开头:忘了tensorflow 1吧,都过去了
pip install tensorflow==2.0.0-alpha
生态系统
TensorFlow 2.0
@tf.function转换成计算图
tf.function解读TensorFlow Lite
TensorFlow.JS
TensorFlow Extended
TensorFlow Prob
TPU Cloud
1. 数据类型
数据载体
list支持不同的数据类型,效率低
np.array相同类型的载体,效率高,但是不支持GPU,不支持自动求导
tf.Tensortensorflow中存储大量连续数据的载体
基本数据类型
tf.int32: tf.constant(1)
tf.float32: tf.constant(1.)
tf.float64: tf.constant(1., dtype=tf.double)
tf.bool: tf.constant([True, False])
tf.string: tf.constant('hello')
数据基本属性
with tf.device("cpu"):
a=tf.range(4)
a.device # '/job:localhost/replica:0/task:0/device:CPU:0'
aa=a.gpu()
a.numpy() # array([0, 1, 2, 3], dtype=int32)
a.ndim # 1 (0的话就是标量)
a.shape # TensorShape([4])
a.name # AttributeError: Tensor.name is meaningless when eager execution is enabled.
tf.rank(tf.ones([3,4,2])) #
tf.is_tensor(a) # True
a.dtype # tf.int32
- rank和ndim的区别在于返回的类型不同
- name属性在tensorflow2没有意义,因为变量名本身就是name
数据类型转换
a=np.arange(5)
a.dtype # dtype('int64')
aa=tf.convert_to_tensor(a) #
aa=tf.convert_to_tensor(a, dtype=tf.int32) #
tf.cast(aa, tf.float32)
b=tf.constant([0,1])
tf.cast(b, tf.bool) #
a.tf.ones([])
a.numpy()
int(a) #标量可以直接这样类型转换
float(a)
可训练数据类型
a=tf.range(5)
b=tf.Variable(a)
b.dtype # tf.int32
b.name # 'Variable:0' 其实没啥用
b.trainable #True
2. 创建Tensor
tf.convert_to_tensor(data)
tf.zeros(shape)
tf.ones(1)生成一个一维tensor,包含一个1
tf.ones([])生成一个标量1
tf.ones([2])生成一个一维tensor,包含两个1
tf.ones_like(a)相当于tf.ones(a.shape)
tf.fill([3,4], 9) 全部填充9
tf.random.normal([3,4], mean=1, stddev=1)
tf.random.truncated_normal([3,4], mean=0, stddev=1) 带截断的正态分布,(大于某个值重新采样),比如在经过sigmoid激活后,如果用不带截断的,容易出现梯度消失问题。
tf.random.uniform([3,4], minval=0, maxval=100, dtype=tf.int32) 平均分布
idx=tf.range(5)
idx=tf.random.shuffle(idx)
a=tf.random.normal([10,784])
b=tf.random.uniform([10])
a=tf.gather(a, idx) # a中随机取5行
b=tf.gather(b, idx) # b中随机取5个
-
三维tensor举例
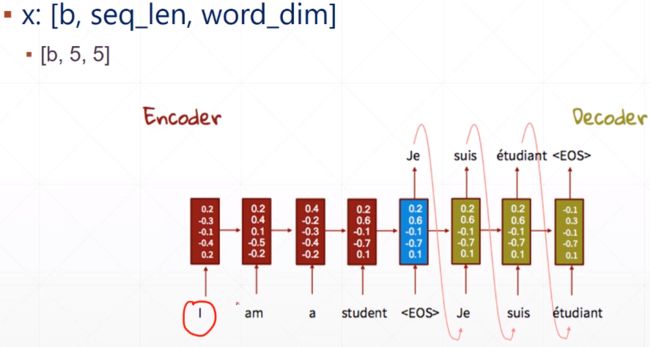 自然语言处理,b个句子,每个句子有5个单词,每个单词由5维向量表示
自然语言处理,b个句子,每个句子有5个单词,每个单词由5维向量表示 - 四维tensor:图像
[b, h, w, c] - 五维tensor:meta-learning
[task_b, b, h, w, c](多任务)
以下是自由活动时间
out=tf.random.uniform([4,10]) # 模拟4张图片的输出,每个输出对应10个分类
y=tf.range(4)
y=tf.one_hot(y, depth=10) # 模拟4张图片的真实分类
loss=tf.keras.losses.mse(y, out)
loss=tf.reduce_mean(loss) # 计算loss
一个简单的x@w+b
from tensorflow.keras import layers
net=layers.Dense(10)
net.build((4,8)) # 4 是batch_size, 前一层有8个units
net.kernel #w shape=(8, 10)
net.bias #b shape=(10, )
记住:W的维度是[input_dim, output_dim], b的维度是[output_dim, ]
自由活动结束
3. Tensor操作
3.1 索引
基本:a[idx][idx][idx]
numpy风格:a[idx,idx,idx]可读性更强
3.2 切片
与numpy基本一致
a[start:end:positive_step]
a[end:start:negative_step]
a[0, 1, ..., 0] 代表任意多个: 只要能推断出有多少个:就是合法的
selective indexing
tf.gather
场景:对[4, 28, 28, 3]Tensor的第[3, 27, 9 ,13]行(也就是第一个28)顺序采样
使用:tf.gather(a, axis=1, indices=[3,27,9,13])-
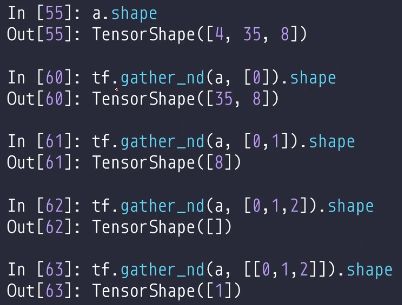
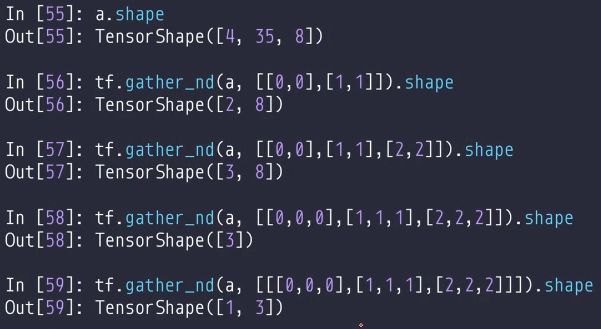
tf.gather_ndW3Cschool解释
场景:对[4, 28, 28, 3]Tensor第二维的[3, 27]和第三维的[20,8]进行采样
使用:tf.gather_nd(a, indices=[[:,3,20,:],[:,3,8,:],[:,27,20,:],[:,27,8,:]])
 更多实例
更多实例
-
tf.boolean_mask
tf.boolean_mask(a, mask=[True, True, False], axis=3)相当于只取RG两个通道的数据,a的shape是[4, 28, 28, 3]。mask可以是一个list,作用有点像tf.gather_nd
3.3 维度变换
-
a.shape,a.ndim -
tf.transpose比如交换图像的行列,也就是旋转90°
a=tf.random.normal([4, 3, 2, 1])
tf.transpose(a, perm=[0, 1, 3, 2])相当于交换最后两维
tf.reshape
a=tf.random.normal([4, 28, 28, 3])
tf.reshape(a, [4, 784, 3])
tf.reshape(a, [4, -1, 3]) #效果和上面一样
tf.reshape(a, [4, -1])
-
tf.expand_dims增加维度(dim和axis含义类似)
a=tf.random.normal([4, 35, 8])
tf.expand_dims(a, axis=3) # 增加的维度是第4(3+1)维 shape是[4, 35, 8, 1]
-
tf.squeeze维度压缩,默认去掉所有长度是1的维度,也可以通过axis指定某一个维度
3.4 Broadcasting
-
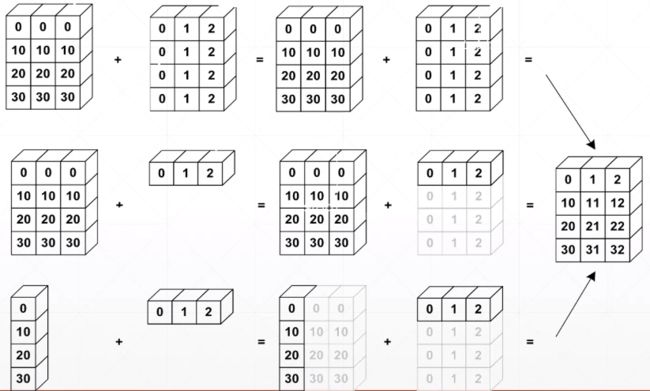
Tensor运算的时候首先右对齐,插入维度,并将长度是1的维度扩张成相应的长度
 图示
图示 - 场景:一般情况下,高维度比低维度的概念更高层,如
[班级,学生,成绩],利用broadcasting把小维度推广到大维度。 - 作用:简洁、节省内存
