最近看到的一个关于Python爬虫的闯关游戏,手痒,试他一试。
第一关
地址:http://www.heibanke.com/lesson/crawler_ex00/
打开网址,首页是这样的
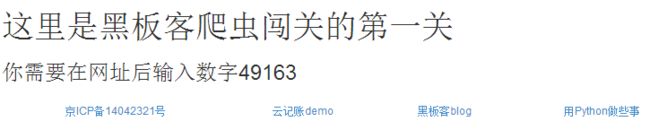 Paste_Image.png
Paste_Image.png
按要求修改地址为:http://www.heibanke.com/lesson/crawler_ex00/49163/ ,页面变化是这样的
 Paste_Image.png
Paste_Image.png
再次修改:http://www.heibanke.com/lesson/crawler_ex00/26470/
 Paste_Image.png
Paste_Image.png
看来,本关卡的目的是使用爬虫获取首页,然后提取进入下一页的关键数字,合成新的页面,如此往复循环,直到找到正确的地址为止。
思路已经有了,静态页面的分析就不说了,看代码
#-*- coding:utf-8 -*-
import requests
from lxml import etree
import re
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"
}
#获取页面
def getHtml(page):
url = 'http://www.heibanke.com/lesson/crawler_ex00/'+page
res = requests.get(url,headers=headers,timeout=30).text
#因为开始的时候不知道成功后的下一个页面地址在哪里,所以将每个页面的源代码都保存了下来,方便查看
# with open('game.html','w') as f:
# f.write(res)
return res
#如果需要继续输入数字,则正则匹配可以成功,
#如果不需要继续输入数字了,那么正则匹配之后会报错,所以报错的时候就是成功的时候
def main():
page = ''
print '开始第一关..'
while True:
try:
html = getHtml(page)
tree = etree.HTML(html)
h3 = tree.xpath('/html/body/div/div/div[2]/h3/text()')[0]
print h3
if u'恭喜' in h3:
n_url = tree.xpath('/html/body/div/div/div[2]/a/@href')[0]
next_url = 'http://www.heibanke.com'+n_url
print '下一关的地址为:%s'%next_url
page = re.findall('\d+',h3)[0]
except Exception,e:
print e
break
if __name__ == '__main__':
main()
运行结果
...........
恭喜你,你找到了答案.继续你的爬虫之旅吧
下一关的地址为:http://www.heibanke.com/lesson/crawler_ex01/
list index out of range
[Finished in 129.4s]
第二关
地址:http://www.heibanke.com/lesson/crawler_ex01/
这个地址有一点挺奇怪,偶尔出现一个现象:如果你是在闯关游戏的页面地址栏输入该地址,则可以链接到,但是如果你直接从其他页面链接过去,则无法打开,应该是做了Referer检测吧,但为什么是偶尔呢?想不通(逃...)
第二关的页面是这样的
 Paste_Image.png
Paste_Image.png
看来是要猜测30次数字了,但是数字是如何提交上去的呢?
随便输入一个值,直接成功的概率太小,主要是让它报错,然后来看请求
发现了这个
 Paste_Image.png
Paste_Image.png
源码中也可以看到csrf验证的值
 Paste_Image.png
Paste_Image.png
所以该请求是使用post方式传入三个字段的信息,验证失败则修改password再次验证,直到成功为止,故源码如下
#-*- coding:utf-8 -*-
import requests
from lxml import etree
import re
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"
}
def getcsrf():
url = 'http://www.heibanke.com/lesson/crawler_ex01/'
res = requests.get(url,headers=headers,timeout=30).text
tree = etree.HTML(res)
csrf = tree.xpath('/html/body/div/div/div[2]/form/input/@value')[0]
#csrf = re.findall('name="csrfmiddlewaretoken" value="(.*?)"',res)
print csrf
return csrf
#猜测密码
def guess(csrf,num):
url = 'http://www.heibanke.com/lesson/crawler_ex01/'
data = {
"csrfmiddlewaretoken":csrf,
"username":"whaike",
"password":str(num)
}
print data
res = requests.post(url,headers=headers,data=data,timeout=30).text
h3 = re.findall('(.*?)
',res)[0]
if not u'密码错误' in h3:
print h3
tree = etree.HTML(res)
n_url = tree.xpath('/html/body/div/div/div[2]/a/@href')[0]
next_url = 'http://www.heibanke.com'+n_url
print '下一关的地址为:%s'%next_url
return True
else:
return False
def main():
page = ''
print '开始第二关..'
csrf = getcsrf()
for n in range(31):
if guess(csrf,n):
break
if __name__ == '__main__':
main()
顺利拿到下一关地址!
