正文之前
紧接上文: 《Effective Detection of Multimedia Protocol Tunneling using Machine Learning》译文(一)
正文
4 Decision Tree-based Classification
In this section, we depart from the use of similarity-based classifiers for detecting the presence of covert traffic. As it is unpractical to explore all possible machine learning algorithms, we focus our experiments in a subset of algorithms based on decision trees. We have chosen these algorithms due to their ability of handling data in a nonlinear fashion, their ability to perform feature selection, and the ease of interpretation of the resulting models. Our results show that this approach is highly effective at detecting covert traffic in the systems under study.
在本节中,我们不再使用基于相似性的分类器来检测隐蔽流量的存在。由于探索所有可能的机器学习算法是不切实际的,我们将我们的实验集中在基于决策树的算法子集中。我们选择这些算法是因为它们能够以非线性方式处理数据,能够执行特征选择,并且易于解释所得到的模型。我们的结果表明,这种方法在检测所研究系统中的隐蔽流量方面非常有效。
4.1 Selected Classifiers
We present a description of the decision-tree based algorithms we have chosen for conducting our experiments:
我们提供了我们为进行实验而选择的基于决策树的算法的描述:
Decision Trees [41] build a model in the form of a tree structure, where each tree node is either a decision or leaf node, representing a branch or a label, respectively. Decision nodes split the current branch by an attribute. A splitting attribute is commonly chosen according to its expected information gain, i.e. the expected reduction in entropy caused by choosing the attribute for a split. The importance of each particular attribute can be assessed by analyzing the tree structure, where nodes closer to the root have a higher importance than those down the tree. Despite its simple interpretation, decision trees can result in complex models unable to generalize well or can build unstable models due to the presence of large numbers of correlated features. A popular way to mitigate such disadvantages is to use decision tree ensembles.
Decision Trees [41]以树结构的形式构建模型,其中每个树节点分别是表示分支或标签的决策或叶节点。决策节点按属性拆分当前分支。通常根据其预期信息增益来选择分裂属性,即通过选择分割的属性而导致的熵的预期减少。可以通过分析树结构来评估每个特定属性的重要性,其中更靠近根的节点比树下的节点具有更高的重要性。尽管其解释简单,但决策树可能导致复杂模型无法很好地推广,或者由于存在大量相关特征而可能构建不稳定模型。减轻这些缺点的一种流行方法是使用决策树集合。
Random Forests [6] are an ensemble learning method, where a label is predicted by performing a majority vote over the output of multiple decisions trees. To prevent overfitting, Random Forests introduce variance in the model through bootstrap aggregation, i.e. each tree is trained using a random sample (with replacement) of the training set. Additionally, Random Forests select random attributes of the feature set when building each tree, a technique named feature bagging. One method for assessing the importance of an attribute is to average its information gain across all trees in the ensemble.
随机森林[6]是一种集合学习方法,其中通过对多个决策树的输出执行多数投票来预测标签。为了防止过度拟合,随机森林通过自举聚合在模型中引入方差,即使用训练集的随机样本(替换)训练每棵树。此外,随机森林在构建每棵树时选择要素集的随机属性,这是一种名为特征装袋的技术。评估属性重要性的一种方法是在整体中的所有树上平均其信息增益。
eXtreme Gradient Boosting (XGBoost) [9] is another technique for building a model based on an ensemble of decision trees; it relies on a technique known as gradient tree boosting. XGBoost starts by building a shallow decision tree (i.e., a weak learner). In each step, XGBoost creates a new tree which optimizes the predictions performed by trees in earlier stages. XGBoost benefits from a regularized model formalization to control overfitting. The importance of individual attributes can be computed in a similar fashion to that of Random Forests. We find the use of XGBoost to be promising among a large pool of classification algorithms. In fact, XGBoost has played a central role on multiple winning solutions for recent data mining competitions, spawning multiple domains, such as the KDD Cup 2016 [12, 44]
eXtreme Gradient Boosting(XGBoost)[9]是另一种基于决策树集合构建模型的技术;它依赖于一种称为渐变树增强的技术。 XGBoost首先建立一个浅层决策树(即弱学习者)。在每个步骤中,XGBoost都会创建一个新树,以优化树在早期阶段执行的预测。 XGBoost受益于正则化模型规范化以控制过度拟合问题。可以以与Random Forests类似的方式计算个体属性的重要性。我们发现使用XGBoost在大量分类算法中很有前途。实际上,XGBoost在最近的数据挖掘竞赛的多个获胜解决方案中发挥了核心作用,产生了多个领域,例如2016年KDD杯[12,44]
The next sections detail our experiments for evaluating the unobservability of Facet and DeltaShaper with the decision tree-based classifiers enumerated above. In our experiments we have used two distinct sets of features: summary statistics and quantized packet lengths. We omit a discussion over CovertCast, as we have found that all of these techniques can identify its covert traffic with a negligible false positive rate.
