1. 什么是seq2seq
在⾃然语⾔处理的很多应⽤中,输⼊和输出都可以是不定⻓序列。以机器翻译为例,输⼊可以是⼀段不定⻓的英语⽂本序列,输出可以是⼀段不定⻓的法语⽂本序列,例如:
英语输⼊:“They”、“are”、“watching”、“.”
法语输出:“Ils”、“regardent”、“.”
当输⼊和输出都是不定⻓序列时,我们可以使⽤编码器—解码器(encoder-decoder)或者seq2seq模型。序列到序列模型,简称seq2seq模型。这两个模型本质上都⽤到了两个循环神经⽹络,分别叫做编码器和解码器。编码器⽤来分析输⼊序列,解码器⽤来⽣成输出序列。两 个循环神经网络是共同训练的。
下图描述了使⽤编码器—解码器将上述英语句⼦翻译成法语句⼦的⼀种⽅法。在训练数据集中,我们可以在每个句⼦后附上特殊符号“
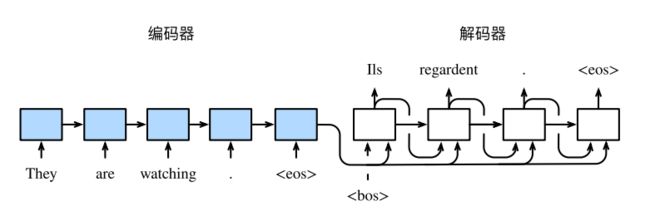
2. 编码器
编码器的作⽤是把⼀个不定⻓的输⼊序列变换成⼀个定⻓的背景变量 c,并在该背景变量中编码输⼊序列信息。常⽤的编码器是循环神经⽹络。
让我们考虑批量⼤小为1的时序数据样本。假设输⼊序列是 x1, . . . , xT,例如 xi 是输⼊句⼦中的第 i 个词。在时间步 t,循环神经⽹络将输⼊ xt 的特征向量 xt 和上个时间步的隐藏状态变换为当前时间步的隐藏状态ht。我们可以⽤函数 f 表达循环神经⽹络隐藏层的变换:
接下来,编码器通过⾃定义函数 q 将各个时间步的隐藏状态变换为背景变量:
例如,当选择 q(h1, . . . , h****T ) = h****T 时,背景变量是输⼊序列最终时间步的隐藏状态h**T。
以上描述的编码器是⼀个单向的循环神经⽹络,每个时间步的隐藏状态只取决于该时间步及之前的输⼊⼦序列。我们也可以使⽤双向循环神经⽹络构造编码器。在这种情况下,编码器每个时间步的隐藏状态同时取决于该时间步之前和之后的⼦序列(包括当前时间步的输⼊),并编码了整个序列的信息。
3. 解码器
刚刚已经介绍,编码器输出的背景变量 c 编码了整个输⼊序列 x1, . . . , xT 的信息。给定训练样本中的输出序列 y1, y2, . . . , yT′ ,对每个时间步 t′(符号与输⼊序列或编码器的时间步 t 有区别),解码器输出 yt′ 的条件概率将基于之前的输出序列 和背景变量 c,即:
为此,我们可以使⽤另⼀个循环神经⽹络作为解码器。在输出序列的时间步 t′,解码器将上⼀时间步的输出 以及背景变量 c 作为输⼊,并将它们与上⼀时间步的隐藏状态 变换为当前时间步的隐藏状态st′。因此,我们可以⽤函数 g 表达解码器隐藏层的变换:
有了解码器的隐藏状态后,我们可以使⽤⾃定义的输出层和softmax运算来计算,例如,基于当前时间步的解码器隐藏状态 st′、上⼀时间步的输出以及背景变量 c 来计算当前时间步输出 yt′ 的概率分布。
4. 训练模型
根据最⼤似然估计,我们可以最⼤化输出序列基于输⼊序列的条件概率:
并得到该输出序列的损失:
在模型训练中,所有输出序列损失的均值通常作为需要最小化的损失函数。在上图所描述的模型预测中,我们需要将解码器在上⼀个时间步的输出作为当前时间步的输⼊。与此不同,在训练中我们也可以将标签序列(训练集的真实输出序列)在上⼀个时间步的标签作为解码器在当前时间步的输⼊。这叫作强制教学(teacher forcing)。
5. seq2seq模型预测
以上介绍了如何训练输⼊和输出均为不定⻓序列的编码器—解码器。本节我们介绍如何使⽤编码器—解码器来预测不定⻓的序列。
在准备训练数据集时,我们通常会在样本的输⼊序列和输出序列后面分别附上⼀个特殊符号“
5.1 贪婪搜索
贪婪搜索(greedy search)。对于输出序列任⼀时间步t′,我们从|Y|个词中搜索出条件概率最⼤的词:
作为输出。⼀旦搜索出“
下⾯来看⼀个例⼦。假设输出词典⾥⾯有“A”“B”“C”和“
下的4个数字分别代表了该时间步⽣成“A”“B”“C”和“
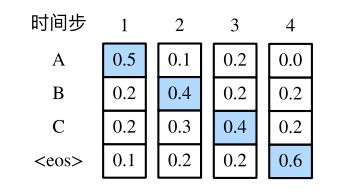
