从本篇文章开始,我将对Android比较复杂的图形系统进行分析,开篇我们先对图形系统做个概览,先不对代码做具体分析。
文章从如下三个层次进行讲解.其中每一层之间的数据传递是使用Buffer(缓冲区)作为载体, 上层和framework间的buffer为图形缓冲区,framework与显示屏间的buffer是硬件帧缓冲区。
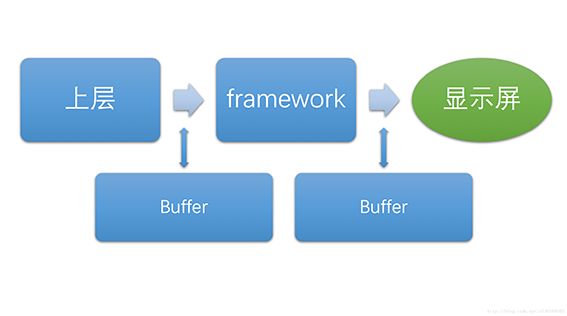
一、图形渲染流程
1.1 app层绘制
由ViewRootImpl发起performTraversals开始View的绘制流程:
1)测量View的宽高(Measure)
2)设置View的宽高位置(Layout)
3)创建显示列表,并执行绘制(Draw)
4)绘制通过图形处理引擎来实现,生成多边形和纹理(Record、 Execute)。
其中引擎包括:
2D : Canvas,Canvas调用的API到下层其实封装了skia的实现。
3D: OpenGL ES , 当应用窗口flag等于WindowManager.LayoutParams.MEMORY_TYPE_GPU , 则表示需要用OpenGL接口来绘制UI.
1.2 Surface
每个Window对应一个Surface,任何View都要画在Surface的Canvas上。图形的传递是通过Buffer作为载体,Surface是对Buffer的进一步封装,也就是说Surface内部具有多个Buffer供上层使用,如何管理这些Buffer呢?请看下面这个模型:
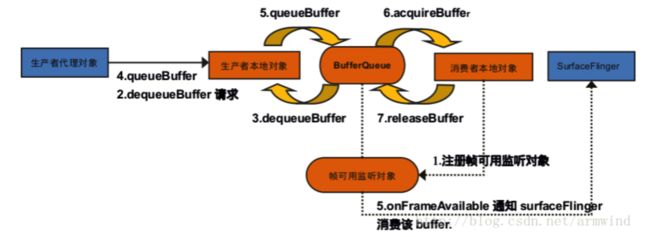
Surface对应生产者代理对象,Surface(Native)对应生产者本地对象。那么流程就是:
上层app通过Surface获取buffer,供上层绘制,绘制过程通过Canvas来完成,底层实现是skia引擎,绘制完成后数据通过Surface被dequeue进BufferQueue, 然后监听会通知SurfaceFlinger去消费buffer, 接着SurfaceFlinger就acquire数据拿去合成, 合成完成后会将buffer release回BufferQueue。如此循环,形成一个Buffer被循环使用的过程。
另外,这个过程有这么几个状态:
Free:可被上层使用
Dequeued:出列,正在被上层使用
Queued:入列,已完成上层绘制,等待SurfaceFlinger合成
Acquired:被获取,SurfaceFlinger正持有该Buffer进行合成
所以Surface主要干两件事:
- 获取Canvas来干绘制的活。
- 申请buffer,并把Canvas最终生产的图形、纹理数据放进去。
1.3 SurfaceFlinger
