一、摘要
为了解决协同过滤的稀疏性和冷启动问题,社交网络或项目属性等辅助信息被用来提高推荐性能。
考虑到知识图谱是边信息的来源,为了解决现有的基于嵌入和基于路径的知识图谱感知重构方法的局限性,本文提出了一种端到端框架,它自然地将知识图结合到推荐系统中。
与水上传播的实际涟漪类似,RippleNet通过在知识图谱实体集上传播用户兴趣,从而自主迭代地沿着知识图谱中的链接来扩展用户的潜在兴趣。
因此,由用户的历史点击项激活的多个“涟漪”被叠加以形成用户相对于候选项目的偏好分布,该偏好分布可用于预测最终点击概率。
通过在真实世界数据集上的大量实验,本文证明RippleNet在各种场景(包括电影、书籍和新闻推荐)中都能在多个最先进的基线上获得实质性的效果。
ripple net :
ripple:波纹,是你往水里面扔石头产生的。
石头就是波纹的中心,也就是RS中的用户历史点击矩阵。
被激起的波纹就对应了知识图谱一个又一个的实体。
由用户的历史纪录激起的水波,就是用户潜在感兴趣的item
除此之外波纹还有一个特点,它会随着层数的变大而逐渐衰减,这里类比到ripplenet也是同样的。
二、引言
背景:
推荐系统(Recommender systems,RS)旨在通过为用户寻找一组满足其个性化兴趣的小商品来弥补信息爆炸带来的负面影响。
在推荐策略中,协作过滤(CF)考虑了用户的历史交互,并根据用户潜在的共同偏好进行推荐,取得了巨大的成功。然而,基于CF的方法通常存在用户-项目交互的稀疏性和冷启动问题。为了解决这些局限性,研究人员提出了将侧边信息整合到CF中,如社交网络、用户/项目属性、图像和上下文。
在各种类型的边信息中,知识图谱(KG)通常包含更多关于项目的有成效的事实和联系。KG是一种有向异构图,其中节点对应于实体,边对应于关系。最近,研究人员提出了一些学术KG,如NELL1、DBpedia2和商业KG,如Google Knowledge Graph和Microsoft Satori。这些知识图已成功地应用于许多应用中,如KG构建、问答、单词嵌入和文本分类。
KG用在推荐的好处:
(1)准确性。KG引入了项目之间的语义关联性,有助于发现它们之间潜在的联系,提高推荐项目的精度;
(2)多样性。由各种类型的关系组成,有助于合理地维护用户的利益,增加推荐项目的多样性;
(3)可解释性。KG将用户的历史记录与推荐项目联系起来,从而为推荐系统带来可解释性。
现有的KG结合推荐可分为两类:
第一类是基于embedding的方法,它使用知识图嵌入(KGE)预处理KG,并将学习到的实体嵌入合并到推荐框架中。
例如,深度知识感知网络(Deep Knowledge aware Network,DKN)将实体embedding和单词embedding作为不同的通道,然后设计一个CNN框架将它们结合起来进行新闻推荐。
协同知识库嵌入(CKE)在统一的贝叶斯框架中将CF模块与知识embedding、文本embedding和项目图像embedding相结合。
签名异构信息网络嵌入(SHINE)设计深度自动编码器,嵌入情感网络、社交网络和个人资料(知识)网络,用于名人推荐。
基于嵌入的方法在利用KG来辅助推荐系统方面显示出高度灵活性,但是在这些方法中采用的KGE算法通常更适合于诸如链接预测之类的图形应用,而不是推荐。
第二类是基于路径的方法,它揭示了以KG为单位的项目之间的各种连接模式,为建议提供额外的指导。
例如,个性化实体推荐(PER)和基于元图的推荐将KG视为异构信息网络(HIN),并提取基于元路径/元图的潜在特征,以表示用户和项目之间沿着不同类型的关系路径/图的连接。
