一、什么是数据库?
数据库是以一定方式储存在一起、能与多个用户共享、具有尽可能小的冗余度、与应用程序彼此独立的数据集合,可视为电子化的文件柜——存储电子文件的处所,用户可以对文件中的数据进行新增、查询、更新、删除等操作
二、什么是范式?
范式来自英文Normal form,简称NF。要想设计—个好的关系,必须使关系满足一定的约束条件,此约束已经形成了规范,分成几个等级,一级比一级要求得严格。
三、什么是数据库范式?
数据的三大范式以及什么是反三大范式
一:首先说一下什么是三大范式:
1.第一范式(1NF):确保每一列的原子性(做到每列不可拆分)
2.第二范式(2NF):在第一范式的基础上,非主字段必须依赖于主字段(一个表只做一件事)
3.第三范式(3NF):在第二范式的基础上,消除传递依赖
上面都是官话 ,对于设计表来说 第一范式是什么意思呢 看表1-1

1-1
上面的用户表明显就不符合三大范式的第一范式:为什么呢?address字段列的数据中是"中国-北京";这是可以拆分的 可以拆分成如下表,为什么要拆分呢,当我统计地区分类时,这样明显是不好统计,我们可以改成表1-2的形式,这就符合了第一范式的要求.

1-2
那什么又是第二范式,第二范式建立在第一范式的基础之上(在第一范式的基础上,非主字段必须依赖于主字段,一个表只做一件事),看表1-3

1-3
我们在后面又添加了数学成绩,英语成绩,家产等一系列的字段,如果这样设计的话,一张表可以满足一个项目所需要的所有字段,都合成在一张表中(后面无限加字段),这样就很乱了,也违背了第二范式
那什么又是第三范式,第三范式建立在第一范式的基础之上(消除传递依赖),看表1-4
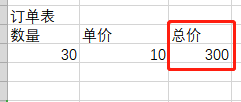
1-4
我们有一张订单表,里面有数量,单机,以及总价一些字段,但总价这个不应该有,总价是可以通过数量乘以单价得到,这就没有遵守第三范式(消除传递依赖)),如果没有理解清楚,我们再看表1-5与表1-6

1-5

1-6
在用户表中,正确来说我们用户表只该存一个企业id,企业名称这个字段是我们推导出来的,企业名称应该是去企业表中去查询,这就明显不符合第三范式;
一:再说什么是反三大范式:
说完三大范式,我们再说一下什么是反三范式,就拿第三范式来说,看表1-7
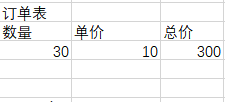
如果我们有数以万计的数据,每次查询完数据之后想要总价这个属性,我们就要进行数以万计次的计算,这明显会拖慢服务性能,就拿表1-5和1-6来说,我们每此查询用户的时候,回显企业信息的时候,还要去查询企业表,这样多了一次查询,也会拖慢服务器的性能.
总结来说呢:反三范式是基于第三范式所调整的,没有冗余的数据库未必是好的数据库,有时为了提高运行效率,就必须降低 范式标准,适当保留冗余数据。基于业务的需要合理设计数据库