第三关
地址:http://www.heibanke.com/lesson/crawler_ex02/
第三关首先需要输入用户名和密码,输入之后发现提示用户不存在,原来需要注册,在这里我用自己的账号注册了一个,登陆之后,就可以继续愉快的玩耍了
 Paste_Image.png
Paste_Image.png
看样子第三关首先需要模拟登陆
在这里我使用requests的session对象来保持会话。
分析网页源码,发现参数的提交使用的是一个form标签,其action参数为空,表示提交数据由本页负责,所以post会将参数提交到本页的地址。
因为登陆之后页面会重定向到其他页,所以使用浏览器自带的抓包工具去抓取请求参数并不友好,这里我使用fiddler进行抓包,在请求头中看到这样的字段
 Paste_Image.png
Paste_Image.png
所以模拟登陆的时候post传参有三个字段,思路已经清晰:
模拟登陆,使用session会话保持登陆状态并获取第三关的地址页源码,取得csrf,然后递增30以内的数字作为密码传递给服务器,当请求到的页面中不包含“您输入的密码错误, 请重新输入”这样的文字的时候,就是成功的时候了。
源码如下
#-*- coding:utf-8 -*-
import requests
from lxml import etree
import re
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
se = requests.session()
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"
}
class HBK():
def __init__(self):
self.login_url = "http://www.heibanke.com/accounts/login"
self.username = "whaike"
self.password = "12345654321"
def getCsrf(self):
res = se.get(url=self.login_url,headers=headers,timeout=30).text
tree = etree.HTML(res)
self.csrf = tree.xpath('/html/body/div/div/div[2]/form/input[@name="csrfmiddlewaretoken"]/@value')[0]
def login(self):
self.getCsrf()
data = {
"csrfmiddlewaretoken":self.csrf,
"username":self.username,
"password":self.password
}
se.post(url=self.login_url,headers=headers,data=data,timeout=30)
print u'登陆成功'
print '开始闯关 - 第三关'
spider = HBK()
spider.login()
url = 'http://www.heibanke.com/lesson/crawler_ex02/'
res = se.get(url,headers=headers,timeout=30).text
tree = etree.HTML(res)
#获取csrf
csrf = tree.xpath('/html/body/div/div/div[2]/form/input[@name="csrfmiddlewaretoken"]/@value')[0]
#猜测密码
def guess(num=1):
print 'guess',num
data = {
"csrfmiddlewaretoken":csrf,
"username":"whaike",
"password":str(num)
}
res = se.post(url,headers=headers,data=data,timeout=30).text
tree = etree.HTML(res)
h3 = tree.xpath('/html/body/div/div/div[2]/h3/text()')[0]
if not u'错误' in h3:
print '猜测到正确的密码为%d'%num
return num #如果没有发现错误两个字,则结束递归
else:
guess(num+1)
guess()
print 'success'
闯关成功之后发现下一关的地址还是原来的那个,崩溃
 Paste_Image.png
Paste_Image.png
不过观察第二关和第三关的地址发现就最后一个路径不一样,有递增的趋势,猜测第四关的地址为:http://www.heibanke.com/lesson/crawler_ex03/ ,果然如此
顺利进入第四关
 Paste_Image.png
Paste_Image.png
第四关
地址:http://www.heibanke.com/lesson/crawler_ex03/
第四关又是猜密码,还不知道是什么鬼,所以随便输一个看看有没有提示,果然
 Paste_Image.png
Paste_Image.png
去看看提示
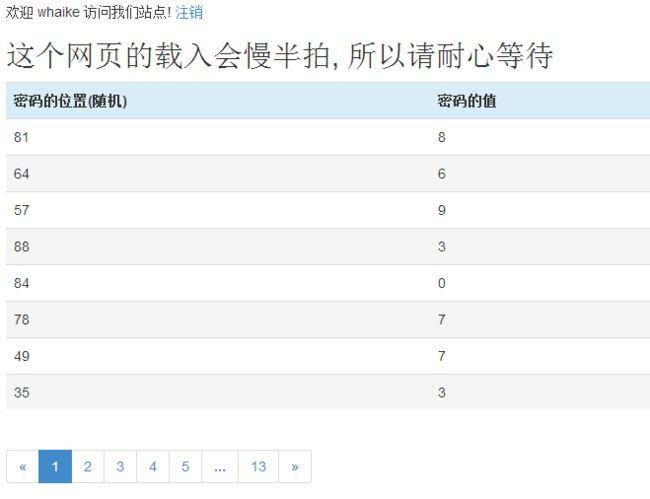 Paste_Image.png
Paste_Image.png
原来密码被拆分掉,分开显示在这里,位置和值一一对应。
首先想到将13页全部抓下来,然后按位置去一一对应,可惜这样失败了,13页的所有数据抓了几次,抓下来去重后组成的密码长度有70多位也有80多位的,去登陆也都失败了。没办法,在网上看到有人说密码位数是100位,我去,谁能想到,哪里来那么多数据。后来看到一个方法,既然每页的数据是随机的,那么只抓取第一页的数据,每抓取一次添加到固定长度的密码位,方法可行。
所以思路是:
模拟登陆,初始化一个长度为100的数组用来存放密码,获取第一页的全部位置和值,将它们的值更新到数组的正确位置,合并数组中的值组成一个字符串,判断字符串长度,如果小于100则继续抓取第一页的数据并跟新到数组,直到数组长度满足100,将数组中的值转换为字符串通过post提交到服务器进行判断,如果不成功则继续更新数组中的值,如果成功则打印消息并退出。
具体代码如下
#-*- coding:utf-8 -*-
#单线程版
import requests
from lxml import etree
import codecs
import csv
import re
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
se = requests.session()
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"
}
class HBK():
def __init__(self):
self.login_url = "http://www.heibanke.com/accounts/login"
self.username = "whaike"
self.password = "12345654321"
self.passwrods = ['' for i in range(101)]
self.pwd = ''
##获取登陆之前的csrf
def getCsrf(self):
res = se.get(url=self.login_url,headers=headers,timeout=30).text
tree = etree.HTML(res)
self.csrf = tree.xpath('/html/body/div/div/div[2]/form/input[@name="csrfmiddlewaretoken"]/@value')[0]
#登陆
def login(self):
self.getCsrf()
data = {
"csrfmiddlewaretoken":self.csrf,
"username":self.username,
"password":self.password
}
se.post(url=self.login_url,headers=headers,data=data,timeout=30)
print u'登陆成功'
#获取登陆之后的csrf,也就是要进行第四关闯关的csrf
def getNCsrf(self):
url = 'http://www.heibanke.com/lesson/crawler_ex03/'
res = se.get(url,headers=headers,timeout=30).text
tree = etree.HTML(res)
csrf = tree.xpath('//input[1]/@value')[0]
return csrf
#猜测密码是否正确
def guesspwd(self):
url = 'http://www.heibanke.com/lesson/crawler_ex03/'
csrf = self.getNCsrf()
data = {
"csrfmiddlewaretoken":csrf,
"username":"whaike",
"password":self.pwd
}
res = se.post(url,headers=headers,data=data,timeout=30)
if int(res.status_code) == 200:
self.h3 = re.findall('(.*?)
',res.text)
return True
else:
return False
#循环抓取第一页的随机值,直到密码长度为100时开始猜测,猜测失败继续执行,猜测成功停止运行
def getGasswords(self):
print '获取第一页'
url = 'http://www.heibanke.com/lesson/crawler_ex03/pw_list/?page=1'
res = se.get(url,headers=headers,timeout=30).text
tree = etree.HTML(res)
trs = tree.xpath('/html/body/div/div/div[2]/table/tr')[1:]
for tr in trs:
p1 = tr.xpath('td[1]/text()')[0] #位置
p = int(re.findall('\d+',p1)[0]) #偶尔数字前会有一些其他字符出现,提取数字部分,转换为整数
w = tr.xpath('td[2]/text()')[0] #值
self.passwrods[p] = w
self.pwd = ''.join(self.passwrods)
length = len(self.pwd) #密码长度
print '当前密码:%s,长度%d'%(self.pwd,length)
if length == 100:
print '满足条件,开始猜测...'
if self.guesspwd():
print '猜测成功,密码为:%s'%self.pwd
else:
print '猜测失败,继续执行'
self.getGasswords()
else: #如果密码长度不为100,则再次获取第一页的随机密码并组成新的密码
self.getGasswords() #递归
print '开始闯关 - 第四关'
spider = HBK()
spider.login()
spider.getGasswords()
print spider.h3
这里还有个坑,网页的反应很慢,每次请求都需要很长时间才能得到数据,所以理想的情况是使用多线程去做,但是我这里使用的是单线程。所以时间会比较长。
运行记录
.............