tf.broadcast_to(a, [2,3,4])
3.5 合并与分割
-
tf.concat([a, b], axis=0)在原来的维度上累加,要求其他维度的长度都相等。比如[4,35,8] concat [2,35,8] => [6,35,8] -
tf.stack([a, b], axis=0)在0维度处创建一个维度,长度为2 (因为这里只有a,b两个),要求所有维度的长度都相等 -
res=tf.unstack(c, axis=3)c的第3维上打散成多个张量,数量是这个维度的长度 -
tf.split(c, axis=3, num_or_size_splits=[2,3,2]比unstack更灵活
3.6 数据统计
tf.norm(a) 求a的范数,默认是二范数
tf.norm(a, ord=1, axis=1) 第一维看成一个整体,求一范数
tf.reduce_min reduce是为了提醒我们这些操作会降维
tf.reduce_max
tf.reduce_mean
tf.argmax(a) 默认返回axis=0上最大值的下标
tf.argmin(a)
tf.equak(a,b) 逐元素比较
tf.reduce_sum(tf.cast(tf.equal(a,b), dtype=tf.int32) 相当于统计相同元素的个数
tf.unique(a)返回一个数组和一个idx数组(用于反向生成a)
3.7 排序
tf.sort(a, direction='DESCENDING' 对最后一个维度进行排序
tf.argsort(a) 得到升序排列后元素在原数组中的下标
tf.gather(a, tf.argsort(a))
res=tf.math.top_k(a,2) res.indices res.value 用于topK accuracy
3.8 填充与复制
-
tf.pad(a, [[1,1],[1,1], ...])每一维上前后填充的数量
a=tf.random.normal([4,28,28,3])
b=tf.pad(a, [[0, 0], [2, 2], [2, 2], [0, 0]]) # 图片四周各填充两个像素
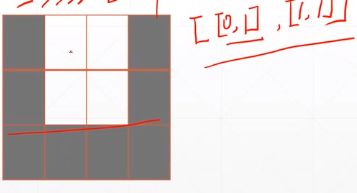
-
tf.tile(a, [ ])后面的参数指定每个维度复制的次数,1表示保持不变,2表示复制一次
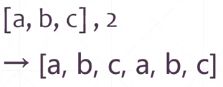
3.9 张量限幅
tf.maximum(a, 2)每个元素都会大于2, 简单的relu实现就用这个tf.minimum(a, 8)tf.clip_by_value(a, 2, 8)new_grads, total_norm = tf.clip_by_globel_norm(grads, 15)等比例放缩,不改变数据的分布,不影响梯度方向,可用于梯度消失,梯度爆炸
3.10 其他高级操作
indices=tf.where(a>0)返回所有为True的坐标,配合tf.gather_nd(a, indices)使用tf.where(cond, A, B)根据cond,从A,B中挑选元素-
tf.scatter_nd(indices, updates, shape)
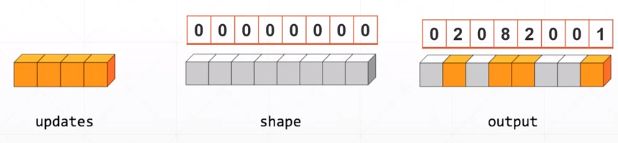 根据indics,把updates中的元素填充到shape大小的全零tensor中
根据indics,把updates中的元素填充到shape大小的全零tensor中 points_x, points_y = tf.meshgrid(x, y)
points=tf.stack([points_x, points_y], axis=2
低层级方法实战MNIST
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets, layers, optimizers
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
def preprocess(x, y):
# [b, 28, 28], [b]
x = tf.cast(x, dtype=tf.float32) / 255.
x = tf.reshape(x, [-1, 28*28])
y = tf.cast(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10)
return x,y
(x, y), (x_test, y_test) = datasets.mnist.load_data()
print('x:', x.shape, 'y:', y.shape, 'x test:', x_test.shape, 'y test:', y_test)
train_db = tf.data.Dataset.from_tensor_slices((x, y))
train_db = train_db.shuffle(60000).batch(128).map(preprocess).repeat(30)
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_db = test_db.shuffle(10000).batch(128).map(preprocess)
x,y = next(iter(train_db))
print('train sample:', x.shape, y.shape)
# print(x[0], y[0])
def main():
# learning rate
lr = 1e-3
# 784 => 512
w1, b1 = tf.Variable(tf.random.truncated_normal([784, 512], stddev=0.1)), tf.Variable(tf.zeros([512])) # 梯度只会跟踪tf.Variable类型的变量
'''
如果不用tf.Variable, 在with tf.GradientTape() as tape: 中需要调用tape.watch(w),否则不会计算梯度
'''
# 512 => 256
w2, b2 = tf.Variable(tf.random.truncated_normal([512, 256], stddev=0.1)), tf.Variable(tf.zeros([256]))
# 256 => 10
w3, b3 = tf.Variable(tf.random.truncated_normal([256, 10], stddev=0.1)), tf.Variable(tf.zeros([10])) # stddev在这里解决了梯度爆炸的问题
for step, (x,y) in enumerate(train_db):
# [b, 28, 28] => [b, 784]
x = tf.reshape(x, (-1, 784))
with tf.GradientTape() as tape:
# layer1.
h1 = x @ w1 + b1
h1 = tf.nn.relu(h1)
# layer2
h2 = h1 @ w2 + b2
h2 = tf.nn.relu(h2)
# output
out = h2 @ w3 + b3
# out = tf.nn.relu(out)
# compute loss
# [b, 10] - [b, 10]
loss = tf.square(y-out)
# [b, 10] => [b]
loss = tf.reduce_mean(loss, axis=1)
# [b] => scalar
loss = tf.reduce_mean(loss)
# compute gradient
grads = tape.gradient(loss, [w1, b1, w2, b2, w3, b3])
# for g in grads:
# print(tf.norm(g))
# update w' = w - lr*grad
for p, g in zip([w1, b1, w2, b2, w3, b3], grads):
p.assign_sub(lr * g) # assign_sub 原地更新, 不会改变变量类型
if step % 100 == 0:
print(step, 'loss:', float(loss))
# evaluate
if step % 500 == 0:
total, total_correct = 0., 0
for step, (x, y) in enumerate(test_db):
