一、HDFS是什么
源自于Google的GFS论文
发表于2003年10月
HDFS是GFS克隆版
Hadoop Distributed File System
易于扩展的分布式文件系统
运行在大量普通廉价机器上,提供容错机制
为大量用户提供性能不错的文件存取服务
1、HDFS优点
高容错性
数据自动保存多个副本
副本丢失后,自动恢复
适合批处理
移动计算而非数据
数据位置暴露给计算框架
适合大数据处理
GB、TB、甚至PB级数据
百万规模以上的文件数量
10K+节点规模
流式文件访问
一次性写入,多次读取
保证数据一致性
可构建在廉价机器上
通过多副本提高可靠性
提供了容错和恢复机制
2、HDFS缺点
低延迟数据访问
比如毫秒级
低延迟与高吞吐率
小文件存取
占用NameNode大量内存
寻道时间超过读取时间
并发写入、文件随机修改
一个文件只能有一个写者
仅支持append
3、HDFS设计思想
请点击此处输入图片描述

请点击此处输入图片描述
请点击此处输入图片描述
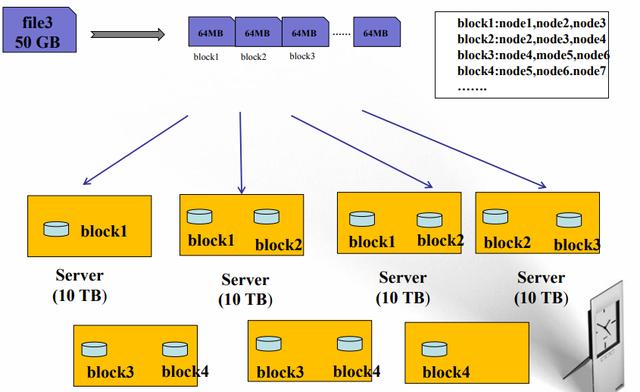
4、HDFS数据块(block)
文件被切分成固定大小的数据块
默认数据块大小为64MB,可配置
若文件大小不到64MB,则单独存成一个block
为何数据块如此之大
数据传输时间超过寻道时间(高吞吐率)
一个文件存储方式
按大小被切分成若干个block,存储到不同节点上
默认情况下每个block有三个副本
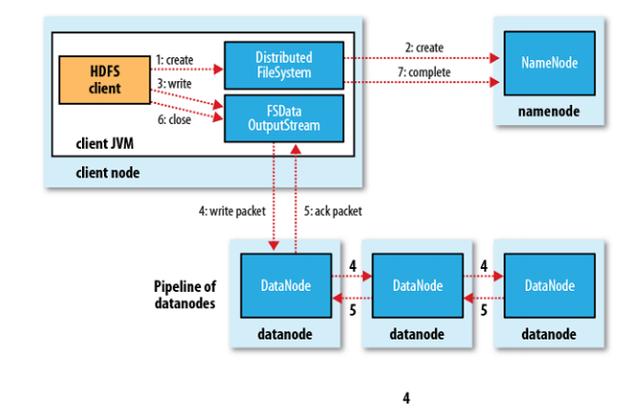
5、HDFS写流程
请点击此处输入图片描述
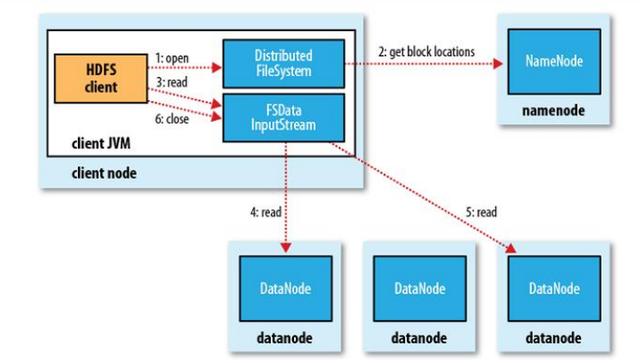
6、HDFS读流程
请点击此处输入图片描述
7、HDFS典型物理拓扑
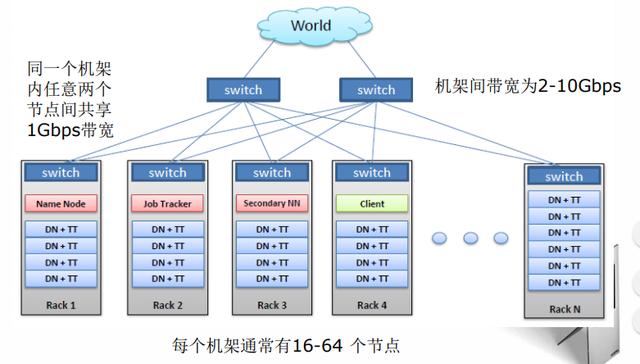
请点击此处输入图片描述
8、HDFS副本放置策略
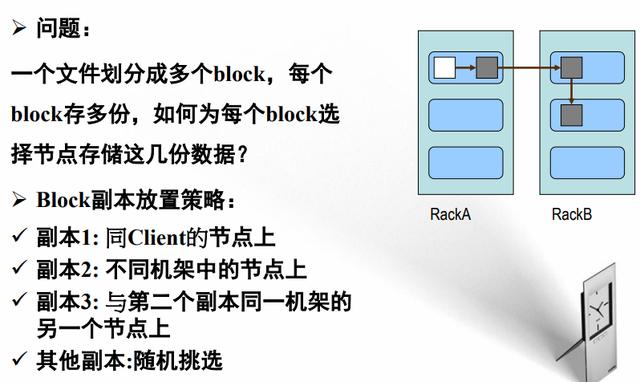
请点击此处输入图片描述
9、HDFS可靠性策略
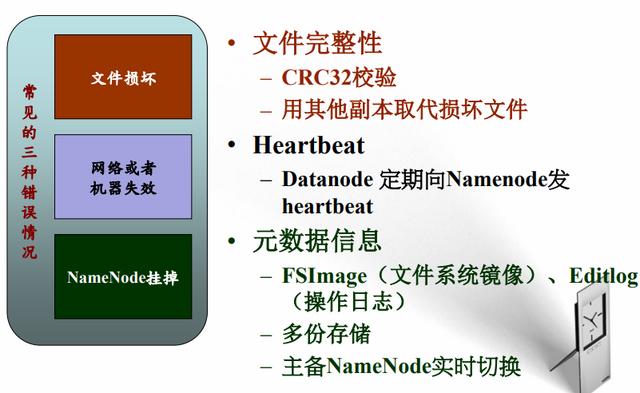
请点击此处输入图片描述
10、HDFS不适合存储小文件
元信息存储在NameNode内存中
一个节点的内存是有限的
存取大量小文件消耗大量的寻道时间
类比拷贝大量小文件与拷贝同等大小的一个大文件
NameNode存储block数目是有限的
