1. Storm介绍:
Storm是实时流计算框架。企业中典型实时分析框架搭建模式: Flume + Kafka + Storm + Hbase ,对这类要求分析结果能妙级甚至毫秒级反馈的场景,需要用专门的实时分析框架,例如Storm和Spark Streaming。
最初由BackType公司研发出来,2011年7月被Twitter公司收购,Twitter公司将Storm应用到他们的海量数据实时处理上。Storm核心部分是由Clojure语言编写的,Clojure是面向函数式编程语言,运行在JVM上。阿里将Storm核心部分用java改写,同时对原先Storm性能不好的地方做了优化,这就是JStorm,目前Strom和JStorm都由Apache来维护。
1. 使用场景:
1.信息流的实时处理:例如实时抓拍汽车行车速度,计算判断是否超速并实时处罚。
2.实时日志分析
3.分布式RPC(远程过程调用) DRPC: 查询请求 --> storm处理 -->实时返回结果。
2.特性
1.分布式框架。
2.可靠性高、容错性高。
3.计算结果可靠:消息可靠性保障机制。
4.性能高、处理速度快。为了提高性能,可以不使用storm的消息可靠性保障机制。
3.与hadoop的区别和联系
Storm并不属于Hadoop生态系统的框架。MapReduce是离线数据分析,批次处理数据,数据处理完成后程序就会终止;Storm是实时数据分析,任务提交后会一直循环运行。
Storm其实也可以进行批量处理数据,但是不会这么用,可以读取HDFS上的文件,一行一行处理,直到文件处理结束。
2. Storm架构:
Storm是Master-Slaves 主从架构(与hadoop等一致)。主节点是Nimbus,从节点是Supervisor。主节点和从节点借助Zookeeper集群来沟通。
Storm集群的各个组件本身都是无状态的(不保存状态信息),例如nimbus、supervisor、worker等,所有的状态信息都保存在zookeeper集群中。这样的话,集群的可靠性非常高,某个Nimbus(或者Supervisor)宕机后,只需要重启一个Nimbus节点(或者Supervisor节点),再从Zookeeper集群中读取状态信息就可以了。
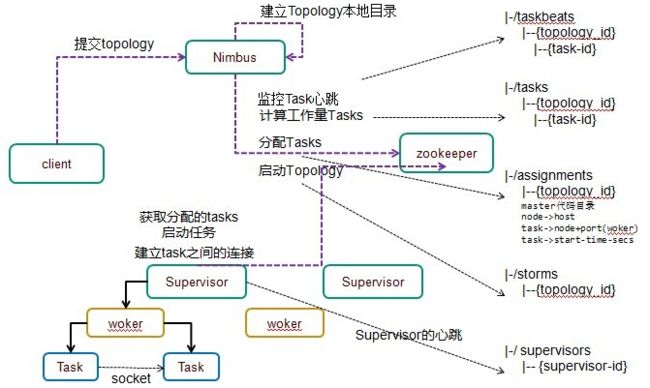
1.Nimbus主节点:
1.监控从节点Supervisor的状态:Supervisor启动和运行过程中会定时将心跳状态信息发送到Zookeeper上,也就是在Zookeeper集群上创建Znode节点,Nimbus监听该Znode节点来监控Supervisor节点的状态。
2.接收客户端任务的提交Topology
3.进行任务代码的分发、任务Task的分配协调,异常任务的重新分配。
2.Supervisor从节点:
Supervisor是真正的工作节点。Supervisor接收到任务分配后,启动Worker节点(一个或者多个)。
1.获取任务:Nimbus分配任务的时候,将任务信息发送到Zookeeper上,Supervisor监听相应的Znode节点信息,拿到分配给他的任务。
2.获取到任务后,启动相应的Worker进程,Worker进程数根据具体的Topology来决定的,之后监控Worker进程状态(Worker进程启动好之后,在运行过程中也会将心跳状态信息发送到zookeeper上,supervisor也是通过监听znode节点信息来监控worker进程的)
3.Worker进程(JVM):
Worker进程不是常驻进程(Nimbus和Supervisor是Storm框架的常驻进程),并且跟具体的Topology相关。Worker进程上具体运行相应的Topology的Task任务。
Worker进程启动Executor线程。Task运行时真正地跑在线程上,Executor线程真正执行Task。
4.Zookeeper集群:
用来存储各节点、各组件的状态信息。
5.topology任务执行整体流程:
Client端向Storm集群提交Topology程序,Nimbus接收到Topology程序后进行任务分配,将执行代码以及相关的配置信息分发到各个Supervisor上(注意,这里不通过zookeeper集群。通过Thrift直接分发到Supervisor节点。)。将任务分配信息发送到Zookeeper集群上,Supervisor从Zookeeper上获取相应的任务,根据任务的要求启动Worker进程,Worker进程启动后,Worker进程会启动一些Executor线程(也是根据任务的要求启动)。Executor线程才是最终真正执行Task逻辑的组件。
3. Storm集群环境搭建:
集群环境的搭建,需要根据官网文档指导,选用的版本是比较稳定的0.9.6版本。官网文档:http://storm.apache.org/releases/0.9.6/Setting-up-a-Storm-cluster.html
1.创建zookeeper集群;
2.在Nimbus和worker机器上安装前置依赖(java和Python);
3.在Nimbus和worker机器上下载和解压Strom安装包;
4.在配置文件storm.yaml中增加必要配置;
5.启动Storm进程。
前置安装内容:网络、IP、主机名、主机名和IP的映射关系、免密码登陆、zookeeper集群、JDK、Python安装。
1. 搭建Zookeeper集群:
Zookeeper集群的搭建方法,前面文章已有介绍。在zookeeper配置中需要做些修改,删掉以下两项的注释:
autopurge.snapRetainCount=3
autopurge.purgeInterval=1
$ scp /opt/modules/zookeeper-3.4.5-cdh5.3.6/conf/zoo.cfg [email protected]:/opt/modules/zookeeper-3.4.5-cdh5.3.6/conf/
autopurge.snapRetainCount是Zookeeper的快照的保存的配置,如果不开启此项,zookeeper的快照会很快占用很大的空间。自动合并,每隔1小时自动合并zookeeper上的数据,相当于日志清理。
Zookeeper的批量启动脚本:
#!/bin/bash
if [ $# -ne 1 ]
then
echo "Useage: sh zkServer_batch.sh [start|status|stop]"
exit 2
fi
for node in 192.168.8.128 192.168.8.129 192.168.8.130
do
echo "$1 in $node"
ssh $node "source /etc/profile && /opt/modules/zookeeper-3.4.5-cdh5.3.6/bin/zkServer.sh $1"
done
免密登陆,telnet XXX:3888 如何开通3888端口的访问。
2. 安装Storm集群:
1.检查python的版本,一般情况下CentOS都会安装python。对于该版本storm,python不能是3.x版本,必须是2.x版本。
$ python --version
2.下载并解压storm release文件:
$ tar zxf apache-storm-0.9.6.tar.gz -C /opt/modules/
3.修改配置文件conf/storm.yaml:
storm.zookeeper.servers:
- "hadoop-senior01.pmpa.com"
- "hadoop-senior02.pmpa.com"
- "hadoop-senior03.pmpa.com"
nimbus.host: "hadoop-senior01.pmpa.com"
storm.local.dir: "/opt/modules/apache-storm-0.9.6/local"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
- 6704