# layer1.
h1 = x @ w1 + b1
h1 = tf.nn.relu(h1)
# layer2
h2 = h1 @ w2 + b2
h2 = tf.nn.relu(h2)
# output
out = h2 @ w3 + b3
# [b, 10] => [b]
pred = tf.argmax(out, axis=1)
# convert one_hot y to number y
y = tf.argmax(y, axis=1)
# bool type
correct = tf.equal(pred, y)
# bool tensor => int tensor => numpy
total_correct += tf.reduce_sum(tf.cast(correct, dtype=tf.int32)).numpy()
total += x.shape[0]
print(step, 'Evaluate Acc:', total_correct/total)
4. 神经网络与全连接
4.1 数据加载
keras.datasets
(x, y), (x_test, y_test) = keras.datasets.mnist.load_data() => numpy数组
y_onehot = tf.one_hot(y, depth=10)
(x, y), (x_test, y_test) = keras.datasets.cifar10.load_data()
tf.data.Dataset.from_tensor_slices
db=tf.data.Dataset.from_tensor_slices((x, y)).batch(16).repeat(2) # 相当于数据翻了倍
itr = iter(db)
for i in range(10):
print(next(itr)[0][15][16,16,0]) # batch中最后一张图中的一个像素
db=db.shuffle(10000)
4.2 全连接层
net=tf.keras.layers.Dense(units)
net.build(input_shape=(None, 784))根据输入shape创建net的所有变量w,b
net(x)#x是真正的输入model = keras.Sequetial([keras,layers.Dense(2, activation='relu'), [keras,layers.Dense(4, activation='relu') ])model.summary()打印网络信息
4.3 输出方式
-
tf.sigmoid保证输出在[0,1]中 -
prob=tf.nn.softmax(logits)保证所有输出之和=1,logits一般指没有激活函数的最后一层的输出 -
tf.tanh输出在[-1, 1]之间
4.4 误差计算
- MSE
tf.reduce_mean(tf.losses.MSE(y, out)) - 交叉熵
-log(q_i)
tf.losses.categorical_crossentropy(y, logits, from_logits=True)大多数情况下,使用from_logits参数,从而不用手动添加softmax
tf.losses.binary_crossentropy(x, y)
5. 梯度下降、损失函数
导数 => 偏微分 某个坐标方向的导数=> 梯度所有坐标方向导数的集合
5.1 自动求梯度
with tf.GradientTape() as tape:
loss= ...
[w_grad] = tape.gradiet(loss, [w]) # w是指定要求梯度的参数
with tf.GradientTape(persistent=True) as tape: 使得tape.gradient可被多次调用
求二阶导
with tf.GradientTape() as t1:
with tf.GradientTape() as t2:
y = x * w + b
dy_dw, dy_db = t2.gradient(y, [w, b])
d2y_dw2 = t1.gradient(dy_dw, w)
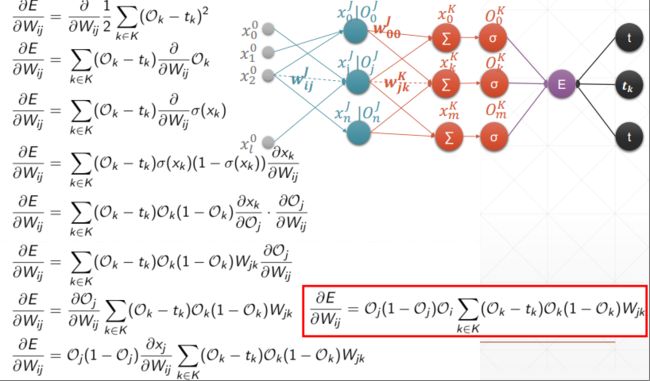
5.2 反向传播
单输出感知机
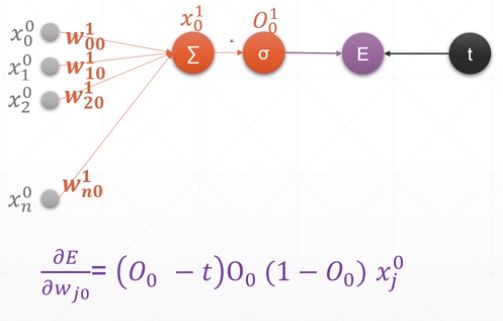
x=tf.random.normal([1,3])
w=tf.ones([3,1])
b=tf.ones([1])
y = tf.constant([1])
with tf.GradientTape() as tape:
tape.watch([w, b])
logits = tf.sigmoid(x@w+b)
loss = tf.reduce_mean(tf.losses.MSE(y, logits))
grads = tape.gradient(loss, [w, b])
print('w grad:', grads[0])
print('b grad:', grads[1])
多输出感知机

x=tf.random.normal([1,3])
w=tf.ones([3,2])
b=tf.ones([2])
y = tf.constant([0, 1])
with tf.GradientTape() as tape:
tape.watch([w, b])
logits = tf.sigmoid(x@w+b)
loss = tf.reduce_mean(tf.losses.MSE(y, logits))
grads = tape.gradient(loss, [w, b])
print('w grad:', grads[0])
print('b grad:', grads[1])
5.3 链式法则
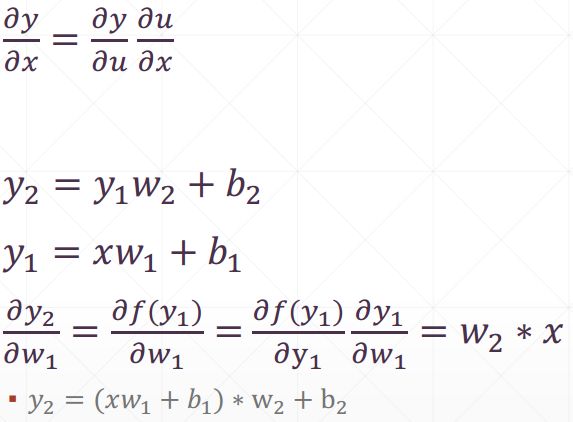
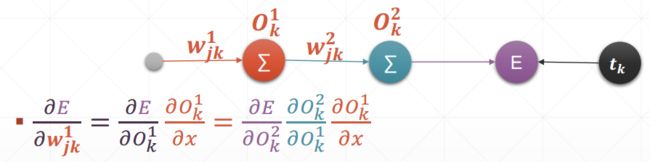
多层感知机
损失函数优化实战
假设损失函数:
import numpy as np
from matplotlib import pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
def loss(x):
return (x[0] ** 2 + x[1] - 11) ** 2 + (x[0] + x[1] ** 2 - 7) ** 2
x = np.arange(-6, 6, 0.1)
y = np.arange(-6, 6, 0.1)
X, Y = np.meshgrid(x, y)
Z = loss([X, Y])
fig = plt.figure('loss')
ax = fig.gca(projection='3d')
ax.plot_surface(X, Y, Z)
ax.view_init(45, -60)
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()

import tensorflow as tf
x = tf.constant([0., 0.])