接下来的部分详细介绍了我们使用上面列举的基于决策树的分类器评估Facet和DeltaShaper的不可观察性的实验。在我们的实验中,我们使用了两组不同的特征:汇总统计和量化分组长度。我们省略了对CovertCast的讨论,因为我们发现所有这些技术都可以用可忽略的误报率识别其隐蔽流量。
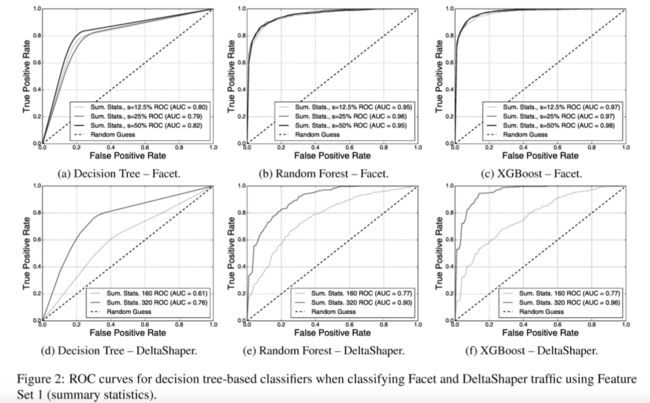
4.2 Feature Set 1: Summary Statistics
The collection of encrypted traffic provides an adversarywith two main sources of data for extracting features necessary for the detection of covert channels: a timeseriesof packet lengths, and a time series of packet interarrivaltimes. Our first set of features comprises a collection of summary statistics computed over the network traces of legitimate and covert traffic. This is a prevalent approach at generating features for the problem of encrypted traffic fingerprinting [22, 38, 49]. Such set of features has notbeen previously applied in the detection of covert channels generated by multimedia protocol tunneling. As for the choice of summary statistics, we compute multiple descriptive statistics for the ingress/ egress packet flows of a connection as a whole, as well as for ingress/ egress traffic individually. This feature set includes simple descriptive statistics over the packet lengthand interarrival time timeseries - such as maximum,minimum, mean, and percentiles - as well as higherorder statistics like the skew or kurtosis of these timeseries. We also consider burst behavior [l], where aburst is a sequence of consecutive packets transmitted along the same direction of a given connection. A total of 166 features are used for training our classifiers. Due to space constraints, we relegate a full listing of the summary statistics we have considered to the appendix. Next, we present our main findings after attempting to detect multimedia protocol tunneling covert channels using the decision-tree based classifiers we have described, while feeding them with our collection of summary statistics. We report the performance of each classifier over 10-fold cross-validation.
加密流量的集合为对手提供了两个主要数据源,用于提取检测隐蔽信道所需的特征:分组长度的时间序列和分组间隔时间的时间序列。我们的第一组功能包括通过合法和隐蔽流量的网络跟踪计算的汇总统计信息的集合。这是为加密流量指纹识别问题生成特征的一种流行方法[22,38,49]。这些特征集先前尚未应用于多媒体协议隧道生成的隐蔽信道的检测。至于摘要统计的选择,我们计算整个连接的入口/出口数据包流的多个描述性统计数据,以及单独的入口/出口流量。此功能集包括对包长度到达时间间隔的简单描述性统计 - 例如最大值,最小值,平均值和百分位数 - 以及更高阶的统计数据,如这些时间序列的偏斜或峰度。我们还考虑突发行为[1],其中aburst是沿给定连接的相同方向发送的连续分组序列。共有166个特征用于训练我们的分类器。由于空间限制,我们将我们考虑的摘要统计信息的完整列表放到附录中。接下来,我们在尝试使用以下方法检测多媒体协议隧道隐蔽信道之后,给出了我们的主要发现。我们已经描述了基于决策树的分类器,同时用我们的汇总统计数据集来训练它们。我们报告每个分类器的性能超过十折交叉验证。
十折交叉验证,英文名叫做10-fold cross-validation,用来测试算法准确性。是常用的测试方法。将数据集分成十份,轮流将其中9份作为训练数据,1份作为测试数据,进行试验。每次试验都会得出相应的正确率(或差错率)。10次的结果的正确率(或差错率)的平均值作为对算法精度的估计,一般还需要进行多次10折交叉验证(例如10次10折交叉验证),再求其均值,作为对算法准确性的估计。
1. The use of Random Forest/ XGBoost, used in tandem with summary statistics, largely undermines the unobservability claims of state-of-the-art multimedia protocol tunneling systems. Figure 2 shows the ROC curve for our decision tree -based classifiers when detecting Facet and DeltaShaper traffic resorting to summary statistic features (ST). Random Forest - ST exhibits a minimum AUC=0.95 when classifying all configurations of Facet taffic, while XGBoost - ST exhibits a minimum AUC=0.97. When compared to XGBoost - ST, the x2 classifier attains a maximum AUC=0.85. For DeltaShaper traffic, XGBoost - ST attains an AUC which is 0.22 larger for both DeltaShaper configurations, when compared to that obtained by the x2 classifier.