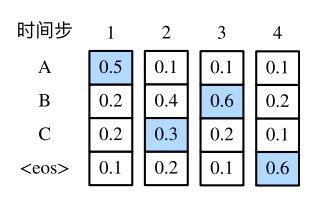
接下来,观察下面演⽰的例⼦。与上图中不同,在时间步2中选取了条件概率第⼆⼤的词“C”
。由于时间步3所基于的时间步1和2的输出⼦序列由上图中的“A”“B”变为了下图中的“A”“C”,下图中时间步3⽣成各个词的条件概率发⽣了变化。我们选取条件概率最⼤的词“B”。此时时间步4所基于的前3个时间步的输出⼦序列为“A”“C”“B”,与上图中的“A”“B”“C”不同。因此,下图中时间步4⽣成各个词的条件概率也与上图中的不同。我们发现,此时的输出序列“A”“C”“B”“
5.2 穷举搜索
如果⽬标是得到最优输出序列,我们可以考虑穷举搜索(exhaustive search):穷举所有可能的输出序列,输出条件概率最⼤的序列。
虽然穷举搜索可以得到最优输出序列,但它的计算开销 很容易过⼤。例如,当|Y| =
10000且T′ = 10时,我们将评估 个序列:这⼏乎不可能完成。而贪婪搜索的计
算开销是 ,通常显著小于穷举搜索的计算开销。例如,当|Y| = 10000且T′ = 10时,我
们只需评估 个序列。
5.3 束搜索
束搜索(beam search)是对贪婪搜索的⼀个改进算法。它有⼀个束宽(beam size)超参数。我们将它设为 k。在时间步 1 时,选取当前时间步条件概率最⼤的 k 个词,分别组成 k 个候选输出序列的⾸词。在之后的每个时间步,基于上个时间步的 k 个候选输出序列,从 k |Y| 个可能的输出序列中选取条件概率最⼤的 k 个,作为该时间步的候选输出序列。最终,我们从各个时间步的候选输出序列中筛选出包含特殊符号“
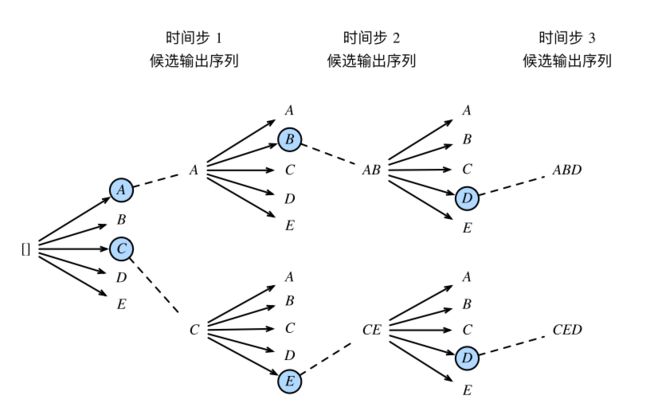
束宽为2,输出序列最⼤⻓度为3。候选输出序列有A、C、AB、CE、ABD和CED。我们将根据这6个序列得出最终候选输出序列的集合。在最终候选输出序列的集合中,我们取以下分数最⾼的序列作为输出序列:
其中 L 为最终候选序列⻓度,α ⼀般可选为0.75。分⺟上的 Lα 是为了惩罚较⻓序列在以上分数中较多的对数相加项。分析可知,束搜索的计算开销为 。这介于贪婪搜索和穷举搜索的计算开销之间。此外,贪婪搜索可看作是束宽为 1 的束搜索。束搜索通过灵活的束宽 k 来权衡计算开销和搜索质量。
6. Bleu得分
评价机器翻译结果通常使⽤BLEU(Bilingual Evaluation Understudy)(双语评估替补)。对于模型预测序列中任意的⼦序列,BLEU考察这个⼦序列是否出现在标签序列中。
具体来说,设词数为 n 的⼦序列的精度为 pn。它是预测序列与标签序列匹配词数为 n 的⼦序列的数量与预测序列中词数为 n 的⼦序列的数量之⽐。举个例⼦,假设标签序列为A、B、C、D、E、F,预测序列为A、B、B、C、D,那么:
预测序列一元词组:A/B/C/D,都在标签序列里存在,所以P1=4/5,以此类推,p2 = 3/4, p3 = 1/3, p4 = 0。设 分别为标签序列和预测序列的词数,那么,BLEU的定义为:
其中 k 是我们希望匹配的⼦序列的最⼤词数。可以看到当预测序列和标签序列完全⼀致时,
BLEU为1。
因为匹配较⻓⼦序列⽐匹配较短⼦序列更难,BLEU对匹配较⻓⼦序列的精度赋予了更⼤权重。例如,当 pn 固定在0.5时,随着n的增⼤,。另外,模型预测较短序列往往会得到较⾼pn 值。因此,上式中连乘项前⾯的系数是为了惩罚较短的输出而设的。举个例⼦,当k = 2时,假设标签序列为A、B、C、D、E、F,而预测序列为A、 B。虽然p1 = p2 = 1,但惩罚系数exp(1-6/2) ≈ 0.14,因此BLEU也接近0.14。
7. 代码实现
TensorFlow seq2seq的基本实现
【机器学习通俗易懂系列文章】

8. 参考文献
动手学深度学习
作者:@mantchs
GitHub:https://github.com/NLP-LOVE/ML-NLP
欢迎大家加入讨论!共同完善此项目!群号:【541954936】点击加入