for step in range(200):
with tf.GradientTape() as tape:
tape.watch([x])
y = loss(x)
grads = tape.gradient(y, [x])[0] # y 对 x求导
x -= 0.01*grads
if step % 20 == 0:
print ('step {}: x = {}, f(x) = {}'
.format(step, x.numpy(), y.numpy()))
Fashion MNIST Dense 实战
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
def preprocess(x, y):
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32)
return x,y
(x, y), (x_test, y_test) = datasets.fashion_mnist.load_data()
batchsz = 128
db = tf.data.Dataset.from_tensor_slices((x,y))
db = db.map(preprocess).shuffle(10000).batch(batchsz)
db_test = tf.data.Dataset.from_tensor_slices((x_test,y_test))
db_test = db_test.map(preprocess).batch(batchsz)
model = Sequential([
layers.Dense(256, activation=tf.nn.relu), # [b, 784] => [b, 256]
layers.Dense(128, activation=tf.nn.relu), # [b, 256] => [b, 128]
layers.Dense(64, activation=tf.nn.relu), # [b, 128] => [b, 64]
layers.Dense(32, activation=tf.nn.relu), # [b, 64] => [b, 32]
layers.Dense(10) # [b, 32] => [b, 10], 330 = 32*10 + 10
])
model.build(input_shape=[None, 28*28])
model.summary()
# w = w - lr*grad
optimizer = optimizers.Adam(lr=1e-3)
def main():
for epoch in range(30):
for step, (x,y) in enumerate(db):
# x: [b, 28, 28] => [b, 784]
# y: [b]
x = tf.reshape(x, [-1, 28*28])
with tf.GradientTape() as tape:
# [b, 784] => [b, 10]
logits = model(x)
y_onehot = tf.one_hot(y, depth=10)
# [b]
loss_mse = tf.reduce_mean(tf.losses.MSE(y_onehot, logits))
loss_ce = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True)
loss_ce = tf.reduce_mean(loss_ce)
grads = tape.gradient(loss_ce, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 100 == 0:
print(epoch, step, 'loss:', float(loss_ce), float(loss_mse))
# test
total_correct = 0
total_num = 0
for x,y in db_test:
# x: [b, 28, 28] => [b, 784]
# y: [b]
x = tf.reshape(x, [-1, 28*28])
# [b, 10]
logits = model(x)
# logits => prob, [b, 10]
prob = tf.nn.softmax(logits, axis=1)
# [b, 10] => [b], int64
pred = tf.argmax(prob, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
# pred:[b]
# y: [b]
# correct: [b], True: equal, False: not equal
correct = tf.equal(pred, y)
correct = tf.reduce_sum(tf.cast(correct, dtype=tf.int32))
total_correct += int(correct)
total_num += x.shape[0]
acc = total_correct / total_num
print(epoch, 'test acc:', acc)
6. Tensorboard 可视化
tensorboad --logdir logs
current_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
log_dir = 'logs/' + current_time
summary_writer = tf.summary.create_file_writer(log_dir)
if step % 100 == 0:
print(step, 'loss:', float(loss))
with summary_writer.as_default():
tf.summary.scalar('train-loss', float(loss), step=step)
...
with summary_writer.as_default():
tf.summary.scalar('test-acc', float(total_correct/total), step=step)
tf.summary.image("val-onebyone-images:", val_images, max_outputs=25, step=step)
val_images = tf.reshape(val_images, [-1, 28, 28])
figure = image_grid(val_images)
tf.summary.image('val-images:', plot_to_image(figure), step=step)

7. Keras 高层接口
datasets
layers
losses
metrics
optimizers
7.1 Metrics
acc_metric =metrics.Accuracy()
acc_metric.update_state(y, pred)
acc_metric.result().numpy() # result() 返回的是tensor
acc_metric.reset_states()
7.2 常规工作流
compile fit evaluate predict
network.compile(optimizer=..., loss=..., metrics=[...])
network.fit(data, epochs=..., validation_data=...)
network.evaluate(x, y)
network.predict(x)
7.3 自定义网络
keras.Sequential是keras.Model的子类
net=Sequential([Layer])
net.build(input_shape=(...))=net(x)
model.trainable_variables
model.call()自定义model的时候需要实现这个方法来实现正向传播的逻辑,从而支持model(x)的写法,背后逻辑是调用了model.__call__(x),然后再调用model.call()keras.layers.Layerkeras.Model
继承之后实现:__init__、call
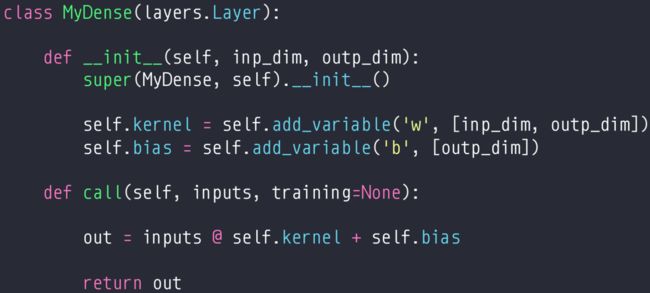
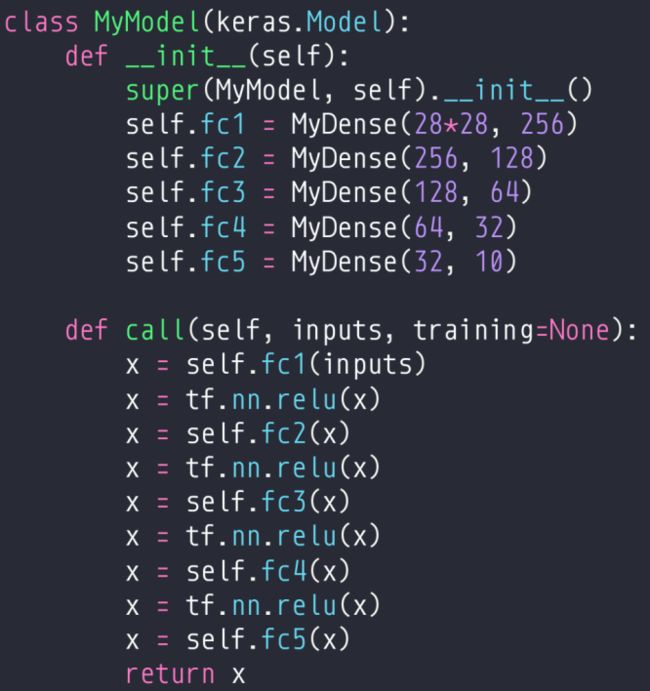
7.4 模型保存与加载
-
save/load weights轻量级的
model.save_weights('path')(.ckpt)
model=create_model()=>model.load_weights('path') -
save/load entire model暴力保存
model.save('xx.h5')
model=tf.keras.models.load_model('xx.h5') -
saved_model生产环境通用格式
tf.saved_model.save(model, 'path')
imported=tf.saved_model.load('path')
CIFAR10 自定义网络实战
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
def preprocess(x, y):
x=tf.cast(x, dtype=tf.float32)/255.