基于路径的方法以更自然和直观的方式使用KG,但它们严重依赖于手动设计的元路径,这在实践中很难优化。另一个问题是,在某些实体和关系不在一个域中的场景(例如,新闻推荐)中,不可能设计手工创建的元路径。
ripple net :
RippleNet是为点击率(CTR)预测而设计的,
输入:用户项目对
输出:用户参与(如点击、浏览)项目的概率。
关键思想:偏好传播。
对于每个用户,RippleNet将其历史兴趣视为KG中的种子集,然后沿着KG链接迭代扩展用户兴趣,以发现其与候选项相关的层次潜在兴趣。
我们将偏好传播与雨滴在水面上传播所产生的实际涟漪进行类比,其中多个“涟漪”叠加在一起,形成用户对知识图的偏好分布。
RippleNet与现有文献的主要区别在于RippleNet结合了上述两种方法的优点:(1)RippleNet通过偏好传播自然地将KGE方法融入到推荐中;(2)RippleNet可以自动发现从用户历史记录中的项目到候选项目的可能路径,而无需任何手工设计。
实验:
根据经验,我们将RippleNet应用于电影、书籍和新闻推荐的三个真实场景。实验结果表明,与最新的推荐基线相比,RippleNet在电影、书籍和新闻推荐中的AUC分别提高了2.0%-40.6%、2.5%-17.4%和2.6%-22.4%。我们还发现,RippleNet根据知识图为推荐的结果提供了一种新的解释方法。
三、问题描述
前提介绍:
在典型的推荐系统中,让U={u1,u2,…}和V={v1,v2,…}分别表示用户和项目的集合。用户项目交互矩阵![]() 根据用户的隐含反馈定义(例如点击、观看、浏览等行为),其中
根据用户的隐含反馈定义(例如点击、观看、浏览等行为),其中

除了交互矩阵Y之外,还有一个知识G,它由实体-大量关系-实体三元组(h、r、t)组成。
其中,![]() ,表示三元组的头、关系、尾。
,表示三元组的头、关系、尾。![]() 表示实体,
表示实体,![]() 表示关系。
表示关系。
例如,三元组(Jurassic Park,film.director,Steven Spielberg):史蒂芬·斯皮尔伯格(Steven Spielberg)是电影《侏罗纪公园》(Jurassic Park)的导演。
在许多推荐场景中,一个项目v可能与G中的一个或多个实体关联。
例如,电影《侏罗纪公园》与其同名的KG关联,而标题为“法国熊猫宝宝首次公开亮相”的新闻则与实体“法国”和“熊猫”关联。
问题定义:
给定交互矩阵Y和知识图G,目的是预测用户u是否对之前没有交互的项目v有潜在兴趣。我们的目标是学习一个预测函数![]() ,其中yˆuv表示用户u单击项目v的概率,而Θ表示函数F的模型参数。
,其中yˆuv表示用户u单击项目v的概率,而Θ表示函数F的模型参数。
四、RippleNet
1、RippleNet框架:
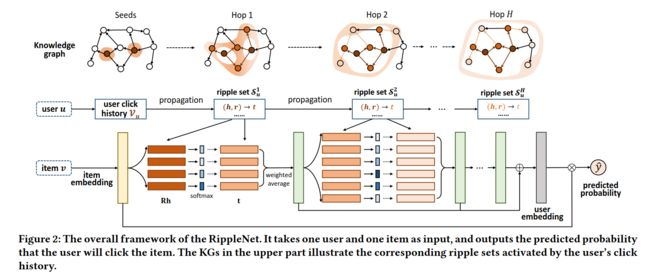
RippleNet将用户u和项目v作为输入,并输出用户u单击项目v的预测概率。
对于输入用户u,其历史兴趣集Vu被视为KG中的种子,然后沿链接扩展以形成多个ripple集Suk(k=1、2、…、H)。
ripple集Suk是远离种子集Vu的k-hop的知识三元组集。这些ripple集用于迭代地与项目嵌入(黄色块)交互,以获得用户u对项目v(绿色块)的响应,然后组合这些响应以形成最终用户嵌入(灰色块)。
最后,利用用户u和项目v的嵌入来计算预测概率yˆuv。
2、Ripple Set
知识图谱通常包含丰富的事实和实体之间的联系。