1.随机森林/ XGBoost的使用与摘要统计一起使用,在很大程度上破坏了最先进的多媒体协议隧道系统的不可观察性要求。图2显示了检测Facet和DeltaShaper流量采用汇总统计特征(ST)时基于决策树的分类器的ROC曲线。随机森林 - ST 当对所有Facet流量配置进行分类时,表现出最小AUC = 0.95,而XGBoost-ST表现出最小AUC = 0.97。与XGBoost-ST相比,x2分类器达到最大AUC = 0.85。对于DeltaShaper流量,XGBoost-ST获得的AUC比两个DeltaShaper配置大0.22,与x2分类器相比。
AUC(Area Under Curve)被定义为ROC曲线下与坐标轴围成的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
2. It is possible to flag a vast majority of covert channels with a very small number of false positives. An adversary that aims at flagging at least 90% of all Facet s=50% connections incurs in a 14.1% FPR when resorting to Random Forest - ST, and a FPR as short as 7.1% when resorting to XGBoost - ST. To flag at least 70% of the same kind of traffic, XGBoost - ST incurs in a FPR of only 1%. In comparison, Figure 1a shows that for correctly identifying just 70% of Facet s=50% traffic when resorting to the X2 classifier, an adversary would face an alarming 21 .5% FPR. The situation is similar for an adversary wishing to flag 90% of DeltaShaper (320x 240,8x 8,6, 1) raffic. For flagging 90% of this kind of traffic, Random Forest ST incurs in a 30.3% FPR and XGBoost ST incurs in a 12.1% FPR. To flag 70% of the same kind of traffic, XGBoost - ST incurs in a FPR of 4%. Flagging just 70% of this kind of traffic with the X- classifier would amount to a 32.2% FPR.
2.有可能用绝对少量的误报来标记绝大多数隐蔽通道。旨在标记至少90% Facet s = 50%连接的对手在使用随机森林 - ST时产生14.1%的FPR,并且当使用XGBoost-ST时,FPR减少至7.1%。而如果只是为了标记至少70%的同样流量,XGBoost-ST的FPR仅为1%。相比之下,图1a显示,在使用X2分类器时,为了正确识别70%的Facet s = 50%的流量,对手将面临惊人的21.5%FPR。对于希望标记90% DeltaShaper(320x 240,8x 8,6,1)交易的对手而言,情况类似。为了标记90%的此类流量,Random Forest ST产生30.3%的FPR,而XGBoost ST产生12.1%的FPR。为了标记70%的同类流量,XGBoost-ST的FPR为4%。用X2分类器标记这种流量的70%将达到32.2%的FPR。
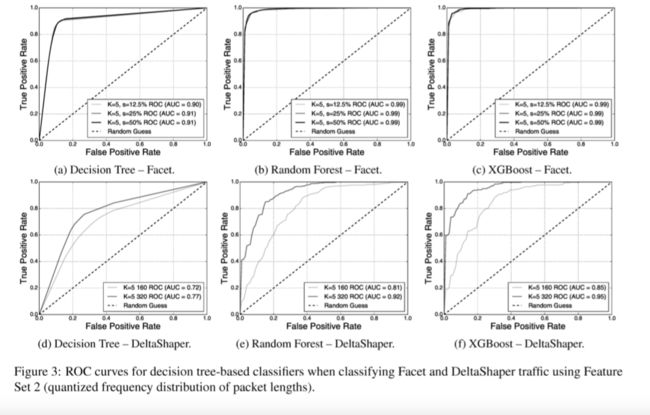
4.3 Feature Set 2: Quantized PLs(特征集2:量化PL)
An alternative feature set is comprised of the quantized frequency distribution of packet lengths, where each K size bin acts as an individual feature. While this feature set is akin to that previously used in KL and EMD similarity-based classifiers, we process these features in a fundamentally different way. In particular, the similarity-based classifiers output a distance score based on the overall difference of the packet lengths frequency distribution, while failing to adjust this score according to the importance of relevant regions of the feature space. Informally, they risk to dilute the greater discriminating power of a given feature among that of possibly irrelevant features [35]. We aim at exploiting the different relevance of particular ranges of the feature space by feeding this feature set to decision tree-based classifiers.
In terms of feature sets, for Facet, we take as features the quantized frequency distribution of packet lengths for the flow carrying covert data. We use K=5 as we have experimentally verified that the classification performance of our decision tree-based algorithms benefit from a finegrained quantization. As for DeltaShaper, and due to the system's bidirectionality, we use the quantized frequency distribution of packet sizes flowing in both directions. Here, we also apply a quantization with K=5. Note that the evaluation performed with the similarity-based classifiers described in Section 3 also considers the same selection on the direction of traffic flows to analyze.
Next, we describe our findings after attempting to identify covert traffic with such feature sets. Figure 3 shows the ROC curve for our decision treebased classifiers when detecting Facet and DeltaShaper traffic resorting to quantized packet lengths as features (PL).
