什么是流计算:
在当下这个数据容量呈几何倍暴增的时代背景下,数据的价值在其产生之后,将随着时间的流逝,逐渐降低。因此,我们最好在事件发生之后,迅速对其进行有效处理,实时,快速的处理新产生的数据,而不是待数据存储在一起之后,再进行批量处理。
流数据(事件流,数据流):流数据可以看成是一组组离散事件集合体,由成千上万个数据源,源源不断的持续生成,生成的数据流以log(非传统意义上的系统日志)方式传送。例如我们金融行业中,用户对哪款基金进行了查看,明细点击了几次,现货期货的下单事件,网购支付事件等。
流计算,即是面向流数据的计算,针对于流计算系统而言,上游的流数据是实时,且持续的,例如某视频网站的视频点播事件,24小时都在发生,点播事件是离散且无固定规律的,点播事件构成的流数据,将按照其发生的顺序发送至流系统被计算,只要网站不停运,点播事件流将绵延不绝的流向流系统,而流系统,也将根据这些事件流信息进行计算,形成分类推荐,以及对各个视频进行热度统计等。
流计算引擎:
结合上述流计算的概念,流计算引擎需具备的三大特点:
1,可接受实时,连续的数据流导入
流计算引擎的上游数据流的特点即是实时,持续,所以流计算引擎系统首先需要具有高可用特性,具有永久提高计算的能力。
2,强大的计算能力
一旦有流数据进入计算引擎,计算引擎则立刻发起计算,并将结果输出至下游,因此,流计算背后的计算模式为“事件驱动”,正如上述所说,数据的价值随着时间的流逝而逐渐降低,所以,流计算引擎需要具有高效的计算能力,快速的将数据流的计算结果输出至下游,并当面对数据流突如其来的小高峰时,同样可快速的生成计算结果。
3,实时且多数据存储端接入
通常,不同类型的流数据计算结果,需要落地到不同的存储端供后续业务消费,甚至不落地到存储,直接打到页面进行实时输出展示,因此,流计算引擎需可接入多种数据存储端,可能是缓存,数据库,亦或是文件服务存储,消息队列,数据中心等,并且在此过程中,数据流计算结果的输出,也应像数据流的输入那样,实时,持续的进行。
SOFA流计算平台:
SOFA流计算平台的建设出于两方面原因,一是由于在整个SOFA微服务架构体系中,不同的组件如SOFA微服务注册中心,SOFA服务状态追踪引擎等都需要经过流计算引擎清洗,甚至聚合后的消息数据,二是,即便是在传统的金融,保险行业内,数据量也是日益剧增,人们对数据的使用方式也是越发多样,有些场景,需要你以秒,甚至是毫秒的时间内响应,此时传统的离线批处理已无法满足这些要求,必须用专门的流式计算系统来解决。
架构设计:
SOFA流计算平台的使用到的主要技术栈包括storm,hadoop-yarn,docker,平台的粗略架构图如下:
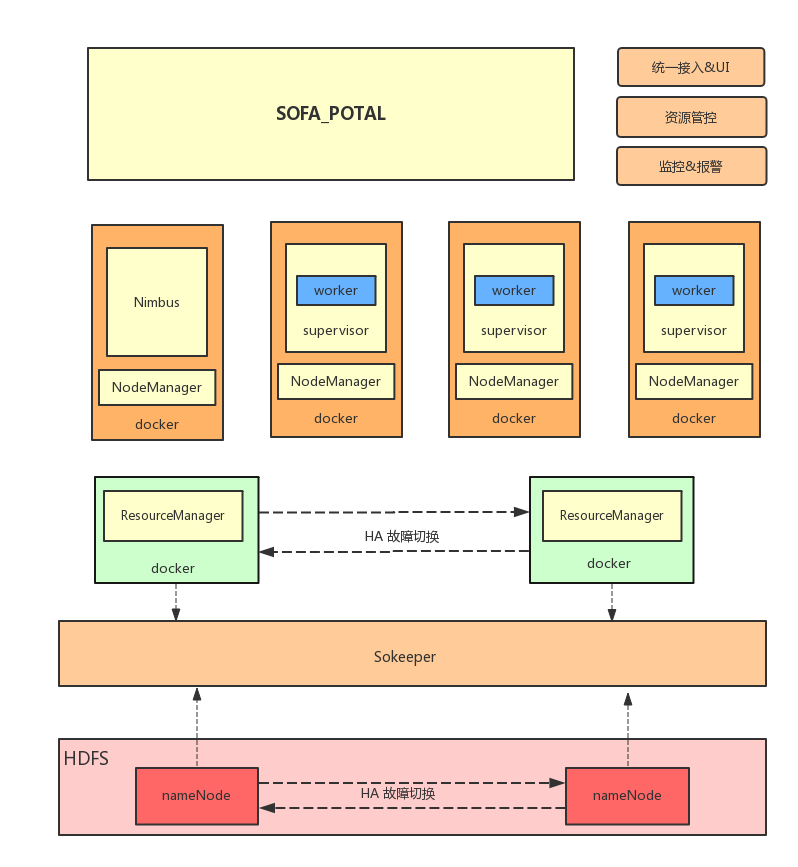
实时计算处理引擎核心组件:
SOFA流计算平台目前是使用storm作为实时处理引擎,作为老牌实时计算中间件,storm久经考验,无论是性能,低延迟,可拓展,以及容错等方面,都有不俗的表现,而且,storm1.0之后,nimbus的HA问题也有了很好的解决,相比于spark streaming,storm是及时处理每一个流入的事件,不会进行时间窗口内的消息积攒,这也是storm实时,低延迟的重要保障。