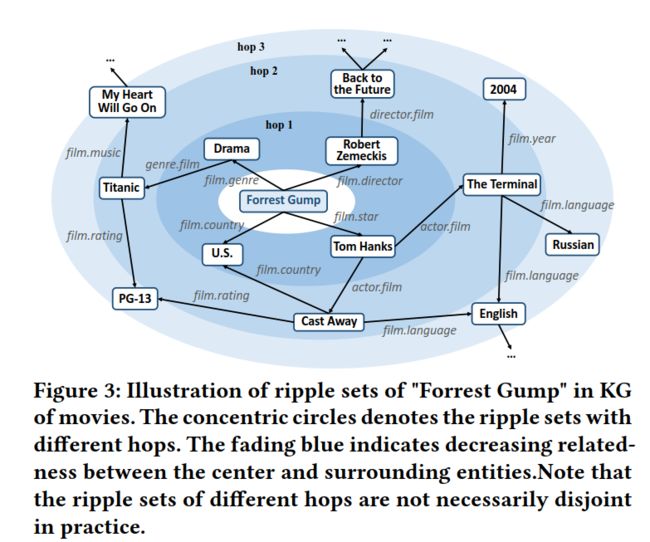
例如,如图3所示,电影《Forrest Gump》与“Robert Zemeckis”(导演)、“Tom Hanks”(明星)、“U.S.”(乡村)和“Drama”(流派)联系在一起,而Tom Hanks则与他主演的电影《The Terminal》和《Cast Away》进一步联系在一起。
这些复杂的KG连接为我们提供了一个深入和潜在的视角来探索用户偏好。
例如,如果用户曾经看过《Forrest Gump》,他可能会成为Tom Hanks的粉丝,对《The Terminal》或《Cast Away》感兴趣。
为了用KG来描述用户的层次扩展偏好,在RippleNet中,我们递归地为用户u定义了一组与k-hop相关的实体,如下所示:
定义1(相关实体)。给定交互矩阵Y和知识图G,用户u的k跳相关实体集定义为
![]()
其中,![]() 是用户过去点击项目集合,即KG中的种子集(seed)。
是用户过去点击项目集合,即KG中的种子集(seed)。
定义2(波纹集)。用户u的k跳Ripple集定义为从![]() 开始的知识三元组:
开始的知识三元组:
![]()
ripple可能存在的问题:随着跳数K的增加,圈子大小可能会变得很大。
解决:
(1)一个KG大量实体没有出度,只有出度。【如图3中的“2004”和“PG-13”实体】
(2)在电影或书籍推荐等特定推荐场景中,可以将关系限制在与场景相关的类别中来减小ripple集大小并提高实体之间的相关性。如图3中,所有关系都与电影相关,并且他们的名称中包含单词“film”
(3)在实践中,最大跳频h的数目通常不太大,因为离用户历史太远的实体可能带来比正信号更多的噪声。在实验部分我们将讨论H的选择。
(4)在RippleNet中,我们可以对一个固定大小的邻域集进行采样,而不是使用一个完整的RippleNet集来进一步减少计算开销。
3、偏好传播(模型)
传统的基于CF的方法及其变体[11,31]学习用户和项目的潜在表示,然后通过直接将特定函数应用于其表示(如内积)来预测未知评级。在RippleNet中,为了以更细粒度的方式对用户和项目之间的交互进行建模,我们提出了一种偏好传播技术来探索用户在RippleNet集合中的潜在兴趣。
item embedding:直接在embedding层计算。
如图2所示,每个item v 与item embedding V∈Rd相关联,其中d是嵌入的维数。基于应用场景,item embedding可以合并项目的one hot ID、属性、字袋或上下文信息。
user embedding计算:【图2 绿色矩形(向量)相加,即以下公式6】
绿色矩形的计算:
1、计算与item embedding的相关概率
给定项embedding V和用户u的1跳ripple集Su1,Su1中的每个三元组(hi,ri,ti)通过比较项目v与该三元组中的头hi和关系ri来分配相关概率:
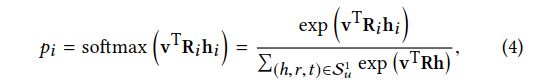
其中,Ri 和hi是关系和头的embedding。相关概率pi可以视作项目 v 和 实体hi 在关系空间Ri中的相似度, 注意不同的Ri关系空间计算得到的相似度不一样。
例如,《阿甘正传》和《弃儿》在考虑导演或明星时非常相似,但如果从体裁或作家的角度来衡量,它们的共同点就少了。
2、计算输入向量:(第一个绿色矩形表示的向量)
在得到相关概率后,取Su1中的尾乘以相应的相关概率进行加权求和,得到向量ou1:
![]()