另一个特征集包括分组长度的量化频率分布,其中每个K大小的区间作为单独的特征。虽然此功能集类似于之前在KL和EMD基于相似性的分类器中使用的功能集,但我们以完全不同的方式处理这些功能。具体地,基于相似度的分类器基于分组长度频率分布的总体差异输出距离分数,而未能根据特征空间的相关区域的重要性来调整该分数。非正式地,它们有可能削弱特定特征在可能不相关的特征之间的更大区别能力[35]。我们的目标是通过将此特征集提供给基于决策树的分类器来利用特征空间的特定范围的不同相关性。
就特征集而言,对于Facet,我们将流量携带隐蔽数据的分组长度的量化频率分布作为特征。我们使用K = 5,因为我们已经通过实验验证了基于决策树的算法的分类性能受益于细粒度量化。至于DeltaShaper,由于系统的双向性,我们使用在两个方向上流动的数据包大小的量化频率分布。这里,我们还应用K = 5的量化。请注意,使用第3节中描述的基于相似性的分类器执行的评估也考虑了要分析的业务流方向的相同选择。
接下来,我们在尝试使用此类功能集识别隐蔽流量后描述我们的发现。图3显示了当检测Facet和DeltaShaper流量采用量化数据包长度作为特征(PL)时,基于决策树的分类器的ROC曲线。
1. Quantized packet lengths outperform the use of summary statistics. In general, the AUC obtained by our decision-tree based classifiers is comparable or superior to the AUC obtained by the same classifiers when making use of summary statistics. Both Random Forest - PL and XGBoost - PL obtain an AUC=0.99 when identifying Facet traffic. This represents a maximum improvement of 0.04 over Random Forest ST and 0.02 over XGBoost - ST. While Decision Tree - PL attains a maximum AUC=0.91, it is still short of the maximum AUC attained by Random Forest - ST. This trend is similar in the classification of DeltaShaper traffic, where the AUC obtained by Decision Tree - PL is also inferior to that of tree ensembles. The detection of (160x 120,4 x 4,6, 1) DeltaShaper traffic benefits the most from packet length features, where XGBoost - PL attains an AUC=0.85, 0.08 larger than that obtained by XGBoost - ST. Interestingly, the detection of (320 x 240,8 x 8,6, 1) DeltaShaper raffic is better performed by XGBoost - ST, albeit by a slight improvement of 0.01 over the AUC of XGBoost - PL.
1.量化的数据包长度优于使用汇总统计数据。通常,我们的基于决策树的分类器获得的AUC与使用汇总统计时由相同分类器获得的AUC相当或更优。随机森林 - PL和XGBoost - PL在识别Facet流量时获得AUC = 0.99。这表示与Random Forest ST相比最大改善0.04,而在XGBoost-ST上最大改善0.02。当决策树 - PL达到最大AUC = 0.91时,它仍然低于随机森林 - ST获得的最大AUC。这种趋势在DeltaShaper流量的分类中类似,其中Decision Tree-PL获得的AUC也低于树集合的AUC。(160x 120,4 x 4,6,1)DeltaShaper流量的检测从包长度特征中获益最多,其中XGBoost-PL达到AUC = 0.85,比XGBoost-ST获得的大0.08。有趣的是,XGBoost-ST可以更好地检测(320 x 240,8 x 8,6,1)DeltaShaper流量,尽管比XGBoost-PL的AUC稍微提高了0.01。
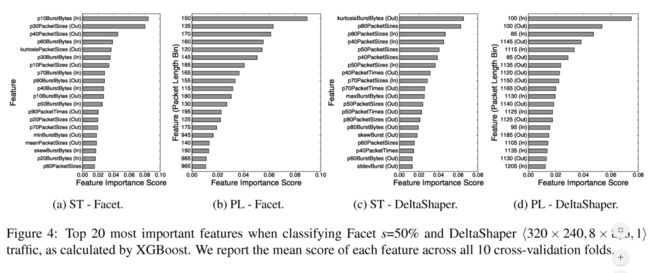
4.4 Feature Importance
The above set of experiments allowed us to implicitly identify which features are more important to distinguish between two classes of raffic. Figure 4a shows the top 20 most important summary statistics for detecting Facet traffic s =50%, as reported by the XGBoost algorithm. Figure 4b summarizes the 20 most important quantized ranges of packet lengths. The features annotated with “Out” correspond to those generated by the packet flow directed towards the client (carrying the covert payload), while the features annotated with In" correspond to the packet flow directed towards the Facet server. Figure 4c depicts the top 20 most important summary statistics for detecting DeltaShaper (320 x 240,8 x 8,6, 1) raffie, as reported by XGBoost. Similarly, Figure 4d depicts the most important quantized ranges of packet lengths for detecting the same kind of traffic. Each feature is annotated with "Out or In", depending on the particular Skype peer originating covert traffic. We note that both peers generate covert traffic simultaneously due to DeltaShaper's bidirectionality. Below, we discuss the main findings of our analysis.
上述一组实验使我们能够隐含地确定哪些特征对于区分两类流量更为重要。图4a显示了检测Facet流量s = 50%的前20个最重要的汇总统计信息,如XGBoost算法所报告的。图4b总结了20个最重要的分组长度量化范围。用“Out”注释的特征对应于由指向客户端的分组流(携带隐蔽有效载荷)生成的特征,而用“In”注释的特征对应于指向Facet服务器的分组流。图4c描绘了前20个用于检测DeltaShaper(320 x 240,8 x 8,6,1)raffie的最重要的摘要统计数据,如XGBoost所报告的那样。图4d描述了用于检测相同类型流量的最重要的数据包长度量化范围。用“Out”或“In”注释,取决于特定的Skype同伴发起的隐蔽流量。我们注意到由于DeltaShaper的双向性,两个对等体同时生成隐蔽流量。下面,我们讨论我们分析的主要发现。
1. Facet is more vulnerable to analysis based on packet lengths and burst behavior. Figure 4a shows that Facet detection is driven by features related to the packet lengths and the burst behavior of the connection, whereas packet timing does not contribute as much. An interesting observation is that the majority of packet bursts features considered important for classification are those included in the flow directed towards the Facet server, which carries no covert data. This fact suggests that Skype flows exhibit some degree of codependency and that both flows provide useful information for distinguishing between legitimate and covert transmissions. Features included in the top 10, and that directly concern the length of packets,index summary statistics from the flow carrying covert data. This suggests that the flow carrying covert data is the prime target for inspection when analyzing packet lengths. Additionally, packet lengths comprehended between the 10th and 40th percentiles, amounting to packets with a mean length comprehended between 138 and 213 bytes, have a superior discriminating power among other packet sizes(翻译的不是很好。。。我回头再看看). XGBoost ranks 123 of the 166 features with a non-zero importance score.
