种子站点的集中特性使得它们很容易被关闭(提供音乐、电影等版权内容的种子文件的网站经常会因法律原因而被关闭,如海盗湾等的关停或者被墙,较近的如17年5月17日Extra Torrent关停)。
而来自土耳其·伊斯坦布尔的19岁程序员Bora想要解决这个问题,致力于真正的去中心化文件分享,他用python制作了一个开源软件,使得可以轻松地在自己的电脑上开启一个种子搜索引擎。(进一步,用pyinstaller打包成exe,前端用electron或者其它工具简单封装一下,完全不熟悉python 的普通用户也可以轻松使用)。
实际上再进一步,如果每个人将自己搜索到的种子数据在开放无审查的零网上进行分享互换(这也可以用python自动化),就可以实现完全无审查去中心化的文件分享机制。(零网参见开放的零网与个人站点尝试)
使用效果图
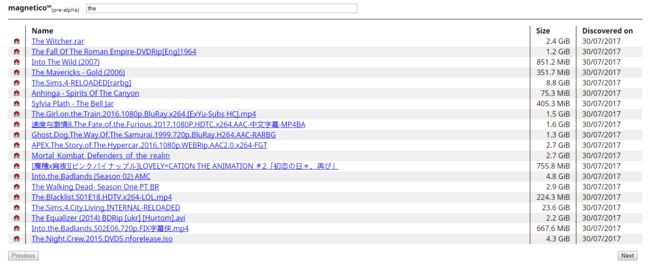
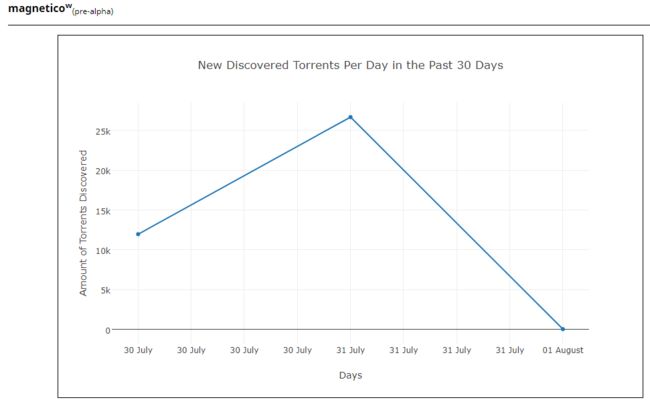
- 在腾讯云最低配服务器上跑了两天的效果,可以看出速度还是很快的,一天上万种子。
快速安装
-
linux使用:在python3的虚拟环境下(小白可以参看云服务器简单配置)
pip3 install magneticod就安装好了种子爬虫,在虚拟环境下命令行执行magneticod就可以运行了,等待一会儿,可以看到如下的日志输出,表明爬虫正在运行,并且收集到种子了。
(也可以使用
magneticod -d运行显示更详细的信息,-d参数表示输出debug信息。)
网页显示与查询功能安装,同样在虚拟环境下pip install magneticow就好了,然后命令行magneticow --port 8080 --user 用户名 密码就可以运行在8080端口了。使用localhost:8080访问,输入自己更改的用户名和密码即可。 -
windows使用:windows下直接使用pip安装暂时有点问题(可以先尝试像上面那样pip安装),需要到github上下载源码包 - download zip,如下图:

然后解压进入magneticod文件夹,在当前目录打开命令行,python setup.py install安装,再进入magneticow文件夹同样命令安装。还需要做一件事,就是找到你的python动态链接库中的sqlite3.dll(我的在Anaconda3\DLLs路径下),在SQLite Download Page找到适合你版本的sqlite-dll替换掉它,我用的是sqlite-dll-win64-x64-3200000.zip。(参考stackoverflow)这样就可以成功运行了。
windows的使用效果不如linux(暂时认为是windows的bug,udp也会报错——[WinError 10054] 远程主机强迫关闭了一个现有的连接),限制速度之后就会好。
 windows不限速
windows不限速
种子与磁力链接
- 说实话,作为一个从不开车、偶尔上车的良好公民 :),我对这些东西的了解十分有限。