一个block元信息消耗大约150 byte内存
存储1亿个block,大约需要20GB内存
如果一个文件大小为10K,则1亿个文件大小仅为1TB(但要消耗掉NameNode 20GB内存)
二、HDFS访问方式
HDFS Shell命令
HDFS Java API
HDFS REST API
HDFS Fuse:实现了fuse协议
HDFS lib hdfs:C/C++访问接口
HDFS 其他语言编程API
使用thrift实现 ** 支持C++、Python、php、C#等语言
HDFS Shell命令—概览
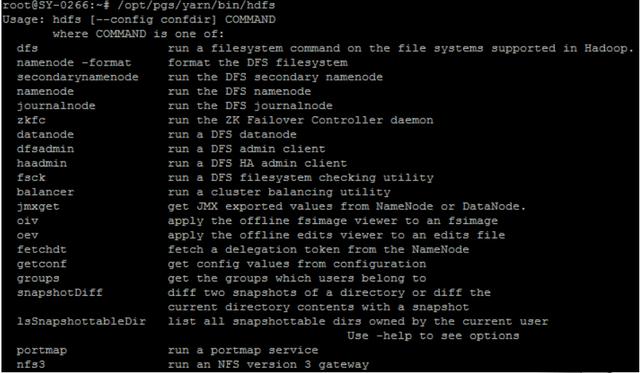
请点击此处输入图片描述
将本地文件上传到HDFS上
bin/hadoop fs -copyFromLocal /local/data /hdfs/data
删除文件/目录
bin/hadoop fs -rmr /hdfs/data
创建目录
bin/hadoop fs -mkdir /hdfs/data
HDFS Shell命令—管理脚本
bin/hadoop dfsadmin
在sbin目录下
start-all.sh
start-dfs.sh
start-yarn.sh
hadoop-deamon(s).sh
单独启动某个服务
hadoop-deamon.sh start namenode
hadoop-deamons.sh start namenode(通过SSH登录到各个节点)
HDFS Shell命令—文件管理命令fsck
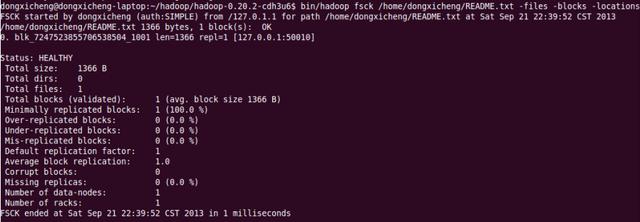
请点击此处输入图片描述
检查hdfs中文件的健康状况
查找缺失的块以及过少或过多副本的块
查看一个文件的所有数据块位置
删除损坏的数据块
HDFS Shell命令—数据均衡器balancer
数据块重分布
bin/start-balancer.sh -threshold
percentage of disk capacity
HDFS达到平衡状态的磁盘使用率偏差值
值越低各节点越平衡,但消耗时间也更长
HDFS Shell命令—设置目录份额
限制一个目录最多使用磁盘空间
bin/hadoop dfsadmin -setSpaceQuota 1t /user/username
限制一个目录包含的最多子目录和文件数目
bin/hadoop dfsadmin -setQuota 10000 /user/username
HDFS Shell命令—增加/移除节点