1. Facet更容易受到基于数据包长度和突发行为的分析的影响。图4a表示出了Facet检测由与分组长度和连接的突发行为相关的特征驱动,而分组定时没有贡献那么多。一个有趣的观察结果是,对于分类而言被认为重要的大多数分组突发特征是包含在面向Facet服务器的流中的那些,其不携带隐蔽数据。这一事实表明Skype流程表现出一定程度的相互依赖性,并且两种流程都提供了有用的信息来区分合法和隐蔽传输。前十名中包含的功能,直接涉及数据包的长度,来自携带隐蔽数据的流的索引摘要统计。这表明携带隐蔽数据的流量是分析数据包长度时检查的主要目标。另外,在第10和第40百分位之间理解的分组长度相当于具有在138和213字节之间的平均长度的分组,在其他分组大小之间具有优越的区分能力。 XGBoost对166个特征中重要性得分非零的123个进行排名。
2. DeltaShaper is more vulnerable to analysis based packet lengths. Figure 4c shows that l0 of the most important features for detecting DeltaShaper regard descriptive statistics of packet lengths. In particular, 7 out of the top l0 most important features for identifying DeltaShaper traffic are related to the length of transmitted packets. Contrary to Facet, these features include a mixture of traffic originating in different peers, which is expected according to the bidirectionality of the covert channel. We find the most influential packet lengths to be within the range of the 40th and 80th percentiles, amounting to packets with a mean length comprehended between 1026-1180 bytes. XGBoost ranks 132 of the 166 features with an importance score larger than zero.
2. DeltaShaper的分析对数据包的分组长度更加敏感。图4c显示了用于检测DeltaShaper的10个最重要的特征是关于分组长度的描述性统计。特别是,用于识别DeltaShaper流量的前10个最重要特征中的7个与传输分组的长度有关。与Facet相反,这些特征包括源自不同对等体的流量混合,这是根据隐蔽信道的双向性预期的。我们发现最有影响的数据包长度在40和80百分位的范围内,相当于平均长度在1026-1180字节之间的数据包。 XGBoost在166个特征中对重要性得分为非零的132个特征进行排名。
2. DeltaShaper is more vulnerable to analysis based packet lengths. Figure 4c shows that l0 of the most important features for detecting DeltaShaper regard descriptive statistics of packet lengths. In particular, 7 out of the top l0 most important features for identifying DeltaShaper traffic are related to the length of transmitted packets. Contrary to Facet, these features include a mixture of traffic originating in different peers, which is expected according to the bidirectionality of the covert channel. We find the most influential packet lengths to be within the range of the 40th and 80th percentiles, amounting to packets with a mean length comprehended between 1026-1180 bytes. XGBoost ranks 132 of the 166 features with an importance score larger than zero.
2. DeltaShaper更容易受到基于分析的数据包长度的影响。图4c显示了用于检测DeltaShaper的10个最重要的特征是关于分组长度的描述性统计。特别是,用于识别DeltaShaper流量的前10个最重要特征中的7个与传输分组的长度有关。与Facet相反,这些特征包括源自不同对等体的流量混合,这是根据隐蔽信道的双向性预期的。我们发现最有影响的数据包长度在40和80百分位的范围内,相当于平均长度在1026-1180字节之间的数据包。 XGBoost在166个特征中排名132,重要性分数大于零。
3. Facet covert channels can be spotted by looking for packets with a length comprehended between 115-195 bytes. Figure 4b not only shows that the most important bin corresponds to that by the packets which length is close to 150, but also that the top 10 features are dominated by packets which lengths are in the range of 115 to 195 bytes. This result concurs with our previous observation, where the most important percentiles of packet lengths focused packets with a mean length between 137 and 200 bytes. This observation is also true when detecting Facet s={12.5%,25%} traffic. This finding suggests that the major factor leading to the distinguishing of Facet traffic concerns the packets carrying audio, which are typically located in the range between 100 and 200 bytes [37]. Additionally, we can observe that some of the least important features included in the top 20 for identifying Facet s = 50% flows include packets with a length between 945-985 bytes. This result hints that larger areas dedicated to video payload translate into packet-level modifications in a higher range of the feature space. Additionally, XGBoost ranks only 175 out of 300 features with a non-zero importance score, suggesting that only approximately half of the quantized packet length bins contribute for the discrimination of Facet traffic.