3、偏好传播:(重复H次,H个绿色矩形)
通过等式(4)和等式(5)中的操作,用户的兴趣沿着Su1中的链路从其历史集合Vu转移到其1跳相关实体Eu1的集合,这在RippleNet中称为偏好传播。
通过(4)和(5)将V 替换成 ou1,重复这个过程,获得用户的2阶ou2,……。
从用户历史点击项目偏好开始通过H阶传播,得到各阶用户的偏好ou1 , ou2 , ..., ouH 。
用户u对于项目v的最终embedding:
![]()
【注意:ouH 会包含前面所有ou1 , ou2 , ..., 的信息,但可能会被稀释,所以把所有的o相加】
4、最后预测的概率:
将user embedding 和item embedding结合成为最终要预测点击的概率:
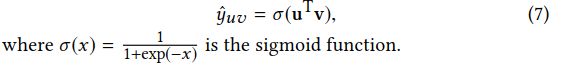
4、学习算法
损失函数的推导:
给定知识图谱G和交互矩阵Y,学习参数![]() 来使得预测的点击概率最大化:
来使得预测的点击概率最大化:
![]()
其中, ![]() 包括所有的实体、关系和项目的embedding。
包括所有的实体、关系和项目的embedding。
后验展开:
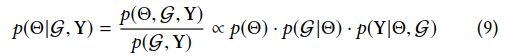 (根据贝叶斯)
(根据贝叶斯)
第一项: ![]() :模型参数的先验概率,设置为均值为0结合对角协方差矩阵的的高斯分布。
:模型参数的先验概率,设置为均值为0结合对角协方差矩阵的的高斯分布。
第二项: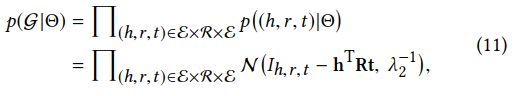 :给定观测知识图谱G的似然函数,G在θ下为均值为0的正太分布,采用张量分解令hTRt 接近于Ih,r,t,如果(h,r,t)属于G,则指标I h,r,t = 1,否则为0。hTRt ≈ 1或0(Ih,r,t)服从正态分布类似于别的KGE方法。
:给定观测知识图谱G的似然函数,G在θ下为均值为0的正太分布,采用张量分解令hTRt 接近于Ih,r,t,如果(h,r,t)属于G,则指标I h,r,t = 1,否则为0。hTRt ≈ 1或0(Ih,r,t)服从正态分布类似于别的KGE方法。
第三项:![]() :给定Θ和KG的观测隐式反馈的似然函数,其定义为伯努利分布的乘积。
:给定Θ和KG的观测隐式反馈的似然函数,其定义为伯努利分布的乘积。
结合前面的(2)到(7)的式子,最终的损失函数为:
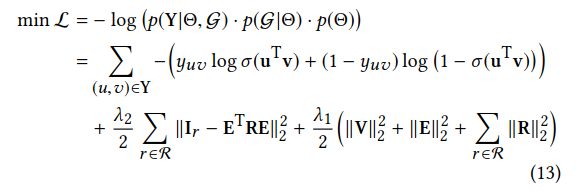
其中,V 和 E 为所有项目和实体的embedding矩阵,Ir 是在KG中关系 r 的指示张量 I 的切片,R 是关系 r 的embedding矩阵。
第一项:计算交互矩阵 Y 和 预测值 的交叉熵。
第二项:计算Ir 和重建指示矩阵ETRE的平方差。(没懂)
第三项:多拟合正则项。
SGD求解:
负采样:分别从 G 和 Y 的真/假三元组中随机抽取一小批,然后计算损失L相对于模型参数Θ的梯度,并基于采样的小批量数据通过反向传播更新所有参数。

5、讨论
(1) 可解释性。RippleNet基于KG探索用户的兴趣,它通过跟踪从用户历史到KG中具有高关联概率的项目(等式(4))的路径,提供了一个新的可解释性观点。
(2)ripple叠加。用户点击历史记录中不同项目的相关实体常常高度重叠。换句话说,从用户的点击历史记录开始,可以通过KG中的多个路径访问实体。
五、实验
三个场景:电影、书籍、新闻推荐
- Movielens-1M是电影推荐中广泛使用的基准数据集,评分1-5.