请点击此处输入图片描述
三、HDFS Java API介绍
Configuration类:该类的对象封装了配置信息,这些配置信息来自core-.xml;
FileSystem类:文件系统类,可使用该类的方法对文件/目录进行操作。一般通过FileSystem的静态方法 get获得一个文件系统对象;
FSDataInputStream和FSDataOutputStream类:HDFS中的输入输出流。分别通过FileSystem的open方法和create方法获得。 以上类均来自java包:org.apache.hadoop.fs
HDFS Java程序举例
将本地文件拷贝到HDFS上
Configuration config = new Configuration();
FileSystem hdfs = FileSystem.get(config);
Path srcPath = new Path(srcFile);
Path dstPath = new Path(dstFile);
hdfs.copyFromLocalFile(srcPath, dstPath);
创建HDFS文件;
//byte[] buff – 文件内容
Configuration config = new Configuration();
FileSystem hdfs = FileSystem.get(config);
Path path = new Path(fileName);
FSDataOutputStream outputStream = hdfs.create(path);
outputStream.write(buff, 0, buff.length);
四、Hadoop 2.0新特性
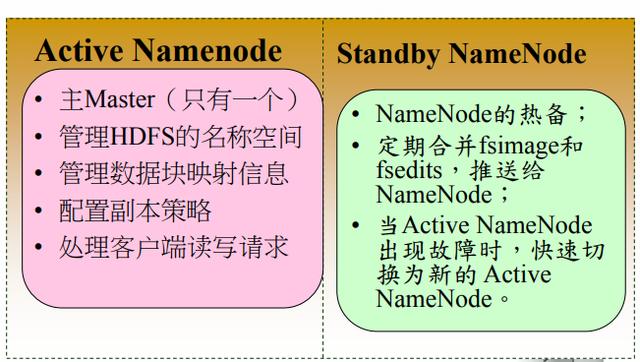
NameNode HA
NameNode Federation
HDFS 快照(snapshot)
HDFS 缓存(in-memory cache)
HDFS ACL
异构层级存储结构(Heterogeneous Storage hierarchy)
1、HA与Federation
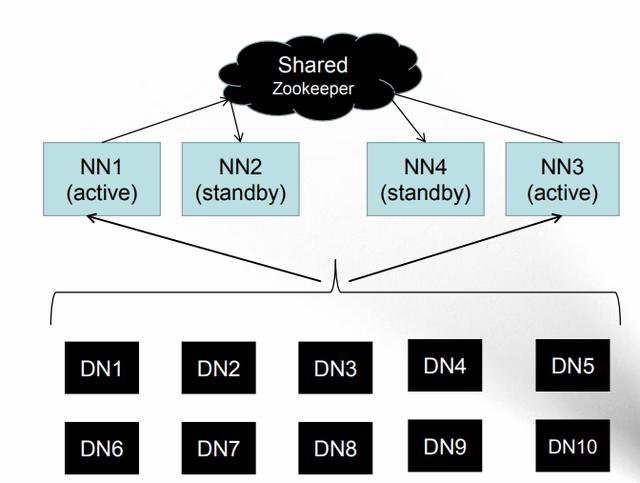
请点击此处输入图片描述
2、异构层级存储结构—背景
HDFS将所有存储介质抽象成性能相同的Disk
dfs.datanode.data.dir
/dir0,/dir1,/dir2,/dir3