3.通过查找长度在115-195字节之间的数据包,可以发现Facet隐蔽信道。图4b不仅表明最重要的bin对应于长度接近150的分组,而且前10个特征由长度在115到195字节范围内的分组控制。这个结果与我们之前的观察一致,其中最重要的数据包长度百分位集中了平均长度在137到200字节之间的数据包。当检测到Facet s = {12.5%,25%}流量时,这种观察也是如此。这一发现表明,导致Facet流量区分的主要因素涉及携带音频的数据包,这些数据包通常位于100到200字节之间[37]。另外,我们可以观察到,前20中用于识别Facet s = 50%流的一些最不重要的特征包括长度在945-985字节之间的分组。该结果暗示专用于视频有效载荷的较大区域转换为更高范围的特征空间中的分组级修改。此外,XGBoost在具有非零重要性分数的300个特征中仅排名175,这表明仅有大约一半的量化分组长度分组有助于区分Facet流量。
4. DeltaShaper covert channels can be spotted by looking for packets with a length between 85-100 and 1105-1205 bytes. Figure 4d shows that the two most important features for identifying DeltaShaper ⟨320 × 240,8×8,6,1⟩ traffic correspond to the packets which size is close to 100 bytes (flowing in both directions). The top 20 features are dominated by packet length bins in the range from 85-100 and 1105-1205 bytes, suggesting that DeltaShaper data modulation markedly affects two distinct regions of the feature space. The region including larger packets roughly overlaps the mean length of the packets included in the most important percentiles of our analysis of summary statistics. Considering that DeltaShaper’s covert data embedding procedure specifically targets the video layer of Skype calls, this finding suggests that such modulation largely affects larger packets of the connection. When classifying DeltaShaper ⟨320×240,8×8,6,1⟩ traffic, XGBoost ranks 253 out of 600 features with a non-zero importance score.
4.通过查找长度在85-100和1105-1205字节之间的数据包,可以发现DeltaShaper隐蔽通道。图4d显示识别DeltaShaper⟨320×240,8×8,6,1⟩流量的两个最重要的特征对应于大小接近100字节(在两个方向上流动)的分组。前20个特征由分组长度箱控制,范围从85-100和1105-1205字节,这表明DeltaShaper数据调制显着影响特征空间的两个不同区域。包括较大数据包的区域与我们的摘要统计分析中最重要百分位中包括的数据包的平均长度大致重叠。考虑到DeltaShaper的隐蔽数据嵌入程序专门针对Skype呼叫的视频层,这一发现表明这种调制很大程度上影响了较大的连接数据包。在对DeltaShaper⟨320×240,8×8,6,1⟩流量进行分类时,XGBoost在600个功能中排名253,具有非零重要性分数。
The most important features for detecting DeltaShaper ⟨160 × 120, 4 × 4, 6, 1⟩ traffic largely overlap the two feature set regions already reported. However, we verify that the region including larger packet lengths was significantly expanded, including bins representing packets with a size within the range of 885-1200 bytes.
检测DeltaShaper⟨160×120,4×4,6,1⟩流量的最重要特征在很大程度上重叠了已报告的两个特征集区域。但是,我们验证包含较大数据包长度的区域是否显著扩展,包括表示大小在885-1200字节范围内的数据包的bin。
4.5 Alternative Dataset Evaluation
We have constructed and handled our dataset by following the same methodology adopted by previous works under study. However, this methodology may raise a few concerns. In particular, the covert streams (positive class) have been produced using the available legitimate videos (negative class), which may introduce some form of correlation among classes. Furthermore, this methodology generates a 1:1 ratio of positive to negative classes, which may be unrealistic if covert streams are a minority among the traffic found in the wild. Thus, one may wonder how accurate is our classifier if: i) the positive class is no longer correlated with the negative class during testing; ii) the positive-to-negative sample ratio is low during testing. To validate the effectiveness of our approach, we performed two additional experiments.
我们按照以前研究中采用的相同方法构建和处理了我们的数据集。但是,这种方法可能引起一些担忧。特别是,隐藏流(正类)已经使用可用的合法视频(否定类)产生,这可能在类之间引入某种形式的相关性。此外,这种方法产生了1:1的正负比例,如果隐蔽流在公共环境中发现的流量中占少数,这可能是不现实的。因此,如果出现以下情况,我们可能会想知道我们的分类器有多准确:i)在测试过程中,正类不再与负类相关; ii)测试期间正负样本比率低。为了验证我们的方法的有效性,我们进行了另外两个实验。
First, we performed an experiment which removed the correlations between the positive and negative classes. We split our legitimate traffic dataset in half, using only one half as legitimate samples. Then, for creating our covert video dataset, we selected those covert videos which embed modulated data in the legitimate videos out of our reduced legitimate traffic dataset. We then used XGBoost to build a model through 10-fold crossvalidation. To prevent the fitting of results to a particular choice of the initial legitimate samples, we repeated the process 10 times while randomly choosing such samples.
