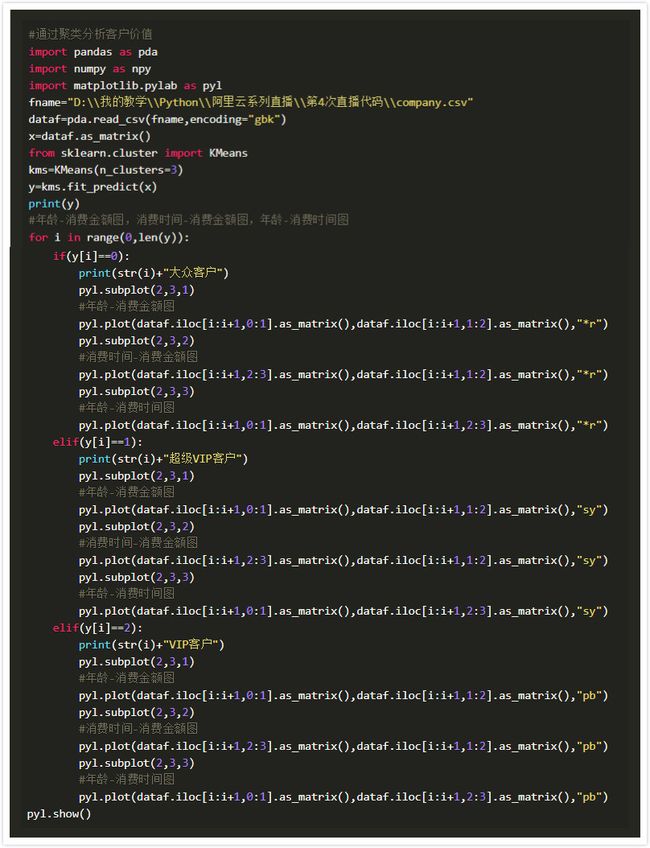
首先加载客户数据文件 company.csv,从中读取客户数据,然后导入K-Means模型,这里设置聚类成3类,然后将聚类结果通过图像来分析,但当聚类有多个特征值时,绘图分析会有一定的难度。例如在本例中有3个特征值,在作图时就需要将特征值两两组合,对年龄-消费金额图、消费周期-消费金额图、年龄-消费周期分别进行分析。在作图之前,可以将毫无关联的特征值组合删除,例如这里可以将年龄-消费周期图剔除。若无法判断,也可以全部绘制再根据图像分析。在绘图时,将预测出的类别作为客户分类标准,例如如果某两个客户被分到标签为0这一类,此时并不了解预测出的标签0类有何实际意义,但可以认为这两个客户是一类。接下来在每个类别中分别绘制上述三种图像,这里将同一类别中的图像采用一种颜色以作区分。做出图像结果如下:

得出图像后,因为分布杂乱的图像表明这两个特征值之间是没有实际关联的,可以将其筛去,留下层次分明的图像分析。观察图像可以发现年龄-消费周期图非常杂乱,和上述猜想相同,可以删去。而年龄-消费金额图中,蓝色点客户显示年龄相对较小,消费金额也较少,偏向于普通用户,红色点客户年龄不定,但消费金额普遍较高,偏向于VIP客户,而绿色点客户年龄较大,消费非常高,属于超级VIP客户。如果图一中的类别分析可靠,那么可以将这些类别应用于图二中继续验证。在图二消费周期-消费金额图中,蓝色点客户消费周期不定,消费金额不高,符合普通客户的特征,红色点客户消费周期偏短,消费金额中等,属于VIP客户,而绿色点客户消费周期短,消费金额高,符合超级VIP客户的特征。分析得出用户类别后,便可以对所有公司客户进行自动划分,基于划分的结果,可以为超级VIP客户提供一些福利,如生日祝福等,加强营销的粘性。
四. 关联分析问题应用场景介绍
关联分析是一种用于分析物体之间关联程度的一种方式,关联分析常见的应用场景有:分析物品之间的关联程度、个性化推荐、超市货品摆放调整等。例如在超市货品摆放时,可以根据用户购买商品时的记录,计算商品之间的关联程度,将关联程度高的商品摆放在一起。接下来为大家介绍两种关联分析算法。
五. Apriori算法介绍
Apriori算法是一种基础的关联分析算法,但效率较低,不建议用于商业场景。Apriori算法的原理如下:
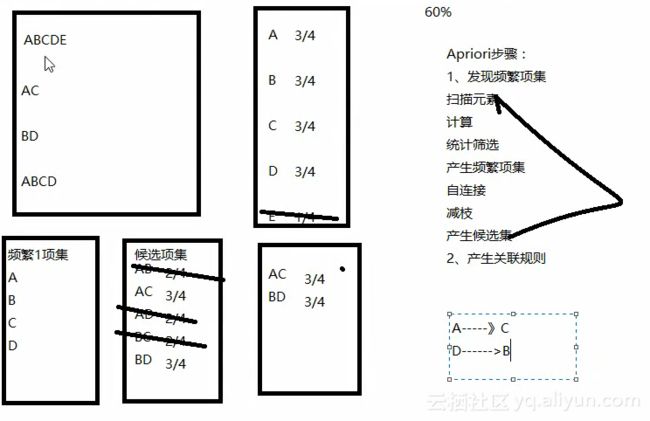
假设如今有一批商品的购买记录,ABCDE分别代表不同的商品,每一行代表某一用户的商品购买记录。首先对各商品进行依次扫描,例如商品A在所有4条商品记录中出现3次,那么商品A的支持度即为3/4,计算出的支持度表明了该产品在所有购买记录中出现的概率大小,显然概率越大,支持度越高。同理,计算出BCDE的支持度分别为3/4、3/4、3/4、1/4。接下来需要设置阈值来筛选出关联度较高的商品数据,这里假设取1/2,那么就先将E筛除,留下商品ABCD,此时便产生频繁一项集{{A},{B},{C},{D}}。然后将频繁一项集中的集合两两组合,得到候选项集{{AB},{AC},{AD},{BC},{BD},{CD}},计算每个项集的支持度。例如项集AB在所有4条商品记录中出现2次,那么AB的支持度即为2/4。同理得出AC,AD,BC,BD,CD的支持度分别为3/4,2/4,2/4,2/4,3/4,2/4。在阈值为1/2的情况下只留下AC和BD。如此便可以继续生成候选集ABCD,支持度为2/4,可以筛去。得到AC和BD的关联程度最高,这意味着,如果某一客户购买了商品A,那么给该客户推荐商品C成功率更大,类似的,如果客户购买了商品B,那么商品D可能也更受该用户青睐。
Apriori算法为什么效率较低呢?从上述过程可以看到每一次计算候选集的支持度时都需要返回至历史记录中进行扫描,因此处理复杂,耗时严重。
六. FP-Growth算法介绍
相比Apriori算法,FP-Growth算法是一种效率比较高的关联分析算法,更适用于商业应用。下面为大家介绍FP-Growth算法的原理。
假设仍然取上述例子,ABCDE分别代表不同的商品,现在有如图所示的产品购买历史记录,每一行代表某一用户的商品购买记录,现在来分析各商品间的关联关系。
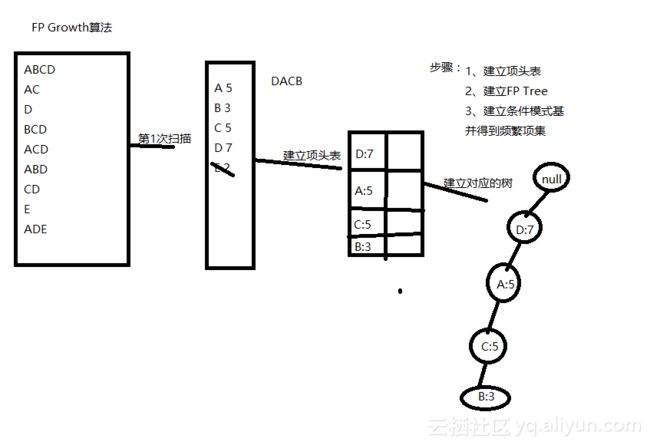
首先仍然需要进行第一次扫描,得到商品ABCDE出现的次数,也就是支持度,分别为5,3,5,7,2。然后筛除支持度较小的商品,这里筛除商品E。接下来按次数大小进行排序创建项头表(此处项头表中的顺序也可以为DCAB),为创建FP树做准备。在FP树中,公用元素要尽量多,以加快后续查找时的检索速度。FP树的根节点可以设置为null,将项头表中的数据按照顺序添加至FP树中。
