一、环境介绍:
1、系统:Debian8.1
2、JAVA:jdk1.7.0_80
3、Hadoop:2.6.0-cdh5.15.1 Compiled with protoc 2.5.0
二、架构介绍
1、双namenode+zookeeper集群的HA使用sshfencing
HA namenode介绍:
Namenode 管理者文件系统的Namespace。它维护着文件系统树(filesystem tree)以及文件树中所有的文件和文件夹的元数据(metadata)。管理这些信息的文件有两个,分别是Namespace 镜像文件(Namespace image)和操作日志文件(edit log),这些信息被Cache在RAM中,当然,这两个文件也会被持久化存储在本地硬盘。Namenode记录着每个文件中各个块所在的数据节点的位置信息,但是他并不持久化存储这些信息,因为这些信息会在系统启动时从数据节点重建。
在hadoop1时代,只有一个NameNode。如果该NameNode数据丢失或者不能工作,那么整个集群就不能恢复了。这是hadoop1中的单点问题,也是hadoop1不可靠的表现。
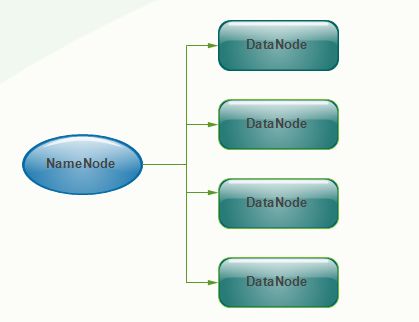
为了解决hadoop1中的单点问题,在hadoop2中新的NameNode不再是只有一个,可以有多个(目前只支持2个(2.4.1版本))。每一个都有相同的职能。一个是active状态的,一个是standby状态的。当集群运行时,只有active状态的NameNode是正常工作的,standby状态的NameNode是处于待命状态的,时刻同步active状态NameNode的数据。一旦active状态的NameNode不能工作,通过手工或者自动切换,standby状态的NameNode就可以转变为active状态的,就可以继续工作了。这就是高可靠。
JournalNode实现NameNode(Active和Standby)数据的共享
当有两个NameNode,一个standby一个active,当active有数据变动时,standby也应该及时更新,这样才可以做到高可靠!否则,信息不一致还怎么叫高可靠呢?
两个NameNode为了数据同步,会通过一组称作JournalNodes(JNs)的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了
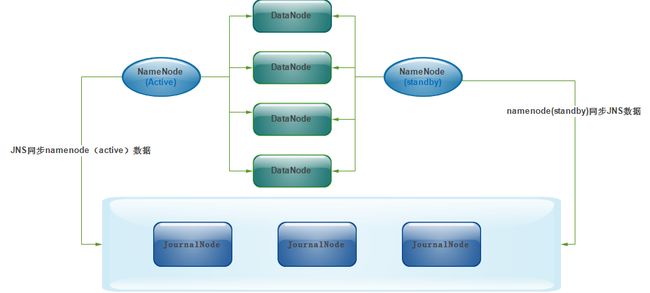
active的NameNode出现了故障,例如挂机了,是谁去切换standby的NameNode变为active状态呢?这时,就需要引入ZooKeeper。首先HDFS集群中的两个NameNode都在ZooKeeper中注册,当active状态的NameNode出故障时,ZooKeeper能检测到这种情况,它就会自动把standby状态的NameNode切换为active状态
2、3台journalnode的HA
上面已经知道了journalNode是负责同步主namenode元数据到从namenode上的,如果一个journalNode宕机之后,那么元数据将无法同步到从namenode,所以。这里使用3台journalnode作为备份
3、3台datanode节点
datanode不多说了,实际存储数据块的节点
三、搭建前的准备工作
1、配置主机名
root@master1:/usr/local/src# hostname master1 root@master1:/usr/local/src# vim /etc/hostname master1
root@master2:/usr/local/src# hostname master2 root@master2:/usr/local/src# vim /etc/hostname master2
root@slaver1:/usr/local/src# hostname slaver1 root@slaver1:/usr/local/src# vim /etc/hostname slaver1
root@slaver2:/usr/local/src# hostname slaver2 root@slaver2:/usr/local/src# vim /etc/hostname slaver2
root@slaver3:/usr/local/src# hostname slaver3 root@slaver3:/usr/local/src# vim /etc/hostname slaver3
2、配置ssh互信(master1免密码登录其他主机,方便使用ansible管理)
root@master2:/usr/local/src# hosts=(master1 master2 slaver1 slaver2 slaver3)
root@master2:/usr/local/src# for host in ${hosts[@]};do ssh-copy-id $host;done
3、配置hosts文件
root@master1:/usr/local/src# ansible nodes -m shell -a "echo '172.31.14.129 master1\n172.31.2.152 master2\n172.31.5.49 slaver1\n172.31.4.230 slaver2\n172.31.3.155 slaver3' >>/etc/hosts" master2 | success | rc=0 >> slaver1 | success | rc=0 >> master1 | success | rc=0 >> slaver2 | success | rc=0 >> slaver3 | success | rc=0 >> root@master1:/usr/local/src# ansible nodes -m command -a "cat /etc/hosts" master2 | success | rc=0 >> 127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 172.31.14.129 master1 172.31.2.152 master2 172.31.5.49 slaver1 172.31.4.230 slaver2 172.31.3.155 slaver3 slaver2 | success | rc=0 >> 127.0.0.1 localhost slaver2 ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 172.31.4.230 slaver2 172.31.14.129 master1 172.31.2.152 master2 172.31.5.49 slaver1 172.31.4.230 slaver2 172.31.3.155 slaver3 slaver1 | success | rc=0 >> 127.0.0.1 localhost slaver1 ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 172.31.5.49 slaver1 172.31.14.129 master1 172.31.2.152 master2 172.31.5.49 slaver1 172.31.4.230 slaver2 172.31.3.155 slaver3 master1 | success | rc=0 >> 127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 172.31.14.129 master1 172.31.2.152 master2 172.31.5.49 slaver1 172.31.4.230 slaver2 172.31.3.155 slaver3 slaver3 | success | rc=0 >> 127.0.0.1 localhost slaver3 ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 172.31.3.155 slaver3 172.31.14.129 master1 172.31.2.152 master2 172.31.5.49 slaver1 172.31.4.230 slaver2 172.31.3.155 slaver3
4、安装cloudera CDH源
root@master1:/usr/local/src# ansible nodes -m shell -a "echo 'deb http://cloudera.proxy.ustclug.org/cdh5/debian/jessie/amd64/cdh jessie-cdh5 contrib\ndeb-src https://archive.cloudera.com/cdh5/debian/jessie/amd64/cdh jessie-cdh5 contrib' >/etc/apt/sources.list.d/cloudera-cdh5.list" root@master1:/usr/local/src# ansible nodes -m command -a "apt-get update" root@master1:/usr/local/src# ansible nodes -m shell -a "curl -s http://archive.cloudera.com/cdh5/debian/wheezy/amd64/cdh/archive.key | sudo apt-key add -"
5、安装配置JAVA环境
下载地址
http://www.oracle.com/technetwork/java/archive-139210.html
root@master1:/usr/local/src# tar -zxvf server-jre-7u80-linux-x64.tar.gz root@master1:/usr/local/src# mv jdk1.7.0_80 /usr/lib/java/ root@master1:/usr/local/src# salt nodes -m shell -a "echo 'export JAVA_HOME=/usr/lib/java/jdk1.7.0_80\nexport JRE_HOME=/usr/lib/java/jdk1.7.0_80/jre\nexport CLASSPATH=:/lib:/jre/lib\nexport PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/bin:/jre/bin:$JAVA_HOME/bin' >>/etc/profile" root@master1:/usr/local/src# ansible nodes -m command -a "source /etc/profile" root@master1:/usr/local/src# ansible nodes -m command -a "java -version" slaver1 | success | rc=0 >> java version "1.7.0_181" OpenJDK Runtime Environment (IcedTea 2.6.14) (7u181-2.6.14-1~deb8u1) OpenJDK 64-Bit Server VM (build 24.181-b01, mixed mode) master2 | success | rc=0 >> java version "1.7.0_181" OpenJDK Runtime Environment (IcedTea 2.6.14) (7u181-2.6.14-1~deb8u1) OpenJDK 64-Bit Server VM (build 24.181-b01, mixed mode) master1 | success | rc=0 >> java version "1.7.0_181" OpenJDK Runtime Environment (IcedTea 2.6.14) (7u181-2.6.14-1~deb8u1) OpenJDK 64-Bit Server VM (build 24.181-b01, mixed mode) slaver2 | success | rc=0 >> java version "1.7.0_181" OpenJDK Runtime Environment (IcedTea 2.6.14) (7u181-2.6.14-1~deb8u1) OpenJDK 64-Bit Server VM (build 24.181-b01, mixed mode) slaver3 | success | rc=0 >> java version "1.7.0_181" OpenJDK Runtime Environment (IcedTea 2.6.14) (7u181-2.6.14-1~deb8u1) OpenJDK 64-Bit Server VM (build 24.181-b01, mixed mode)
