这篇文章主要是讲述如何通过LDA处理文本内容TXT,并计算其文档主题分布,主要是核心代码为主。其中LDA入门知识介绍参考这篇文章,包括安装及用法:
[python] LDA处理文档主题分布代码入门笔记
1.输入输出
输入是test.txt文件,它是使用Jieba分词之后的文本内容,通常每行代表一篇文档。
该文本内容原自博客:文本分析之TFIDF/LDA/Word2vec实践 ,推荐大家去阅读。
新春 备 年货 , 新年 联欢晚会
新春 节目单 , 春节 联欢晚会 红火
大盘 下跌 股市 散户
下跌 股市 赚钱
金猴 新春 红火 新年
新车 新年 年货 新春
股市 反弹 下跌
股市 散户 赚钱
新年 , 看 春节 联欢晚会
大盘 下跌 散户
输出则是这十篇文档的主题分布,Shape(10L, 2L)表示10篇文档,2个主题。
具体结果如下所示:
shape: (10L, 2L)
doc: 0 topic: 0
doc: 1 topic: 0
doc: 2 topic: 1
doc: 3 topic: 1
doc: 4 topic: 0
doc: 5 topic: 0
doc: 6 topic: 1
doc: 7 topic: 1
doc: 8 topic: 0
doc: 9 topic: 1
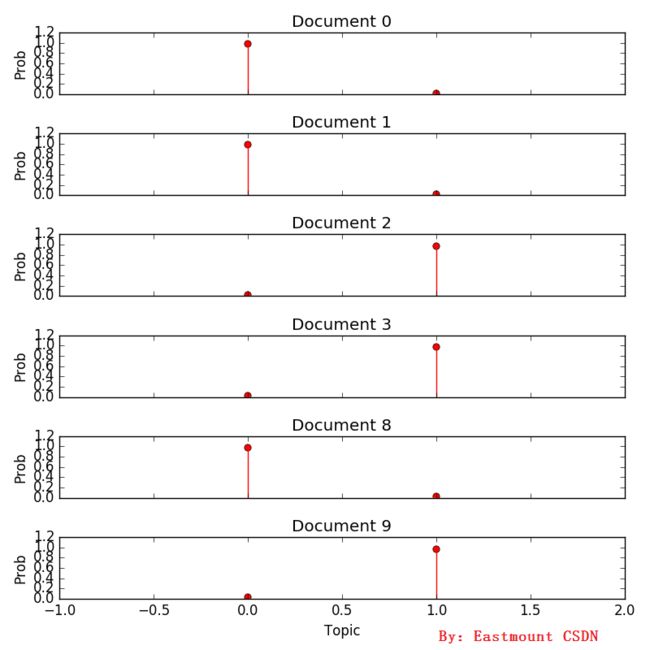
同时调用 matplotlib.pyplot 输出了对应的文档主题分布图,可以看到主题Doc0、Doc1、Doc8分布于Topic0,它们主要描述主题新春;而Doc2、Doc3、Doc9分布于Topic1,主要描述股市。
其过程中也会输出描述LDA运行的信息,如下图所示:
2.核心代码
其中核心代码如下图所示,包括读取文本、LDA运行、输出绘图等操作。
# coding=utf-8
import os
import sys
import numpy as np
import matplotlib
import scipy
import matplotlib.pyplot as plt
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import HashingVectorizer
if __name__ == "__main__":
#存储读取语料 一行预料为一个文档
corpus = []
for line in open('test.txt', 'r').readlines():
#print line
corpus.append(line.strip())
#print corpus
#将文本中的词语转换为词频矩阵 矩阵元素a[i][j] 表示j词在i类文本下的词频
vectorizer = CountVectorizer()
print vectorizer
X = vectorizer.fit_transform(corpus)
analyze = vectorizer.build_analyzer()
weight = X.toarray()
print len(weight)
print (weight[:5, :5])
#LDA算法
print 'LDA:'
import numpy as np
import lda
import lda.datasets
model = lda.LDA(n_topics=2, n_iter=500, random_state=1)
model.fit(np.asarray(weight)) # model.fit_transform(X) is also available
topic_word = model.topic_word_ # model.components_ also works
#文档-主题(Document-Topic)分布
doc_topic = model.doc_topic_
print("type(doc_topic): {}".format(type(doc_topic)))
print("shape: {}".format(doc_topic.shape))
#输出前10篇文章最可能的Topic
label = []
for n in range(10):
topic_most_pr = doc_topic[n].argmax()
label.append(topic_most_pr)
print("doc: {} topic: {}".format(n, topic_most_pr))
#计算文档主题分布图