首先,我们进行了一项实验,删除了正负类之间的相关性。我们将合法的流量数据集分成两半,只使用一半作为合法样本。然后,为了创建我们的隐蔽视频数据集,我们选择了那些将调制数据嵌入合法视频中的隐蔽视频,这些视频来自我们简化的合法流量数据集。然后我们使用XGBoost通过十折交叉验证来构建模型。为了防止将结果拟合到初始合法样本的特定选择,我们重复该过程10次,同时随机选择这样的样本。
Second, we performed an experiment where we keep the positive-to-negative sample ratio low during testing. We split our data in training / testing sets in a 70 / 30 proportion, and where we kept the training set ratio as 1:1, and keep the positive to negative ratio of the testing set to 1:100. To prevent the fitting of results to a particular split of the data, we randomly choose each set 10 times.
其次,我们进行了一项实验,在测试过程中我们将正负采样率保持在较低水平。我们将训练/测试集中的数据分成70/30比例,并且我们将训练集比率保持为1:1,并将测试集的正负比保持为1:100。为了防止将结果拟合到特定的数据分割,我们随机选择每组10次。
The results of our additional experiments suggest that possible correlations among training and testing data, as well as sample ratios, do not limit the accuracy of our approach. For our first experiment, XGBoost obtained an AUC=0.94 for DeltaShaper ⟨320 × 240, 8 × 8, 6, 1⟩ traffic (only 0.01 less than the results reported in Section 4.3), and an AUC=0.99 for traffic pertaining to Facet s=50% configuration. As for the second experiment, XGBoost was able to correctly identify 90% of Facet s=50% traffic with an FPR of only 2%, while it was able to identify 90% of DeltaShaper ⟨320×240,8×8,6,1⟩ traffic with an FPR of 18% (only 4% larger).
我们的其他实验结果表明,训练和测试数据之间可能的相关性以及样本比率并不会限制我们方法的准确性。对于我们的第一个实验,XGBoost获得了DeltaShaper⟨320×240,8×8,6,1⟩流量的AUC = 0.94(仅比第4.3节中报告的结果少0.01),并且与Facet相关的流量的AUC = 0.99 s = 50%配置。至于第二个实验,XGBoost能够正确识别90%的Facet s = 50%流量,FPR仅为2%,同时能够识别出DeltaShaper的总数为<300×240,8×8,6, 1⟩流量,FPR为18%(仅增加4%)。
4.6 Practical Considerations
This section details several practical considerations which may be useful to an adversary considering the use of decision tree classifiers for the detection of covert channels. The following results reflect processing time in a VM configuration akin to that described in Section 2.4.
本节详细介绍了考虑使用决策树分类器检测隐蔽通道的对手可能有用的几个实际考虑因素。以下结果反映了VM配置中的处理时间,类似于第2.4节中描述的处理时间。
Feature extraction. The extraction of quantized packet length bins from a 60 second Facet network trace amounts to an average of 0.33s per sample. Generating summary statistics describing the same type of traffic flow amounts to an average of 0.44s per sample. This result indicates that an adversary can quickly generate feature vectors for conducting subsequent classification.
特征提取。从60秒的Facet网络轨迹中提取量化的分组长度,每个样本平均0.33s。生成描述相同类型的流量的汇总统计数据平均为每个样本0.44s。该结果表明攻击者可以快速生成特征向量以进行后续分类。
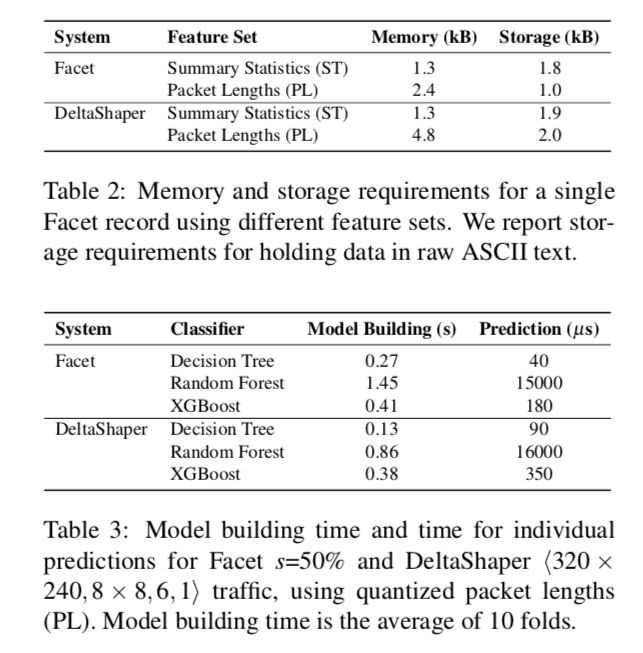
Memory and storage requirements. Table 2 depicts the memory and storage requirements for holding a single Facet or DeltaShaper sample. In our Python implementation, a NumPy [47] array storing the quantized packet lengths describing a Facet sample (300 attributes) occupies 2.4kB of memory per sample. In comparison, an array containing the bi-grams required by the χ2 classifier occupy a total of 45kB per sample. The numbers in Table 2 suggest that an adversary can efficiently store and process large datasets. As an example, storing 1 million Facet quantized packet lengths feature vectors in a raw ASCII text file would only occupy approximately 1GB of disk space. Storing summary statistics in raw ASCII text would occupy nearly twofold the space due to the characters required to represent floating-point precision.