四、安装hadoop依赖
1、为HA namenode安装配置zookeeper集群
namenode的failover要在zookeeper下实现。安装了cdh的仓库之后使用apt安装的版本太高,会导致namenode等其他包安装不上,所以在cloudera找了符合的版本进行安装
root@master1:/usr/local/src# wget root@master1:/usr/local/src# ansible zookeepernodes -m copy -a "src=./zookeeper_3.4.5+cdh5.15.0+144-1.cdh5.15.0.p0.52~jessie-cdh5.15.0_all.deb dest=/usr/local/src/"
root@master1:/usr/local/src# ansible zookeepernodes -m command -a "dpkg -i /usr/local/src/zookeeper_3.4.5+cdh5.15.0+144-1.cdh5.15.0.p0.52~jessie-cdh5.15.0_all.deb"
root@master1:/usr/local/src# cat /etc/zookeeper/conf/zoo.cfg
maxClientCnxns=50
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/var/lib/zookeeper
clientPort=2181
dataLogDir=/var/lib/zookeeper
server.1=master1:2888:3888
server.2=master2:2888:3888
server.3=slaver1:2888:3888
root@master1:/usr/local/src# ansible zookeepernodes -m copy -a "src=/etc/zookeeper/conf/zoo.cfg dest=/etc/zookeeper/conf/"
root@master1:/usr/local/src# zookeepers=(master1 master2 slaver3)
root@master1:/usr/local/src# for loop in ${zookeepers[@]};do ssh $loop "echo $count >/var/lib/zookeeper/myid";let count+=1 ;done
root@master1:/usr/local/src# ansible zookeepernodes -m command -a "service zookeeper-server init"
root@master1:/usr/local/src# ansible zookeepernodes -m command -a "service zookeeper-server start"
root@master1:/usr/local/src# ansible zookeepernodes -m command -a "/usr/lib/zookeeper/bin/zkServer.sh status"
master1 | success | rc=0 >>
Mode: followerJMX enabled by default
Using config: /usr/lib/zookeeper/bin/../conf/zoo.cfg
slaver1 | success | rc=0 >>
Mode: leaderJMX enabled by default
Using config: /usr/lib/zookeeper/bin/../conf/zoo.cfg
master2 | success | rc=0 >>
Mode: followerJMX enabled by default
Using config: /usr/lib/zookeeper/bin/../conf/zoo.cfg
2、hadoop-yarn-resourcemanager
2.1、YARN基础架构
Hadoop 2.0 中新引入的资源管理系统,它的引入使得 Hadoop 不再局限于 MapReduce 一类计算,而是支持多样化的计算框架。它由两类服务组成,分别是 ResourceManager 和 NodeManager。
MRv2的YARN体系结构的基本思想是将JobTracker的两个主要职责——资源管理和任务调度/监控——分解成单独的守护进程:全局资源管理程序(RM)和每个应用程序应用程序管理程序(AM)。使用MRv2, ResourceManager (RM)和每个节点nodemanager (NM)形成了数据计算框架。ResourceManager服务有效地取代了JobTracker的功能,nodemanager在从节点上运行,而不是在TaskTracker守护进程上运行。实际上,每个应用程序的ApplicationMaster是一个特定于框架的库,其任务是与ResourceManager协商资源,并与NodeManager(s)合作执行和监视任务。
ResourceManager(RM)
接收客户端任务请求,接收和监控 NodeManager(NM) 的资源情况汇报,负责资源的分配与调度,启动和监控 ApplicationMaster(AM)
2.2、安装hadoop-yarn-resourcemanager
root@master1:/usr/local/src# ansible namenodes -m command -a "apt-get install hadoop-yarn-resourcemanager -y" root@master1:/usr/local/src# ansible namenodes -m command -a "/etc/init.d/hadoop-yarn-resourcemanager start"
3、安装journalnode