y=tf.squeeze(y) # y的原始shape是(5000,1) 第二维是多余的
y=tf.one_hot(y, depth=10)
y=tf.cast(y, dtype=tf.int32)
return x, y
batch_size=128
(x, y), (x_val, y_val)=datasets.cifar10.load_data()
train_db=tf.data.Dataset.from_tensor_slices((x,y))
train_db=train_db.map(preprocess).shuffle(10000).batch(batch_size)
val_db=tf.data.Dataset.from_tensor_slices((x_val,y_val))
val_db=val_db.map(preprocess).shuffle(10000).batch(batch_size)
class MyDense(layers.Layer):
def __init__(self, in_dim, out_dim):
super(MyDense, self).__init__()
self.kernel=self.add_variable('w', [in_dim, out_dim])
def call(self, inputs, training=None):
[email protected]
return x
class MyNet(keras.Model):
def __init__(self):
super(MyNet, self).__init__()
self.fc1=MyDense(32*32*3, 256)
self.fc2=MyDense(256,128)
self.fc3=MyDense(128,64)
self.fc4=MyDense(64,32)
self.fc5=MyDense(32,10)
def call(self, inputs, training=None):
x=tf.reshape(inputs, [-1, 32*32*3])
x=self.fc1(x)
x=tf.nn.relu(x)
x=self.fc2(x)
x=tf.nn.relu(x)
x=self.fc3(x)
x=tf.nn.relu(x)
x=self.fc4(x)
x=tf.nn.relu(x)
x=self.fc5(x)
return x
model = MyNet()
model.compile(
optimizer=optimizers.Adam(),
loss=tf.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
model.fit(train_db, epochs=10, validation_data=val_db)
8. 卷积神经网络
概念就不覆盖了,只关注API
keras.layers.Conv2D() 类的实现
padding='same' #输入输出的h w相同
tf.nn.conv2d 功能的实现

keras.layers.MaxPool2D
keras.layers.UpSampling2D
layers.ReLU
Cifar100 VGG13实战

import tensorflow as tf
from tensorflow.keras import layers, optimizers, datasets, Sequential
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
tf.random.set_seed(2019)
conv_layer=[
layers.Conv2D(64, kernel_size=(3,3), padding='same', activation=tf.nn.relu),
layers.Conv2D(64, kernel_size=(3,3), padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=(2,2), strides=2, padding='same'),
layers.Conv2D(128, kernel_size=(3,3), padding='same', activation=tf.nn.relu),
layers.Conv2D(128, kernel_size=(3,3), padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=(2,2), strides=2, padding='same'),
layers.Conv2D(256, kernel_size=(3,3), padding='same', activation=tf.nn.relu),
layers.Conv2D(256, kernel_size=(3,3), padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=(2,2), strides=2, padding='same'),
layers.Conv2D(512, kernel_size=(3,3), padding='same', activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=(3,3), padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=(2,2), strides=2, padding='same'),
layers.Conv2D(512, kernel_size=(3,3), padding='same', activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=(3,3), padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=(2,2), strides=2, padding='same'),
layers.Flatten(),
layers.Dense(4096, activation=tf.nn.relu),
layers.Dense(4096, activation=tf.nn.relu),
layers.Dense(100, activation=None)
]
model = Sequential(layers=conv_layer)
model.build(input_shape=[None, 32,32,3])
'''
跑模型的时候先给个随便什么输入,看看输出是不是期望的
'''
x=tf.random.normal([4,32,32,3])
out=model(x)
print(out.shape)
def preprocess(x, y):
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32)
y = tf.squeeze(y, axis=0)
y = tf.cast(tf.one_hot(y, depth=100),dtype=tf.int32)
return x, y
(x, y), (x_test, y_test) = datasets.cifar100.load_data()
print(y.shape)
train_db=tf.data.Dataset.from_tensor_slices((x,y)).shuffle(1000).map(preprocess).batch(128)
test_db=tf.data.Dataset.from_tensor_slices((x_test,y_test)).map(preprocess).batch(128)
optimizer = optimizers.Adam(lr=1e-4)
variables = model.trainable_variables
for epoch in range(50):
for step, (x,y) in enumerate(train_db):
with tf.GradientTape() as tape:
# [b, 32, 32, 3] => [b, 1, 1, 512]
logits = model(x)
# compute loss
loss = tf.losses.categorical_crossentropy(y, logits, from_logits=True)
loss = tf.reduce_mean(loss)
grads = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(grads, variables))
if step %100 == 0:
print(epoch, step, 'loss:', float(loss))
total_num = 0
total_correct = 0
for x,y in test_db:
logits = model(x)
prob = tf.nn.softmax(logits, axis=1)
pred = tf.argmax(prob, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
correct = tf.cast(tf.equal(pred, tf.cast(tf.argmax(y, axis=1), dtype=tf.int32)), dtype=tf.int32)
correct = tf.reduce_sum(correct)
total_num += x.shape[0]
total_correct += int(correct)
acc = total_correct / total_num
print(epoch, 'acc:', acc)
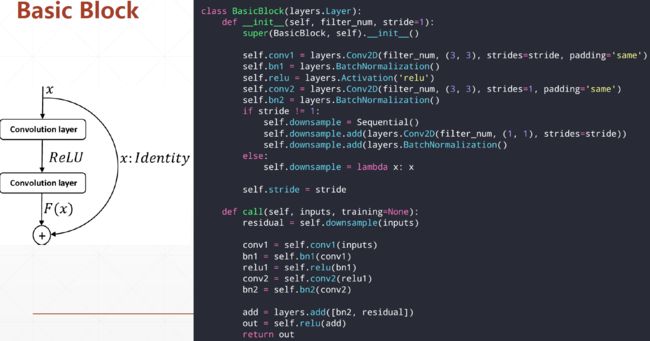
Cifar100 ResNet实战
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, Sequential
class BasicBlock(layers.Layer):
def __init__(self, filter_num, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = layers.Conv2D(filter_num, (3, 3), strides=stride, padding='same')
self.bn1 = layers.BatchNormalization()
self.relu = layers.Activation('relu')
self.conv2 = layers.Conv2D(filter_num, (3, 3), strides=1, padding='same')
self.bn2 = layers.BatchNormalization()
if stride != 1:
self.downsample = Sequential()
self.downsample.add(layers.Conv2D(filter_num, (1, 1), strides=stride))
else:
self.downsample = lambda x:x
def call(self, inputs, training=None):
# [b, h, w, c]
out = self.conv1(inputs)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
identity = self.downsample(inputs)
output = layers.add([out, identity])
output = tf.nn.relu(output)
return output
class ResNet(keras.Model):
def __init__(self, layer_dims, num_classes=100): # [2, 2, 2, 2]
super(ResNet, self).__init__()
self.stem = Sequential([layers.Conv2D(64, (3, 3), strides=(1, 1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(pool_size=(2, 2), strides=(1, 1), padding='same')
])
self.layer1 = self.build_resblock(64, layer_dims[0])
self.layer2 = self.build_resblock(128, layer_dims[1], stride=2)
self.layer3 = self.build_resblock(256, layer_dims[2], stride=2)
self.layer4 = self.build_resblock(512, layer_dims[3], stride=2)
# output: [b, 512, h, w],
self.avgpool = layers.GlobalAveragePooling2D()
self.fc = layers.Dense(num_classes)
def call(self, inputs, training=None):
x = self.stem(inputs)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# [b, c]
x = self.avgpool(x)
# [b, 100]
x = self.fc(x)
return x
def build_resblock(self, filter_num, blocks, stride=1):
res_blocks = Sequential()
# may down sample
res_blocks.add(BasicBlock(filter_num, stride))
for _ in range(1, blocks):
res_blocks.add(BasicBlock(filter_num, stride=1))
return res_blocks
def resnet18():
return ResNet([2, 2, 2, 2])
def resnet34():
return ResNet([3, 4, 6, 3])
from tensorflow.keras import optimizers, datasets
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
tf.random.set_seed(2345)
def preprocess(x, y):
# [-1~1]
x = tf.cast(x, dtype=tf.float32) / 255. - 0.5
y = tf.cast(y, dtype=tf.int32)
return x,y
(x,y), (x_test, y_test) = datasets.cifar100.load_data()
y = tf.squeeze(y, axis=1)
y_test = tf.squeeze(y_test, axis=1)
print(x.shape, y.shape, x_test.shape, y_test.shape)
train_db = tf.data.Dataset.from_tensor_slices((x,y))
train_db = train_db.shuffle(1000).map(preprocess).batch(128)
test_db = tf.data.Dataset.from_tensor_slices((x_test,y_test))
test_db = test_db.map(preprocess).batch(128)
sample = next(iter(train_db))
print('sample:', sample[0].shape, sample[1].shape,
tf.reduce_min(sample[0]), tf.reduce_max(sample[0]))
# [b, 32, 32, 3] => [b, 1, 1, 512]
model = resnet18()
model.build(input_shape=(None, 32, 32, 3))
model.summary()
optimizer = optimizers.Adam(lr=1e-3)
for epoch in range(500):
for step, (x,y) in enumerate(train_db):
with tf.GradientTape() as tape:
# [b, 32, 32, 3] => [b, 100]
logits = model(x)
# [b] => [b, 100]
y_onehot = tf.one_hot(y, depth=100)
# compute loss
loss = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True)
loss = tf.reduce_mean(loss)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step %50 == 0:
print(epoch, step, 'loss:', float(loss))
total_num = 0
total_correct = 0
for x,y in test_db:
logits = model(x)
prob = tf.nn.softmax(logits, axis=1)
pred = tf.argmax(prob, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
correct = tf.cast(tf.equal(pred, y), dtype=tf.int32)
correct = tf.reduce_sum(correct)
total_num += x.shape[0]
total_correct += int(correct)
acc = total_correct / total_num
print(epoch, 'acc:', acc)
9. 循环神经网络
- Sequence Embedding:
word=>vector
语义相似的词汇,vector的距离也应该小
layers.Embedding(input_dim, output_dim)input_dim:Size of the vocabulary, (一共能处理的词汇量)i.e. maximum integer index + 1.output_dim:Dimension of the dense embedding.