统一接入:
storm原生API开发流式组件,开发门槛高,并存在大量重复工作,SOFA流计算平台提供封装了的SDK包,对计算拓扑,以及重复使用的组件,如kafka接入,内部log服务接入,hbase输出,消息队列输出等都进行了抽象封装。并实现简单的聚合,过滤,窗口等基础编程组件,抛去不常使用的特性,我们封装了资源(内存,cpu)的概念,为MC(memory,cpu),提供可视化操作在发布计算拓扑时对计算组件进行资源配置,配置单位最小为1MC(1core,3g),用户可调配自己组件所需要的系统资源(预估值,平台也可根据组件的资源使用程度,动态分配资源)。
资源管理:
由于SOFA流计算平台是多租户使用,因此,我们有必要对有限的资源进行合理的管理,避免多租户间的相互影响,其次,为避免出现一部分流计算作业负载过高,而另一部分资源空闲这种资源浪费的情况,流计算的资源管理也是不可或缺的,平台使用hadoop-yarn进行资源管理,并使用FairSchedule资源调度算法,资源管理的中间件有很多,这里,我们考虑尽量使用java技术为主的中间件,方便技术团队后期二次改造,我们为每一个租户建立一个队列,并为队列配置一定资源量,同时,系统将预留一定资源,我们的sofa-stream-potal会不间断的监控各个队列的资源使用率,当队列使用率超过80%时,则会触发对该队列的扩容操作,系统预留资源不够时,我们会选择在较空闲的队列中,“拿取”资源、在这里,我们选择主动触发方式,而不是当资源不够时,被动触发,也是考虑保证平台响应的低延迟。因为我们的这个yarn平台上跑的是storm,所以多数是永久性占用资源的进程,扩容操作的频率会高于缩容操作,管理员也可通过历史监控数据,查看各队列的历史资源使用率,重新配置资源额度。由于当前业务场景使用简单,我们没有提供多级子队列的使用方式。
彻底的资源隔离与管理:
SOFA流计算平台使用docker实现彻底的资源隔离与资源管理,我们的hdfs不归SOFA流计算平台管理,在我们内部,SOFA流计算平台将与恒河数据库使用同一个大的hdfs集群,因此hdfs的nameNode,以及dataNode都不运行于docker之上,yarn以及跑在上面的storm运行于docker之上,我们可以由此限制一个yarn-NodeManager节点使用的资源,形成完全的资源隔离,一个16core,64G的物理机,单跑一个yarn的NodeManager不免容易造成资源浪费,如果我们在此机器上建立3个docker容器,每个docker容器分配4core,18g内存,那么,一个物理机上就可跑三个NodeManager节点。这样,我们对资源的管理也更细粒度了,对yarn所分配的资源都以精确到CPU核数,内存大小。不过一个物理机上,不应起太多的docker容器,最好别超过3个,因为docker容器本身也是需要消耗资源的。
后续:
V2.0的SOFA流计算平台主要优化点将在于支持类sql的执行,通过直接执行sql,即可生成相应的计算拓扑,来进一步减少开发计算组件的难度,以及docker容器之间网络传输上的性能优化。
产品特性:
1,SOFA流计算平台,在保证流计算处理高性能,低延迟的基础上,兼顾了集群计算资源可控,可管理,可根据逻辑节点负载动态扩容,部署运维一体化的重要特性,