- 我一直习惯使用的是基于ipv6的非公开BT站点,类似北邮人BT、6维空间这样需要注册的BT站点。想要资源时,在站点上下载相应的种子(torrent)文件,使用utorrent客户端下载即可,至于其中的原理不求甚解,大概知道的就是下载完成该资源且开启ut客户端的用户越多我的下载速度越快,同时下载的人越多速度越快,因为下载的同时会互相上传文件的不同部分给对方,下载完成后要尽保种的义务,尽量开启ut客户端,方便其他用户下载该资源,增加我的上传量。分享文件做种时,要生成一个种子文件,并提交到站点服务器。
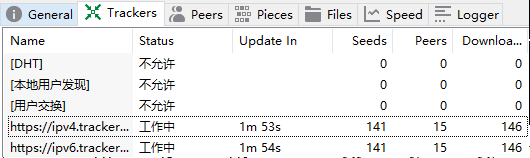
- 为了有更清楚的认知,打开ut客户端研究一下,顺便下载下权力的游戏最新集。用ut客户端打开种子进行下载,在下载时观察下面的状态栏,第二栏就是Trackers,看来是非常关键的一个东西。
基本概念 - Tracker:收集下载者信息的服务器,并将此信息提供给其他下载者,使下载者们相互连接起来,传输数据。
-
原来,该BT站点提供了一个Tracker服务器(倒数一二行),记录了所有下载者的信息或者文件分享者的信息,当我下载文件时,这个服务器会告诉我其他人的下载状态(谁拥有资源,谁下载完成了,谁正在下载),也告诉其他人我的下载状态,让我们互通有无,互相传递资源,增加下载速度,而tracker服务器充当了信息交换中心的角色。可以看到,第一行的DHT被禁用了,是为了不走外网流量,DHT非常重要,下文会讲到,暂时不管。

在peers一栏我们可以看到其他下载者的详细信息,大家互相帮助上传与下载。
-
在pieces一栏可以发现文件被分割成为很多份,每小份为1M大小,而我当前下载的视频为4个多G。在files栏里可以看到所有区块的下载状况。
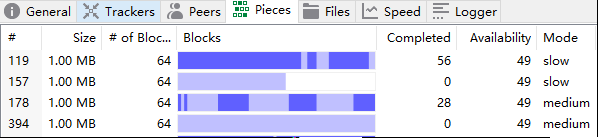

-
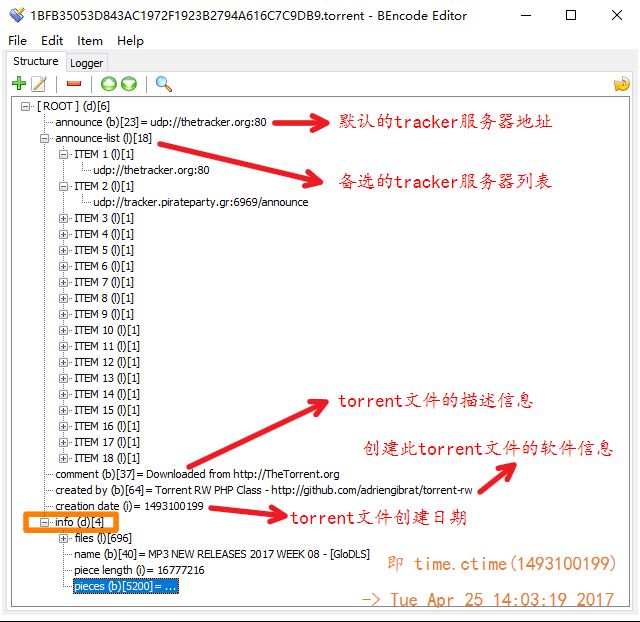
在对资源下载过程有了初步认识后,我们来详细地看下种子文件到底是什么。原来种子文件本质上是一种B编码后的文本文件,它包含了资源的详细信息,要打开它看里面的内容需要先解码,我们可以使用BEncode Editor这个软件。随便打开一个外网站点上下载的种子。

-
在BEncode Editor中显示如下,这个73KB的种子包含了丰富的信息,在它的tracker服务器列表中可以看到名为海盗党的希腊域名,这个种子文件也才创建不久。
-
而最关键的信息全在
info字典中,它是种子文件元信息。点开查看详细内容。可以看到下载文件的分块机制和我们之前在ut客户端看到的一致。在种子文件的元信息中包含了所有内容信息,以及所有分块的哈希验证码(数字指纹),来确保文件的真实性。在下载时我们会向种子文件中记录的tracker服务器发出请求,得到其他有该资源的用户的地址,一小块一小块的下载,每小块下载完成后都与种子文件中的该小块的哈希值进行比对,看是否被篡改。
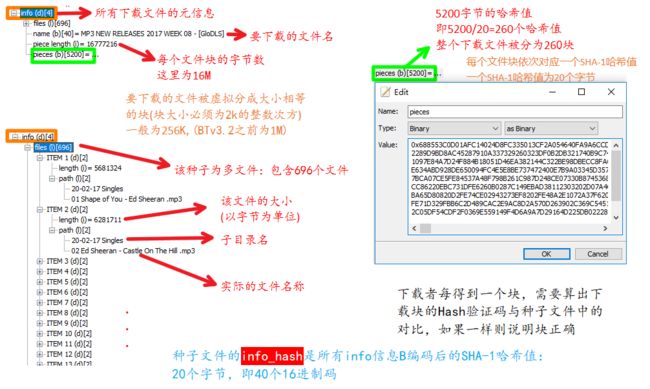
每个种子文件也具有一个唯一标识码,称为种子文件的info_hash,是种子中所有info信息B编码后的SHA-1哈希值:20个字节,即40个16进制码。根据这串码就能找到对应的种子文件。
-
除了种子,我们还会遇到磁力链接,如下图,磁力链接又是什么呢?