ui.port: 8081
默认日志会写到根目录下:
01:13:54,021 |-ERROR in ch.qos.logback.core.rolling.RollingFileAppender[A1] - openFile(/nimbus.log,true) call failed. java.io.FileNotFoundException: /nimbus.log (Permission denied)
启动Storm 的 nimbus和 supervisor:
$ bin/storm nimbus > ./logs/nimbus.out 2>&1 &
$ bin/storm supervisor > ./logs/supervisor.out 2>&1 &
启动UI:
$ bin/storm ui > ./logs/ui.out 2>&1 &
测试提交topology:
$ bin/storm jar examples/storm-starter/storm-starter-topologies-0.9.6.jar storm.starter.WordCountTopology wordcount
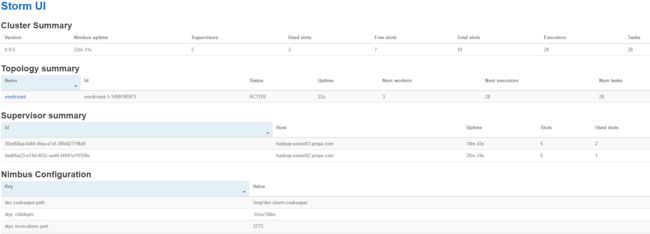
4. Storm集群启停脚本:
Nimbus topology任务提交后,程序是运行在supervisor节点上,nimbus不参与程序的运行。
如果nimbus出现故障,不能提交topology,但是已经提交了的topology还是正常运行在集群上的。已经运行在集群上的topology,如果这时候某些task出现异常则无法重新分配节点。
1.查看topology的日志:
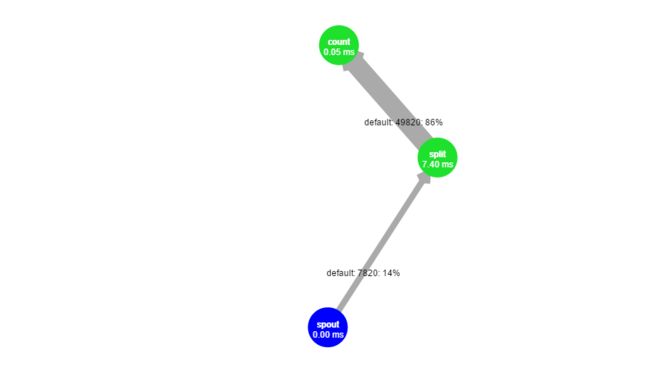
上边我们启动了例子的wordcount topology,如下图:
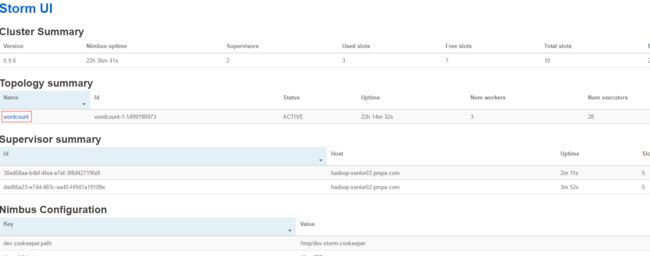
为了查看Topology(wordcount)的运行日志, 需要启动进程logviewer,需要在 每个supervisor节点上启动,不用在nimbus节点启动。
$ bin/storm logviewer > ./logs/logviewer.out 2>&1 &
在supervisor上启动了logviewer后,就可以在Storm UI界面上查看wordcount的日志了。在ui界面上点击“wordcount”(topology名称)。
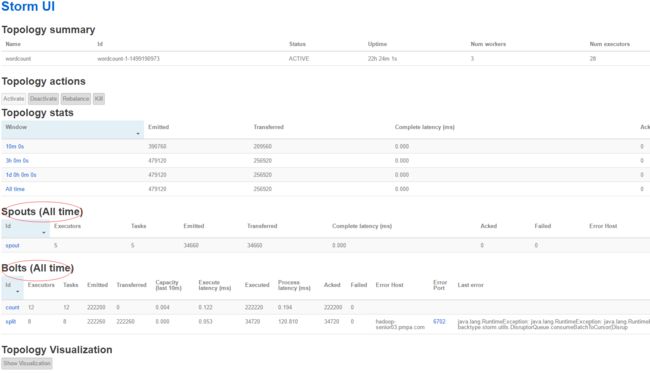
上边可以看到topology的组件 Spouts、Bolts等等。
2.停止Topology:
1.可以在ui界面上停止topology:

Activate : 激活
Deactivate :暂停
Rebalance : 当动态添加了一个Supervisor节点,想要让Topology部分任务能使用该新增的Supervisor,那就可以通过Rebalance实现。
Kill : 将Topology从Storm集群上移除。
2.通过命令行停止:
可以使用下命令kill掉topology:
$ bin/storm kill wordcount
其中wordcount是你启动topology时,所指定的名称。
3.在Zookeeper查看存储的Storm节点信息:
为了查看zookeeper存储的节点信息,需要打开zookeeper的客户端。选择任何一个zookeeper节点,执行命令:
$ bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 1] ls /
[storm, hbase, zookeeper]
[zk: localhost:2181(CONNECTED) 2] ls /storm
[workerbeats, errors, supervisors, storms, assignments]