root@master1:/usr/local/src# ansible zookeepernodes -m command -a "apt-get install hadoop-hdfs-journalnode -y" root@master1:/usr/local/src# ansible zookeepernodes -m command -a "service hadoop-hdfs-journalnode start"
4、安装namenode
root@master1:/usr/local/src# ansible namenodes -m command -a "apt-get install hadoop-hdfs-namenode" root@master1:/usr/local/src# ansible namenodes -m command -a "apt-get install hadoop-hdfs-zkfc" root@master1:/usr/local/src# ansible namenodes -m command -a "service hadoop-hdfs-zkfc start"
4.1、配置namenode的HA
root@master1:/usr/local/src# ansible namenodes -m command -a "cp -r /etc/hadoop/conf.empty /etc/hadoop/conf.my_cluster" root@master1:/usr/local/src# ansible namenodes -m command -a "update-alternatives --install /etc/hadoop/conf hadoop-conf /etc/hadoop/conf.my_cluster 50" root@master1:/usr/local/src# ansible namenodes -m command -a "update-alternatives --set hadoop-conf /etc/hadoop/conf.my_cluster" root@master1:/usr/local/src# ansible namenodes -m command -a "update-alternatives --display hadoop-conf" hadoop-conf - manual mode link currently points to /etc/hadoop/conf.my_cluster /etc/hadoop/conf.empty - priority 10 /etc/hadoop/conf.impala - priority 5 /etc/hadoop/conf.my_cluster - priority 50 Current 'best' version is '/etc/hadoop/conf.my_cluster'.
4.2、namode主要配置文件
1、hdfs-site.xml
root@master1:/etc/hadoop/conf.my_cluster# cat hdfs-site.xmldfs.namenode.shared.edits.dir qjournal://master1:8485;master2:8485;slaver1:8485/cluster dfs.journalnode.edits.dir /space/hadoop/data/dfs/cache/journal dfs.namenode.http-bind-host 0.0.0.0 dfs.namenode.name.dir file:///space/hadoop/data/dfs/nn dfs.datanode.data.dir file:///space/hadoop/data/dfs/dn dfs.nameservices mycluster dfs.ha.namenodes.mycluster master1,master2 dfs.namenode.rpc-address.mycluster.master1 master1:8020 dfs.namenode.http-address.mycluster.master1 master1:50070 dfs.namenode.rpc-address.mycluster.master2 master2:8020 dfs.namenode.http-address.mycluster.master2 master2:50070 dfs.ha.automatic-failover.enabled true dfs.client.failover.proxy.provider.mycluster org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider dfs.ha.fencing.methods sshfence dfs.ha.fencing.ssh.private-key-files /var/lib/hadoop-hdfs/.ssh/id_rsa dfs.replication 3 dfs.permissions.superusergroup hadoop
2、core-site.xml
root@master1:/etc/hadoop/conf.my_cluster# cat core-site.xmlfs.defaultFS hdfs://mycluster hadoop.tmp.dir /space/hadoop/data/temp ha.zookeeper.quorum master1:2181,master2:2181,slaver1:2181 fs.trash.interval 120
3、同步从namenode配置文件
root@master1:/usr/local/src# scp -r /etc/hadoop/conf.empty/* master2:/etc/hadoop/conf.empty/
4、准备hadoop数据目录
root@master1:/usr/local/src# ansible namenodes -m shell -a "mkdir -p /space/hadoop/data/dfs/nn" root@master1:/usr/local/src# ansible namenodes -m shell -a "mkdir -p /space/hadoop/data/dfs/cache/journal && chown -R /space/hadoop/data/"