-
下图是一个磁力链接的分解,来自阮一峰老师的BT下载的未来,详细见wiki百科-磁力链接

可以得出磁力链接最重要的是红线勾出来的那40个16进制字符码,也就是种子文件的info_hash,根据它就能找到对应的种子文件,得到资源的详细信息,进而下载资源。
-
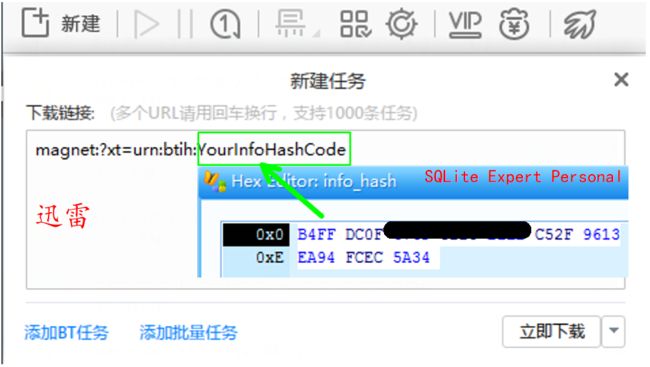
拥有这串16进制码,我们可以轻松构造出磁力链,通常我们会打开迅雷下载,迅雷会自动搜索相应的种子。
-
或者我们也可以到提供服务的站点,如thetorrent.org,由哈希码得到相应种子文件再进行下载。
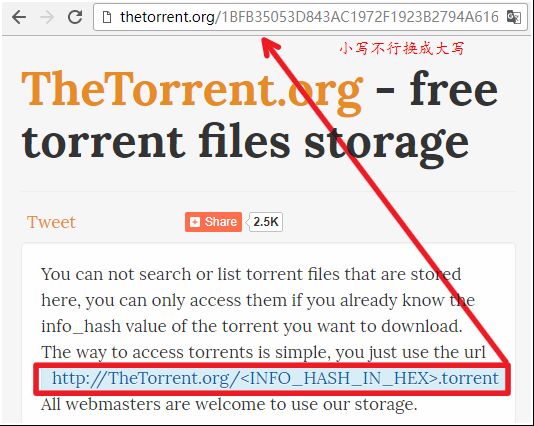 通过磁力链接中的info_hash码获取种子文件
通过磁力链接中的info_hash码获取种子文件 在没有服务商或站点情况下,通过info_hash码可以直接获取到相应的种子元信息及其资源吗?可以,基于DHT协议(BEP-5: DHT Protocol - 翻译),该协议基于Kademila算法,用udp实现。DHT是分布式哈希表的简写,用来存储种子的下载者(peer)的联系信息。一般每个下载者(peer)拥有一个节点(node),而DHT网络由节点组成(node)。每个节点(node)拥有一个唯一的ID:20字节标识码,和种子文件的info_hash一样长。每个节点都维持一个自己的路由表,存储了一小部分其他节点的联系方式,同时也存储了一些下载者的联系信息。节点之间互相联系帮助寻找资源。比如节点A拿着资源X的唯一标识码(info_hash)去问在它路由表中的节点B有没有资源X的下载者信息,如果节点B中没有资源X的记录信息,节点B会在自己的路由表中选出最可能拥有资源X的k个节点,把他们的联系方式返回给节点A,节点A再根据节点B的返回信息去联系这些节点进行询问,依次迭代。(每一个节点比其他节点对它周边的节点有更好的感知能力,
周边与否由Kademila算法定义)(node用来查找和存储信息,peer负责下载)(详细信息见BEP文档)只要找到一个种子的下载者(peer)就可以使用
BEP-9: Extension for Peers to Send Metadata Files拓展协议从该下载者(peer)处下载种子元信息(info)(同样可以使用元信息的哈希值(info_hash)来验证该信息的真实性),当然也可以从它那下载资源。这样只需要一个磁力链接在没有中心服务器的情况下也可以下载资源了。(注:ut客户端中会自动保存一份已下载资源的种子文件)
补充1:在前面我们看到的种子文件中,
announce键记录了tracker服务器的地址信息,在BEP-5的Torrent File Extensions小节中提到无tracker的种子文件中没有announce键,而有nodes键记录了良好的节点地址。总之,在一个新节点(自身路由表为空)加入DHT网络时,需要一个引导过程,要知道一个已经在该网络中的节点。要么通过tracker服务器获取节点,要么是直接得到节点,并没有那么自由。此外,tracker服务器的速度还是比DHT查找要快,一般下载过程是两者的结合。
补充2:文件分享过程
补充3:Kademlia算法概要 - Kademlia基于两个节点之间的距离计算,该距离是两个网络节点ID号的异或,计算的结果最终作为整型数值返回。资源的info_hash和节点ID有同样的格式和长度,因此,可以使用同样的方法计算资源(info_hash)和节点ID之间的距离。节点ID一般是一个大的随机数,选择该数的时候所追求的一个目标就是它的唯一性(希望在整个网络中该节点ID是唯一的)。异或距离跟实际上的地理位置没有任何关系,只与ID相关。因此很可能来自德国和澳大利亚的节点由于选择了相似的随机ID而成为邻居。选择异或是因为通过它计算的距离享有几何距离公式的一些特征
(此外还有用户交换 (PEX)协议,暂不讨论)
源码分析
注:网络分享繁多,很多话的正确性都不是那么高,深入探索还得自己去读官方英文协议和论文。别人的话都只是你通往更高处的一个垫脚石,不能停留在上面。