在zookeeper的根节点下,有个Storm子节点。也就是,在zookeeper中有一个storm Znode,而在storm Znode下有5个子Znode:workerbeats, errors, supervisors, storms, assignments。
/workerbeats : worker的心跳信息;
/errors : topology运行过程中Task运行异常信息(Task在哪个Supervisor上运行失败的,nimbus需要对异常任务重新分配);
/supervisors :记录supervisor状态心跳信息;
/storms :记录topology任务信息(哪个jar包,jar包位置等)
/assignments :记录的是topology任务的分配信息。
4.storm的nimubs、supervisor、ui、logviewer进程的关闭:
不像Hadoop,Storm没有提供这些进程的stop脚本。可以通过kill -9 方式来关闭这些进程。查看进程pid的方式:
$ ps -ef | grep daemon.nimbus | awk '{print $2}' | head -n 1
在关闭进程前,一定记得先要关闭topology。 下面脚本(在主节点上执行)完成storm的批量启停。
5.storm的批量启动脚本:
先创建一个文件,来保存supervisor节点的主机名,supervisor_cluster.conf :
hadoop-senior02.pmpa.com
hadoop-senior03.pmpa.com
Storm批量启动脚本,start_storm.sh
#!/bin/bash
source /etc/profile
STROM_HOME=/opt/modules/apache-storm-0.9.6
##主节点:启动nimubs和ui
${STORM_HOME}/bin/storm nimbus > /dev/null 2>&1 &
${STORM_HOME}/bin/storm ui > /dev/null 2>&1 &
##从节点,启动supervisor和logviewer:
for supervisor in `cat supervisor_cluster.conf`
do
ssh ${supervisor} "source /etc/profile && ${STORM_HOME}/bin/storm supervisor> /dev/null 2>&1 &" &
ssh ${supervisor} "source /etc/profile && ${STORM_HOME}/bin/storm logviewer> /dev/null 2>&1 &" &
done
6.storm的批量停止脚本:
在执行该脚本之前,必须要保证所有的topology关闭。storm的关闭需要杀掉nimbus和supervisor上的所有的进程。
#!/bin/bash
# author: natty date:2017-08-22
# Storm batch close. Kill these processes: nimubs,supervisor,ui,logviewer
source /etc/profile
kill -9 `ps -ef | grep nimbus.daemon | awk '{print $2}'`
kill -9 `ps -ef | grep ui.daemon | awk '{print $2}'`
for supervisor in `cat supervisor_cluster.conf`
do
ssh ${supervisor} "source /etc/profile && kill -9 `ps -ef | grep supervisor.daemon | awk '{print $2}'`" &
ssh ${supervisor} "source /etc/profile && kill -9 `ps -ef | grep logviewer.daemon | awk '{print $2}'`" &
done