Embedding也是可以训练的,语义表达会越来越好 -
layers.SimpleRNNCell(units)units是输出的维度,需要手动管理h
layers.SimpleRNN()不需要关心h
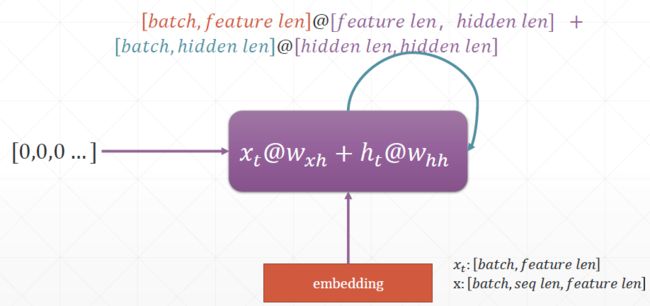
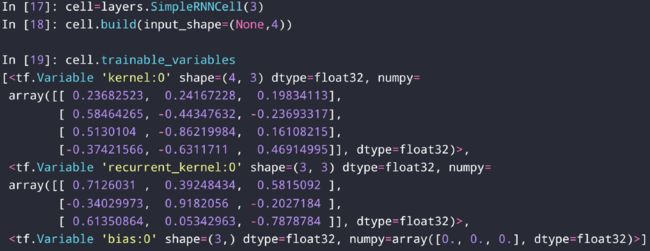 h_t = x@w1+h_t-1@w2+b ___ (4,3)是x的w1 (3,3)是h的w2
h_t = x@w1+h_t-1@w2+b ___ (4,3)是x的w1 (3,3)是h的w2
中间状态h在tensorflow中都是一个List
RNN实战 - 情感分类

低层级实现
import os
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
batchsz = 128
# the most frequest words
total_words = 10000
max_review_len = 80
embedding_len = 100
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)
# x_train:[b, 80]
# x_test: [b, 80]
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.batch(batchsz, drop_remainder=True)
print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))
print('x_test shape:', x_test.shape)
class MyRNN(keras.Model):
def __init__(self, units):
super(MyRNN, self).__init__()
# [b, 64]
self.state0 = [tf.zeros([batchsz, units])]
self.state1 = [tf.zeros([batchsz, units])]
# transform text to embedding representation
# [b, 80] => [b, 80, 100]
self.embedding = layers.Embedding(total_words, embedding_len,
input_length=max_review_len)
# [b, 80, 100] , h_dim: 64
# RNN: cell1 ,cell2, cell3
# SimpleRNN
self.rnn_cell0 = layers.SimpleRNNCell(units, dropout=0.5)
self.rnn_cell1 = layers.SimpleRNNCell(units, dropout=0.5)
# fc, [b, 80, 100] => [b, 64] => [b, 1]
self.outlayer = layers.Dense(1)
def call(self, inputs, training=None):
"""
net(x) net(x, training=True) :train mode
net(x, training=False): test
:param inputs: [b, 80]
:param training:
:return:
"""
# [b, 80]
x = inputs
# embedding: [b, 80] => [b, 80, 100]
x = self.embedding(x)
# rnn cell compute
# [b, 80, 100] => [b, 64]
state0 = self.state0
state1 = self.state1
for word in tf.unstack(x, axis=1): # word: [b, 100]
# h1 = x*wxh+h0*whh
# out0: [b, 64]
out0, state0 = self.rnn_cell0(word, state0, training)
# out1: [b, 64]
out1, state1 = self.rnn_cell1(out0, state1, training)
# out: [b, 64] => [b, 1]
x = self.outlayer(out1)
# p(y is pos|x)
prob = tf.sigmoid(x)
return prob
def main():
units = 64
epochs = 4
model = MyRNN(units)
model.compile(optimizer = keras.optimizers.Adam(0.001),
loss = tf.losses.BinaryCrossentropy(),
metrics=['accuracy'])
model.fit(db_train, epochs=epochs, validation_data=db_test)
model.evaluate(db_test)
if __name__ == '__main__':
main()
Layer实现
import os
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
batchsz = 128
# the most frequest words
total_words = 10000
max_review_len = 80
embedding_len = 100
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)
# x_train:[b, 80]
# x_test: [b, 80]
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.batch(batchsz, drop_remainder=True)