之前网络上已经有不少开源的dht种子搜索的python代码。比较有名的是手撕包菜种子搜索引擎网站的python代码(开源在github上),但在项目介绍里的相关博文链接已经失效,来看源码,关键的种子嗅探爬虫都在目录workers下。而最重要的info_hash码(即种子唯一标识码)爬虫为simdht_worker.py文件。主要使用了CreateChen/simDownloader项目中的代码。而与fanpei91/simDHT基本一致。
simDHT最简单易读,单线程,建议先阅读。思路是伪装成一个DHT节点。初始化时,给自己随机生成一个20位的ID,通过大的tracker服务器(如
router.bittorrent.com)获取其他节点的地址信息(find_node操作),进入DHT网络,利用KRPC协议传输B编码的字典信息,即DHT查询信息(4种,见bep05),与DHT网络中的其他节点互相通信。由于在初始化时已经从大的Tracker服务器获取了一定量的节点信息,接下来向这些节点发送
find_node请求,参数中:1. 将自己的ID构造成被请求节点的(按异或)相近ID(代码为get_neighbor函数,如向ID为A的节点发送find_node请求,将自己ID构造成A[:end]+X[:20-end],也就是构造的ID的前end位与A节点ID相同,而后(20-end)位随意,end取10-15,这样伪装成A的周边节点,而按规则每个节点对周边节点的感知能力要好,它很可能将你记录在它的路由表上,使得它自己或引导其他节点主动向你通信),2. 要查找的节点ID随机生成即可。大部分随机生成的节点ID是不可能直接查找到的,那么被请求节点会返回另一批节点信息,在接受到返回的新节点信息后,向新节点继续发送请求,依此迭代进行,目的就是不断地和其他节点混脸熟,即auto_send_find_node函数。这里维护了一个有限长的双端队列(deque)存储节点。节点不断从队首取出,向其发送find_node请求,收到的应答中的新节点不断被添加到队尾。如果队列为空,则重新初始化一下。一旦和越来越多的节点混脸熟了,就会有不断的查询请求从其他节点发送过来,作为爬虫,只要处理
get_peers和announce_peer请求就够了。get_peers是一个节点向另一个节点发出的查询与info_hash相关的下载者信息,包含的info_hash参数就是我们需要的种子的info_hash,但是,get_peers中包含的info_hash对应的种子可能已经失效或者难连接上,不采用。这时我们要回应它,关键是给他一个token(自己以一定方式生成,不固定,用来校验的)与一个空的nodes参数(我们没有种子的下载者信息,按协议应当返回最有可能有该信息的K个节点给查询节点,但是也可以返回空值)。这个向我查询的节点如果最终(通过其他节点)找到了资源(其他下载者,即peer),而控制该节点的下载者开始下载资源了,该节点很可能向我发送
announce_peer消息,该消息告诉我们它的下载者信息。消息参数中的info_hash和下载者地址就是我们需要的,同时要验证参数中的token是否就是我之前发送给该节点的,保证真实性。返回给它的消息只是自己节点的ID。对于其他节点发送给自己的
ping和find_node查询不用管即可。(可以思考,对于这两种查询是否有某种响应方式可以给自己带来更多收益)以上就是simDHT的内容了。
而进一步,光有种子的info_hash码还不够,能直接拿到种子的元信息就好了。这就是手撕包菜里的simMetadata.py实现的通过bep9拓展协议从之前
announce_peer消息中的下载者那里获取到种子的元信息。此外,wuzhenda/simDHT和0x0d/dhtfck实现了K桶等,有一定注释和他个人的理解,但作为爬虫可能并不需要这个功能,还有NanYoMy的DHT-woodworm 以及DHT-simDHT增加了一点新特性,可以浏览下。
以上都是python2的,基于python3的异步IO特性的DHT爬虫并不多,有whtsky/maga,而zrools基于maga,写了asyncDHT,并有图文并茂的博文,DHT爬虫:18.4GB种子分析小记,值得一看。
另外,B编码的编解码库:python2使用的多为bencode,