当前密码:4895069524432954894613647990394874326048437134877661813696344916326470648993670283105253381901613579,长度100
满足条件,开始猜测...
猜测成功,密码为:4895069524432954894613647990394874326048437134877661813696344916326470648993670283105253381901613579
[u'\u606d\u559c! \u7528\u6237whaike\u6210\u529f\u95ef\u5173, \u7ee7\u7eed\u4f60\u7684\u722c\u866b\u4e4b\u65c5\u5427']
[Finished in 795.7s]
最后一个打印h3的时候忘记添加索引了,导致打印了一个数组(尴尬脸...),懒得改了
第五关地址依然靠猜吧
第五关
地址:http://www.heibanke.com/lesson/crawler_ex04/
进入第五关,看到了这样的界面
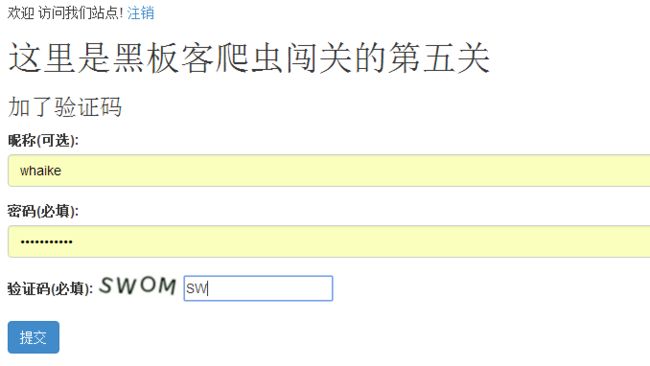 Paste_Image.png
Paste_Image.png
通过前几关的经验,可以分析出这次的请求依然是猜密码,只不过增加了验证码识别。
请求的字段为5个:一个是csrf验证,一个在验证码的img标签之后与csrf以相同的方式隐藏value,其实也是验证码src的最后一个路径,还有一个是验证码识别出来的字符,另外两个是用户名和密码。
 Paste_Image.png
Paste_Image.png
在这里,我使用开源的OCR库Tesseract(地址:https://github.com/tesseract-ocr/tesseract/wiki) 来进行验证码识别。
在windows上使用只需百度搜索下载并安装tesseract-ocr-setup-3.02.02.exe文件即可,注意,目前良好支持windows的版本只有3.02。
安装完成之后,可以在命令行键入tesseract myscan.png out -l eng来识别当前目录下的myscan.png文件并将结果输出到out.txt中。
在Python中本来使用os模块可以执行命令行,但是这样的命令行过于简单,无法完成复杂的输入和输出,我们可以使用subprocess.Popen来解决这个问题。
所以思路是这样的:
模拟登录,获取csrf和验证码隐藏的value以及下载验证码图片到本地,识别验证码,识别成功则从密码0开始递增猜测,每一次猜测都要获取新的验证码,如果识别验证码失败则重新获取验证码直到识别成功才继续猜测,如果猜测密码时提示输入的验证码不正确,则重新获取验证码并且重新猜测该值,直到成功为止。
相关代码如下
#-*- coding:utf-8 -*-
import requests
from lxml import etree
import datetime,time
import re
import os
import subprocess
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
se = requests.session()
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"
}
#log日志
def loggs(strs):
with open('logs.log','ab') as f:
time = str(datetime.datetime.now())[:-7]
t = os.linesep
s = time+' : '+strs
print s
f.write(s+t)
class HBK():
def __init__(self):
self.login_url = "http://www.heibanke.com/accounts/login"
self.chapter_url = 'http://www.heibanke.com/lesson/crawler_ex04/'
self.username = "whaike"
self.password = "12345654321"
#获取登陆之前的csrf
def getCsrf(self):
res = se.get(url=self.login_url,headers=headers,timeout=30).text
tree = etree.HTML(res)
self.csrf = tree.xpath('/html/body/div/div/div[2]/form/input[@name="csrfmiddlewaretoken"]/@value')[0]
#登陆
def login(self):
self.getCsrf()
data = {
"csrfmiddlewaretoken":self.csrf,
"username":self.username,
"password":self.password
}
se.post(url=self.login_url,headers=headers,data=data,timeout=30)
loggs('登陆成功')
#识别验证码,识别当前目录下的capt.png图片
def get_captcha(self):
p = subprocess.Popen(['tesseract','capt.png','captcha'])
p.wait()
with open('captcha.txt','r') as f:
data = f.read()
s= data.strip()
return s
#保存图片
def saveImg(self,url):
res = se.get(url,headers=headers,timeout=30)