print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))
print('x_test shape:', x_test.shape)
class MyRNN(keras.Model):
def __init__(self, units):
super(MyRNN, self).__init__()
# transform text to embedding representation
# [b, 80] => [b, 80, 100]
self.embedding = layers.Embedding(total_words, embedding_len,
input_length=max_review_len)
# [b, 80, 100] , h_dim: 64
self.rnn = keras.Sequential([
layers.SimpleRNN(units, dropout=0.5, return_sequences=True, unroll=True),
layers.SimpleRNN(units, dropout=0.5, unroll=True)
])
# fc, [b, 80, 100] => [b, 64] => [b, 1]
self.outlayer = layers.Dense(1)
def call(self, inputs, training=None):
"""
net(x) net(x, training=True) :train mode
net(x, training=False): test
:param inputs: [b, 80]
:param training:
:return:
"""
# [b, 80]
x = inputs
# embedding: [b, 80] => [b, 80, 100]
x = self.embedding(x)
# rnn cell compute
# x: [b, 80, 100] => [b, 64]
x = self.rnn(x)
# out: [b, 64] => [b, 1]
x = self.outlayer(x)
# p(y is pos|x)
prob = tf.sigmoid(x)
return prob
def main():
units = 64
epochs = 4
model = MyRNN(units)
model.compile(optimizer = keras.optimizers.Adam(0.001),
loss = tf.losses.BinaryCrossentropy(),
metrics=['accuracy'])
model.fit(db_train, epochs=epochs, validation_data=db_test)
model.evaluate(db_test)
if __name__ == '__main__':
main()
梯度裁剪
grads=[tf.clip_by_norm(g, 15) for g in grads] #15是经验值,一般梯度小于10是比较好的
LSTM
参数unroll:性能优化
GRU
10. AutoEncoder
非监督学习
- 降维、压缩、预处理、可视化
-
Denoising AutoEncoder
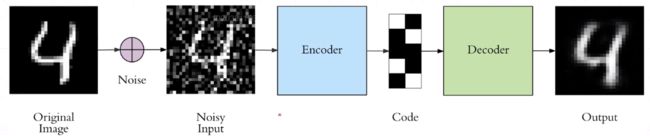 找到真实的语义
找到真实的语义 -
Dropout AutoEncoder
 0.2比较好
0.2比较好 -
Adversarial AutoEncoder
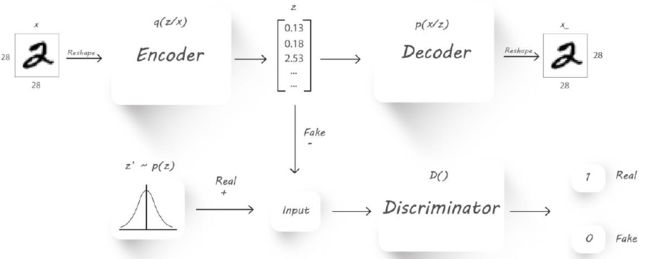 使得Z除了能完成重建,而且能尽可能满足预设的分布,比如正态分布
使得Z除了能完成重建,而且能尽可能满足预设的分布,比如正态分布 -
Variational AutoEncoder
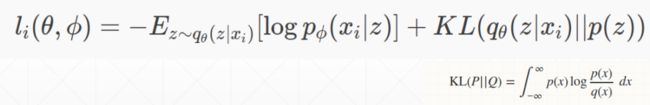 第一项就是MSE,第二项KL散度,也就是z的分布与z|x的分布越接近越好
第一项就是MSE,第二项KL散度,也就是z的分布与z|x的分布越接近越好
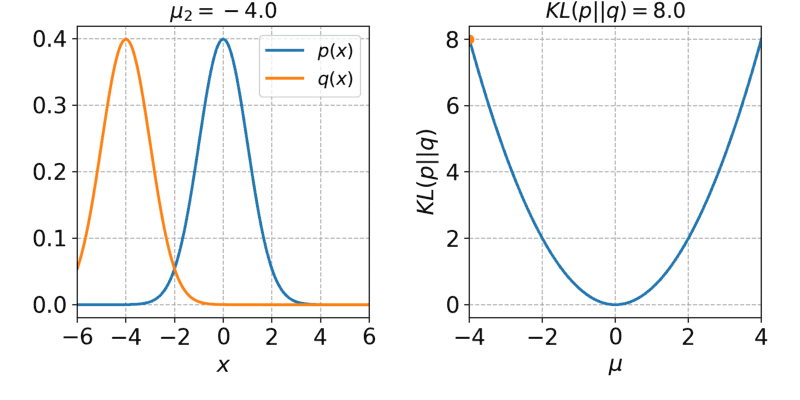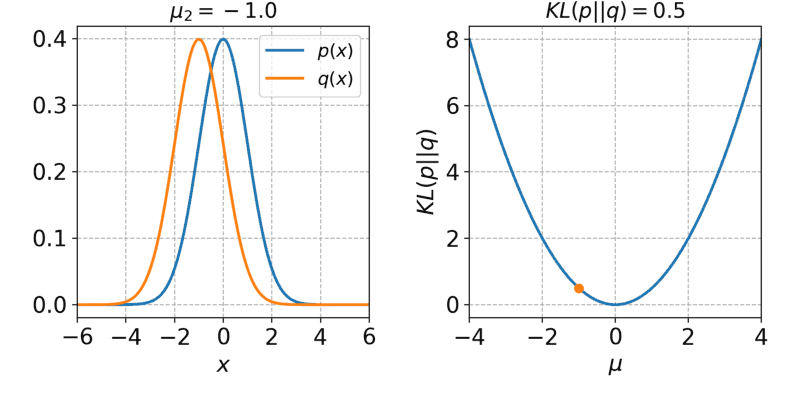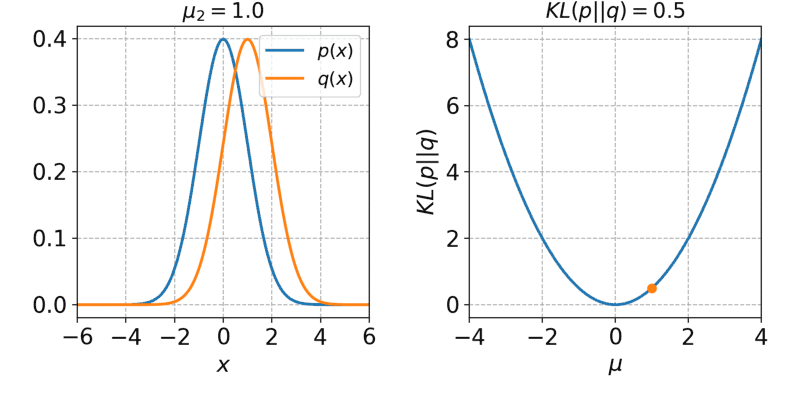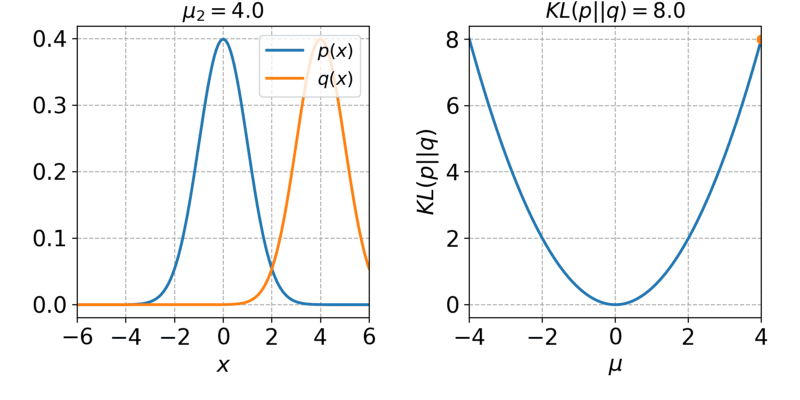
- 效果没法和GAN比,但是训练要比GAN稳定很多
VAE实战 (MNIST)
import os
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import Sequential, layers
from PIL import Image
from matplotlib import pyplot as plt
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
def save_images(imgs, name):
new_im = Image.new('L', (280, 280))
index = 0
for i in range(0, 280, 28):
for j in range(0, 280, 28):
im = imgs[index]
im = Image.fromarray(im, mode='L')
new_im.paste(im, (i, j))
index += 1
new_im.save(name)
h_dim = 20
batchsz = 512
lr = 1e-3
(x_train, y_train), (x_test, y_test) = keras.datasets.fashion_mnist.load_data()
x_train, x_test = x_train.astype(np.float32) / 255., x_test.astype(np.float32) / 255.