SurfaceFlinger 是一个独立的Service, 它接收所有Surface作为输入,创建layer(其主要的组件是一个 BufferQueue)与Surface一一对应,根据ZOrder, 透明度,大小,位置等参数,计算出每个layer在最终合成图像中的位置,然后交由HWComposer或OpenGL生成最终的栅格化数据, 放到layer的framebuffer上。
1.4 Layer
Layer是SurfaceFlinger 进行合成的基本操作单元,其主要的组件是一个 BufferQueue。Layer在应用请求创建Surface的时候在SurfaceFlinger内部创建,因此一个Surface对应一个 Layer。Layer 其实是一个 FrameBuffer,每个 FrameBuffer 中有两个 GraphicBuffer 记作 FrontBuffer 和 BackBuffer。
1.5 Hardware Composer
Hardware Composer HAL (HWC) 在 Android 3.0 中被引入。它的主要目标是通过可用硬件确定组合缓冲区的最有效方式。
1)SurfaceFlinger 为 HWC 提供完整的 layers 的列表并询问,“你想要如何处理它?”。
2)HWComposer根据硬件性能决定是使用硬件图层合成器还是GPU合成,分别将每个layer对应标记为 overlay 或 GLES composition 来进行响应。
3)SurfaceFlinger处理需要GPU合成的layers,将结果递交给HWComposer做显示(通过Hwcomposer HAL),需要硬件图层合成器合成的layers由HWComposer自行处理(通过Hwcomposer HAL)。
4)合成Layer时,优先选用HWComposer,在HWComposer无法解决时,SurfaceFlinger采用默认的3D合成,也即调OpenGL标准接口,将各layer绘制到fb上。
分析:这样设计的好处是可以充分发挥硬件性能,同时降低SurfaceFlinger和硬件平台的耦合度(方便移植),另外SurfaceFlinger能将一些合成工作委托给Hardware Composer,从而降低来自OpenGL和GPUd的负载。
总结下两种合成方式:
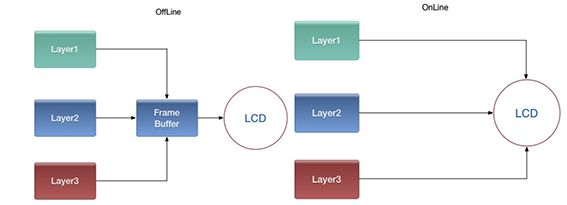
离线合成:
先将所有图层画到一个最终层(FrameBuffer)上,再将FrameBuffer送到LCD显示。由于合成FrameBuffer与送LCD显示一般是异步的(线下生成FrameBuffer,需要时线上的LCD去取),因此叫离线合成。毫无疑问,SurfaceFlinger采用默认的3D合成,也即调OpenGL标准接口,将各layer绘制到fb上属于离线合成。
在线合成:
不使用FrameBuffer,在LCD需要显示某一行的像素时,用显示控制器将所有图层与该行相关的数据取出,合成一行像素送过去。只有一个图层时,又叫Overlay技术。由于省去合成FrameBuffer时读图层,写FrameBuffer的步骤,大幅降低了内存传输量,减少了功耗,但这个需要硬件支持。毫无疑问,HWComposer合成属于在线合成。