内存和存储要求。表2描述了保存单个Facet或DeltaShaper示例的内存和存储要求。在我们的Python实现中,存储描述Facet样本(300个属性)的量化包长度的NumPy [47]数组占用每个样本2.4kB的内存。相比之下,包含χ2分类器所需的二元组的阵列每个样本总共占据45kB。表2中的数字表明,攻击者可以有效地存储和处理大型数据集。例如,在原始ASCII文本文件中存储100万个Facet量化包长度特征向量只占用大约1GB的磁盘空间。由于表示浮点精度所需的字符,在原始ASCII文本中存储摘要统计信息将占用几乎两倍的空间。
Model building and classification speed. Table 3 depicts the average training time of our classifiers, as well as the average time to output a prediction. Building a Decision Tree PL for identifying Facet traffic takes an average of 0.27s. For an ensemble composed of 100 trees, Random Forest PL and XGBoost – PL models are built in 1.45s and 0.41s, respectively. Moreover, the average classification time for an individual sample is 180μs for XGBoost – PL. XGBoost is not only more accurate but also trains faster and exhibits a faster classification speed than Random Forest. This relation is also present when classifying DeltaShaper traffic. These results stress the fact that an adversary would benefit from using XGBoost to detect multimedia protocol tunneling covert channels.
模型构建和分类速度。表3描述了我们的分类器的平均训练时间,以及输出预测的平均时间。构建用于识别Facet流量的决策树PL平均需要0.27秒。对于由100棵树组成的集合,Random Forest PL和XGBoost-PL模型分别建于1.45s和0.41s。此外,对于XGBoost-PL,单个样品的平均分类时间为180μs。 XGBoost不仅更准确,而且训练更快,并且比Random Forest表现出更快的分类速度。在对DeltaShaper流量进行分类时也会出现此关系。这些结果强调了这样一个事实,即攻击者将受益于使用XGBoost来检测多媒体协议隧道隐蔽信道。
Generalization ability of the classifiers. A classifier with good generalization ability is able to perform correct predictions for previously unseen data. Albeit the AUC obtained by our decision tree-based classifiers suggests that these can generalize well, we further assess their classification performance when training data is severely limited. We split our data in two 10 / 90 training and testing sets, and report the mean AUC obtained by the classifier after repeating this process 10 times while randomly choosing the samples making part of each set. In this setting, when classifying Facet s=50%, XGBoost PL attains an AUC=0.98, only 0.01 short of that obtained after 10x cross-validation. For DeltaShaper ⟨160×120,4×4,6,1⟩ traffic, XGBoost PL attains an AUC 0.1 smaller than their 10x cross-validation counterpart. These results suggest that an adversary can build accurate decision tree-based classifiers for detecting covert traffic while resorting to a small sample of data.
分类器的泛化能力。具有良好泛化能力的分类器能够对先前未见过的数据执行正确的预测。虽然我们基于决策树的分类器获得的AUC表明这些可以很好地推广,但是当训练数据严重受限时,我们会进一步评估其分类性能。我们将数据分成两个10/90训练和测试集,随机选择构成每组测试数据的样本,重复测试10次后报告分类器获得的平均AUC。在此设置中,当分级Facet s = 50%时,XGBoost PL达到AUC = 0.98,仅比十折交叉验证后获得的结果减少了0.01。对于DeltaShaper⟨160×120,4×4,6,1⟩流量,XGBoost PL的AUC比其十折交叉验证减少了0.1。这些结果表明,攻击者可以构建准确的基于决策树的分类器,以便在采用少量数据样本的同时检测隐蔽流量。
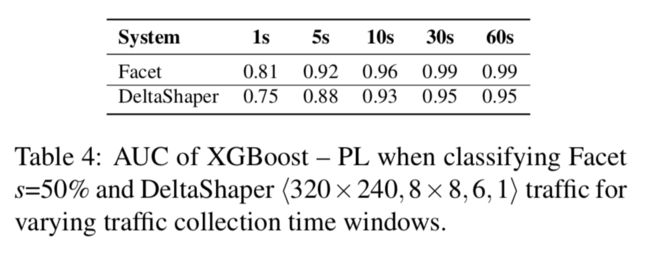
Impact of network traces collection time. Table 4 depicts the AUC obtained by XGBoost – PL when detecting different types of covert traffic for varying time-spans of traffic flows collection. Results show that capturing traffic by 30s is enough for attaining the same classification performance achieved in our initial experiments, which admitted 60s traffic captures. The numbers in Table 4 also show that classification performance decreases monotonically for traffic collections fewer than 30s, suggesting that the inspection of at least 30s of video traffic provides the adversary with sufficient data for identifying covert traffic flows with low false positives.
网络跟踪收集时间的影响。表4描述了XGBoost-PL在针对流量收集的不同时间跨度下,检测不同类型的隐蔽流量时获得的AUC。结果表明,捕获30s网络流量足以获得在我们最初的实验相同的分类性能,从60秒的流量捕获的结果就能看出来。表4中的数字还表明,对于少于30秒的流量收集,分类性能单调下降,这表明至少30s视频流量的检查为对手提供了足够的数据来识别具有低误报率的隐蔽流量。
正文之后
好气啊!!什么时候还有长度限制了?这是被攻击了???