pip install bencode。python可以使用的有bcoding,pip install bcoding与better-bencode,pip install better-bencode。实现bttorrent客户端的python库libtorrent,貌似只支持python2,libtorrent库的使用可以看: 从磁力链获取种子文件 - Magnet_To_Torrent2.py的43行到67行(其他都是次要代码)。还可以参考creating daemon using Python libtorrent for fetching meta data of 100k+ torrents。(注:还发现有个Simple libtorrent,
pip install SimpleTorrentStreaming)回到文章开头使用的
magneticod,它使用了python3提供的asyncio机制。主要嗅探代码部分magneticod/dht.py中的思路和之前介绍的simDHT基本相似,有点不同的是,它维护了一个自己的节点字典self._routing_table,每一轮(间隔一秒)向里面所有节点发出find_node查询然后清空字典,如果收到自己发出的find_node请求的响应时,字典中的所有节点数超出self.__n_max_neighbours数则不再加入新节点。(主要函数为async def tick_periodically(self),这个机制还有可以斟酌的地方)在大的异步结构上继承了官方的
asyncio.DatagramProtocol,可以先看官方样例UDP echo client protocol和UDP echo server protocol,很简明,数据的发送和接收都封装好了,并且可以通过pause_writing和resume_writing控制流量。在处理
announce_peer消息时,用asyncio.ensure_future新建异步任务来抓取种子元信息,且对同一个种子元信息的多个抓取进行管理。在数据存储方面使用了python自带的sqlite,不用安装就能使用,很方便。数据库存储位置管理使用了appdirs库。
作者表示近期会有一次大的重构,让我们拭目以待。
论文
- Kademlia: A Peer-to-Peer Information System Based on the XOR Metric
- A Torrent Recommender based on DHT Crawling
- Real-World Sybil Attacks in BitTorrent Mainline DHT
- Measuring large-scale distributed systems: case of BitTorrent Mainline DHT
- Crawling BitTorrent DHTs for Fun and Profit
可用参考
- 如何通过infohash得到torrent种子文件?
- 种子文件 - Torrent file
- Torrent 文件格式详解
- B编码以及BT种子文件分析
- What exactly is the info_Hash in a torrent file
- Hash calculation in torrent clients
- BT服务器/tracker服务器 - BitTorrent tracker - Trackerless torrents
- 分布式散列表
- Kademlia算法
迅雷下载原理
Torrentz2
透视BT(一)── BT的基本运作原理
透视BT(二)──网路的频宽分享与BT的随机过程模型
透视BT(三)──数字会说话, BT有什么问题?
透視BT(四)──為什麼BT沒有內建搜尋功能?
P2P之Kademlia
网易云音乐电台 - BT软件(BitTorrent)的前生今世
Python开发的 dht网络爬虫
DHT 公网嗅探器实现(DHT 爬虫)
一步一步教你写BT种子嗅探器--DHT篇
其他
- http://torrage.com/
- SimpleXMLRPCServer
-
迅雷从磁力链接下载种子时的http请求
 请求,参数为大写的infohash
请求,参数为大写的infohash
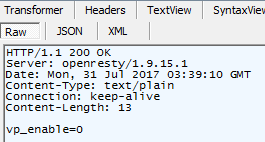 响应
响应