import matplotlib.pyplot as plt
f, ax= plt.subplots(6, 1, figsize=(8, 8), sharex=True)
for i, k in enumerate([0, 1, 2, 3, 8, 9]):
ax[i].stem(doc_topic[k,:], linefmt='r-',
markerfmt='ro', basefmt='w-')
ax[i].set_xlim(-1, 2) #x坐标下标
ax[i].set_ylim(0, 1.2) #y坐标下标
ax[i].set_ylabel("Prob")
ax[i].set_title("Document {}".format(k))
ax[5].set_xlabel("Topic")
plt.tight_layout()
plt.show()
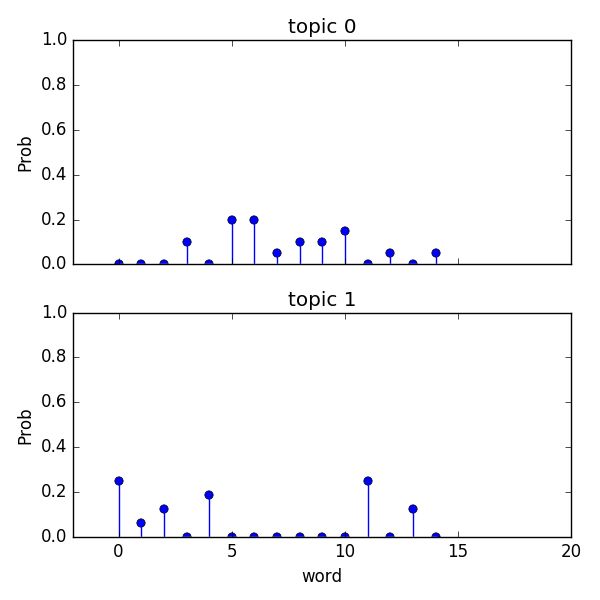
同时如果希望查询每个主题对应的问题词权重分布情况如下:
import matplotlib.pyplot as plt
f, ax= plt.subplots(2, 1, figsize=(6, 6), sharex=True)
for i, k in enumerate([0, 1]): #两个主题
ax[i].stem(topic_word[k,:], linefmt='b-',
markerfmt='bo', basefmt='w-')
ax[i].set_xlim(-2,20)
ax[i].set_ylim(0, 1)
ax[i].set_ylabel("Prob")
ax[i].set_title("topic {}".format(k))
ax[1].set_xlabel("word")
plt.tight_layout()
plt.show()
运行结果如下图所示:共2个主题Topics,15个核心词汇。
绘图推荐文章: http://blog.csdn.net/pipisorry/article/details/37742423
PS:讲到这里,整个完整的LDA算法就算结束了,你可以通过上面的代码进行LDA主题分布的计算,下面是一些问题。
3.TFIDF计算及词频TF计算
特征计算方法参考:Feature Extraction - scikit-learn
#计算TFIDF
corpus = []
#读取预料 一行预料为一个文档
for line in open('test.txt', 'r').readlines():
#print line
corpus.append(line.strip())
#print corpus
#将文本中的词语转换为词频矩阵 矩阵元素a[i][j] 表示j词在i类文本下的词频
vectorizer = CountVectorizer()
#该类会统计每个词语的tf-idf权值
transformer = TfidfTransformer()
#第一个fit_transform是计算tf-idf 第二个fit_transform是将文本转为词频矩阵
tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus))
#获取词袋模型中的所有词语
word = vectorizer.get_feature_names()
#将tf-idf矩阵抽取出来,元素w[i][j]表示j词在i类文本中的tf-idf权重
weight = tfidf.toarray()
#打印特征向量文本内容
print 'Features length: ' + str(len(word))
for j in range(len(word)):
print word[j]
#打印每类文本的tf-idf词语权重,第一个for遍历所有文本,第二个for便利某一类文本下的词语权重
for i in range(len(weight)):
for j in range(len(word)):
print weight[i][j],
print '\n'
输出如下图所示,共统计处特征词15个,对应TF-IDF矩阵,共10行数据对应txt文件中的10个文档,每个文档15维数据,存储TF-IDF权重,这就可以通过10*15的矩阵表示整个文档权重信息。
Features length: 15
下跌 反弹 大盘 年货 散户 新年 新春 新车 春节 红火 联欢晚会 股市 节目单 赚钱 金猴