- •Book-Crossing数据集包含对图书交叉社区图书的1149780个明确评分(从0到10不等)。
- •Bing News数据集包含从2016年10月16日至2017年8月11日Bing News的服务器日志中收集的1025192条隐含反馈。每条新闻都有标题和片段。
输入:
对于MovieLens-1M和Book Crossing,我们使用用户和项目的ID embedding作为原始输入,而对于Bing News,我们将一条新闻的ID embedding和其标题的平均单词embedding连接为项目的原始输入,因为新闻标题通常比电影或书籍的名称长得多。
构造知识图谱:
我们使用Microsoft Satori为每个数据集构造知识图。
对于MovieLens-1M和Book Crossing,我们首先从KG集中选择 关系名包含“movie”或“Book”且置信度大于0.9的三元组子集。
给定子KG,我们通过将所有有效电影/书籍的名称与三元祖的尾部(head,film.film.name,tail)或(head,book.book.title,tail)匹配来收集它们的ID。为简单起见,排除没有匹配或多个匹配实体的项目。
然后,我们将ID 与所有KG三元组的头和尾匹配,从子KG中选择所有匹配良好的三元组,并将实体集迭代扩展到四跳。
Bing新闻的构造过程与Bing新闻相似,不同之处在于:
(1)我们使用实体链接工具来提取新闻标题中的实体;
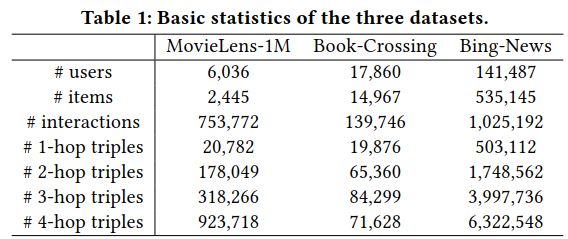
(2)由于新闻标题中的实体不在一个特定的域内,因此我们不限制关系的名称。三个数据集的基本统计数据见表1。
基线方法:
CKE、SHINE、DKN、PER、LibFM、Wide&Deep
实验设置:
设置高的H性能不能提升且计算量大。
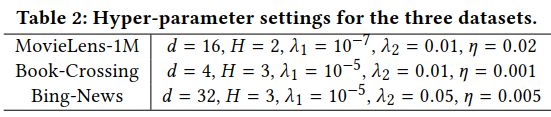
训练集:验证集:测试集 = 6:2:2
指标:
准确性和AUC评估CTR预估性能。
精度、召回、F1评估推荐性能。
六、 实验代码
本文的代码地址如下:https://github.com/princewen/tensorflow_practice/tree/master/recommendation/Basic-RippleNet-Demo
参考的代码地址为:https://github.com/hwwang55/RippleNet
数据下载地址为::https://pan.baidu.com/s/13vL-z5Wk3jQFfmVIPXDovw 密码:infx
在对数据进行预处理后,我们得到了两个文件:kg_final.txt和rating_final.txt
rating_final.txt数据形式如下,三列分别是user-id,item-id以及label(1表示正样本,0是负样本。0是通过负采样得到的,正负样本比例为1:1)。label表示用户与项目的偏好和不偏好。

kg_final.txt格式如下,三类分别代表h,r,t(这里entity和item用的是同一套id):
h和 t都是有关于item的实体,类似于 “4657 film.actor.film 64604” 。 电影 id 为4657的导演是 电影id 64604。
以下的关系 r 为film.actor.film等,比如 “film.film.star”、“film.film.writer”、“film.person_or_entity_appearing_in_film.film”。共有25种关系。

作者:文哥的学习日记
链接: https://www.jianshu.com/p/c5ffaf7ed449
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。