5、hdfs用户的免密登录
5.1、主namenode
root@master1:/usr/local/src# su hdfs hdfs@master1:/usr/local/src$ ssh-keygen hdfs@master1:/usr/local/src$ scp-copy-id master2
5.2、从namenode
root@master2:/usr/local/src# su hdfs hdfs@master2:/usr/local/src$ ssh-keygen hdfs@master2:/usr/local/src$ scp-copy-id master1
6、namenode的初始化
6.1、在其中一台zookeeper初始化HA状态
root@master1:/etc/hadoop/conf.my_cluster# sudo -u hdfs hdfs zkfc -formatZK
6.2、在主namenode上格式化hdfs
root@master1:/etc/hadoop/conf.my_cluster# sudo -u hdfs hdfs namenode -format PRESS Y root@master1:/etc/hadoop/conf.my_cluster# /etc/init.d/hadoop-hdfs-namenode start
6.3、从namenode的启动
root@master2:/etc/hadoop/conf.my_cluster# sudo -u hdfs hdfs namenode -bootstrapStandby root@master2:/etc/hadoop/conf.my_cluster# sudo -u hdfs hdfs namenode -initializeSharedEdits root@master2:/etc/hadoop/conf.my_cluster# /etc/init.d/hadoop-hdfs-namenode start
五、验证故障切换
1、查看两个namenode的状态
root@master1:/etc/hadoop/conf.my_cluster# sudo -u hdfs hdfs haadmin -getServiceState master1 active root@master1:/etc/hadoop/conf.my_cluster# sudo -u hdfs hdfs haadmin -getServiceState master2 standby
2、上传文件到hdfs上
root@master1:/etc/hadoop/conf.my_cluster# hadoop fs -mkdir /test root@master1:/etc/hadoop/conf.my_cluster# hadoop fs -put /space/test.txt /test/ root@master1:/etc/hadoop/conf.my_cluster# hadoop fs -ls /space Found 1 items -rw-r--r-- 3 hdfs hadoop 2 2018-08-24 18:48 /test/test.txt
3、停止主namenode服务
root@master1:/etc/hadoop/conf.my_cluster# /etc/init.d/hadoop-hdfs-namenode stop root@master1:/etc/hadoop/conf.my_cluster# sudo -u hdfs hdfs haadmin -getServiceState master1 standby root@master1:/etc/hadoop/conf.my_cluster# sudo -u hdfs hdfs haadmin -getServiceState master2 active
master2自动切换成主
4、验证文件是否还在
root@master2:/usr/local/src# hadoop fs -ls /space Found 1 items -rw-r--r-- 3 hdfs hadoop 2 2018-08-24 18:48 /input/test1.txt
六、安装配置故障汇总
1、namenode无法自动failover 由于debian使用ssh的版本是6.7新版本,hadoop的加密方法使用不了,所以在fencing时报错不能连接
在/etc/ssh/sshd_config中加入“KexAlgorithms [email protected],ecdh-sha2-nistp256,ecdh-sha2-nistp384,ecdh-sha2-nistp521,diffie-hellman-group-exchange-sha256,diffie-hellman-group14-sha1,diffie-hellman-group-exchange-sha1,diffie-hellman-group1-sha1”并重启ssh即可解决
2、在验证故障切换时,使用hdfs fs -pu发现hdfs只能读不能写,提示namenode处于安全模式
排查步骤:
2.1、主namenode下线之后,查看从的状态是active,但是下面的live Nodes是0,磁盘和块均看不到信息
2.2、检查namenode错误日志,未发现异常
2.3、检查datanode提示不能连接到master1?并没有报master2连接不上
2.4、重新启动datanode发现错误:WARN org.apache.hadoop.hdfs.DFSUtil: Namenode for mycluster remains unresolved for ID master2. Check your hdfs-site.xml file to ensure namenodes are configured properly.
2.5、检查hdfs-site.xml发现master2的节点属性我写错了,value写成了name,改回来启动正常。在测试,已经可读可写
3、各种端口不通,防火墙放行,关闭selinux,如果是云主机,组安全策略也要放行。
至此,namenode的高可用搭建完成,以后会补上ResourceManager的HA。