if res.status_code == 200:
with open('capt.png','wb') as f:
f.write(res.content)
#获取第五关的页面,得到csrf和验证码图片
def getinfos(self):
res = se.get(url=self.chapter_url,headers=headers,timeout=30).text
tree = etree.HTML(res)
self.f_csrf = tree.xpath('/html/body/div/div/div[2]/form/input[@name="csrfmiddlewaretoken"]/@value')[0]
img_src = tree.xpath('/html/body/div/div/div[2]/form/div[3]/img/@src')[0]
img_url = 'http://www.heibanke.com'+img_src
self.saveImg(img_url)
self.img_name = tree.xpath('//*[@id="id_captcha_0"]/@value')[0]
try:
yzm = self.get_captcha()
except Exception,e:
yzm = ''
loggs('验证码识别失败')
if re.match('^[A-Z|0-9]{3,6}$',yzm,re.I):
loggs('识别出验证码:%s'%yzm)
self.yzm = yzm
else:
loggs('验证码识别错误%s,重新获取'%yzm)
self.getinfos()
#return (self.f_csrf,img_url,self.yzm)
#猜数字
def guessNum(self,num=0):
self.getinfos()
loggs('guess number %d'%num)
data = {
"csrfmiddlewaretoken":self.f_csrf,
"username":self.username,
"password":str(num),
"captcha_0":self.img_name,
"captcha_1":self.yzm
}
loggs(str(data))
res = se.post(url=self.chapter_url,headers=headers,data=data,timeout=30)
if res.status_code == 200:
h3 = re.findall('(.*?)
',res.text)
h3 = h3[0]
loggs(h3)
if u'恭喜' in h3: #如果成功则打印h3,如果失败则继续猜测
loggs('验证成功!')
loggs(h3)
elif u'验证码输入错误' in h3:
loggs('再次请求%s'%res.status_code)
self.guessNum(num)
else:
loggs('验证失败,继续猜测')
self.guessNum(num+1)
else:
loggs('请求失败%s,再次请求'%res.status_code)
self.guessNum(num)
loggs('开始闯关 - 第五关')
spider = HBK()
spider.login()
spider.guessNum()
注意:存放py文件的路径不能有中文。
运行结果如下
.........
Tesseract Open Source OCR Engine v3.02 with Leptonica
2017-06-07 15:30:36 : 识别出验证码:MPPO
2017-06-07 15:30:36 : guess number 20
2017-06-07 15:30:36 : {'username': 'whaike', 'csrfmiddlewaretoken': 'maXozqF1efyoirhMz41RzhmWCUVc8tYq', 'password': '20', 'captcha_0': 'cd7254fedd008d5e434980de86447c2187e240ac', 'captcha_1': 'MPPO'}
2017-06-07 15:30:37 : 恭喜! 用户whaike成功闯关, 后续关卡敬请期待
2017-06-07 15:30:37 : 验证成功!
2017-06-07 15:30:37 : 恭喜! 用户whaike成功闯关, 后续关卡敬请期待
[Finished in 372.4s]
这里不同的时间其密码也可能不同,比如我第二次识别的时候答案为1那么很快就成功了。
...........
Tesseract Open Source OCR Engine v3.02 with Leptonica
2017-06-07 23:00:22 : 识别出验证码:ARCN
2017-06-07 23:00:22 : guess number 1
2017-06-07 23:00:22 : {'username': 'whaike', 'csrfmiddlewaretoken': 'K4eUEZpJ5siJ26f2B9zFue0WsVDZKwna', 'password': '1', 'captcha_0': 'cae8539c36fdcd39f3eab44469e9c066670a1539', 'captcha_1': 'ARCN'}
2017-06-07 23:00:23 : 恭喜! 用户whaike成功闯关, 后续关卡敬请期待
2017-06-07 23:00:23 : 验证成功!
2017-06-07 23:00:23 : 恭喜! 用户whaike成功闯关, 后续关卡敬请期待
[Finished in 19.5s]
关键在过程!
 Paste_Image.png
Paste_Image.png
在这里,感谢黑板客提供的好玩儿的爬虫游戏。