经过上述分析,我们大概了解了整个显示数据的产生、传送、合成的过程以及相关类在这个过程中所起的作用,最后总结一张图形数据流:

1.6 Screen显示
显示屏上的内容,是从硬件帧缓冲区读取的,大致读取过程为:从Buffer的起始地址开始,从上往下,从左往右扫描整个Buffer,将内容映射到显示屏上。
下图显示的是双缓冲:一个FrontBuffer用于提供屏幕显示内容,一个BackBuffer用于后台合成下一帧图形。

假设前一帧显示完毕,后一帧准备好了,屏幕将会开始读取下一帧的内容,也就是开始读取上图中的后缓冲区的内容.此时,前后缓冲区进行一次角色互换,之前的后缓冲区变为前缓冲区,进行图形的显示,之前的前缓冲区则变为后缓冲区,进行图形的合成。
最后通过官方给出的图了解下关键组件如何协同工作:
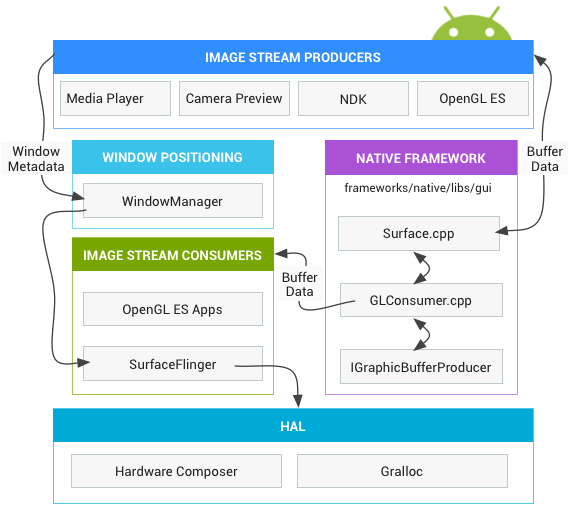
总结下渲染Android应用视图的渲染流程:
测量流程用来确定视图的大小、布局流程用来确定视图的位置、绘制流程最终将视图绘制在应用窗口上。
Android应用程序窗口UI首先是使用Canvas通过Skia图形库API来绘制在一块画布上,实际地是通过Surface绘制在这块画布里面的一个图形缓冲区中,这个图形缓冲区最终会通过layer的形式交给SurfaceFlinger来合成,而合成后栅格化数据的操作交由HWComposer或OpenGL生成,即将这个图形缓冲区渲染到硬件帧缓冲区中,供屏幕显示。
二、CPU/GPU的合成帧率与Display的刷新率同步问题
接上节,我们已经知道系统层不断地合成显示内容到后缓冲区,屏幕消费前缓冲区的显示内容,两缓冲区再交换。那么两者的频率是怎样的呢?
我们先来了解两个概念:
屏幕刷新率(HZ):代表屏幕在一秒内刷新屏幕的次数,Android手机一般为60HZ(也就是1秒刷新60帧,大约16.67毫秒刷新1帧)。
系统帧速率(FPS):代表了系统在一秒内合成的帧数,该值的大小由系统算法和硬件决定。
屏幕刷新率决定了屏幕消费显示内容的速度,而系统帧速率则决定了生产显示内容的速度。这是一个典型的生产者消费者的问题。两个缓冲区的操作速率不一致,势必会出现同步问题,如何解决?
从Android4.1版本开始,Android对显示系统进行了重构,引入了三个核心元素:VSYNC, Tripple Buffer和Choreographer。来解决同步问题。下面分别来介绍:
2.1 垂直同步(VSync)
垂直同步(VSync):当屏幕从缓冲区扫描完一帧到屏幕上之后,开始扫描下一帧之前,发出的一个同步信号,该信号用来切换前缓冲区和后缓冲区。
很明显这个垂直同步信号要求的是让合成帧的速率以屏幕刷新率为标杆。为什么要这样?很简单:屏幕的显示节奏是固定的,而系统帧速率是可以调整的,所以操作系统需要配合屏幕的显示,在固定的时间内准备好下一帧,以供屏幕进行显示。