# we do not need label
train_db = tf.data.Dataset.from_tensor_slices(x_train)
train_db = train_db.shuffle(batchsz * 5).batch(batchsz)
test_db = tf.data.Dataset.from_tensor_slices(x_test)
test_db = test_db.batch(batchsz)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
z_dim = 10
class VAE(keras.Model):
def __init__(self):
super(VAE, self).__init__()
# Encoder
self.fc1 = layers.Dense(128)
self.fc2 = layers.Dense(z_dim) # get mean prediction
self.fc3 = layers.Dense(z_dim)
# Decoder
self.fc4 = layers.Dense(128)
self.fc5 = layers.Dense(784)
def encoder(self, x):
h = tf.nn.relu(self.fc1(x))
# get mean
mu = self.fc2(h)
# get variance
log_var = self.fc3(h)
return mu, log_var
def decoder(self, z):
out = tf.nn.relu(self.fc4(z))
out = self.fc5(out)
return out
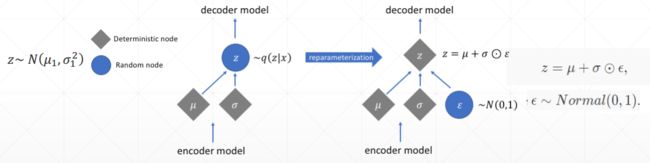
def reparameterize(self, mu, log_var):
eps = tf.random.normal(log_var.shape)
std = tf.exp(log_var*0.5)
z = mu + std * eps
return z
def call(self, inputs, training=None):
# [b, 784] => [b, z_dim], [b, z_dim]
mu, log_var = self.encoder(inputs)
# reparameterization trick
z = self.reparameterize(mu, log_var)
x_hat = self.decoder(z)
return x_hat, mu, log_var
model = VAE()
model.build(input_shape=(4, 784))
optimizer = tf.optimizers.Adam(lr)
for epoch in range(1000):
for step, x in enumerate(train_db):
x = tf.reshape(x, [-1, 784])
with tf.GradientTape() as tape:
x_rec_logits, mu, log_var = model(x)
rec_loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=x, logits=x_rec_logits)
rec_loss = tf.reduce_sum(rec_loss) / x.shape[0]
# compute kl divergence (mu, var) ~ N (0, 1)
# https://stats.stackexchange.com/questions/7440/kl-divergence-between-two-univariate-gaussians
kl_div = -0.5 * (log_var + 1 - mu**2 - tf.exp(log_var))
kl_div = tf.reduce_sum(kl_div) / x.shape[0]
loss = rec_loss + 1. * kl_div
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 100 == 0:
print(epoch, step, 'kl div:', float(kl_div), 'rec loss:', float(rec_loss))
# evaluation
z = tf.random.normal((batchsz, z_dim))
logits = model.decoder(z)
x_hat = tf.sigmoid(logits)
x_hat = tf.reshape(x_hat, [-1, 28, 28]).numpy() *255.
x_hat = x_hat.astype(np.uint8)
save_images(x_hat, 'vae_images/sampled_epoch%d.png'%epoch)
x = next(iter(test_db))
x = tf.reshape(x, [-1, 784])
x_hat_logits, _, _ = model(x)
x_hat = tf.sigmoid(x_hat_logits)
x_hat = tf.reshape(x_hat, [-1, 28, 28]).numpy() *255.
x_hat = x_hat.astype(np.uint8)
save_images(x_hat, 'vae_images/rec_epoch%d.png'%epoch)
11. GAN
本质
- 逼近两个分布,不管用KL散度还是JS散度
- 容易出现训练不起来的原因是:两个分布如果相差太远,散度的梯度始终是0,梯度不起作用
- WGAN-GP
WGAN实战
class Generator(keras.Model):
def __init__(self):
super(Generator, self).__init__()
# z:[b, 100] => [b, 3*3*512] => [b, 3,3,512] =>[b,64,64,3]
self.fc= layers.Dense(3*3*512)
self.conv1=layers.Conv2DTranspose(256, 3, 3)
self.bn1 = BatchNormalization()
self.conv2=layers.Conv2DTranspose(128, 5, 2)
self.bn2 = BatchNormalization()
self.conv3=layers.Conv2DTranspose(3, 4, 3)
def call(self, inputs, training=None):
x = self.fc(inputs)
x = tf.reshape(x, [-1, 3, 3, 512])
x = tf.nn.leaky_relu(x)
x = tf.nn.leaky_relu(self.bn1(self.conv1(x), training=training))
x = tf.nn.leaky_relu(self.bn2(self.conv2(x), training=training))
x = self.conv3(x)
x=tf.tanh(x) # [-1, 1] Discriminator的输入是[-1,1]
return x
class Discriminator(keras.Model):
def __init__(self):
super(Discriminator, self).__init__()
# [b, 64, 64, 3] => [b,1]
self.conv1 = layers.Conv2D(filters=64, kernel_size=5, strides=3, padding='valid')
self.conv2 = layers.Conv2D(128, 5, 3)
self.bn2 = BatchNormalization()
self.conv3 = layers.Conv2D(256, 5, 3)
self.bn3 = BatchNormalization()
# [b, h, w, 3] => [b, -1]
self.flatten = layers.Flatten()
self.fc = layers.Dense(1)
def call(self, inputs, training=None):
x = tf.nn.leaky_relu(self.conv1(inputs))
x = tf.nn.leaky_relu(self.bn2(self.conv2(x), training=training))
x = tf.nn.leaky_relu(self.bn3(self.conv3(x), training=training))
x= self.flatten(x)
logits = self.fc(x)
return logits
def celoss_ones(logits):
# [b, 1]
# [b] = [1, 1, 1, 1,]
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits=logits,
labels=tf.ones_like(logits))
return tf.reduce_mean(loss)
def celoss_zeros(logits):
# [b, 1]
# [b] = [1, 1, 1, 1,]
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits=logits,
labels=tf.zeros_like(logits))
return tf.reduce_mean(loss)
def gradient_penalty(discriminator, batch_x, fake_image):
batchsz = batch_x.shape[0]
#[b, h, w, c]
t=tf.random.uniform([batchsz, 1, 1, 1])
t = tf.broadcast_to(t, batch_x.shape)
interplate = t*batch_x+(1-t)*fake_image
with tf.GradientTape() as tape:
tape.watch([interplate])
d_interplote_logits = discriminator(interplate)
grads = tape.gradient(d_interplote_logits, interplate)
# grads:[b, h, w, c] => [b, -1]
grads = tf.reshape(grads, [grads.shape[0], -1])
gp = tf.norm(grads, axis=1) #[b]
gp = tf.reduce_mean( (gp-1)**2 )
return gp
def d_loss_fn(generator, discriminator, batch_z, batch_x, is_training):
# 1. treat real image as real
# 2. treat generated image as fake
fake_image = generator(batch_z, is_training)
d_fake_logits = discriminator(fake_image, is_training)
d_real_logits = discriminator(batch_x, is_training)
d_loss_real = celoss_ones(d_real_logits)
d_loss_fake = celoss_zeros(d_fake_logits)
gp = gradient_penalty(discriminator, batch_x, fake_image)
loss = d_loss_fake + d_loss_real + 5. * gp
return loss, gp
def g_loss_fn(generator, discriminator, batch_z, is_training):
fake_image = generator(batch_z, is_training)
d_fake_logits = discriminator(fake_image, is_training)
loss = celoss_ones(d_fake_logits)
return loss
z_dim = 100
epochs = 3000000
batch_size = 512
learning_rate = 0.002
is_training = True
generator = Generator()
generator.build(input_shape = (None, z_dim))
discriminator = Discriminator()
discriminator.build(input_shape=(None, 64, 64, 3))
g_optimizer = tf.optimizers.Adam(learning_rate=learning_rate, beta_1=0.5)
d_optimizer = tf.optimizers.Adam(learning_rate=learning_rate, beta_1=0.5)
for epoch in range(epochs):
batch_z = tf.random.uniform([batch_size, z_dim], minval=-1., maxval=1.)
batch_x = next(db_iter)
# train D
with tf.GradientTape() as tape:
d_loss, gp = d_loss_fn(generator, discriminator, batch_z, batch_x, is_training)
grads = tape.gradient(d_loss, discriminator.trainable_variables)
d_optimizer.apply_gradients(zip(grads, discriminator.trainable_variables))
with tf.GradientTape() as tape:
g_loss = g_loss_fn(generator, discriminator, batch_z, is_training)
grads = tape.gradient(g_loss, generator.trainable_variables)
g_optimizer.apply_gradients(zip(grads, generator.trainable_variables))
if epoch % 100 == 0:
print(epoch, 'd-loss:',float(d_loss), 'g-loss:', float(g_loss),
'gp:', float(gp))
z = tf.random.uniform([100, z_dim])
fake_image = generator(z, training=False)
img_path = os.path.join('images', 'wgan-%d.png'%epoch)
save_result(fake_image.numpy(), 10, img_path, color_mode='P')