0.0 0.0 0.0 0.579725686076 0.0 0.450929562568 0.450929562568 0.0 0.0 0.0 0.507191470855 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.356735384792 0.0 0.458627428458 0.458627428458 0.401244805261 0.0 0.539503693426 0.0 0.0
0.450929562568 0.0 0.579725686076 0.0 0.507191470855 0.0 0.0 0.0 0.0 0.0 0.0 0.450929562568 0.0 0.0 0.0
0.523221265036 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.523221265036 0.0 0.672665604612 0.0
0.0 0.0 0.0 0.0 0.0 0.410305398084 0.410305398084 0.0 0.0 0.52749830162 0.0 0.0 0.0 0.0 0.620519542315
0.0 0.0 0.0 0.52749830162 0.0 0.410305398084 0.410305398084 0.620519542315 0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.482964462575 0.730404446714 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.482964462575 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.568243852685 0.0 0.0 0.0 0.0 0.0 0.0 0.505209504985 0.0 0.649509260872 0.0
0.0 0.0 0.0 0.0 0.0 0.505209504985 0.0 0.0 0.649509260872 0.0 0.568243852685 0.0 0.0 0.0 0.0
0.505209504985 0.0 0.649509260872 0.0 0.568243852685 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
但是在将TF-IDF用于LDA算法model.fit(np.asarray(weight))时,总是报错如下:
TypeError: Cannot cast array data from dtype('float64') to dtype('int64') according to the rule 'safe'
所以后来LDA我采用的是统计词频的方法进行的,该段代码如下:
#存储读取语料 一行预料为一个文档
corpus = []
for line in open('test.txt', 'r').readlines():
#print line
corpus.append(line.strip())
#print corpus
#将文本中的词语转换为词频矩阵 矩阵元素a[i][j] 表示j词在i类文本下的词频
vectorizer = CountVectorizer()
#fit_transform是将文本转为词频矩阵
X = vectorizer.fit_transform(corpus)
#获取词袋模型中的所有词语
word = vectorizer.get_feature_names()
analyze = vectorizer.build_analyzer()
weight = X.toarray()
#打印特征向量文本内容
print 'Features length: ' + str(len(word))
for j in range(len(word)):
print word[j],
#打印每类文本词频矩阵
print 'TF Weight: '
for i in range(len(weight)):
for j in range(len(word)):
print weight[i][j],
print '\n'
print len(weight)
print (weight[:5, :5])
输出如下所示:
Features length: 15
下跌 反弹 大盘 年货 散户 新年 新春 新车 春节 红火 联欢晚会 股市 节目单 赚钱 金猴 TF Weight:
0 0 0 1 0 1 1 0 0 0 1 0 0 0 0
0 0 0 0 0 0 1 0 1 1 1 0 1 0 0
1 0 1 0 1 0 0 0 0 0 0 1 0 0 0
1 0 0 0 0 0 0 0 0 0 0 1 0 1 0
0 0 0 0 0 1 1 0 0 1 0 0 0 0 1
0 0 0 1 0 1 1 1 0 0 0 0 0 0 0
1 1 0 0 0 0 0 0 0 0 0 1 0 0 0
0 0 0 0 1 0 0 0 0 0 0 1 0 1 0
0 0 0 0 0 1 0 0 1 0 1 0 0 0 0
1 0 1 0 1 0 0 0 0 0 0 0 0 0 0
10
[[0 0 0 1 0]
[0 0 0 0 0]
[1 0 1 0 1]
[1 0 0 0 0]
[0 0 0 0 0]]
得到weight权重后,然后调用对应的算法即可执行不用的应用,如:
import lda
model = lda.LDA(n_topics=20, n_iter=500, random_state=1)
model.fit(np.asarray(weight))
from sklearn.cluster import KMeans
clf = KMeans(n_clusters=4) #景区 动物 人物 国家
s = clf.fit(weight)
4.百度互动主题分布例子
输入数据主要是前面讲述过的爬取百度百科、互动百科的景区、动物、人物、国家四类信息,具体如下所示:
输出如下所示,共12行数据,其中doc0 doc2主题分布为topic1,其主题表示景区;doc3doc5主题分布为topic3,其主题表示动物;doc6 doc8主题分布为topic0,其主题表示人物;doc9doc11主题分布为topic2,其主题表示国家。
shape: (12L, 4L)
doc: 0 topic: 1
doc: 1 topic: 1
doc: 2 topic: 1
doc: 3 topic: 3
doc: 4 topic: 3
doc: 5 topic: 3
doc: 6 topic: 0
doc: 7 topic: 0
doc: 8 topic: 0
doc: 9 topic: 2
doc: 10 topic: 2
doc: 11 topic: 2
5.计算主题TopN
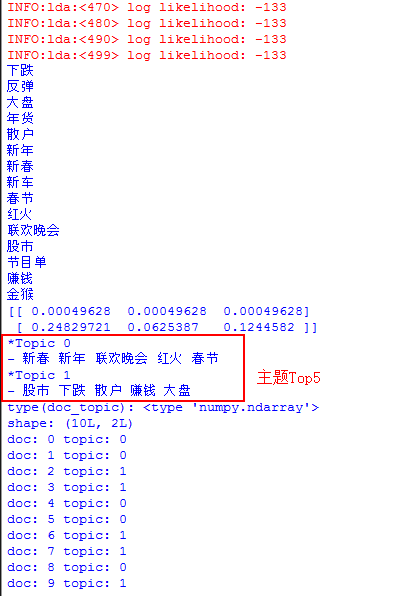
主要是回复读者的问题,如何计算主题的TopN关键词。核心代码如下:
#LDA算法
print 'LDA:'
import numpy as np
import lda
import lda.datasets
model = lda.LDA(n_topics=2, n_iter=500, random_state=1)
model.fit(np.asarray(weight)) # model.fit_transform(X) is also available
topic_word = model.topic_word_ # model.components_ also works
#输出主题中的TopN关键词
word = vectorizer.get_feature_names()
for w in word:
print w
print topic_word[:, :3]
n = 5
for i, topic_dist in enumerate(topic_word):
topic_words = np.array(word)[np.argsort(topic_dist)][:-(n+1):-1]
print(u'*Topic {}\n- {}'.format(i, ' '.join(topic_words)))
#文档-主题(Document-Topic)分布
doc_topic = model.doc_topic_
print("type(doc_topic): {}".format(type(doc_topic)))
print("shape: {}".format(doc_topic.shape))
通过word = vectorizer.get_feature_names()获取整个预料的词向量,其中TF-IDF对应的就是它的值。然后再获取其位置对应的关键词即可,代码中输出5个关键词,如下图所示:
讲到此处你也应该理解了LDA的基本用法和适用场景,你可以通过它进行新闻主题分布,同时再进行引文推荐、聚类算法等操作。