存储介质种类繁多,一个集群中存在多种异构介质
磁盘、SSD、RAM等
多种类型的任务企图同时运行在同一个Hadoop集群中
批处理,交互式处理,实时处理
不同性能要求的数据,最好存储在不同类别的存储介质上
3、异构层级存储结构—原理
dfs.datanode.data.dir
[disk]/dir0,[disk]/dir1,[ssd]/dir2,[ssd]/dir3
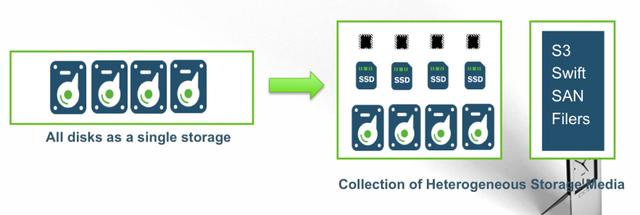
请点击此处输入图片描述
4、异构层级存储结构—原理
HDFS仅提供了一种异构存储结构,并不知道存储介质的性能;
HDFS为用户提供了API,以控制目录/文件写到什么介质上;
HDFS为管理员提供了管理工具,可限制每个用户对每种介质的可使用份额;
目前完成度不高
阶段1:DataNode支持异构存储介质(HDFS-2832,完成)
阶段2:为用户提供访问API(HDFS-5682,未完成)
五、HDFS ACL—基于POSIX ACL的实现

请点击此处输入图片描述
六、HDFS快照—背景
HDFS上文件和目录是不断变化的,快照可以帮助用户保存某个时刻的数据;
HDFS快照的作用
防止用户误操作删除数据
数据备份
HDFS快照—基本使用方法

请点击此处输入图片描述
七、HDFS缓存
HDFS自身不提供数据缓存功能,而是使用OS缓存容易内存浪费,eg.一个block三个副本同时被缓存
多种计算框架共存,均将HDFS作为共享存储系统
MapReduce:离线计算,充分利用磁盘
Impala:低延迟计算,充分利用内存
Spark:内存计算框架
HDFS应让多种混合计算类型共存一个集群中
合理的使用内存、磁盘等资源
比如,高频访问的特点文件应被尽可能长期缓存,防止置换到磁盘上
HDFS缓存—原理
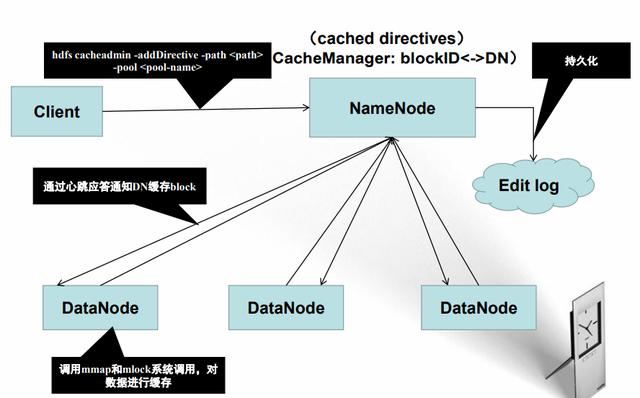
请点击此处输入图片描述
HDFS缓存—实现情况
用户需通过命令显式的将一个目录或文件加入/移除缓存
不支持块级别的缓存
不支持自动化缓存
可设置缓存失效时间
缓存目录:仅对一级文件进行缓存
不会递归缓存所有文件与目录
以pool的形式组织缓存资源
借助YARN的资源管理方式,将缓存划分到不同pool中
每个pool有类linux权限管理机制、缓存上限、失效时间等
独立管理内存,未与资源管理系统YARN集成
用户可为每个DN设置缓存大小,该值独立于YARN
长按识别关注我们,每天都有精彩技术内容分享哦 ~ ~