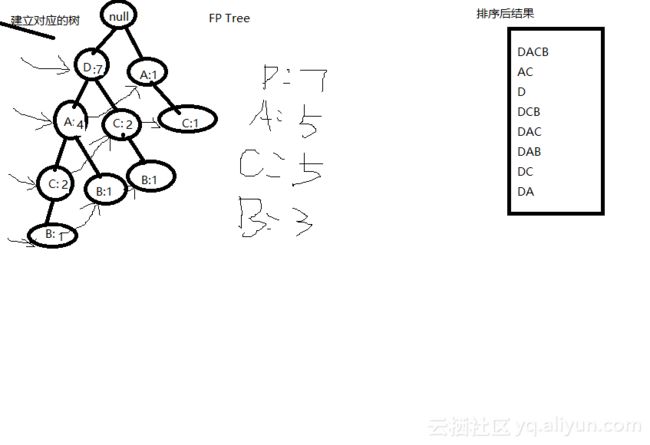
接下来只需要再遍历一次购买记录,将所有记录插入到初始的FP树中即可。但在插入之前,需要将每一条记录按照项头表中的大小顺序进行重排。例如第一条记录ABCD,改为DACB或者DCAB(根据初始的项头表而定),第四条记录BCD,改为DCB。历史记录排序完成后,将每一条记录从根节点开始插入至树中。例如,第一条记录DACB,与初始FP树公用,因此不用插入。第二条记录AC,同样从根节点开始,第一个节点和初始根节点不共用,因此建立新的节点,插入记录AC,且出现次数都为1。第三条记录DCB,第一个节点D是可以公用的,后续节点CB不共用,因此在节点D下建立新节点CB,此时CB的次数也都为1。第七条记录DC插入时,已经有公用的节点了,就直接将除初始节点之外的其他节点支持度加1即可,这里D的支持度不变,C的支持度从1变成2。那么这里只需要进行一次扫描,就可以将所有历史记录插入到建立的FP树中。FP树建立完成后便可以进行频繁项集的挖掘。
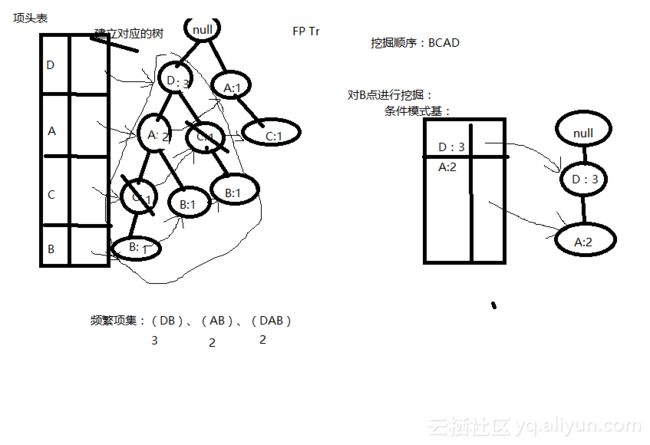
在频繁项集挖掘时,要按照项头表中支持度从小到大的顺序进行,如此越向后挖掘,公用节点越多。因此首先对B点进行挖掘,找出所有以B节点结尾的分支,将这些分支组成的树取出,找出其中的父节点D,A,C,删除支持度较小的C,得到B的条件模式基D:3和A:2。将B与条件模式基中的节点进行组合,得到频繁项集{DB},{AB},{DAB},取每个项集中支持度较小的条件模式基支持度作为该项集的支持度,如DB的支持度取D的支持度3,AB的支持度取A的支持度2,,DAB的支持度取A的支持度2。
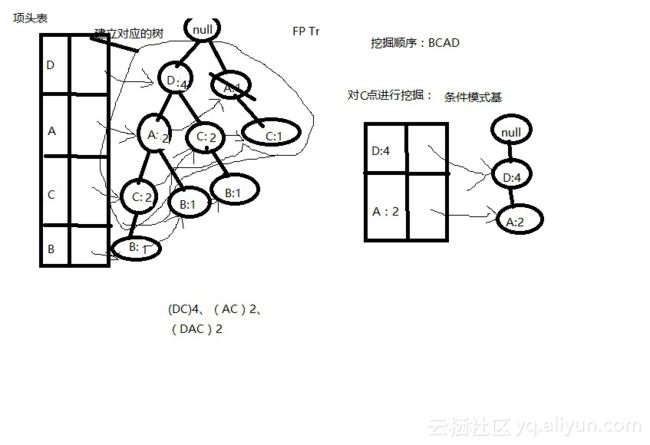
同理,对C进行挖掘,取出含节点C的部分树,得到C的条件模式基为D:4和A:2。以及频繁项集为{DC}4,{AC}2,{DAC}2。

以及对A进行挖掘得到的条件模式基为D:4,频繁项集为{DA}4。支持度最高的D点不需要进行挖掘。
最后将所有频繁项集合并,得到最终各点的频繁项集{DC}4, {DA}4, {DB}3, {AC}2, {DAC}2, {AB}2, {DAB}2。如此便可判断出D与C和A的关联度最高,和B关联度也较高。若用户购买了商品D,可以向其推荐商品C和A,或者商品B。