2,通过提供的SDK拓展包,以及对常用组件的封装,使得开发人员开发计算组件的难度,门槛大大降低,效率大大提高。
3,可视化监控,自动化报警,保证了使用者实时知道计算平台的运行状态,并可根据运行状态动态调配资源。
部署实施:
hdfs集群:
首先,由于sofa流计算平台使用yarn实现资源管控,所以需要一个hdfs集群,在sofa生态中,sofa流计算平台将与恒河数据库共用一套底层hdfs集群。
Sokeeper集群:
Sokeeper是我们的SOFA分布式协调中心,功能类似于zookeeper,我们的sofa docker容器通过overlay网络实现容器间的互通,这里我们使用Sokeeper实现key-value存储服务,存储各个主机节点在overlay网络中的配置信息。以及yarn的HA,storm都需依赖使用Sokeeper。这里,我们也可以使用zookeeper集群替代Sokeeper。
docker sofa-stream-master:
sofa-stream-master为SOFA流计算平台的主节点docker镜像。首先,我们的docker容器与容器之间是通过overlay网络访问,启动docker engine时,需要指定Sokeeper或zookeeper或其他K-V存储来实现容器发现彼此。overlay网络环境建立之后,随即根据已经打好的master镜像启动容器,此时需要指定容器对外映射的端口,以及给容器分配的cpu,内存资源等。容器创建好之后,则将容器添加至overlay网络,并指定IP地址(避免容器重启后,ip地址更改,造成不必要的麻烦)sofa流计算平台镜像基于centos操作系统,并集成了常用linux软件包(vim,ping,gcc等)以及jdk,hadoop,maven,storm-on-yarn等必要软件包,镜像通过dockerfile构建,构建完成后,即完成对jdk,hadoop等的安装,和环境变量的配置,并开启sshd。实际使用时,使用者不需要再通过dockerfile构建镜像,使用者可通过sofa-stream-potal获取最新版本的镜像。
docker网络以及容器启动语句都将集成于shell脚本,并可在sofa-stream-potal上一键触发。
docker sofa-stream-slave:
sofa-slave docker镜像内集成的软件基本与master相似,slave上运行yarn的NodeManager进程,以及storm的Nimbus,Supervisor进程。需要注意的是,slave与master都需要完成hostname与ip地址的映射关系,以及实现免密互通。当需要扩容时,即是增加slave节点,并将slave节点加入至集群内。
sofa-stream-potal:
sofa-stream-potal是用户与流计算平台交互的接入层,通过sofa-stream-potal,使用者可对系统指标以及资源状况进行查看,创建分组用户,上传计算拓扑,并配置组件资源使用量等操作。sofa-stream-potal作为一个springBoot应用,可直接运行,其运行环境需要与sofa-stream-master容器网络互通。