那么以Android手机60Hz的刷新率来换算的话,垂直同步信号每16ms发送一次,那么也就意味着如何一帧在16ms内合成并显示,那么就算是流畅的。当然为什么设计刷新率为60Hz, 那是因为人眼的物理结构对60Hz刷新率的感受就已经是流畅了。
另外从执行者的角度看CPU与GPU的分工:
CPU:Measure,Layout,纹理和多边形生成,发送纹理和多边形到GPU
GPU:将CPU生成的纹理和多边形进行栅格化以及合成
好了,弄清楚上述信息之后,来看看VSYNC信号的例子:
1)没有VSYNC信号同步时
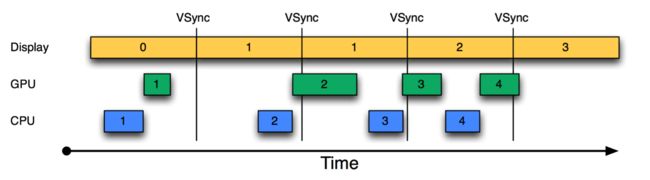
1> 第一个16ms开始:Display显示第0帧,CPU处理完第一帧后,GPU紧接其后处理继续第一帧。三者都在正常工作。
2> 进入第二个16ms:因为早在上一个16ms时间内,第1帧已经由CPU,GPU处理完毕。故Display可以直接显示第1帧。显示没有问题。但在本16ms期间,CPU和GPU却并未及时去绘制第2帧数据(前面的空白区表示CPU和GPU忙其它的事),直到在本周期快结束时,CPU/GPU才去处理第2帧数据。
3> 进入第三个16ms,此时Display应该显示第2帧数据,但由于CPU和GPU还没有处理完第2帧数据,故Display只能继续显示第一帧的数据,结果使得第1帧多画了一次(对应时间段上标注了一个Jank),导致错过了显示第二帧。
通过上述分析可知,此处发生Jank的关键问题在于,为何第1个16ms段内,CPU/GPU没有及时处理第2帧数据?原因很简单,CPU可能是在忙别的事情,不知道该到处理UI绘制的时间了。可CPU一旦想起来要去处理第2帧数据,时间又错过了。 为解决这个问题,Android 4.1中引入了VSYNC,核心目的是解决刷新不同步的问题。
2)引入VSYNC信号同步后
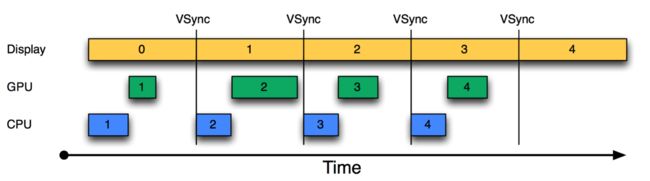
在加入VSYNC信号同步后,每收到VSYNC中断,CPU就开始处理各帧数据。已经解决了刷新不同步的问题。
但是上图中仍然存在一个问题:
CPU和GPU处理数据的速度似乎都能在16ms内完成,而且还有时间空余,这种情况没问题。
CPU/GPU的帧率高于Display的刷新率,这种情况虽然显示也没问题,但是CPU/GPU出现空闲状态。
但如果CPU/GPU的帧率低于Display的刷新率,情况又不同了,将会发生如下图的情况:
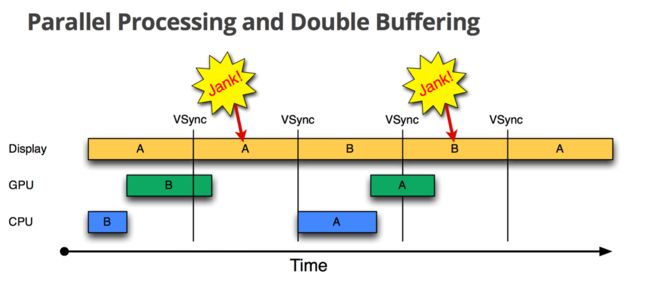
1> 在第二个16ms时间段,Display本应显示B帧,但却因为GPU还在处理B帧,导致A帧被重复显示。
2> 同理,在第二个16ms时间段内,CPU无所事事,因为A Buffer被Display在使用。B Buffer被GPU在使用。注意,一旦过了VSYNC时间点,CPU就不能被触发以处理绘制工作了。