在FP-Growth算法中,只需要进行两次扫描便可完成关联度分析,所以相比Apriori算法性能更佳。
七. 使用关联分析算法解决个性化推荐问题
先用Apriori算法来解决一个课程的个性化推荐问题。假设现在有如下所示相关数据,每一行代表每一位客户购买的书籍信息,需要分析出课程之间的关联性,将关联度较高的课程推荐给相关的用户使购买转化率最高。
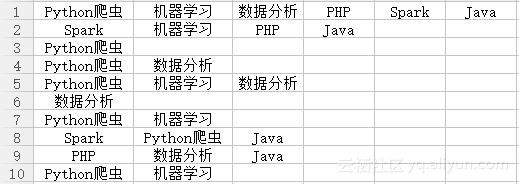
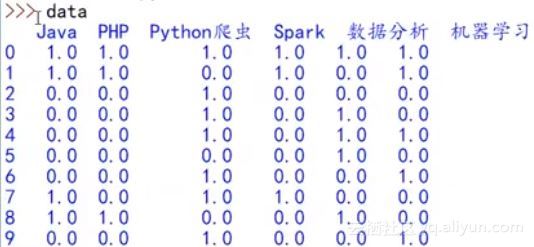
首先使用Apriori算法来解决这个推荐问题。在实现过程中,值得注意的是需要将输入数据进行转化,将课程记录转化为矩阵形式,如下图所示,具体应用代码如下:
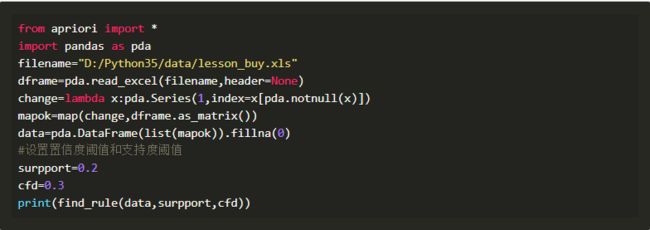
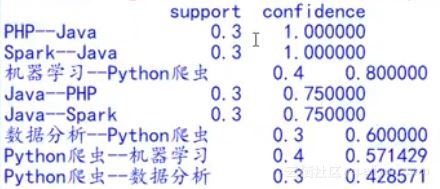
得到关联结果如下,其中support为支持度,confidence为置信度。在本例中,若客户购买机器学习,那么便有较大的概率会购买Python爬虫,这具有一定的实际意义。Apriori算法的实现代码在网上有开源资源,若有需要可自行阅读。
现在使用FP-Growth算法解决超市货品的推荐问题。假设现在有如下所示相关二维列表数据,分析这些商品间的关联度。
具体实现代码来源于github,此处也附上:
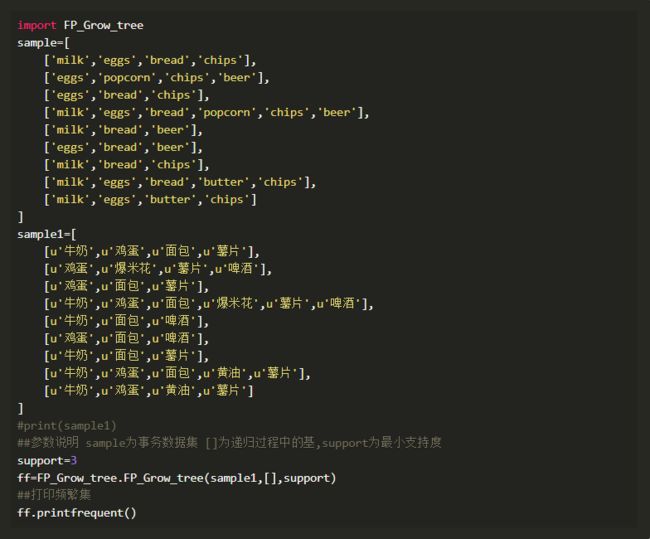
关联结果如下所示。类似的,这种关联度分析可以使用于超市商品的货架摆放等问题,增加用户的购买转化率。

八. 作业练习:使用关联分析算法解决超市商品货品摆放调整问题
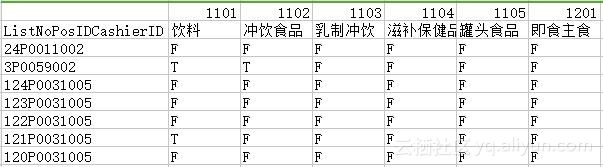
假如有一个超市的商品购买记录数据集,需要分析各商品之间的关联程度以调整货品摆放。数据集格式如下所示,ListNoPosIDCashierID为不同用户的购买记录ID,各商品下F表示未购买,T表示购买。请分别使用Apriori算法和FP-Growth算法实现关联分析,并比较两种算法的耗时。这里也提供一份一位同学所写的优秀作业代码供大家参考,具体数据集和参考代码点击阅读原文
详情请阅读原文