上述情况产生了两个问题:1. CPU/GPU的帧率高于Display的刷新率,CPU/GPU出现空闲状态,这个状态能不能利用起来提前为下一轮准备好数据呢?2. 为什么CPU不能在第二个16ms处开始绘制工作呢?原因就是只有两个Buffer(Android 4.1之前)。如果有第三个Buffer的存在,CPU就能直接使用它,而不至于空闲。
2.2 Tripple Buffer
针对上述问题,google给出的解决方案是:加入第三个Buffer,CPU和GPU还有SurfaceFlinger各占一个Buffer,并行处理图形:

上图中,第二个16ms时间段,CPU使用C Buffer绘图。虽然还是会多显示A帧一次,但后续显示就比较顺畅了。
是不是Buffer越多越好呢?回答是否定的。由上图可知,在第二个时间段内,CPU绘制的第C帧数据要到第四个16ms才能显示,这比双Buffer情况多了16ms延迟。所以缓冲区并不是越多越好。
稍微总结下:
1> 一个Buffer: 如果在同一个Buffer进行读取和写入(合成)操作,将会导致屏幕显示多帧内容, 出现图像撕裂现象。
2> 两个Buffer: 解决撕裂问题,但是有卡顿问题,而且CPU/GPU利用率不高
3> 三个Buffer: 提高CPU/GPU利用率,减少卡顿,但是缺引入延迟问题。
2.3 Choreographer
屏幕的VSync信号只是用来控制帧缓冲区的切换,并未控制上层的绘制节奏,也就是说上层的生产节奏和屏幕的显示节奏是脱离的:

VSync信号如果光是切换backBuffer 和 frontBuffer,而不及时通知上层开始CPU GPU的工作,那么显示内容的合成还是无法同步的。
所以,google在Android 4.1系统中加入了上层接收垂直同步信号的逻辑,大致流程如下:
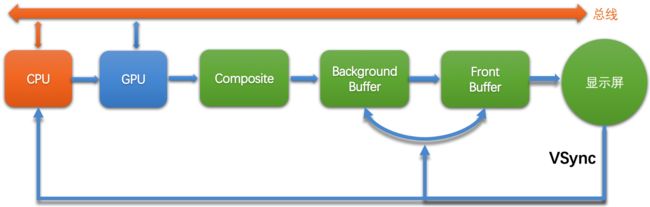
也就是说,屏幕在显示完一帧后,发出的垂直同步除了通知帧缓冲区的切换之外,该消息还会发送到上层,通知上层开始绘制下一帧。
那么,上层是如何接受这个VSync消息的呢?
Google为上层设计了一个Choreographer类,作为VSync信号的上层接收者。
首先看看Choreographer的类图:
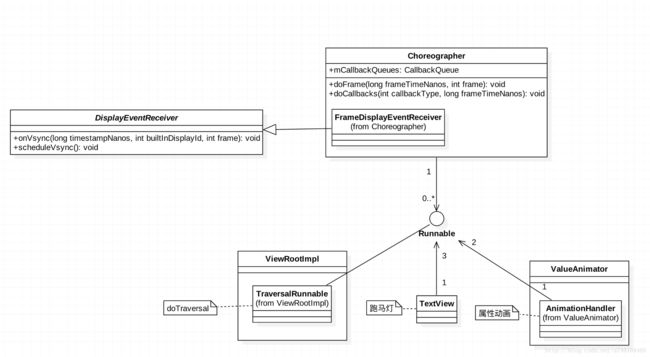
可以发现,Choreographer需要向SurfaceFlinger来注册一个VSync信号的接收器DisplayEventReceiver。同时在Choreographer的内部维护了一个CallbackQueue,用来保存上层关心VSync信号的组件,包括ViewRootImpl,TextView,ValueAnimator等。
再看看上层接收VSync的时序图:
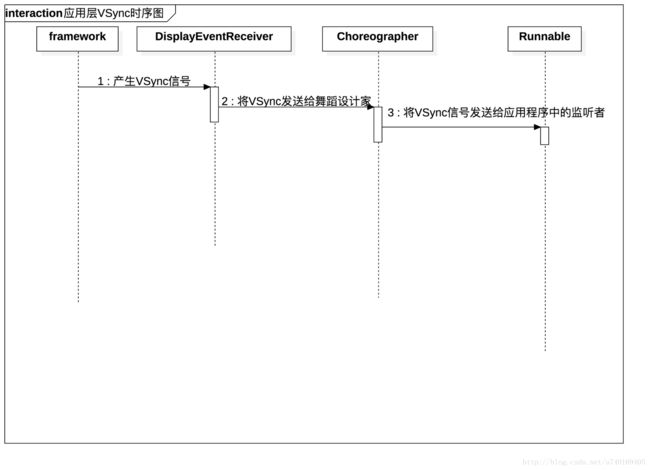
知道了Choreographer是上层用来接收VSync的角色之后,我们需要进一步了解VSync信号是如何控制上层的绘制的:
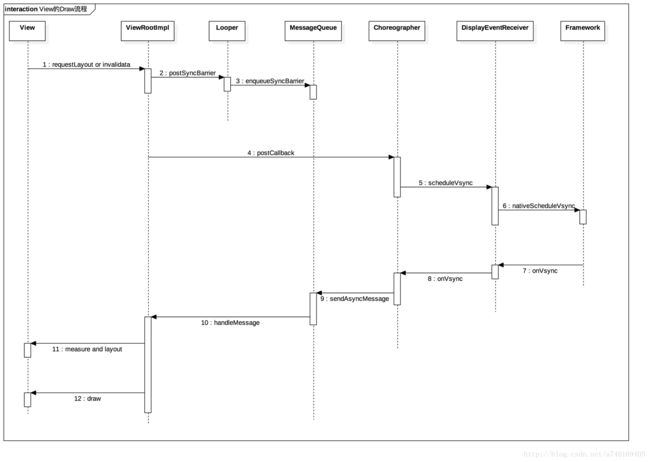
一般,上层需要绘制新的UI都是因为View的requestLayout或者是invalidate方法被调用触发的,我们以这个为起点,跟踪上层View的绘制流程:
requestLayout或者invalidate触发更新视图请求
更新请求传递到ViewRootImpl中,ViewRootImpl向主线程MessageQueue中加入一个阻塞器,该阻塞器将会拦截所有同步消息,也就是说此时,我们再通过Handler向主线程MessageQueue发送的所有Message都将无法被执行。
ViewRootImpl向Choreographer注册下一个VSync信号
Choreographer通过DisplayEventReceiver向framework层注册下一个VSync信号
当底层产生下一个VSync消息时,该信号将会发送给DisplayEventReceiver,最后传递给Choreographer
Choreographer收到VSync信号之后,向主线程MessageQueue发送了一个异步消息,我们在第二步提到,ViewRootImpl向MessageQueue发送了一个同步消息阻塞器。这里Choreographer发送的异步消息,是不会被阻塞器拦截的。
最后,异步消息的执行者是ViewRootImpl,也就是真正开始绘制下一帧了
总结:
Android通过Buffer来保存图形信息,为了让图形显示的更加流程,在提供一一个Buffer用于显示的同时,开辟一个或者多个Buffer用于后台图形的合成。
Android4.1之前,VSync信号并未传递给上层,导致生产与消费节奏不统一。
Android4.1之后,上层开始绘制时机都放到了VSync信号的到来时候
除了在上层引入VSync机制,Anroid在4.1还加入了三缓冲,用来减少卡顿的产生。
每个Surface都有自己的绘制流程,需要先经过CPU处理,再经过GPU处理,之后经过SurfaceFlinger与其他Surface绘制好的图形和合成在一起,供屏幕显示。
VSync信号贯穿整个绘制流程,控制着整个Android图形系统的节奏。
本篇只是简单描述下图形系统渲染流程的轮廓,我从下一篇开始详细分析每个流程。本文仅代表我个人的理解,欢迎批评指正!
参考:
https://blog.csdn.net/armwind/article/details/73436532
https://blog.csdn.net/STN_LCD/article/details/73801116
https://blog.csdn.net/a740169405/article/details/70548443?utm_source=blogxgwz0
https://blog.csdn.net/freekiteyu/article/details/79483406